python Requests 库的使用
1. 介绍
对了解一些爬虫的基本理念,掌握爬虫爬取的流程有所帮助。入门之后,我们就需要学习一些更加高级的内容和工具来方便我们的爬取。那么这一节来简单介绍一下 requests 库的基本用法
参考文档:
https://github.com/kennethreitz/requests
https://www.runoob.com/python3/python-requests.html
2. 安装
利用 pip 安装
pip install requests
3. 基本请求
req = requests.get("http://www.baidu.com")
req = requests.post("http://www.baidu.com")
req = requests.put("http://www.baidu.com")
req = requests.delete("http://www.baidu.com")
req = requests.head("http://www.baidu.com")
req = requests.options("http://www.baidu.com")
3.1 get请求
参数是字典,我们也可以传递json类型的参数:
import requests
url = "http://www.baidu.com/s"
params = {'wd': '尚学堂'}
response = requests.get(url, params=params)
print(response.url)
response.encoding = 'utf-8'
html = response.text
# print(html)
# 导入 requests 包
import requests
# 发送请求
x = requests.get('https://www.runoob.com/')
# 返回 http 的状态码
print(x.status_code)
# 响应状态的描述
print(x.reason)
# 返回编码
print(x.apparent_encoding)
输出结果如下:
200
OK
utf-8
3.2 post请求
参数是字典,我们也可以传递json类型的参数:
import requests
from fake_useragent import UserAgent
headers = {
"User-Agent": UserAgent().chrome
}
login_url = "http://www.sxt.cn/index/login/login"
params = {
"user": "17703181473",
"password": "123456"
}
response = requests.post(login_url, headers=headers, data=params)
print(response.text)
d = {'user':'admin','password':'123456'}
r = requests.post(url='http://www.langzi.fun/admin.php',data=d)
3.3 自定义请求头部
伪装请求头部是采集时经常用的,我们可以用这个方法来隐藏:
headers = {'User-Agent': 'python'}
r = requests.get('http://www.zhidaow.com', headers = headers)
print(r.request.headers['User-Agent'])
import requests
from fake_useragent import UserAgent
headers = {
"User-Agent": UserAgent().chrome
}
url = "https://www.baidu.com/s"
params = {
"wd": "haimait.top"
}
response = requests.get(url, headers=headers, params=params)
print(response.text)
3.4 设置超时时间
可以通过timeout属性设置超时时间,一旦超过这个时间还没获得响应内容,就会提示错误
requests.get('http://github.com', timeout=0.001)
3.5 代理访问
采集时为避免被封IP,经常会使用代理。requests也有相应的proxies属性
import requests
proxies = {
"http": "http://10.10.1.10:3128",
"https": "https://10.10.1.10:1080",
}
requests.get("http://www.zhidaow.com", proxies=proxies)
from fake_useragent import UserAgent
import requests
url = "http://ip.3322.net/"
headers = {
"User-Agent": UserAgent().chrome
}
# https://www.89ip.cn/ 免费代理
proxies = {
# "http": "http://398707160:j8inhg2g@120.27.224.41:16818"
"http": "47.100.69.29:8888"
}
response = requests.get(url, headers=headers, proxies=proxies)
print(response.text)
如果代理需要账户和密码,则需这样
proxies = {
"http": "http://user:pass@10.10.1.10:3128/",
}
3.6 session自动保存cookies
seesion的意思是保持一个会话,比如 登陆后继续操作(记录身份信息) 而requests是单次请求的请求,身份信息不会被记录
# 创建一个session对象
s = requests.Session()
# 用session对象发出get请求,设置cookies
s.get('http://httpbin.org/cookies/set/sessioncookie/123456789')
from fake_useragent import UserAgent
import requests
session = requests.Session()
headers = {
"User-Agent": UserAgent().chrome
}
login_url = "http://www.sxt.cn/index/login/login"
params = {
"user": "17703181473",
"password": "123456"
}
response = session.post(login_url, headers=headers, data=params)
info_url = "http://www.sxt.cn/index/user.html"
resp = session.get(info_url, headers=headers)
print(resp.text)
3.7 ssl验证
# 禁用安全请求警告
requests.packages.urllib3.disable_warnings()
resp = requests.get(url, verify=False, headers=headers)
from fake_useragent import UserAgent
import requests
url = "https://www.12306.cn/mormhweb/"
headers = {
"User-Agent": UserAgent().chrome
}
# 关闭警告
requests.packages.urllib3.disable_warnings()
response = requests.get(url, verify=False, headers=headers)
response.encoding = "utf-8"
print(response.text)
3.8 上传文件
还可以上传文件,格式也需要是字典格式
files = {'file': open('report.xls', 'rb')}
r = requests.post(url='http://www.langzi.fun/upload', files=files)
如果上传极大的文件,需要使用requests toolbelt
参考文档 作者:安全研发 https://www.bilibili.com/read/cv12424194 出处:bilibili
3.9 requests请求返回内容 中文乱码问题
参考文档:
https://blog.csdn.net/qq_27629199/article/details/90170836
解决方法
- 自行设置
查看该网页的网页源代码,还以上面国家统计局的连接为例,搜索charset的编码。然后在代码中指定它的编码格式,重新打印相应内容的text,这次中文就不会乱码问题了。
在这里插入图片描述
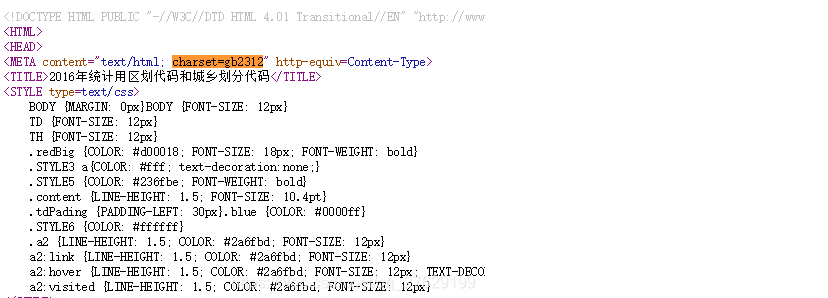
res = requests.get(url, headers = header)
res.encoding = ‘gb2312’
pritn(res.text)
- 利用apparent_encoding
res = requests.get(url, headers = header)
res.encoding = res.apparent_encoding
pritn(res.text)
- 已经爬好的带有\u5430的字符串怎么转为正常的中文显示字符串
python3: 字符串.encode(‘utf-8’).decode(‘unicode_escape’)
例:
res = requests.get(url, headers = header)
res.encoding = res.apparent_encoding
r.text.encode("utf-8").decode("unicode_escape")
4. 获取响应信息
| 代码 | 含义 |
|---|---|
| resp.json() | 获取响应内容(以json字符串) |
| resp.text | 获取响应内容 (以字符串) |
| resp.content | 获取响应内容(以字节的方式) |
| resp.headers | 获取响应头内容 |
| resp.url | 获取访问地址 |
| resp.encoding | 获取网页编码 |
| resp.request.headers | 请求头内容 |
| resp.cookie | 获取cookie |
5. 实例
实例一
步骤:
- 按行读规则文件
- 循环请求接口获取ip列表
- 结果写入文件
rule.txt
banner="Proxy-Agent: Privoxy" && country!="CN"
getip.py
import base64
import requests
import json
import time
def writeFile(fileName, q):
# s = 'banner="Blue Coat SG-S500"'
# print(fileName, q)
# query = q.replace('\n', '') + ' && after="2021-08-04" && country!="CN" && protocol="http"'
query = q.replace('\n', '')
print(fileName, query)
bytes_url = query.encode("utf-8")
str_url = base64.b64encode(bytes_url).decode() # base64 被编码的参数必须是二进制数据 5c79501f7e3f7ccda538e24c23f3cf64
url = 'https://ff.info/api/v1/search/all?email=XXXXXX@qq.com&key=XXXXX&qbase64=' + str_url + '&fields=host&full=true&size=10&page=1'
print("url:======>", url)
headers = {
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36 UOS'
}
r = requests.get(url, headers=headers, timeout=5)
r.encoding = "utf-8"
print(r.status_code, r)
if r.status_code != 200:
return
# print(json.encoder(r.content)) # {"error":false,"consumed_fpoint":0,"required_fpoints":0,"size":51594648,"page":1,"mode":"extended","query":"banner=\\\\\"basic\\\\\" \\\\u0026\\\\u0026 country!=\\\\\"CN\\\\\" \\\\u0026\\\\u0026 after=\\\\\"2021-07-26\\\\\"","results":["194.105.158.187:8607","https://169.62.186.218:2078","172.245.242.198:7777","https://173.236.13.157:2078","https://173.233.76.183:2078","194.107.125.88:8607","91.231.142.204:8607","185.111.157.103","188.119.115.142:8607","188.119.115.186:8607"]}
# 有 u0026 的字符串怎么转为正常的中文显示字符串
print(r.text.encode("utf-8").decode("unicode_escape")) # {"error":false,"consumed_fpoint":0,"required_fpoints":0,"size":51595423,"page":1,"mode":"extended","query":"banner="basic" && country!="CN" && after="2021-07-26"","results":["https://162.55.196.113:16044","https://45.136.154.78:16044","179.215.210.114:50777","175.110.100.168:8082","173.249.59.16:2077","172.255.81.19:7777","179.219.214.185:50777","https://173.254.43.33:2078","https://176.223.126.90:2078","196.189.192.4"]}
obj = json.loads(r.text) # 内容转json 对象
print(obj)
if obj["error"] != False:
return
if len(obj["results"])==0: # 判断数组的长度
return
print(obj["results"])
objUniq = list(dict.fromkeys(obj["results"])) # 用字典dict去重
print(objUniq) # objUniq ['115.240.154.32:554', '177.34.15.150:50777', 'https://179.188.17.117:2078', '188.119.115.87:8899', '173.254.59.173:2077', '168.151.243.50:55555', '179.158.162.124:50777', '173.236.22.100:2077', '173.243.16.34:8000', '172.245.66.121:7777']
# 写入xx.txt文件
with open(fileName, "w") as f: # 打开文件
for host in objUniq:
# 如果host 中包涵 : && 不包涵http 的写入文件 (只要ip地址)
if (':' in host) and (('http' in host) == False):
# print(host)
f.write(host) # 自带文件关闭功能,不需要再写f.close()
f.write("\n") # 自带文件关闭功能,不需要再写f.close()
with open("./proxy_rule.txt", "r") as f:
k = 0
# 按行读文件
for rule in f.readlines():
print(k, rule)
r = rule.rstrip('\n')
# r = rule.replace('\n', '')
if len(r) == 0:
k += 1
continue
k += 1
fileName = "res/" + str(k) + ".txt"
# print(fileName)
time.sleep(0.5)
writeFile(fileName, rule)
# s = 'banner="Blue Coat SG-S500"'
# write(s)
结果:
1.txt
121.173.29.19:8090
122.201.98.165:2079
118.27.116.109:60000
174.90.172.246:10000
179.215.29.115:50777
162.144.15.69:2079
193.135.13.129:9122
193.176.237.124:9122
实例二
gitIpInfo.py
# encoding:utf-8
# import base64
import json
import requests
import xlwt
import csv
def writeFile(fileName):
print(11111)
url = 'https://ff.so/api/v1/search/all?email=xxx@qq.com&key=xxxx&qbase64=ZG9tYWluPSJ3bS1tb3Rvci5jb20iIHx8IHRpdGxlPSLlqIHpqazmsb3ovaYiIHx8IHRpdGxlPSLlqIHpqazmmbrooYwiIHx8IGJvZHk9IuWogemprOaxvei9pueJiOadg%2BaJgOaciSIgfHwgYm9keT0iIFdNIE1vdG9yIEFsbCBSaWdodHMgUmVzZXJ2ZWQiIHx8IHRpdGxlPSJ2bS1tb3RvciIgfHwgdGl0bGU9IuWogemprOaZuumAoCIgfHwgYmFubmVyPSLlqIHpqazmsb3ovabniYjmnYPmiYDmnIkiICB8fCBiYW5uZXI9IiBXTSBNb3RvciBBbGwgUmlnaHRzIFJlc2VydmVkIiB8fCBiYW5uZXI9IuWogemprOaxvei9piIgfHwgYmFubmVyPSIgV00gTW90b3IgIiB8fCBiYW5uZXI9IuWogemprOaxvei9piIgfHwgYmFubmVyPSLlqIHpqazmmbrooYwiIHx8IGJhbm5lcj0iIFdNLU1vdG9yICIgfHwgdGl0bGU9Iua5luWMl%2BaYn%2BaZliIgfHwgYm9keT0i5rmW5YyX5pif5pmW54mI5p2D5omA5pyJIiB8fCBiYW5uZXI9Iua5luWMl%2BaYn%2BaZliIgfHwgdGl0bGU9IuWogemprOiejei1hCIgfHwgYmFubmVyPSLlqIHpqazono3otYQiIHx8IGRvbWFpbj0id20tbGVhc2UuY29tIiB8fCBkb21haW49IndtLW9hLmNvbSIgfHwgZG9tYWluPSJ3bW1vdG9ycy5jbiIgfHwgZG9tYWluPSJ3bS1pbW90b3IuY29tIiB8fCBiYW5uZXI9IndtLW1vdG9yLmNvbSIgfHwgYmFubmVyPSJ3bS1vYS5jb20iIHx8IGJvZHk9InNlcnZpY2VAd20tbW90b3IuY29tIiB8fCBib2R5PSI0MDA2LTk5OS02NjYi&fields=host,title,ip,domain,port,country,province,city,country_name,header,server,protocol,banner,cert,isp,as_number,as_organization,latitude,longitude,icp,fid,cname&&size=600&full=true'
headers = {
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36 UOS'
}
r = requests.get(url, headers=headers)
print(r)
obj = r.text
# obj = r.text["results"]
print(obj)
# obj = json.loads(r.text)
# print(obj["results"])
# objUniq = list(dict.fromkeys(obj["results"])) # 用字典dict去重
with open(fileName, "w") as f: # 打开文件
f.write(obj) # 自带文件关闭功能,不需要再写f.close()
f.write("\n") # 自带文件关闭功能,不需要再写f.close()
# writeFile('威马汽车.json')
def readFile2():
with open("威马汽车.json", "r", encoding='utf-8') as f:
results = ''
for data in f.readlines():
dataJson = json.loads(data)
results = dataJson['results']
titles = ["host", "title", "ip", "domain", "port", "country", "province", "city", "country_name", "header",
"server", "protocol", "banner", "cert", "isp", "as_number", "as_organization", "latitude", "longitude",
"icp", "fid", "cname"]
print(results[0])
# 创建一个workbook 设置编码
workbook = xlwt.Workbook(encoding='utf-8')
# 创建一个worksheet
worksheet = workbook.add_sheet('My Worksheet')
# 写入excel
for i in range(len(titles)):
# print(titles[i])
# 参数对应 行, 列, 值
worksheet.write(0, i, label=titles[i])
j = 1
for i in range(len(results)):
item = results[i]
for k in range(len(item)):
print(j, k, item[k])
# 参数对应 行, 列, 值
worksheet.write(j, k, label=item[k])
j += 1
# 保存
workbook.save('Excel_test.xls')
def readFile():
with open("威马汽车.json", "r") as f:
results = ''
for data in f.readlines():
dataJson = json.loads(data)
results = dataJson['results']
titles = ["host", "title", "ip", "domain", "port", "country", "province", "city", "country_name", "header",
"server", "protocol", "banner", "cert", "isp", "as_number", "as_organization", "latitude", "longitude",
"icp", "fid", "cname"]
print(results[0])
with open('001.csv', 'w', newline='', encoding='utf-8') as f: # newline=" "是为了避免写入之后有空行
ff = csv.writer(f)
ff.writerow(titles)
ff.writerows(results)
readFile2()
# s = 'banner="Blue Coat SG-S500"'
# write(s)
实例三
ip.txt
198.41.223.221
104.21.44.24
request_ip_rel.py
import requests
import json
def do_request(url):
response = requests.get(url)
if response.status_code == 200:
content = response.text
json_dict = json.loads(content)
return json_dict
else:
print("请求失败!")
def do_query(ip):
url = "http://192.168.1.244:7779/query/ip_basic?key=xxx&ip=%s" % ip
json_result = do_request(url)
if json_result['code'] != 200:
return {"ip": ip,
"country": "",
"country_code": "",
"region": "",
"city": "",
"asn": "",
"isp": "",
"org": ""}
country = json_result['data']['country'] if 'country' in json_result['data'] else ""
region = json_result['data']['province'] if 'province' in json_result['data'] else ""
city = json_result['data']['city'] if 'city' in json_result['data'] else ""
isp = json_result['data']['isp'] if 'isp' in json_result['data'] else ""
country_code = json_result['data']['country_code'] if 'country_code' in json_result['data'] else ""
return {"ip": ip,
"country": country,
"country_code": country_code,
"region": region,
"city": city,
"asn": "",
"isp": isp,
"org": ""}
if __name__ == '__main__':
file = "ip.txt"
result = list()
error_list = list()
count = 0
with open(file, 'r', encoding='utf-8') as in_file:
for line in in_file.readlines():
ip = line.strip('\n')
try:
result.append(do_query(ip))
print('finished ip #%d: %s' % (count, ip))
count += 1
if count > 3000:break
except:
error_list.append(ip)
print('error ip #%d: %s' % (count, ip))
with open('./out.json', 'w', encoding='utf-8') as out_file:
json.dump(result, out_file, ensure_ascii=False)
if error_list:
with open('./out_todo.txt', 'w', encoding='utf-8') as out_file:
out_file.writelines('\n'.join(error_list))
python Requests 库的使用的更多相关文章
- 大概看了一天python request源码。写下python requests库发送 get,post请求大概过程。
python requests库发送请求时,比如get请求,大概过程. 一.发起get请求过程:调用requests.get(url,**kwargs)-->request('get', url ...
- python requests库学习笔记(上)
尊重博客园原创精神,请勿转载! requests库官方使用手册地址:http://www.python-requests.org/en/master/:中文使用手册地址:http://cn.pytho ...
- Python——Requests库的开发者接口
本文介绍 Python Requests 库的开发者接口,主要内容包括: 目录 一.主要接口 1. requests.request() 2. requests.head().get().post() ...
- 使用python requests库写接口自动化测试--记录学习过程中遇到的坑(1)
一直听说python requests库对于接口自动化测试特别合适,但由于自身代码基础薄弱,一直没有实践: 这次赶上公司项目需要,同事小伙伴们一起学习写接口自动化脚本,听起来特别给力,赶紧实践一把: ...
- Python:requests库、BeautifulSoup4库的基本使用(实现简单的网络爬虫)
Python:requests库.BeautifulSoup4库的基本使用(实现简单的网络爬虫) 一.requests库的基本使用 requests是python语言编写的简单易用的HTTP库,使用起 ...
- Python requests库的使用(一)
requests库官方使用手册地址:http://www.python-requests.org/en/master/:中文使用手册地址:http://cn.python-requests.org/z ...
- Python Requests库:HTTP for Humans
Python标准库中用来处理HTTP的模块是urllib2,不过其中的API太零碎了,requests是更简单更人性化的第三方库. 用pip下载: pip install requests 或者git ...
- Python Requests库
背景 Requests is an elegant and simple HTTP library for Python, built for human beings. Requests是一个优雅简 ...
- python requests库学习笔记(下)
1.请求异常处理 请求异常类型: 请求超时处理(timeout): 实现代码: import requestsfrom requests import exceptions #引入exc ...
- python+requests库,接口自动化
1.requests库的使用 requests是python的一个HTTP客户端库,跟urllib,urllib2类似,那为什么要用requests而不用urllib2呢?官方文档中是这样说明的: “ ...
随机推荐
- 浅谈 KingbaseES 和 SQLServer 中的 instead of 触发器
本文基于Kingbase和SqlServer的INSTEAD OF 触发器主要功能特点进行对比浅析,同时针对SqlServer 的INSTEAD OF 触发器提出了多种kingbase环境的等价代码方 ...
- KingbaseES sys_restore 恢复表时默认不包括表上的索引
前言 最近碰到一个案例,在使用sys_restore恢复指定表时,默认不恢复表上的索引,如果想恢复需要单独指定. 测试过程 [](javascript:void(0) 查看表的有关属性:test=# ...
- arch 安装xfce
参照 https://www.cnblogs.com/3V4NZ/p/15330275.html 1.安装linux显示服务器 pacman -S xorg Xorg是一个开源的X Window系统的 ...
- SpringBoot配置启动页(首页)控制台打印项目访问入口url
一.SpringBootApplication 1 package com.reliable.yang; 2 3 /** 4 * @author Administrator 5 * @date 202 ...
- #二分,spfa#洛谷 1948 [USACO08JAN] Telephone Lines S
题目 分析 二分答案,设高于答案的边权为1,否则为0 然后如果最短路答案\(\leq k\)那么这个答案符合要求 代码 #include <cstdio> #include <cct ...
- 使用OHOS SDK构建mimalloc
参照OHOS IDE和SDK的安装方法配置好开发环境. 从github下载源码. 执行如下命令: git clone https://github.com/microsoft/mimalloc.git ...
- winrt新dx截图最小实现
转自:https://stackoverflow.co/questions/11283015 效果还是很不错的 #include <iostream> #include <Windo ...
- Nacos无法连接wsl2上部署的MySQL
情况描述 在部署Nacos时,需要连接MySQL数据库管理数据,但是如果连接的是wsl2上部署的MySQL,使用127.0.0.1或者localhost,通常会出现如下错误: org.springfr ...
- Deep Learning on Graphs: A Survey第五章自动编码论文总结
论文地址:https://arxiv.org/pdf/1812.04202.pdf 最近老师让我们读的一片论文,已经开组会讲完了,我负责的是第五章,图的自动编码,现在再总结一遍,便于后者研读.因为这篇 ...
- JavaScript如何判断一个元素是否在可视区域中?
一.用途 可视区域即我们浏览网页的设备肉眼可见的区域,如下图 在日常开发中,我们经常需要判断目标元素是否在视窗之内或者和视窗的距离小于一个值(例如 100 px),从而实现一些常用的功能,例如: 图片 ...