ScaleDet:AWS 基于标签相似性提出可扩展的多数据集目标检测器 | CVPR 2023
论文提出了一种可扩展的多数据集目标检测器(
ScaleDet),可通过增加训练数据集来扩大其跨数据集的泛化能力。与现有的主要依靠手动重新标记或复杂的优化来统一跨数据集标签的多数据集学习器不同,论文引入简单且可扩展的公式来为多数据集训练产生语义统一的标签空间,通过视觉文本对齐进行训练,能够学习跨数据集的标签语义相似性来进行标签分配。经过训练后,ScaleDet可以很好地泛化任意具有可见和不可见类的上游和下游数据集来源:晓飞的算法工程笔记 公众号
论文: Training data-efficient image transformers & distillation through attention

Introduction
计算机视觉的重大进步是由大规模数据集推动的,大规模数据集对于训练具有良好泛化能力的识别模型至关重要。但收集大量带标注的数据集既费钱又费时,为了在没有额外标注成本的情况下利用更多训练数据,最近的研究集中于统一多个数据集。从更多视觉类别和更多样化的视觉领域中学习,然后进行检测和分割。
要跨多个数据集训练目标检测器,需要应对几个挑战:
- 多数据集训练需要统一跨数据集的异构标签空间,来自两个数据集的标签可能指代相同或相似的对象。
- 数据集之间的训练设置可能不一致,不同大小的数据集通常需要不同的数据采样策略和学习计划。
- 多数据集模型应该比单数据集模型表现更好,但异构的标签空间、数据集之间的域差异以及对较大数据集的过拟合风险使得这一目标的实现更难。
为了解决上述挑战,现有研究大多手动重新标记类或训练多个特定于数据集的分类器。但这些方法缺乏可扩展性,随着数据集的增加,手动重新标记工作量和训练多个分类器的复杂性迅速增加。

与上述研究不同,ScaleDet是可扩展的多数据集目标检测器,主要有两个创新点:
- 可扩展的公式统一多个标签空间。
- 新颖的损失公式学习跨数据集的硬标签和软标签分配:硬标签用于消除类标签的歧义,而软标签作为正则化器关联相似类标签。
总体而言,论文的贡献如下:
- 论文提出了一种用于目标检测的新型可扩展多数据集训练方法,利用文本编码根据语义相似性来统一和关联跨数据集的标签,通过视觉文本对齐训练单个分类器来学习硬标签分配和软标签分配。
- 论文通过大量实验证明
ScaleDet在多数据集训练中具有令人信服的可扩展性、通用性以及性能。 - 论文评估了
ScaleDet在具有挑战性的Object Detection in the Wild基准上的可转移性,证明其在下游数据集上具有不错的泛化能力。
ScaleDet: A Scalable Multi-Dataset Detector
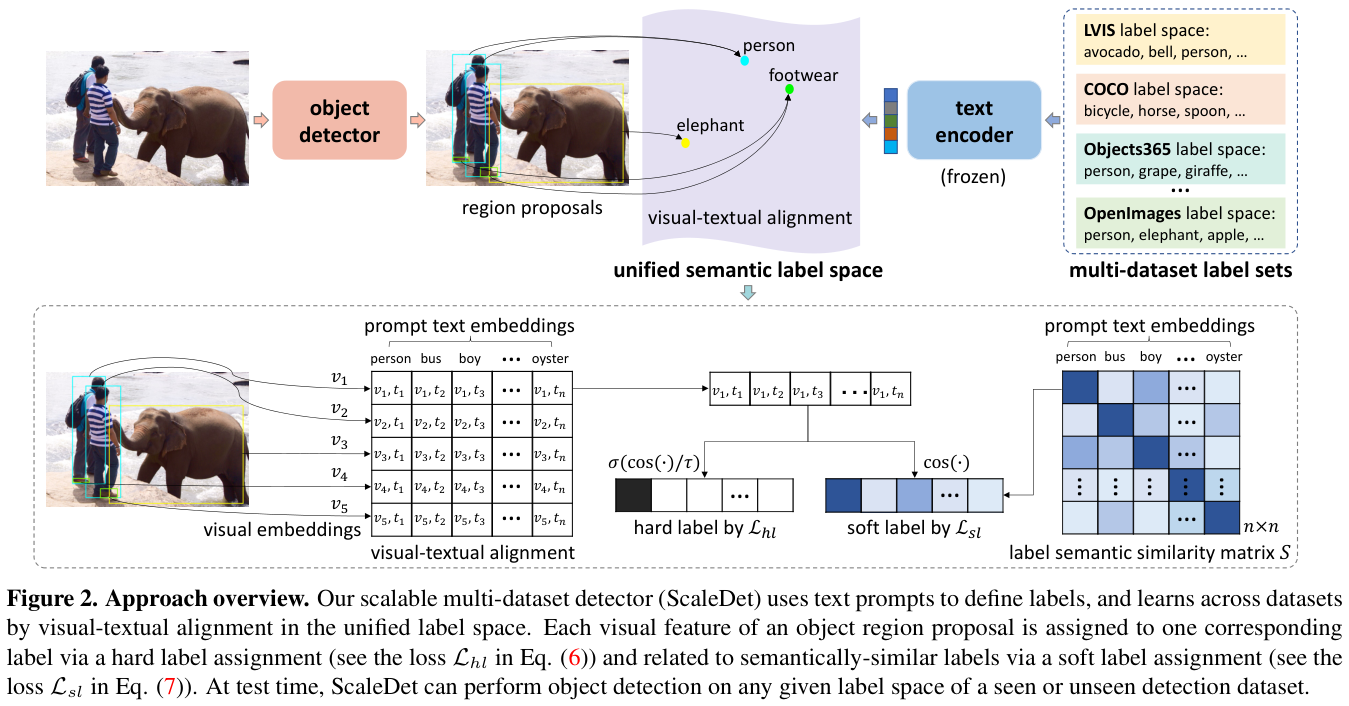
ScaleDet通过统一不同的标签集以形成统一的标签语义空间(图2顶部)进行跨数据集学习,并通过硬标签和软标签分配实现视觉文本对齐来进行训练(图2底部)。
Preliminaries and problem formulation
Standard object detection
典型的对象检测器旨在预测对象的\(b_{i}\in{\mathbf{R}}^{4}\)边界位置以及在给定\(n\)个类中的类标签\(c_i \in \mathbb{R}^n\)。给定图像 \(I\) ,检测器的图像编码器(例如 CNN 或 Transformer)提取框特征和视觉特征,将其送到边界框回归器 \(B\) 和视觉分类器 \(C\)进行预测。检测器通过最小化边界框损失 \(\mathcal{L}_{b b o x}\) 和分类损失 \(\mathcal{L}_{cls}\) 来学习边界框的预测以及框特征和视觉特征对应的类标签,即,
\]
现有的目标检测器通常采用一级或二级框架,其中可能包含额外损失项。单级检测器使用回归损失来回归对象位置的属性,如中心性,两阶段检测器则改为使用包含专用损失函数的RPN网络来预测每个框是目标的概率。
在这项工作中,论文专注于重新制定分类损失\(\mathcal{L}_{cls}\),在两级检测器之上解决多数据集训练问题。
Multi-dataset object detection
给定一组\(K\) 数据集 \(\{D_1, D_2, \dots, D_K\}\) 及标签空间 \(\{L_{1},L_{2},\dots,L_{K}\}.\) ,论文的目标是训练一个可扩展的多数据集检测器,该检测器可以很好地泛化上游和下游检测数据集。
之前的多数据集学习器手动将跨数据集的相似标签关联或合并到联合标签,而论文提出了一个简单但可扩展的公式来进行标签统一,无需手动合并任何标签。
Scalable unification of multi-dataset label space
如图2上部分所示,每次训练都从多个训练集中随机抽取一小批图像一起提取视觉特征 \(\{v_1, v_2, \ldots, v_j\}\),其中 \(v_{i}\in{\mathbf{R}}^{D}\) 是 \(D\) 维向量。每个视觉特征 $ v_{i}$ 通过标签分配与一组文本编码 \(\{t_{1},t_{2},\ldots,t_{n}\}\) 进行匹配。
Define labels with text prompts
论文用扩展的文本提示来表示每个类标签\(l_{i}\),例如,标签 人 可以用文本提示 一个人的照片 来表示。论文从预训练的 CLIP 或 OpenCLIP 的文本编码器中提取提示文本的编码\(t_{i}\),然后将所有文本编码进行均值操作。
Unify label spaces by concatenation
给定来自所有数据集的类标签的文本编码,多数据集训练的一个关键问题是统一不相同的标签空间\(\{L_{1},L_{2},\ldots,L_{K}\}\),这可以通过将相似的标签关联并合并来解决。然而,如果没有仔细的人工检查,标签定义的模糊性会导致模型训练中传播错误的风险。因此,论文不进行跨数据集的标签合并,而是先直接通过并集来统一不同的标签空间:
\]
其中 \(\coprod\) 表示并集,\(l_{k,i}\) 是来自数据集 \(k\) 的标签 \(i\)。除了简单之外,这个统一语义标签空间 \(L\) 最大限度地保留了所有标签的语义,从而为训练提供了更丰富的词汇。
Relate labels by semantic similarities
当使用文本编码来表示类标签时,可以在统一标签空间中关联相似语义的标签。为了展示跨数据集的标签关系,论文基于提示文本编码来计算语义相似性。对于给定的类标签 \(l_{i}\) ,用余弦相似性计算与所有标签的语义相似性,并在 0 和 1 之间归一化:
{{\operatorname*{sim}(l_{i},l_{j})=\displaystyle\frac{\cos(t_{i},t_{j})-\alpha_{i}}{\beta_{i}-\alpha_{i}},}}
\\
{{ \alpha_{i}=\operatorname*{min}\{\cos(t_{i},t_{j})\}_{j=1}^{n},}}
\\
{{\beta_{i}=\operatorname*{min}\{\cos(t_{i},t_{j})\}_{j=1}^{n}=\cos(t_{i},t_{i})=1,}}
\end{array}
\]
其中 \(\operatorname*{sim}(l_{i},l_{j})\) 是两个标签 \(l_{i},l_{j}\) 的文本编码 \(t_{i},t_{j}\) 之间的语义相似度。
编码所有类标签之间的标签关系,得到标签语义相似度矩阵 \(S\):
\]
其中\(S\)是一个\(n \times n\)矩阵,每个行向量\(\mathbf{S}_{i}\)编码标签\(l_{i}\)相对于所有 \(n\) 类标签的语义关系。
有了这些标签语义相似性,论文可以引入显式约束,使检测器能够在具有编码标签语义相似性的统一语义标签空间上学习。重要的是,相似性和标签空间都是离线计算的,这不会为训练和推理增加任何计算成本,在扩大训练数据集的数量时也不需要重新制定模型。
Training with visual-language alignment
为了在统一语义标签空间 \(\{l_1, l_2,\ldots, l_n\}\)上进行训练,论文通过硬标签和软标签分配将视觉特征与文本编码 \(\left\{t_{1},t_{2},\ldots,t_{n}\right\}\) 对齐。
Visual-language similarities
给定对象区域提案的视觉特征\(v_{i}\),论文首先计算 \(v_{i}\) 和所有文本编码\(\{t_{1},t_{2},\ldots,t_{n}\}\)之间的余弦相似度:
\]
有了这些相似度分数,论文可以根据以下损失项将视觉特征 \(v_i\) 与的文本编码对齐。
Hard label assignment
每个视觉特征 \(v_{i}\) 都有其真实标签 \(l_{i}\) ,因此可以通过硬标签分配与的文本编码 \(t_{i}\)匹配:
\]
其中 \(\mathrm{BCE}(\cdot)\) 是二元交叉熵损失,\(\sigma_{s g}{\big(}\cdot)\) 是 sigmoid 激活函数,\(\tau\) 是温度超参数。
上述公式虽然确保视觉特征 \(v_{i}\) 与文本嵌入\(t_{i}\) 对齐,但没有明确地学习跨数据集的标签关系。因此,论文引入软标签分配来学习语义标签关系。
Soft label assignment
论文通过语义相似度分数将单个标签与所有标签关联,同样地,视觉特征也可以通过使用语义相似度分数与所有文本编码关联。为此,论文在视觉特征\(v_{i}\) 上引入了软标签分配:
\]
其中,\(\mathrm{MSE}(\cdot)\) 是均方误差,\(\mathbf{s}_{i}\) 表示标签 \(l_{i}\) 和所有 \(n\) 类标签之间的语义相似性(标签语义相似性矩阵 \(S\) 的第 \(i\) 行)。
Remark
硬标签分配可以在概率空间消除不同类别标签的歧义,而软标签分配则可以在语义相似性空间中将每个视觉特征以不同的语义相似度分配给不同的文本编码,充当正则化器来关联跨数据集的相似类标签。
Training with semantic label supervision
基于硬标签和软标签分配,论文通过将视觉特征与统一语义标签空间中的文本编码对齐来对不同区域提议进行分类,从而训练检测器。即将原来检测器中的分类损失 \(\mathcal{L}_{c l,s}\) 被替换为:
\]
其中\(\lambda\) 是平衡超参数。由于上述损失使用语言监督将图像映射到文本,可以实现对不可见标签的零样本检测。
Overall objective
论文不改变原检测器中的检测损失\(\mathcal{L}_{b b o x}\),训练 ScaleDet 的总体目标是:
\]
使用 \(\mathcal{L}_{S c a l e D e t}\) 进行训练后,ScaleDet 可部署在包含可见或未见类的任何上游或下游数据集上。对于任何给定的测试数据集的标签空间,替换统一标签空间 \(L\) 后,ScaleDet 可以根据视觉语言相似性分配标签。当测试数据集包含未见过的类时,整体评估设置即为zero-shot检测或open-vocabulary对象检测。在任何给定的数据集上进行测试时,可以直接评估 ScaleDet 或在评估之前对其进行微调。
Experiments
Training with a growing number of datasets
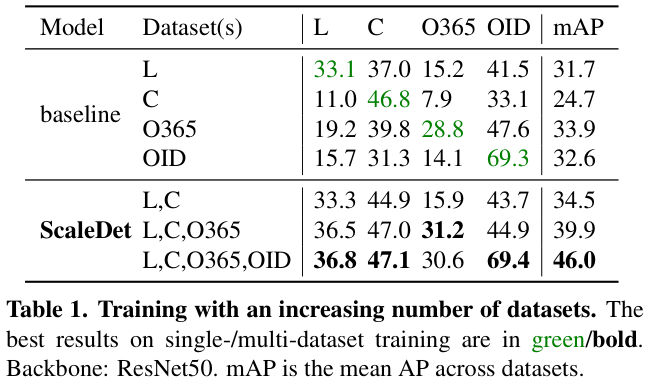
表 1 展示了在增加数据集数量时对上游数据集的影响:1) 增加训练数据集的数量始终会带来更好的模型性能。2)多数据集使用 ScaleDet 进行训练通常优于单数据集训练。这表明 ScaleDet 在异构标签空间、不同数据集的不同领域中学习得很好,并且不会过度拟合任何特定数据集。
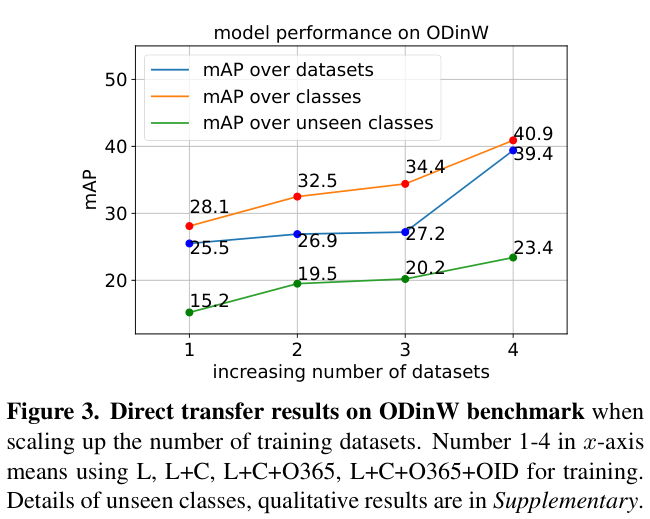
图 3 展示了在 ODinW 基准测试中直接迁移的性能。值得注意的是,扩大 ScaleDet 训练数据集的数量显着提高了下游数据集的准确性。
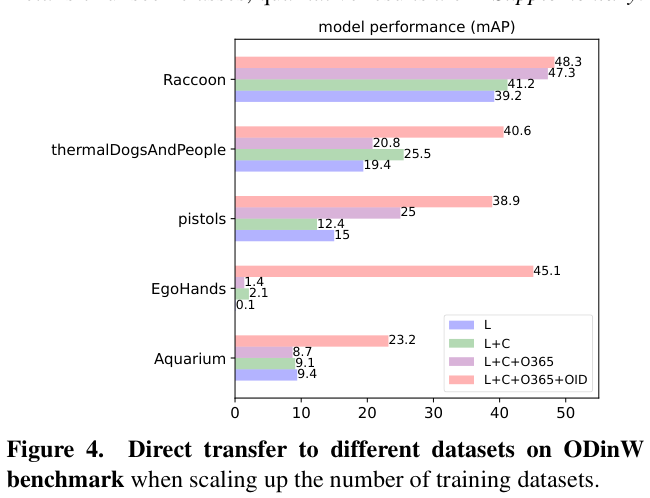
图 4 进一步可视化了 ScaleDet 在 ODinW 中的一些下游数据集上的性能。这些数据集要么包含看不见的类,要么来自与用于训练的那些非常不同的视觉域。重要的是,ScaleDet 在这两种情况下都表现良好。
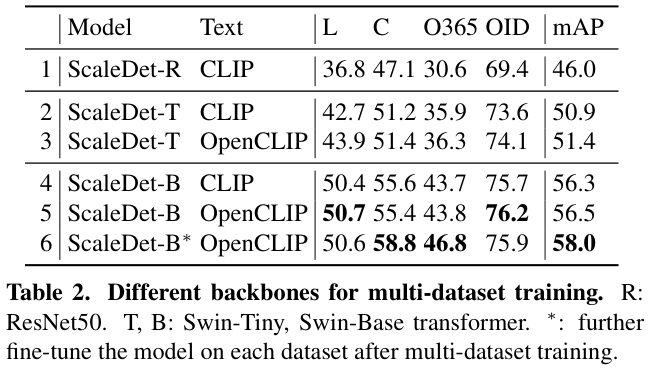
表 2 展示了使用不同的骨干和文本编码的测试结果。
Comparison to SOTA multi-dataset detectors
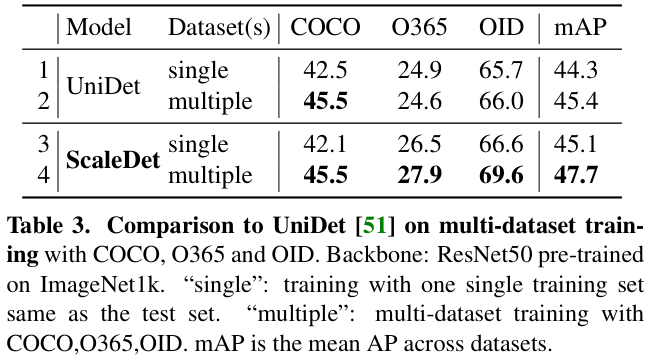
表 3 展示了遵循 UniDet 的设置并在相同的数据集上训练 ScaleDet的性能。UniDet 训练了多个特定于数据集的分类器,而 ScaleDet 则由一个分类器使用语义标签进行训练。
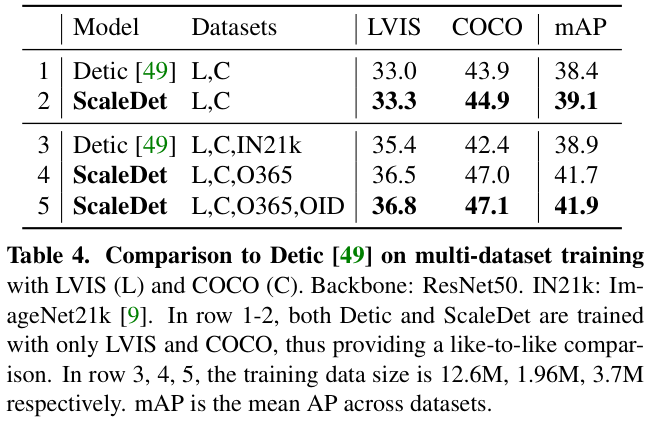
在表 4 展示了遵循 Detic 的设置执行多数据集训练的性能对比。在 Detic 中,LVIS 和 COCO 的统一标签空间包含 1203 个类标签,通过将两个标签集与 wordnet 同义词集合并获得,而 ScaleDet 将它们的标签(1203+80)“扁平化”为 1283。
Comparison to SOTA detectors on COCO
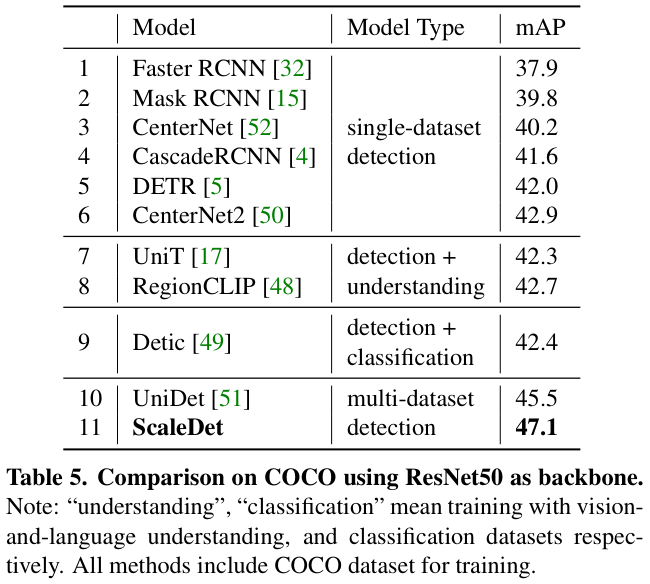
表 5 展示了基于 LVIS、COCO、O365、OID 训练论文的 ScaleDet 与其他模型的检测性能对比,其中所有模型都使用 ResNet50 主干训练。
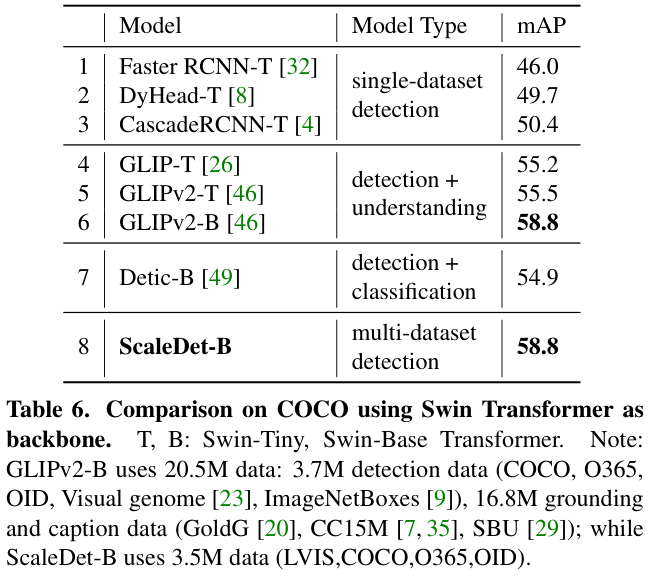
表 6 展示了使用 Swin Transformers 作为主干网络的性能对比。
Comparison of SOTA on ODinW
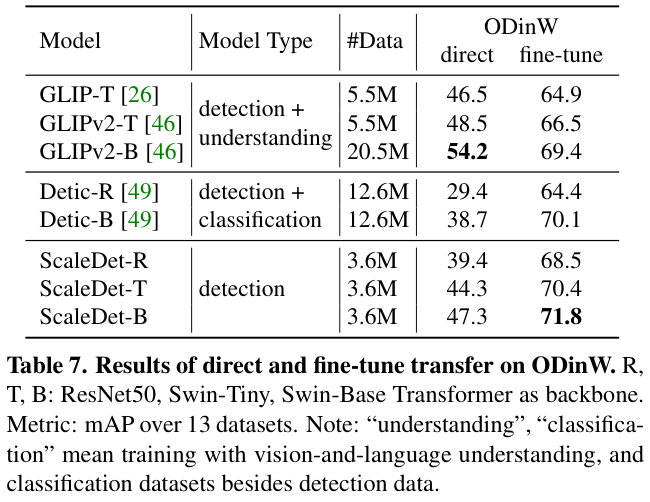
表 7 展示了 3 种检测器在 ODinW 上的性能比较。
Ablation study
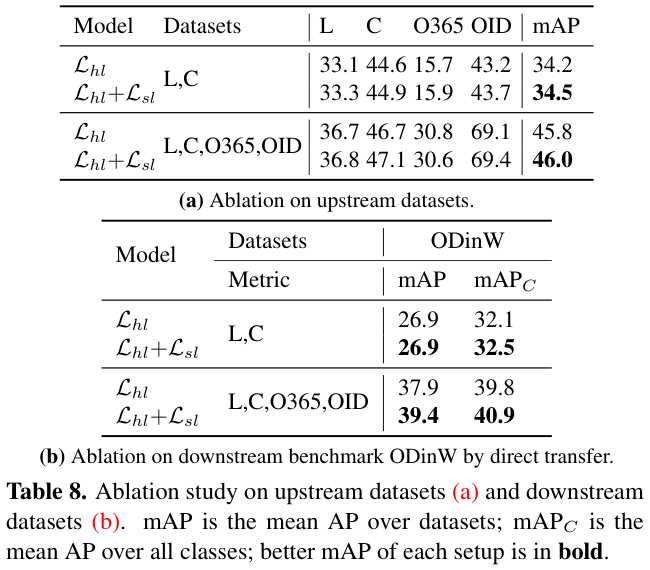
表 8 展示了 ScaleDet 的组件的消融实验结果。
Conclusion
论文介绍了一种简单但可扩展且有效的多数据集目标检测训练方法ScaleDet,在统一的语义标签空间中跨多个数据集学习,通过硬标签和软标签分配进行优化以对齐视觉和文本编码。 ScaleDet 在多个上游数据集(LVIS、COCO、Objects365、OpenImages)和下游数据集(ODinW)上实现了最新的性能。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

ScaleDet:AWS 基于标签相似性提出可扩展的多数据集目标检测器 | CVPR 2023的更多相关文章
- 基于Dapper的开源Lambda扩展LnskyDB 2.0已支持多表查询
LnskyDB LnskyDB是基于Dapper的Lambda扩展,支持按时间分库分表,也可以自定义分库分表方法.而且可以T4生成实体类免去手写实体类的烦恼. 文档地址: https://lining ...
- 基于log4net的日志组件扩展封装,实现自动记录交互日志 XYH.Log4Net.Extend(微服务监控)
背景: 随着公司的项目不断的完善,功能越来越复杂,服务也越来越多(微服务),公司迫切需要对整个系统的每一个程序的运行情况进行监控,并且能够实现对自动记录不同服务间的程序调用的交互日志,以及通一个服务或 ...
- 基于Dapper的开源LINQ扩展,且支持分库分表自动生成实体二
LnskyDB LnskyDB是基于Dapper的Lambda扩展,支持按时间分库分表,也可以自定义分库分表方法.而且可以T4生成实体类免去手写实体类的烦恼. 文档地址: https://lining ...
- 基于ABP的AppUser对象扩展
在ABP中AppUser表的数据字段是有限的,现在有个场景是和小程序对接,需要在AppUser表中添加一个OpenId字段.今天有个小伙伴在群中遇到的问题是基于ABP的AppUser对象扩展后,用 ...
- drf-day5——反序列化类校验部分源码分析、断言、drf请求、drf响应、视图组件及两个视图基类、基于GenericAPIView+5个视图扩展类
目录 一.反序列化类校验部分源码解析(了解) 二.断言 三.drf之请求 3.1 Request能够解析的前端传入的编码格式 3.2 Request类有哪些属性和方法(学过) 常用参数 Respons ...
- drf-drf请求、响应、基于GenericAPIView+5个视图扩展类
1.反序列化类校验部分源码分析(了解) 1.当我们在视图类中生成一个序列化类对象ser,并且用ser.is_valid()是就会执行校验,校验通过返回True,不通过返回False.首先对象ser和序 ...
- easyui tree扩展tree方法获取目标节点的一级子节点
Easyui tree扩展tree方法获取目标节点的一级子节点 /* 只返回目标节点的第一级子节点,具体的用法和getChildren方法是一样的 */ $.extend($.fn.tree.meth ...
- 基于 Golang 构建高可扩展的云原生 PaaS(附 PPT 下载)
作者|刘浩杨 来源|尔达 Erda 公众号 本文整理自刘浩杨在 GopherChina 2021 北京站主会场的演讲,微信添加:Erda202106,联系小助手即可获取讲师 PPT. 前言 当今时 ...
- HTML5部分新标签属性及DOM扩展元素
HTML5定义了一系列新元素,如新语义标签.智能表单.多媒体标签等. 我们日常讨论的H5其实是一个泛称,它指的是由HTML5 + CSS3 + Javascript等技术组合而成的一个应用开发平台. ...
- 推荐系统第6周--- SVD和基于标签的推荐系统
“隐语义”的真正背景 LSA(latent semantic analysis)潜在语义分析,也被称为LSI(latent semantic index),是Scott Deerweste ...
随机推荐
- CSS——样式继承
CSS的样式表继承指的是,特定的CSS属性向下传递到子孙元素.总的来说,一个HTML文档就是一个家族,然后html元素有两个子元素,相当于它的儿子,分别是head和body,然后body和head各自 ...
- ubuntu docker 解决sudo权限问题
#如果还没有 docker group 就添加一个:$sudo groupadd docker#将用户加入该 group 内.然后退出并重新登录就生效啦.$sudo gpasswd -a ${USER ...
- Xcode 最近使用的一些问题
1.上架的App如何测试推送? 苹果的证书分为开发证书和发布证书,上架AppStore的App应该使用发布证书进行配置,但是发布证书编译出包的App无法安装到手机上 只有一种方式,采用Ad hoc p ...
- tab切换中嵌套swiper轮播
今天在做官网的时候需要用到swiper多图轮播的功能,但是得嵌套在tab切换中,就在我把砖都搬完后,发现了个问题,就是我在进行tab切换后,发现原本设置的swiper的自动轮播竟然失效了,而且样式也是 ...
- vue计算属性computed
模板中放入太多的逻辑会让模板过重且难以维护,使用计算属性可以让模板变得简洁易于维护.计算属性是基于它们的响应式依赖进行缓存的,计算属性比较适合对多个变量或者对象进行处理后返回一个结果值,也就是数多个变 ...
- 国产大模型参加高考,同写2024年高考作文,及格分(通义千问、Kimi、智谱清言、Gemini Advanced、Claude-3-Sonnet、GPT-4o)
大家好,我是章北海 今天高考,上午的语文结束,市面上又要来一场大模型参考的文章了. 我也凑凑热闹,让通义千问.Kimi.智谱清言一起来写一下高考作文. 公平起见,不加任何其他prompt,直接把题目甩 ...
- kettle从入门到精通 第十四课 kettle kafka 生产者和消费者
1.本节课讲解kafka生产者和消费者两个步骤.这两个组件可以实现数据实时同步(后续课程会讲解). 2.kafka producer 步骤 1)step name:自定义名称 2)connection ...
- OpenTelemetry 实践指南:历史、架构与基本概念
背景 之前陆续写过一些和 OpenTelemetry 相关的文章: 实战:如何优雅的从 Skywalking 切换到 OpenTelemetry 实战:如何编写一个 OpenTelemetry Ext ...
- window10设置保护眼睛的颜色
1.调出运行菜单.右击开始键选择运行,或者同时按下键盘上的WIN+R打开运行框,输入 regedit 回车转到注册表编辑器.2.选择第二项 HKEY_CURRENT_USER 点击进入.进入后点击 C ...
- 掌握 Nuxt 3 中的状态管理:实践指南
title: 掌握 Nuxt 3 中的状态管理:实践指南 date: 2024/6/22 updated: 2024/6/22 author: cmdragon excerpt: 摘要:该文指南详述了 ...