手绘流程图讲解spark是如何实现集群的高可用
摘要:本文讲述spark是怎么针对master、worker、executor的异常情况做处理的。
本文分享自华为云社区《图解spark是如何实现集群的高可用》,作者:breakDawn。
我们看下spark是怎么针对master、worker、executor的异常情况做处理的。
容错机制-exeuctor退出
首先可以假设worker中的executor执行任务时,发送了莫名其妙的异常或者错误,然后对应线程消失了。
我们看这个时候会做什么事情
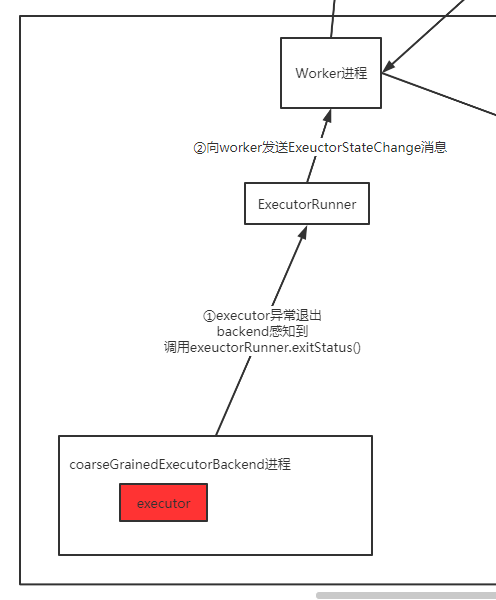
上图总结下来就是:
executor由backend进程包着,如果抛异常,他会感知到,并调用executorRunner.exitStatus(), 通知worker
看下通知worker之后发生了什么:
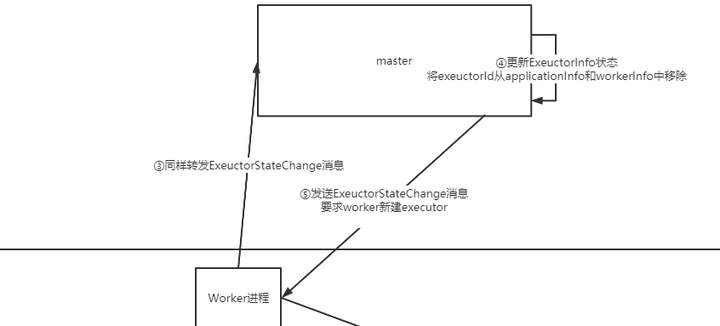
- worker会通知master,master会将exectorInfo清除,然后调度worker让他重新创建
- 这里可以看到worker创建executor的指令仍然是让master来调度和管理的,不是自己想创建就创建。
接下来就是重建executor,然后重新开始执行这个地方的任务了(因此数据也会重新拉,之前发送端缓存的数据就能够派上用场了)
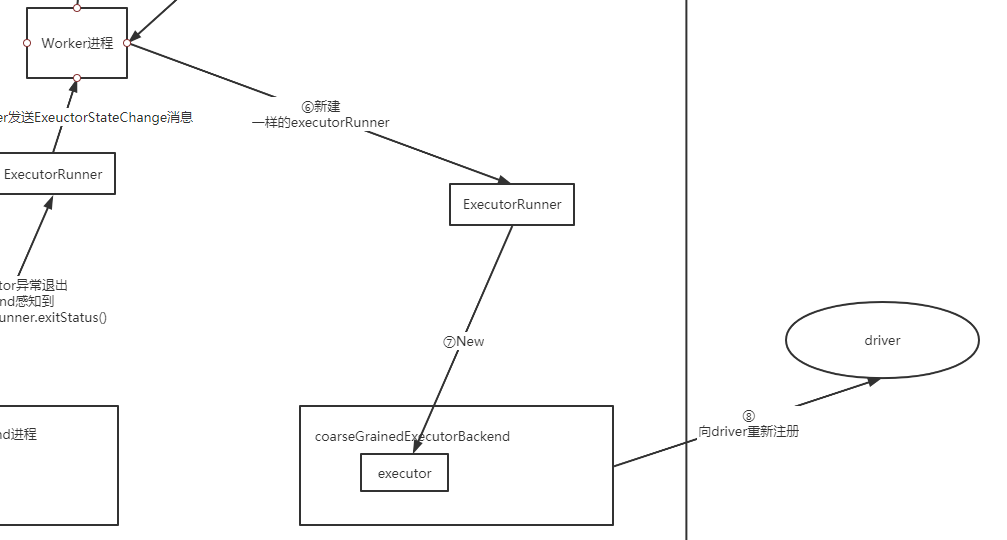
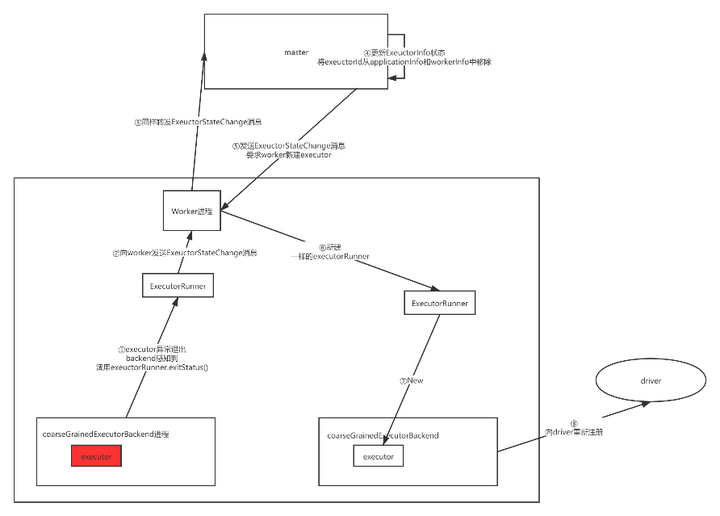
完整流程图如下:
worker异常退出
假设此时是worker挂掉了, 那么正在执行任务的exeuctor和master会怎么做呢?如下:
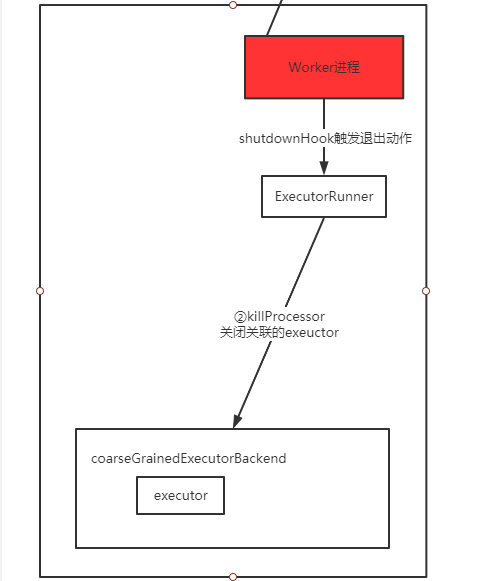
可以看到worker有一个shutdownHook,会帮忙关闭正在执行的executor。
但是此时worker挂了,因此没法往master发送消息了,怎么办?
上一节有讲到master和worker之间存在心跳,因此就会有如下处理:
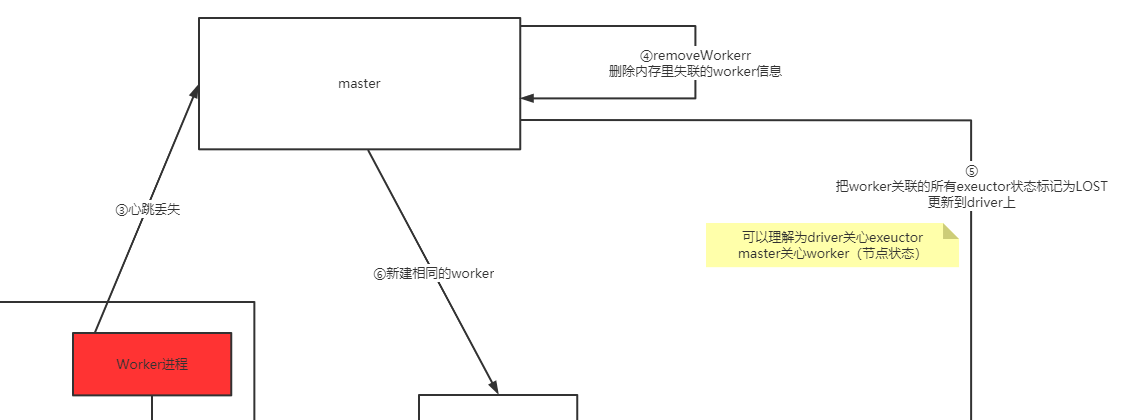
可以看到当master发现worker的心跳丢失时,会进行:
- 删除执行列表里的worker信息
- 重新下发创建worker的操作给对应spark节点
- 通知driver这个worker里面的exector都已经lost了
看下此时worker重建和driver分别做了什么:
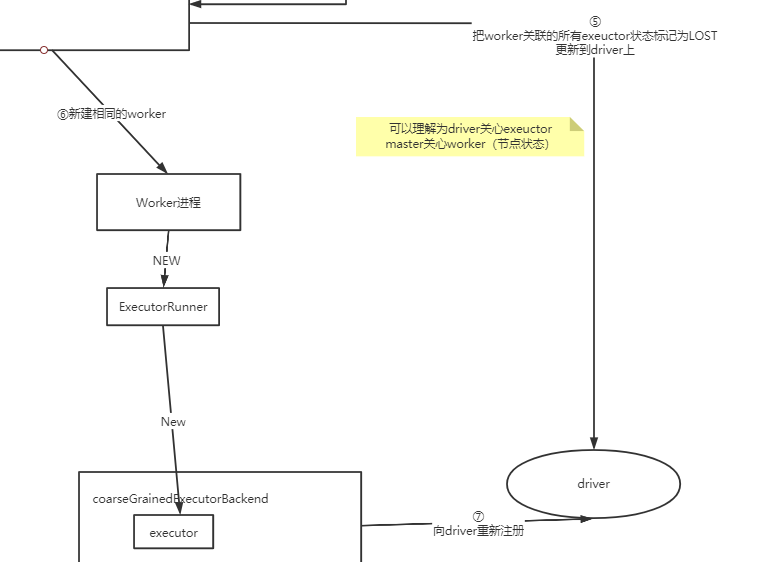
这里还可以看到1个很重要的概念:
- master关心worker状态
- driver会关心executor进展
- exeuctor重建后需要注册到driver上
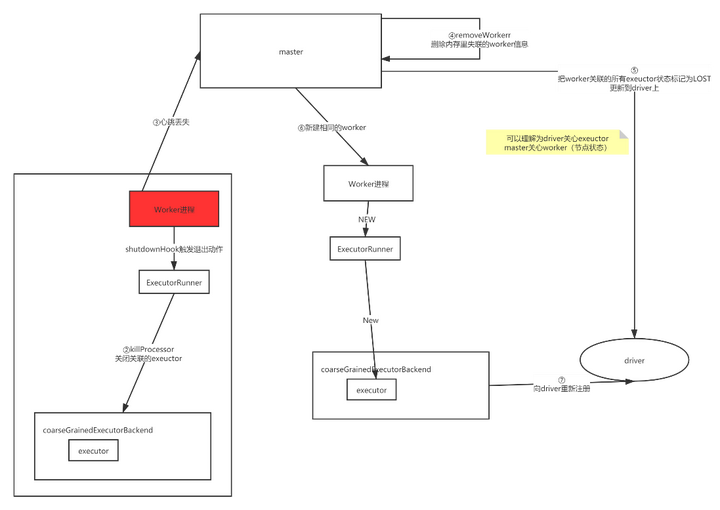
完整流程图如下:
master异常
由于master不参与任务的计算,只是对worker做管理,因此对于master的异常,分两种情况:
1、任务正常运行时master异常退出
则流程如下:
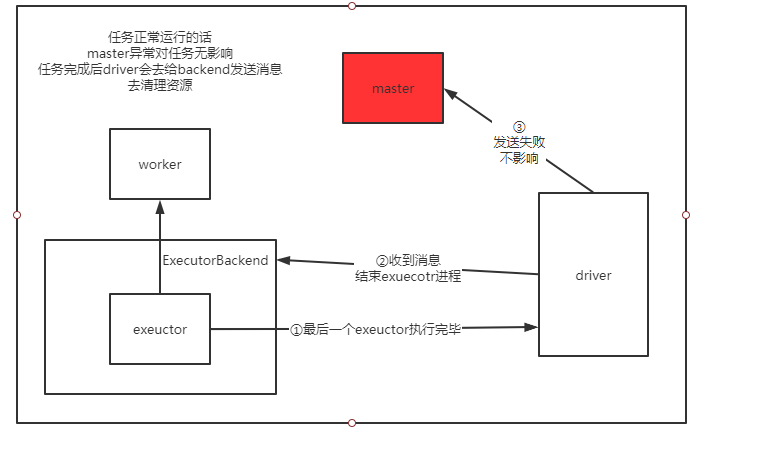
从这里可以看到当任务正常运行时,只会在结束时,由driver去触发master的清理资源操作,但是master进程已经挂掉了,所以也没关系。
2、当任务执行过程中,master挂掉后,worker和executor也异常了
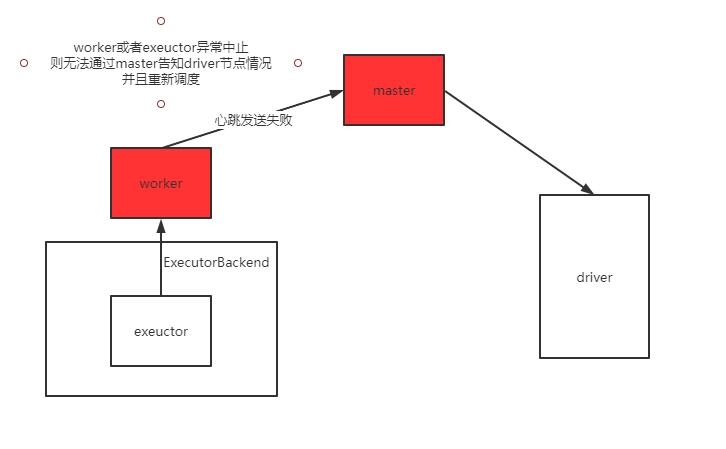
可以看到这时候时没办法重启exeuctor的
此时driver那边就会看起来任务一直没进展了。
为了避免这种情况,master可以做成无状态化,然后做主备容灾。当然master节点做的时候比较少,一般不容易崩溃,除非认为kill或者部署节点故障。
手绘流程图讲解spark是如何实现集群的高可用的更多相关文章
- Spark Streaming揭秘 Day31 集群模式下SparkStreaming日志分析(续)
Spark Streaming揭秘 Day31 集群模式下SparkStreaming日志分析(续) 今天延续昨天的内容,主要对为什么一个处理会分解成多个Job执行进行解析. 让我们跟踪下Job调用过 ...
- Spark Streaming揭秘 Day30 集群模式下SparkStreaming日志分析
Spark Streaming揭秘 Day30 集群模式下SparkStreaming日志分析 今天通过集群运行模式观察.研究和透彻的刨析SparkStreaming的日志和web监控台. Day28 ...
- Spark学习之在集群上运行Spark
一.简介 Spark 的一大好处就是可以通过增加机器数量并使用集群模式运行,来扩展程序的计算能力.好在编写用于在集群上并行执行的 Spark 应用所使用的 API 跟本地单机模式下的完全一样.也就是说 ...
- 【原创 Hadoop&Spark 动手实践 5】Spark 基础入门,集群搭建以及Spark Shell
Spark 基础入门,集群搭建以及Spark Shell 主要借助Spark基础的PPT,再加上实际的动手操作来加强概念的理解和实践. Spark 安装部署 理论已经了解的差不多了,接下来是实际动手实 ...
- Spark学习之在集群上运行Spark(6)
Spark学习之在集群上运行Spark(6) 1. Spark的一个优点在于可以通过增加机器数量并使用集群模式运行,来扩展程序的计算能力. 2. Spark既能适用于专用集群,也可以适用于共享的云计算 ...
- 在local模式下的spark程序打包到集群上运行
一.前期准备 前期的环境准备,在Linux系统下要有Hadoop系统,spark伪分布式或者分布式,具体的教程可以查阅我的这两篇博客: Hadoop2.0伪分布式平台环境搭建 Spark2.4.0伪分 ...
- Idea里面远程提交spark任务到yarn集群
Idea里面远程提交spark任务到yarn集群 1.本地idea远程提交到yarn集群 2.运行过程中可能会遇到的问题 2.1首先需要把yarn-site.xml,core-site.xml,hdf ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- HADOOP+SPARK+ZOOKEEPER+HBASE+HIVE集群搭建(转)
原文地址:https://www.cnblogs.com/hanzhi/articles/8794984.html 目录 引言 目录 一环境选择 1集群机器安装图 2配置说明 3下载地址 二集群的相关 ...
- hadoop+tachyon+spark的zybo cluster集群综合配置
1.zybo cluster 架构简述: 1.1 zybo cluster 包含5块zybo 开发板组成一个集群,zybo的boot文件为digilent zybo reference design提 ...
随机推荐
- QGradient渐变填充
QGradient渐变填充 QGradient (一)简介 (二)枚举类型 1.spread 2.CoordinateMode 3.type (三)常用函数 1.coordinateMode() 2. ...
- JVM指令分析
代码: 1 public class AppGo{ 2 public static void test() { 3 boolean flag = true; 4 if (flag) System.ou ...
- Java 中 field 和 variable 区别及相关术语解释(转)
https://www.jianshu.com/p/08e2d85d3ce9 这是一个以前从没仔细想过的问题--最近在阅读Java Puzzlers,发现其大量使用了"域"这个词, ...
- CodeDesk-一个新款跨平台桌面开发框架
CodeDesk 的灵感来自 Electron和Photino.这是一个基于 .NET 的开源项目. CodeDesk 的目标是使开发人员能够在跨平台的本机应用程序中使用 Web UI(HTML.Ja ...
- 12k Star、40万+开发者信赖的开源商城系统
前几天,有位读者问我有没有什么优秀的国产开源电商平台,他要拿来接单赚外快.我一听这话,精神头就来了. 所以,今天 HelloGitHub 就给大家找来了一款自用.二开都很方便的国产开源商城系统--CR ...
- list.add()语句作用
----该方法用于向集合列表中添加对象 示例 本示例使用List接口的实现类ArrayList初始化一个列表对象,然后调用add方法向该列表中添加数据. public static void mai ...
- 2023-12-02:用go语言,如何求模立方根? x^3=a mod p, p是大于等于3的大质数, a是1到p-1范围的整数常数, x也是1到p-1范围的整数,求x。 p过大,x不能从1到p-1遍
2023-12-02:用go语言,如何求模立方根? x^3=a mod p, p是大于等于3的大质数, a是1到p-1范围的整数常数, x也是1到p-1范围的整数,求x. p过大,x不能从1到p-1遍 ...
- 构建满足流批数据质量监控用火山引擎DataLeap
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 面对今日头条.抖音等不同产品线的复杂数据质量场景,火山引擎 DataLeap 数据质量平台如何满足多样的需求?本文 ...
- 用元编程来判断STL类型
在此之前,先来回顾元编程当中的一个重要概念. template<typename _Tp, _Tp __v> struct integral_constant { static con ...
- 吉特日化MES系统&各类化妆品检验标准汇总
在日化行业中,生产配料过程中,对产品的检验主要分为四大类: (1) 感官指标 (2) 理化指标 (3) 微生物指标 (4) 毒理指标 根据每个产品的不同,其指标会有所不同