(十)selenium实现微博高级搜索信息爬取
1.selenium模拟登陆
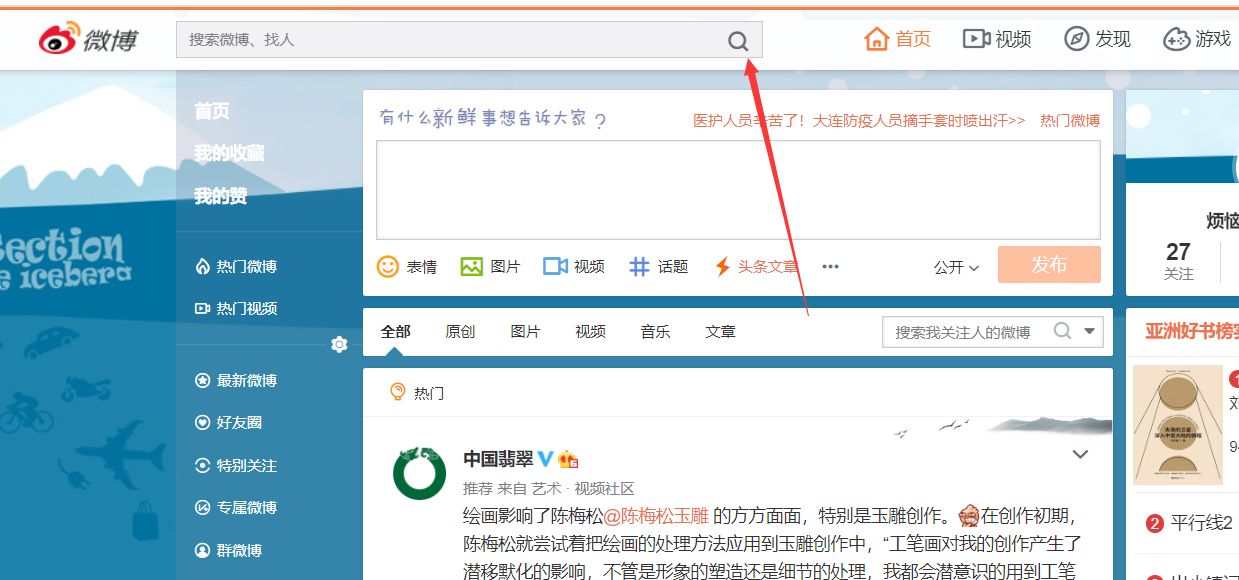
2.定位进入高级搜索页面
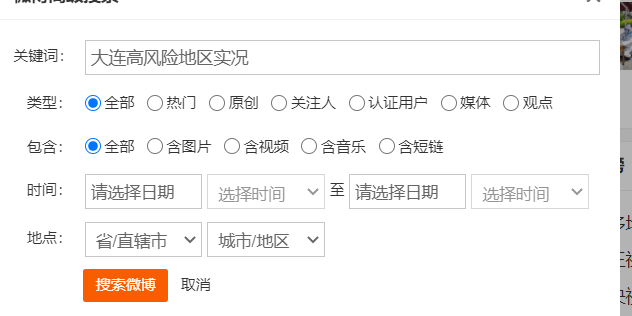
3.对高级搜索进行定位,设置。
4.代码实现
import time
from selenium import webdriver
from lxml import etree
from selenium.webdriver import ChromeOptions
import requests
from PIL import Image
from hashlib import md5
from selenium.webdriver.support.select import Select
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36',
} # 超级鹰
class Chaojiying_Client(object):
"""超级鹰源代码""" def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
} def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files,
headers=self.headers)
return r.json() def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json() # 输入用户名 密码
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
url = 'https://www.weibo.com/'
bro = webdriver.Chrome(executable_path='./chromedriver.exe',options=option)
bro.maximize_window()
bro.get(url=url)
time.sleep(10) # 视网速而定
bro.find_element_by_id('loginname').send_keys('你的账号')
time.sleep(2)
bro.find_element_by_css_selector(".info_list.password input[node-type='password']").send_keys(
"你的密码")
time.sleep(1) #识别验证码
def recognize(bro):
bro.save_screenshot('weibo.png')
pic = bro.find_element_by_xpath('//div[@class="login_innerwrap"]/div[3]/div[3]/a/img')
location = pic.location
size = pic.size
rangle = (location['x'] * 1.25, location['y'] * 1.25, (location['x'] + size['width']) * 1.25,
(location['y'] + size['height']) * 1.25)
i = Image.open('./weibo.png')
code_img_name = 'code.png' # 裁剪文件的文件名称
frame = i.crop(rangle) # 根据指定区域进行裁剪
frame.save(code_img_name)
chaojiying = Chaojiying_Client('超级鹰账号', '密码', ' 905993')
im = open('./code.png', 'rb').read()
result = chaojiying.PostPic(im, 3005)['pic_str']
return result # 输入验证码
# 微博第一次点击登陆可能不成功 确保成功登陆
for i in range(5):
try:
bro.find_element_by_xpath('//div[@class="login_innerwrap"]/div[3]/div[3]/div/input').send_keys(recognize(bro))
bro.find_element_by_xpath('//div[@class="login_innerwrap"]/div[3]/div[6]/a').click()
except Exception:
continue time.sleep(5)
# 进入高级搜索页面
bro.find_element_by_xpath('//div[@class="gn_header clearfix"]/div[2]/a').click()
bro.find_element_by_xpath('//div[@class="m-search"]/div[3]/a').click()
# 填入关键词
key_word = bro.find_element_by_xpath('//div[@class="m-layer"]/div[2]/div/div[1]/dl//input')
key_word.clear()
key_word.send_keys('雾霾') # 填入地点
province = bro.find_element_by_xpath('//div[@class="m-adv-search"]/div/dl[5]//select[1]')
city = bro.find_element_by_xpath('//div[@class="m-adv-search"]/div/dl[5]//select[2]')
Select(province).select_by_visible_text('陕西')
Select(city).select_by_visible_text('西安') # 填入时间
# 起始
bro.find_element_by_xpath('//div[@class="m-adv-search"]/div[1]/dl[4]//input[1]').click() # 点击input输入框
sec_1 = bro.find_element_by_xpath('//div[@class="m-caldr"]/div/select[1]')
Select(sec_1).select_by_visible_text('一月')
sec_2 = bro.find_element_by_xpath('//div[@class="m-caldr"]/div/select[2]')
Select(sec_2).select_by_visible_text('2019')
bro.find_element_by_xpath('//div[@class="m-caldr"]/ul[2]/li[3]').click() # 起始日期 # 终止
bro.find_element_by_xpath('//div[@class="m-adv-search"]/div[1]/dl[4]//input[2]').click() # 点击input输入框
sec_1 = bro.find_element_by_xpath('//div[@class="m-caldr"]/div/select[1]')
Select(sec_1).select_by_visible_text('一月') #月份
sec_2 = bro.find_element_by_xpath('//div[@class="m-caldr"]/div/select[2]')
Select(sec_2).select_by_visible_text('2019') # 年份
bro.find_element_by_xpath('//div[@class="m-caldr"]/ul[2]/li[6]').click() # 日期 sec_3 = bro.find_element_by_xpath('//div[@class="m-adv-search"]/div[1]/dl[4]//select[2]') # 点击input输入框
Select(sec_3).select_by_visible_text('8时') # 小时
bro.find_element_by_xpath('//div[@class="btn-box"]/a[1]').click() # 爬取用户ID 发帖内容 时间 客户端 评论数 转发量 点赞数 并持久化存储
page_num = 1
with open('2019.txt','a',encoding='utf-8') as f:
while page_num<=50:
page_text = bro.page_source
tree = etree.HTML(page_text)
div_list = tree.xpath('//div[@id="pl_feedlist_index"]/div[2]/div')
for div in div_list:
try:
user_id = div.xpath('./div/div[1]/div[2]/div[1]/div[2]/a[1]/text()')[0] # 用户id
flag = div.xpath('./div/div[1]/div[2]/p[3]')
if not flag:
content = div.xpath('./div/div[1]/div[2]/p[1]')[0].xpath('string(.)') # 内容
time = div.xpath('./div/div[1]/div[2]/p[2]/a/text()')[0] # 发布时间
client = div.xpath('./div/div[1]/div[2]/p[2]/a[2]/text()')[0]
else:
content = div.xpath('./div/div[1]/div[2]/p[2]')[0].xpath('string(.)') # 内容
time = div.xpath('./div/div[1]/div[2]/p[3]/a/text()')[0] # 发布时间
client = div.xpath('./div/div[1]/div[2]/p[3]/a[2]/text()')[0] #客户端
up=div.xpath('./div/div[2]/ul/li[4]/a')[0].xpath('string(.)') #点赞数
transfer = div.xpath('./div/div[2]/ul/li[2]/a/text()')[0] # 转发量
comment = div.xpath('./div/div[2]/ul/li[3]/a/text()')[0] # 评论数
f.write('\n'+user_id+'\n'+content+'\n'+time+client+' '+transfer+' '+comment+' '+'赞'+up+'\n'+'\n')
except IndexError:
continue
if page_num ==1: # 第一页 元素位置不同 进行判断
bro.find_element_by_xpath('//div[@class="m-page"]/div/a').click()
else:
bro.find_element_by_xpath('//div[@class="m-page"]/div/a[@class="next"]').click()
page_num+=1
(十)selenium实现微博高级搜索信息爬取的更多相关文章
- selenium跳过webdriver检测并爬取淘宝我已购买的宝贝数据
简介 上一个博文已经讲述了如何使用selenium跳过webdriver检测并爬取天猫商品数据,所以在此不再详细讲,有需要思路的可以查看另外一篇博文. 源代码 # -*- coding: utf-8 ...
- Javascript动态生成的页面信息爬取和openpyxl包FAQ小记
最近,笔者在使用Requests模拟浏览器发送Post请求时,发现程序返回的html与浏览器F12观察到的略有不同,经过观察返回的response.text,cookies确认有效,因为我们可以看到返 ...
- selenium实现淘宝的商品爬取
一.问题 本次利用selenium自动化测试,完成对淘宝的爬取,这样可以避免一些反爬的措施,也是一种爬虫常用的手段.本次实战的难点: 1.如何利用selenium绕过淘宝的登录界面 2.获取淘宝的页面 ...
- 安居客scrapy房产信息爬取到数据可视化(下)-可视化代码
接上篇:安居客scrapy房产信息爬取到数据可视化(下)-可视化代码,可视化的实现~ 先看看保存的数据吧~ 本人之前都是习惯把爬到的数据保存到本地json文件, 这次保存到数据库后发现使用mongod ...
- 豆瓣电影信息爬取(json)
豆瓣电影信息爬取(json) # a = "hello world" # 字符串数据类型# b = {"name":"python"} # ...
- selenium跳过webdriver检测并爬取天猫商品数据
目录 简介 编写思路 使用教程 演示图片 源代码 @(文章目录) 简介 现在爬取淘宝,天猫商品数据都是需要首先进行登录的.上一节我们已经完成了模拟登录淘宝的步骤,所以在此不详细讲如何模拟登录淘宝.把关 ...
- Python 招聘信息爬取及可视化
自学python的大四狗发现校招招python的屈指可数,全是C++.Java.PHP,但看了下社招岗位还是有的.于是为了更加确定有多少可能找到工作,就用python写了个爬虫爬取招聘信息,数据处理, ...
- 基于selenium+phantomJS的动态网站全站爬取
由于需要在公司的内网进行神经网络建模试验(https://www.cnblogs.com/NosenLiu/articles/9463886.html),为了更方便的在内网环境下快速的查阅资料,构建深 ...
- Scrapy项目 - 实现豆瓣 Top250 电影信息爬取的爬虫设计
通过使Scrapy框架,掌握如何使用Twisted异步网络框架来处理网络通讯的问题,进行数据挖掘和对web站点页面提取结构化数据,可以加快我们的下载速度,也可深入接触各种中间件接口,灵活的完成各种需求 ...
- Scrapy项目 - 实现斗鱼直播网站信息爬取的爬虫设计
要求编写的程序可爬取斗鱼直播网站上的直播信息,如:房间数,直播类别和人气等.熟悉掌握基本的网页和url分析,同时能灵活使用Xmind工具对Python爬虫程序(网络爬虫)流程图进行分析. 一.项目 ...
随机推荐
- 阿里云 EMAS Serverless 重磅发布
简介: EMAS Serverless 是阿里云提供的基于Serverless技术的一站式后端开发平台,为开发者提供高可用.弹性伸缩的云开发服务,包含云函数.云数据库.云存储.静态网站托管等功能,可用 ...
- 阿里云GanosBase重磅升级,发布首个云孪生时空数据库
简介: GanosBase是李飞飞带领的达摩院数据库与存储实验室联合阿里云共同研发的新一代位置智能引擎:本次重磅升级为V4.0版本,推出首个云孪生时空数据库. 作者 | 谢炯 来源 | 阿里技术 ...
- [FAQ] SSH 免密登录主机/服务器 怎么操作 ?
1. 生成公私钥对,保存好. 命令:ssh-keygen -t rsa -C "xxx" 2. 将公钥传到远程主机的 ~/.ssh/authorized_keys 之中. 命令:s ...
- [ML] Google colab GPU 免费使用, 可挂载 Google drive
colab 的文本行就相当于命令行,命令统一都在前面加 ! . 开启 GPU 加速,通过菜单栏的 "修改" 菜单,选择 "笔记本设置". 挂载 Google d ...
- dotnet OpenXML 读取 PPT 形状边框定义在 Style 的颜色画刷
本文来和大家聊聊在 PPT 形状使用了 Style 样式的颜色画刷读取方法 在开始之前,期望大家已了解如何在 dotnet 应用里面读取 PPT 文件,如果还不了解读取方法,请参阅 C# dotnet ...
- Redisant Toolbox——面向开发者的多合一工具箱
Redisant Toolbox--面向开发者的多合一工具箱 Redisant Toolbox 拥有超过30种常用的开发工具:精心设计,快速.高效:离线使用,尊重您的隐私.官网地址:http://ww ...
- 由初中生实现的 Windows 12 网页版!
大家好,我是 Java陈序员. 这几天,逛 Github 的时候,看到了一个项目 win12 -- 仿 Windows12 网页版!被它实现的页面功能震撼到了,大家可以一起来感受下! 首先是登录页面. ...
- 基于三菱Q系列cc-Link的立体仓库控制系统
系统说明: 方案选择: 工艺流程: 触摸屏设计: 程序设计:采用SFC进行编程,结构清晰,逻辑明了 本文章为学习记录,水平有限,望各路大佬们轻喷!!! 转载请注明出处!!!
- 03 Xpath lxml库的安装和使用
Python lxml库的安装和使用 lxml 是 Python 的第三方解析库,完全使用 Python 语言编写,它对 Xpath 表达式提供了良好的支持,因此能够了高效地解析 HTML/XML 文 ...
- 【漏洞分析】HPAY 攻击事件分析
背景 造成本次攻击的原因是关键函数的鉴权不当,使得任意用户可以设置关键的变量值,从而导致攻击的发生. 被攻击合约:https://www.bscscan.com/address/0xe9bc03ef0 ...