用Python制作新浪微博爬虫
早上刷空间发现最近好多人过生日诶~
仔细想想,好像4月份的时候也是特别多人过生日【比如我
那么每个人生日的月份有什么分布规律呢。。。突然想写个小程序统计一下
最简单易得的生日数据库大概就是新浪微博了:
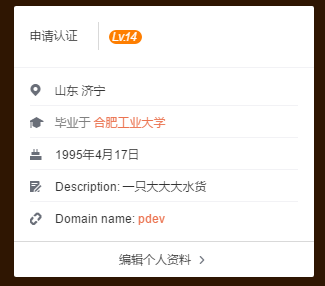
但是电脑版的新浪微博显然是动态网页。。。如果想爬这个应该要解析JS脚本【就像上次爬网易云音乐。。然而并不会解
其实有更高效的方法:爬移动版
移动版因为手机浏览器的限制大多都做了简化,更有利于爬虫
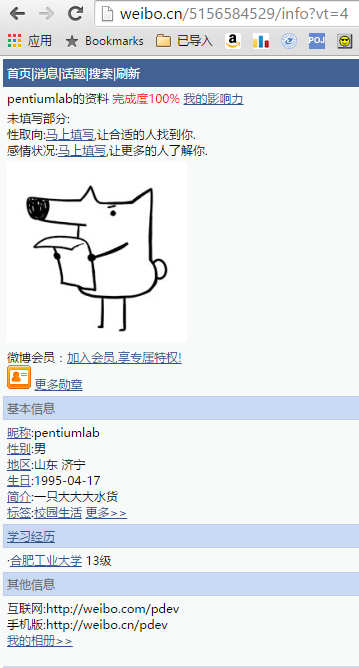
注意上面的网址:http://weibo.cn/5156584529/info
经测试不同的用户仅仅是中间的数字不同,那么只要枚举数字就可以实现爬虫了~
但是移动版微博想查看用户资料是必须要登录的。所以我们要先模拟登录,获取cookie,再访问url,获取用户资料。
许多网站的登录都用到了cookie,大体过程如下:
用户输入用户名密码,浏览器将这些组成一个form(表单)提交给服务器,若服务器判断用户名密码正确则会返回一个cookie,然后浏览器会记录下这个cookie。之后用本地的cookie再访问就不用登录了。
模拟登录:
打开微博移动版主页http://weibo.cn,点击登录,得到登录地址:
http://login.weibo.cn/login/?ns=1&revalid=2&backURL=http%3A%2F%2Fweibo.cn%2F&backTitle=%CE%A2%B2%A9&vt=
【这界面真的好丑。。。
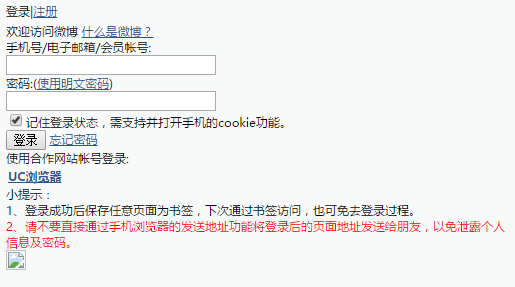
输入用户名密码登录,用chrome抓包,查看表单:
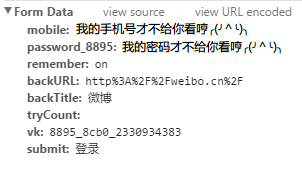
其实我们只需要表单就够了。
用Python中的urllib2,使用表单数据访问登录页,获取cookie,再用cookie访问用户页即可。
但是还要注意一个问题:新浪微博作了反爬虫处理,因此会遇到这个错误:
urllib2.HTTPError: HTTP Error 403: Forbidden
所以还要加上一个头信息headers来冒充浏览器
code:
__author__ = 'IBM'
import urllib2
import urllib
import cookielib
headers = {'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
cookie = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie)) #uurl='http://weibo.cn/5156582529/info'
wurl='http://login.weibo.cn/login/?backURL=&backTitle=&vt=4&revalid=2&ns=1' logindata=urllib.urlencode(
{
'mobile':'不许偷看我手机号!',
'password_8199':'不许偷看我密码!',
'remember':'on',
'backURL':'http%253A%252F%252Fweibo.cn%252F',
'backTitle':'%E5%BE%AE%E5%8D%9A',
'tryCount':'',
'vk':'8199_4012_2261332562',
'submit':'%E7%99%BB%E5%BD%95'
}
) loginreq=urllib2.Request(
url=wurl,
data=logindata,
headers=headers
) loginres=opener.open(loginreq)
print loginres.read() html=opener.open(urllib2.Request(url='http://weibo.cn/5156584529/info',headers=headers))
dat=html.read()
print dat
输出的dat就是用户资料页的HTML。随便想要什么信息都可以去里面找啦~
【但是目前还有个问题没解决:注意表单里红色underline的那两段:
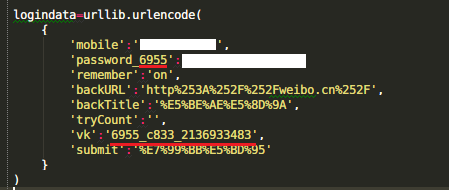
经测试这两个数字每次登录的时候都是不一样的。。而且同一个数字有效期是一定的,也就是说过一会儿这段代码可能就登录不了了。。。
个人猜测这可能是为了反爬虫吧。。。
under construction
Ref:
http://blog.csdn.net/pleasecallmewhy/article/details/9305229
http://www.douban.com/note/131370224/
用Python制作新浪微博爬虫的更多相关文章
- 利用python实现新浪微博爬虫
第一个模块,模拟登陆sina微博,创建weiboLogin.py文件,输入以下代码: #! /usr/bin/env python # -*- coding: utf-8 -*- import sys ...
- Windows 环境下运用Python制作网络爬虫
import webbrowser as web import time import os i = 0 MAXNUM = 1 while i <= MAXNUM: web.open_new_t ...
- dota玩家与英雄契合度的计算器,python语言scrapy爬虫的使用
首发:个人博客,更新&纠错&回复 演示地址在这里,代码在这里. 一个dota玩家与英雄契合度的计算器(查看效果),包括两部分代码: 1.python的scrapy爬虫,总体思路是pag ...
- 利用aiohttp制作异步爬虫
asyncio可以实现单线程并发IO操作,是Python中常用的异步处理模块.关于asyncio模块的介绍,笔者会在后续的文章中加以介绍,本文将会讲述一个基于asyncio实现的HTTP框架--a ...
- Python 开发轻量级爬虫08
Python 开发轻量级爬虫 (imooc总结08--爬虫实例--分析目标) 怎么开发一个爬虫?开发一个爬虫包含哪些步骤呢? 1.确定要抓取得目标,即抓取哪些网站的哪些网页的哪部分数据. 本实例确定抓 ...
- Python 开发轻量级爬虫07
Python 开发轻量级爬虫 (imooc总结07--网页解析器BeautifulSoup) BeautifulSoup下载和安装 使用pip install 安装:在命令行cmd之后输入,pip i ...
- Python 开发轻量级爬虫06
Python 开发轻量级爬虫 (imooc总结06--网页解析器) 介绍网页解析器 将互联网的网页获取到本地以后,我们需要对它们进行解析才能够提取出我们需要的内容. 也就是说网页解析器是从网页中提取有 ...
- Python 开发轻量级爬虫05
Python 开发轻量级爬虫 (imooc总结05--网页下载器) 介绍网页下载器 网页下载器是将互联网上url对应的网页下载到本地的工具.因为将网页下载到本地才能进行后续的分析处理,可以说网页下载器 ...
- Python 开发轻量级爬虫04
Python 开发轻量级爬虫 (imooc总结04--url管理器) 介绍抓取URL管理器 url管理器用来管理待抓取url集合和已抓取url集合. 这里有一个问题,遇到一个url,我们就抓取它的内容 ...
随机推荐
- IOS开发之学习《AV Foundation 开发秘籍》
敲了这么久的代码,查阅了很多资料,都是网络电子版的,而且时间久了眼睛也累了,还不如看一下纸质的书籍,让眼睛休息休息. 本篇开始学习<AV Foundation 开发秘籍>,并记录对自己本人 ...
- IoC容器Autofac(5) - Autofac在Asp.net MVC Filter中的应用
Autofac结合EF在MVC中的使用,上一篇IoC容器Autofac(4) - Autofact + Asp.net MVC + EF Code First(附源码)已经介绍了.但是只是MVC中Co ...
- SQLServer中的页如何影响数据库性能 (转)
无论是哪一个数据库,如果要对数据库的性能进行优化,那么必须要了解数据库内部的存储结构.否则的话,很多数据库的优化工作无法展开.对于对于数据库管理员来说,虽然学习数据库的内存存储结构比较单调,但是却是我 ...
- Tomcat启动找不到JRE_HOME的解决方法
在配置测试环境时,将生产服务器的Tomcat目录打包过来后解压后,启动Tomcat后,发现如下问题: [tomcat@gsp bin]$ ./shutdown.sh Using CATALINA_BA ...
- oracle查看对象信息
1.查看某用户下所有对象的信息: SELECT owner, object_type, status, COUNT(*) count# FROM all_objects where owner='xx ...
- linux c++应用程序内存高或者占用CPU高的解决方案_20161213
对于绝大多数实时程序来说,实时处理相关程序中的循环问题所带来的对机器的损耗和自身的处理速度的平衡,以及与其他程序的交互以及对其他功能的影响难免会成为程序设计中最大的障碍同时也是最大的突破点. 在所有这 ...
- 今天发现一些很有意思的ubuntu命令
跑火车的sl/LS 终端数字雨cmatrix 可能是名言警句也可能是逗你玩的笑话的fortune/fortune-zh 一只会说话的牛 一只会吟诗的牛 上真牛喽! 炫酷 炫酷到这里了!!!
- vim 命令详解
vi: Visual Interface 可视化接口vim: VI iMproved VI增强版 全屏编辑器,模式化编辑器 vim模式: 编辑模式(命令模式) 输入模式 末行模式 模式转换: 编辑-- ...
- [WPF系列-高级TemplateBinding vs RelativeSource TemplatedParent]
What is the difference between these 2 bindings: <ControlTemplate TargetType="{x:Type Button ...
- HDU 5183 Negative and Positive (NP) --Hashmap
题意:问有没有数对(i,j)(0<=i<=j<n),使得a[i]-a[i+1]+...+(-1)^(j-i)a[j]为K. 解法:两种方法,枚举起点或者枚举终点. 先保存前缀和:a1 ...