OLOR:已开源,向预训练权值对齐的强正则化方法 | AAAI 2024
随着预训练视觉模型的兴起,目前流行的视觉微调方法是完全微调。由于微调只专注于拟合下游训练集,因此存在知识遗忘的问题。论文提出了基于权值回滚的微调方法
OLOR(One step Learning, One step Review),把权值回滚项合并到优化器的权值更新项中。这保证了上下游模型权值范围的一致性,有效减少知识遗忘并增强微调性能。此外,论文还提出了逐层惩罚,采用惩罚衰减和多样化衰减率来调整不同层的权值回滚级别,以适应不同的下游任务。通过对图像分类、对象检测、语义分割和实例分割等各种任务的广泛实验,证明了OLOR的普遍适用性和最先进的性能来源:晓飞的算法工程笔记 公众号
论文: One Step Learning, One Step Review

Introduction
随着深度学习技术的快速发展,大量的大规模图像数据集已经建立,产生了许多有前途的预训练视觉模型。这些预训练模型可以通过迁移学习和微调技术有效地解决相关但不同的视觉任务。基本的微调方法是线性探测和完全微调。
- 在线性探测中,预训练模型的主干被冻结,仅训练特定于下游任务的头部。然而,这种方法通常会限制预训练主干的性能。
- 另一方面,完全微调涉及直接训练整个网络,但这通常会导致知识遗忘。
为了进行有效的微调,许多研究提出了不同的方法:
- 基于重放机制的方法需要在学习新任务的同时对存储的上游样本子集进行再训练,效率相当低。
EWC提出了一种基于正则化的微调方法,使用Fisher信息矩阵来确定权值参数的重要性。这有助于调整上游和下游任务之间的参数,减少遗忘。L2-SP使用L2惩罚来限制参数的更新,解决微调过程中的知识遗忘问题。然而,它与自适应优化器不兼容,这可能会产生错误的正则化方向。- 参数隔离方法为下游任务的不同网络模型和任务创建新的分支或模块。但它引入了额外的新训练参数,需要一定的训练技巧,并且通用性低于排练方法。
在本文中,论文提出了一种结合优化器来解决知识遗忘的新颖微调方法,称为OLOR(One step Learning, One step Review)。具体来说,OLOR在微调阶段将权值回滚项引入到权值更新项中,使模型在学习下游任务的同时逐渐逼近预训练的权值。这个过程避免了延迟缺陷,并使上下游模型的权值更加相似。此外,还设计了逐层惩罚,利用惩罚衰减和多样化衰减率来调整各层的权值回滚水平。惩罚衰减将特征金字塔与迁移学习相结合,对与颜色、纹理等浅层特征相关的浅层给予更显着的权值回滚力度,对与语义信息等深层特征相关的深层给予更小的权值回滚力度。具有逐层惩罚的OLOR使模型的每一层都可以根据其需要进行更新,从而更好地提取广义特征。最后,OLOR合并到优化器中,引入的额外计算开销可以忽略不计。与Adam和SGD等流行优化器配合良好,满足各种条件下的特定需求。
论文主要贡献总结如下:
- 提出了新颖的微调方法
OLOR,与优化器合作解决知识遗忘问题,从而提高微调性能。 - 设计的权值回滚通过将当前梯度纳入惩罚项,避免延迟缺陷,从而修正惩罚目标,平滑回滚过程。
- 提出逐层惩罚,采用惩罚衰减和多样化衰减率来调整层的权值回滚级别,以适应不同的下游任务。
- 所提出的方法在广泛的下游任务上实现了最先进的性能,包括不同类型的图像分类、不同的预训练模型以及图像检测和分割。
Method
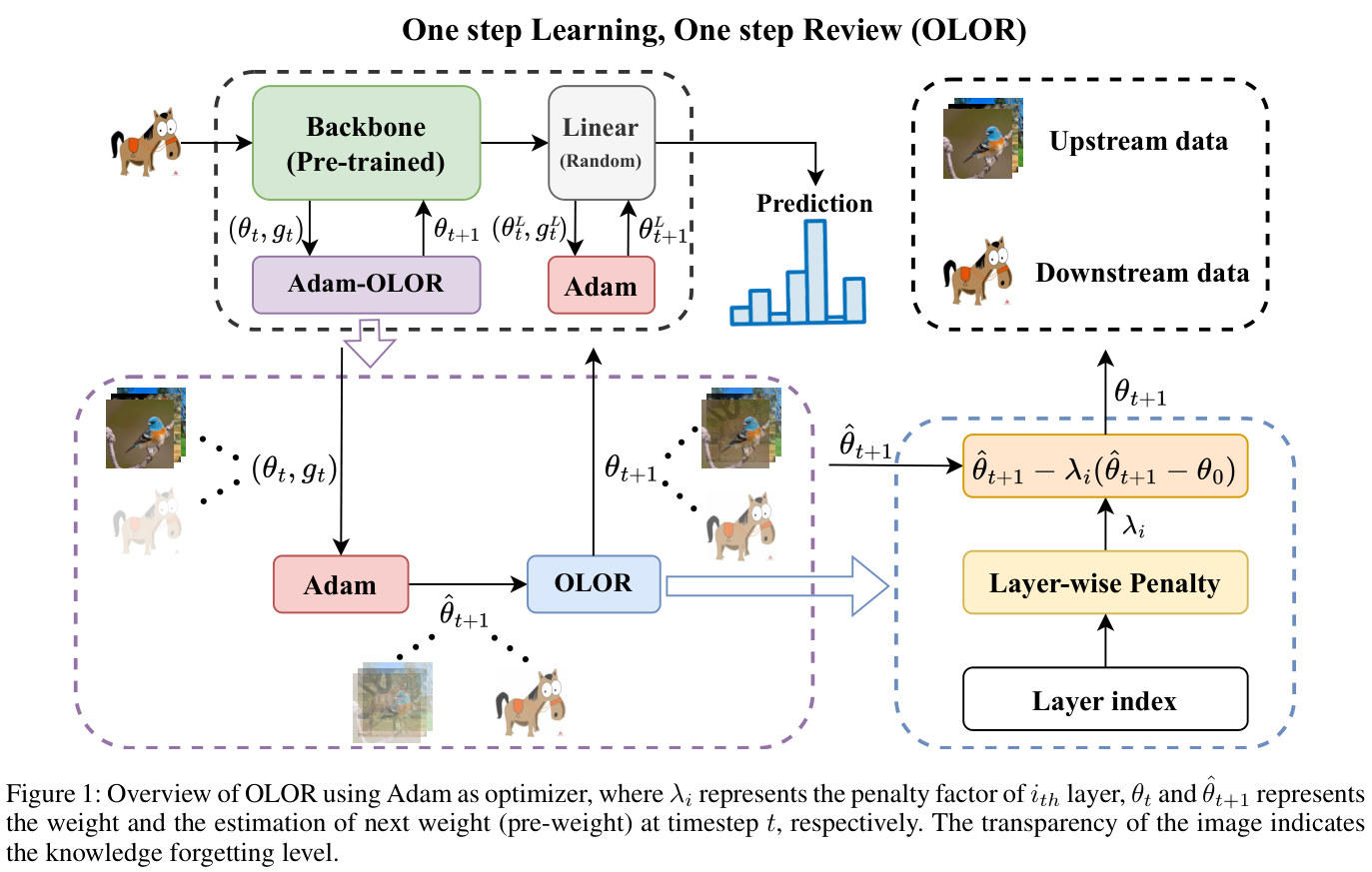


Previous Regularization Mechanisms Have a Delay Defect
OLOR的实现受到L2正则化和权值衰减的启发,这是用于正则化模型参数的常用方法。然而,论文的研究结果表明它们的有效性与最初的预期并不相符。
在经典SGD优化器的场景下,L2正则化可以被视为等价于权值衰减,其定义如下:
\quad\quad(1)
\]
其中 \({\theta}_{t}\) 表示迭代 \(t\) 时的模型权值,\({\theta}_{t-1}\) 是前一次迭代的相应权值, \(\lambda\) 是正则化因子(权重衰减强度) \({\eta}_{t}\) 是迭代时的学习率,\(g_{t}\) 是在迭代 \(t\) 时根据损失函数计算得出的当前批量的梯度。权值衰减通过将前一次迭代获得的权值推向 0 来对其进行惩罚。
然而,在实践中,\(\mathrm{lim}_{\lambda\to1}\theta_{t}=-\eta_{t}g_{t}\),权值往往会被推向当前梯度的负值而不是 0,行为与最初的期望不同。此外,与不应用权值衰减相比,应用权值衰减实际上会增加当前权值:
\quad\quad (2)
\]
简化为:
{{\eta g_{t}>(1-\frac{\lambda}{2})\theta_{t-1},}}&{{\mathrm{if}\,\theta_{t-1}>0,}}
\\
{{\eta g_{t}<(1-\frac{\lambda}{2})\theta_{t-1},}}&{{\mathrm{if}\,\theta_{t-1}<0,}}
\end{cases}
\]
如果 \(\eta\)、\(g_t\)、\(\lambda\) 和 \(\theta_{t-1}\) 处于上述条件下,使用权值衰减将使当前权重远离 0,这与目标相反。同样,衰减效应的问题也存在于其他正则化机制中,例如L1正则化、L2-SP等方法。
Weight Rollback
权值回滚是一种实时正则化方法,紧密跟踪每个权值的更新步骤,使当前模型权值更接近预先训练的权值以进行知识回顾(knowledge review)。
具体来说,第一步是通过梯度计算预权值 \(\theta_{\mathrm{pre}}\):
\quad\quad (3)
\]
其中 \(\theta_{t-1}\) 表示前一步的模型权值,\({\eta}_{t}\) 是当前步的学习率,\(g_t\) 表示当前梯度。随后,\(\theta_{\mathrm{pre}}\) 和预训练权值 \(\theta_{0}\) 之间的差异 \(\Delta d\) 计算如下:
\quad\quad (4)
\]
最后,权值更新过程加入了 \(\Delta d\),从而得到调整后的模型权值 \({\theta}_{t}\) :
\quad\quad (5)
\]
通过代入公式 3 和公式 4 到等式 5,可得到:
\quad\quad (6)
\]
公式 6 确保 \(\mathrm{lim}_{\lambda\rightarrow1}\theta_{t}=\theta_{0}\),符合论文的期望并防止异常情况。此外,由于梯度 \(g_t\) 也受到惩罚,可能也有助于减轻梯度爆炸。
综上所述,权值回滚技术可以缓和每一步 \({\theta}_{t}\) 和 \(\theta_{0}\) 之间的偏差,从而减轻对当前任务的过度拟合和对前一个任务的知识遗忘。
Layer-Wise Penalty
Penalty Decay
对于深度学习神经网络,每一层都可以被概念化为处理其输入的函数。给定层索引 \(i\),该过程可以描述如下:
\quad\quad (7)
\]
其中 \(f_{i}\) 代表 \({i}_{th}\) 层。令 \({x}_{i}^{u}\) 表示上游任务中 \(f_{i}\) 的输入,分布为 \(q_{i}\bigl(x_{i}^{u}\bigr)\),\({x}_{i}^{d}\) 表示下游任务中 \(f_{i}\) 的输入,分布为 \(p_{i}\left(x_{i}^{\tilde{d}}\right)\)。因为 \(q_{i}\bigl(x_{i}^{u}\bigr)\) 总是与 \(p_{i}\left(x_{i}^{\tilde{d}}\right)\) 不同,所以先解冻所有层以确保 \(f_i\) 将有充足的更新来更好地处理此差距。
在图像特征提取的研究中,普遍的理解是浅层主要负责捕获颜色、纹理和形状等表面特征。相比之下,更深的层专注于提取更深刻的特征,例如语义信息。这意味着浅层与数据的分布密切相关,而深层则与特定任务的目标更加一致。
迁移学习的一个基本假设是 \(q_{i}\bigl(x_{i}^{u}\bigr)\) 与 \(p_{i}\left(x_{i}^{\tilde{d}}\right)\) 具有一定程度的相似性。因此,浅层往往在预训练和微调阶段表现出相似性。此外,与较深的层相比,浅层需要的更新较少。
基于这些观察,论文提出了一种用于权值回滚的分层惩罚衰减机制。随着层深度的增加,逐渐降低回滚级别,鼓励浅层在下游任务中提取更通用的特征,同时保留整体模型容量。对于 \(i\) 层,惩罚因子 \(\lambda_{i}\) 的计算如下:
\quad\quad (8)
\]
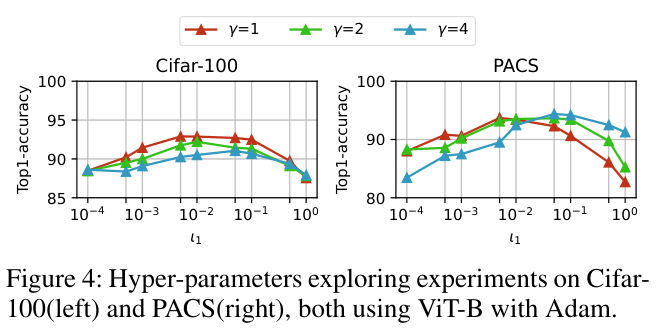
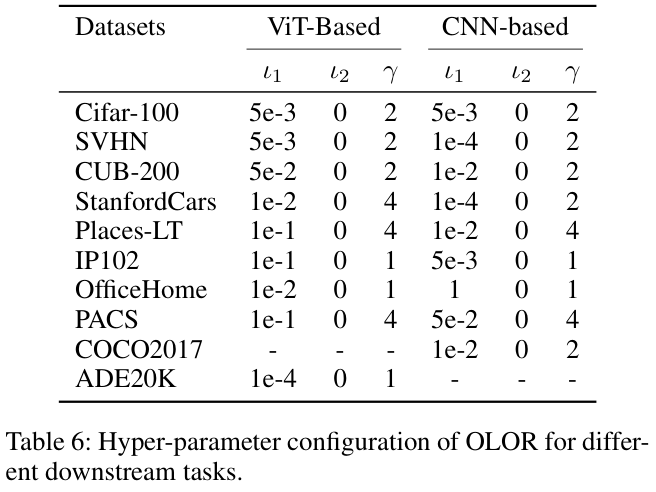
其中 \(n\) 表示预训练模型中的总层数,\({\iota_{1}\) 和 \({\iota_{2}\)分别表示最大和最小回滚级别。
Diversified Decay Rate
在各种下游任务中,训练目标通常与上游任务表现出不同程度的差异。为了适应这种可变性,论文通过向权值回滚值引入幂指数 \(\gamma\) 来调整层之间的惩罚衰减率,具体为:
\quad\quad(9)
\]
这种动态调整有助于减轻不同层的 \(q_{i}\bigl(x_{i}^{u}\bigr)\) 与 \(p_{i}\left(x_{i}^{\tilde{d}}\right)\) 之间的相似性由于固定衰减速率而产生的偏差。因此,惩罚衰减变得更具适应性和通用性,满足各种下游规定的一系列任务的要求。
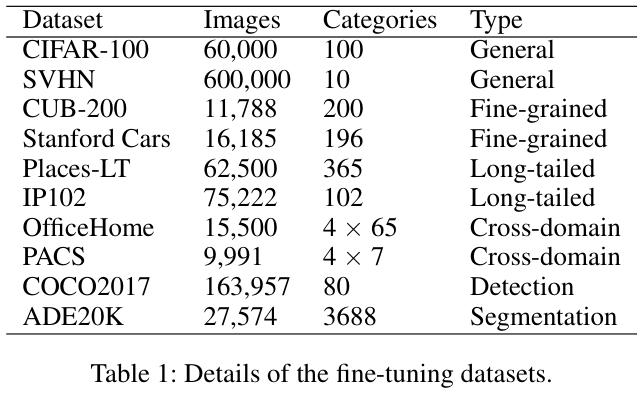
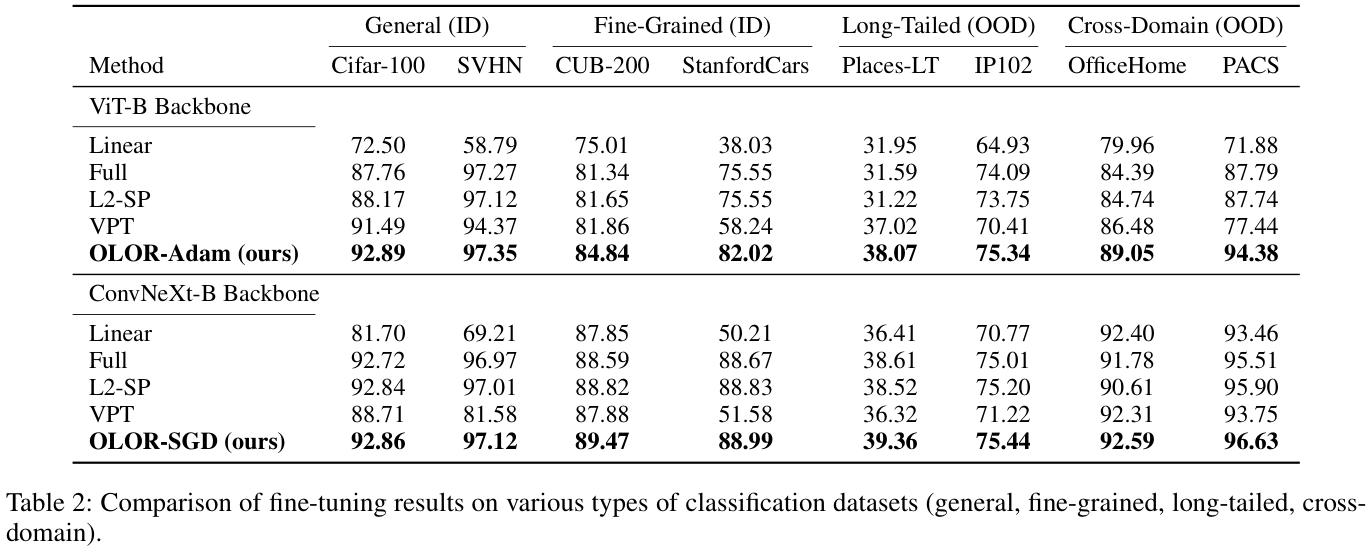
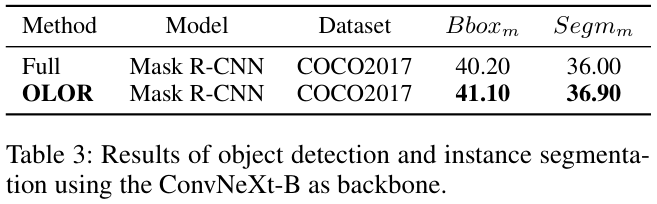
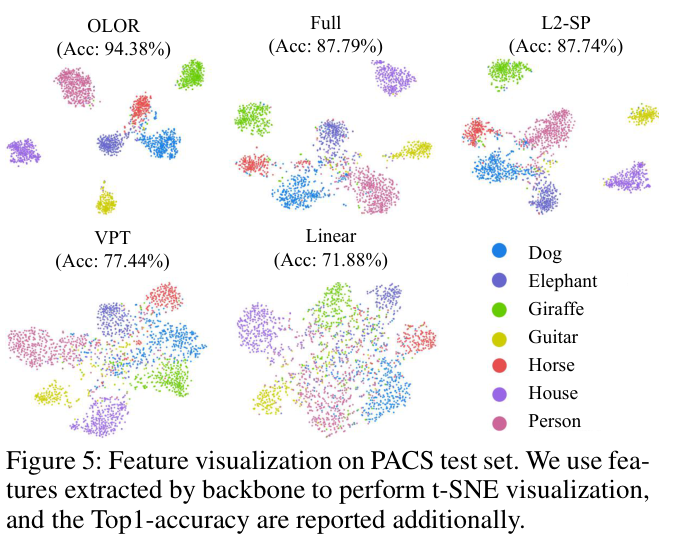
Experiments
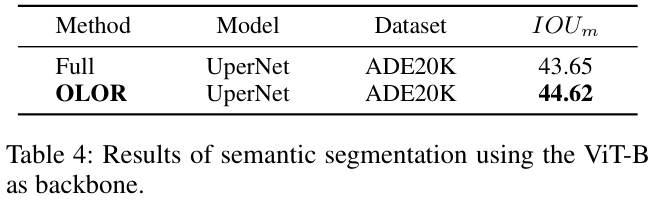
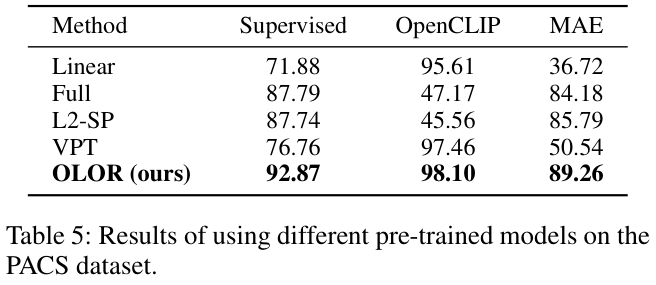
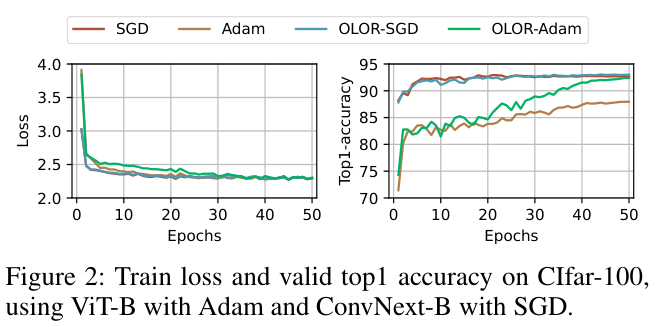
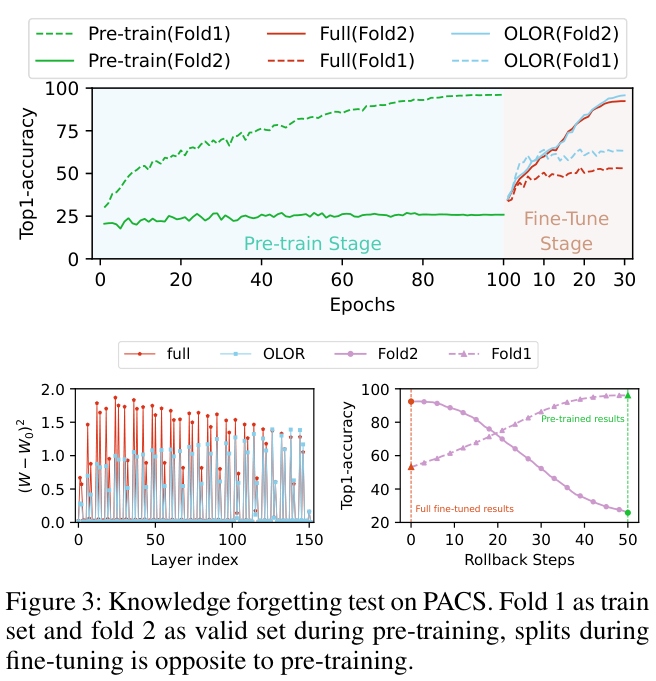

如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

OLOR:已开源,向预训练权值对齐的强正则化方法 | AAAI 2024的更多相关文章
- 因为相同类型的其他实体已具有相同的主键值。在使用 "Attach" 方法或者将实体的状态设置为 "Unchanged" 或 "Modified" 。。。
因为相同类型的其他实体已具有相同的主键值.在使用 "Attach" 方法或者将实体的状态设置为 "Unchanged" 或 "Modified&quo ...
- 关于Entity Framework更新的几种方式以及可能遇到的问题(附加类型“Model”的实体失败,因为相同类型的其他实体已具有相同的主键值)在使用 "Attach" 方法或者将实体的状态设置为 "Unchanged" 或 "Modified" 时如果图形中的任何实体具有冲突键值,则可能会发生上述行为
在日常使用Entity Framework中,数据更新通常会用到.下面就简单封装了一个DBContext类 public partial class EFContext<T> : DbCo ...
- 权值初始化 - Xavier和MSRA方法
设计好神经网络结构以及loss function 后,训练神经网络的步骤如下: 初始化权值参数 选择一个合适的梯度下降算法(例如:Adam,RMSprop等) 重复下面的迭代过程: 输入的正向传播 计 ...
- 附加类型“UniversalReviewSystem.Models.ApplicationUser”的实体失败,因为相同类型的其他实体已具有相同的主键值。在使用 "Attach" 方法或者将实体的状态设置为 "Unchanged" 或 "Modified" 时如果图形中的任何实体具有冲突键值
在使用asp.net Identity2 的 UserManager RoleManager 时,同时还有其他仓储类型接口,能实现用户扩展信息的修改,用户注册没有问题.当修改用户信息时,出现了如下异常 ...
- 附加类型的实体失败,因为相同类型的其他实体已具有相同的主键值。在使用 "Attach" 方法或者将实体的状态设置为 "Unchanged" 或 "Modified" 时如果图形中的任何实体具有冲突键值
var list= DAL.LoadEntities(x => x.OrderCode == orderCode).AsNoTracking().ToList().FirstOrDefault( ...
- 错误:因为相同类型的其他实体已具有相同的主键值。在使用 "Attach" 方法或者将实体的状态设置为 "Unchanged" 或 "Modified" 解决方法
在更新一个实体类的时候可能会有预先有一次查询或者其它操作,我们这样用目的是为了与提交的数据做一个比较之类的东西,如果先查询再对此类进行SaveChanges就会出错. 我们只要用AsNoTrackin ...
- 【中文版 | 论文原文】BERT:语言理解的深度双向变换器预训练
BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding 谷歌AI语言组论文<BERT:语言 ...
- 刷题总结——骑士的旅行(bzoj4336 树链剖分套权值线段树)
题目: Description 在一片古老的土地上,有一个繁荣的文明. 这片大地几乎被森林覆盖,有N座城坐落其中.巧合的是,这N座城由恰好N-1条双 向道路连接起来,使得任意两座城都是连通的.也就是说 ...
- 学习AI之NLP后对预训练语言模型——心得体会总结
一.学习NLP背景介绍: 从2019年4月份开始跟着华为云ModelArts实战营同学们一起进行了6期关于图像深度学习的学习,初步了解了关于图像标注.图像分类.物体检测,图像都目标物体检测等 ...
- NLP之预训练
内容是结合:https://zhuanlan.zhihu.com/p/49271699 可以直接看原文 预训练一般要从图像处理领域说起:可以先用某个训练集合比如训练集合A或者训练集合B对这个网络进行预 ...
随机推荐
- 流式响应Web小工具实践
作为一位拥有多年经验的老程序员,我对于提升Web应用性能和用户体验有些兴趣.今天,我要和大家聊聊一个非常实用的技术--流式响应(Streaming Response). 首先,流式响应到底是什么呢?简 ...
- .net core 5,6,7【多线程笔记】取消令牌(CancellationToken) CancellationTokenSource
介绍 在使用C#异步的场景,多多少少会接触到CancellationTokenSource.它和取消异步任务相关的,CancellationToken就是它生产出来的. 演示 任务取消执行回调 var ...
- 保姆教程系列:小白也能看懂的 Linux 挂载磁盘实操
!!!是的没错,胖友们,保姆教程系列又更新了!!! @ 目录 前言 简介 一.磁盘分区 二.文件系统 三.实际操作 1. 使用lsblk命令查看新加入的磁盘信息 2. 使用fdisk或者cfdisk分 ...
- pandas基础--基本功能
pandas含有是数据分析工作变得更快更简单的高级数据结构和操作工具,是基于numpy构建的. 本章节的代码引入pandas约定为:import pandas as pd,另外import numpy ...
- Vuex 4与状态管理实战指南
title: Vuex 4与状态管理实战指南 date: 2024/6/6 updated: 2024/6/6 excerpt: 这篇文章介绍了使用Vuex进行Vue应用状态管理的最佳实践,包括为何需 ...
- js字符串类型
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8 ...
- kettle从入门到精通 第五十二课 ETL之kettle Avro output
1.上一节课我们学习了avro input,本节课我们一起学习下avro out步骤. 本节课通过json input 加载json文件,通过avro out 生成avro二进制文件,写日志步骤打印日 ...
- OOP第一阶段题集总结
一.前言 知识点:数组,字符串的使用,链表,hashmap,泛型的使用,正则表达式的使用,类的设计,类与类之间的关系,单一职责. 题量:题目数量为5+4+3,数量适中,其中都是前几题较简单,最后一题较 ...
- 解决Vue中使用history路由模式出现404的问题
背景 vue中默认的路由模式是hash,会出现烦人的符号#,如http://127.0.0.1/#/. 改为history模式可以解决这个问题,但是有一个坑是:强刷新.回退等操作会出现404. Vue ...
- Linux增加系统调用(亲测成功)
我使用的操作系统是CentOS,其他的操作系统类似. 相关软件和Linux的基础操作这里不再赘述. 实验环境 VMWare Workstation.CentOS-7 实验步骤 ...