强化学习中atari游戏环境下帧的预处理操作
在网上找到一个Rainbow算法的代码(https://gitee.com/devilmaycry812839668/Rainbow),在里面找到了atari游戏环境下帧的预处理操作。
具体代码地址:
https://gitee.com/devilmaycry812839668/Rainbow/blob/master/env.py
# -*- coding: utf-8 -*-
from collections import deque
import random
import atari_py
import cv2
import torch class Env():
def __init__(self, args):
self.device = args.device
self.ale = atari_py.ALEInterface()
self.ale.setInt('random_seed', args.seed)
self.ale.setInt('max_num_frames_per_episode', args.max_episode_length)
self.ale.setFloat('repeat_action_probability', 0) # Disable sticky actions
self.ale.setInt('frame_skip', 0)
self.ale.setBool('color_averaging', False)
self.ale.loadROM(atari_py.get_game_path(args.game)) # ROM loading must be done after setting options
actions = self.ale.getMinimalActionSet()
self.actions = dict([i, e] for i, e in zip(range(len(actions)), actions))
self.lives = 0 # Life counter (used in DeepMind training)
self.life_termination = False # Used to check if resetting only from loss of life
self.window = args.history_length # Number of frames to concatenate
self.state_buffer = deque([], maxlen=args.history_length)
self.training = True # Consistent with model training mode def _get_state(self):
state = cv2.resize(self.ale.getScreenGrayscale(), (84, 84), interpolation=cv2.INTER_LINEAR)
return torch.tensor(state, dtype=torch.float32, device=self.device).div_(255) def _reset_buffer(self):
for _ in range(self.window):
self.state_buffer.append(torch.zeros(84, 84, device=self.device)) def reset(self):
if self.life_termination:
self.life_termination = False # Reset flag
self.ale.act(0) # Use a no-op after loss of life
else:
# Reset internals
self._reset_buffer()
self.ale.reset_game()
# Perform up to 30 random no-ops before starting
for _ in range(random.randrange(30)):
self.ale.act(0) # Assumes raw action 0 is always no-op
if self.ale.game_over():
self.ale.reset_game()
# Process and return "initial" state
observation = self._get_state()
self.state_buffer.append(observation)
self.lives = self.ale.lives()
return torch.stack(list(self.state_buffer), 0) def step(self, action):
# Repeat action 4 times, max pool over last 2 frames
frame_buffer = torch.zeros(2, 84, 84, device=self.device)
reward, done = 0, False
for t in range(4):
reward += self.ale.act(self.actions.get(action))
if t == 2:
frame_buffer[0] = self._get_state()
elif t == 3:
frame_buffer[1] = self._get_state()
done = self.ale.game_over()
if done:
break
observation = frame_buffer.max(0)[0]
self.state_buffer.append(observation)
# Detect loss of life as terminal in training mode
if self.training:
lives = self.ale.lives()
if lives < self.lives and lives > 0: # Lives > 0 for Q*bert
self.life_termination = not done # Only set flag when not truly done
done = True
self.lives = lives
# Return state, reward, done
return torch.stack(list(self.state_buffer), 0), reward, done # Uses loss of life as terminal signal
def train(self):
self.training = True # Uses standard terminal signal
def eval(self):
self.training = False def action_space(self):
return len(self.actions) def render(self):
cv2.imshow('screen', self.ale.getScreenRGB()[:, :, ::-1])
cv2.waitKey(1) def close(self):
cv2.destroyAllWindows()
该代码主要使用 atari_py 库实现游戏环境运行及图像的采集。
上面的代码为pytorch深度学习计算框架提供支持,同时可以经过适当的更改同样可以为TensorFlow等其他深度计算框架提供支持。
### 创建atari游戏环境的连接对象

### 为连接对象ale设置属性, 设置随机种子:random_seed ,每一个回合最多的帧个数(最多step数):max_num_frames_per_episode
### 执行动作传递给游戏环境时是否对上一个动作进行重复(迟滞动作):repeat_action_probability , frame_skip:是否跳帧(中间帧使用重复动作)

打印游戏路径:
atari_py.get_game_path(args.game)


为ale游戏连接对象加载游戏仿真环境的二进制文件:
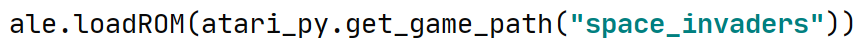
获得ale的灰度值图像:

将ale的RGB图像更改为BGR图像以使cv2进行显示:
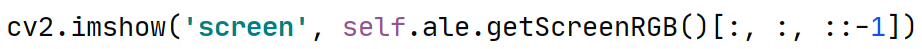
手动编写跳帧操作:
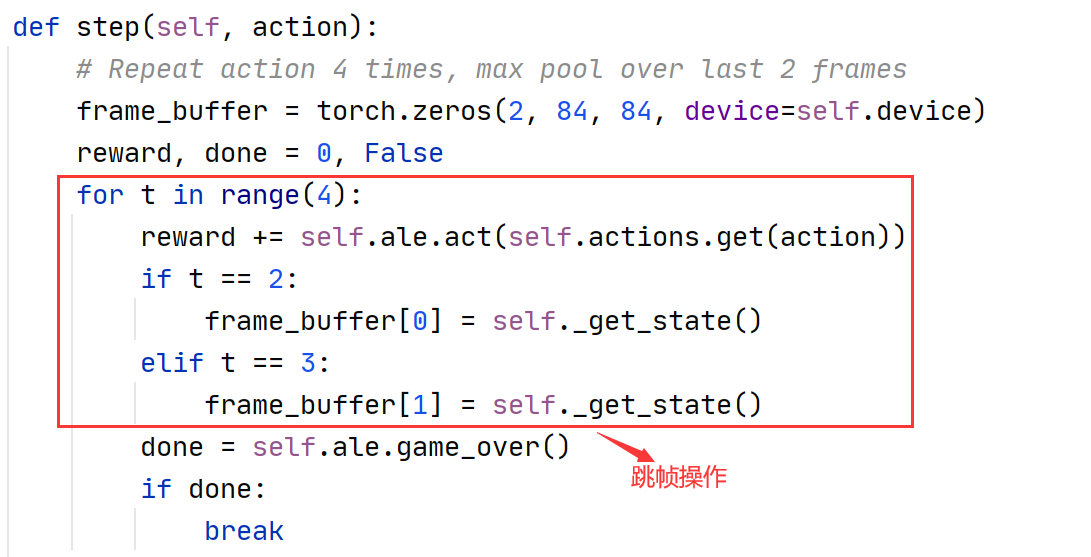
相邻两帧图像取最大值,避免图像闪烁问题:

对特殊游戏(一回合游戏有多条游戏生命数)设置 training 和 eval 两种模式, training模式下将每个生命数内的游戏帧提取为一个回合。

整体回合没有结束,但是部分回合结束(游戏生命数减少),使结束画面和开始画面连接:

游戏回合开始时进行一定步数的随机操作:

游戏回合内新生命数下游戏开始时进行随机操作,否则游戏游戏无法进行下一步操作:

扩展:
gym atari游戏的环境设置问题:Breakout-v0, Breakout-v4, BreakoutNoFrameskip-v4和BreakoutDeterministic-v4的区别
(https://www.cnblogs.com/devilmaycry812839668/p/14665402.html)
强化学习中atari游戏环境下帧的预处理操作的更多相关文章
- 强化学习实战 | 自定义Gym环境之井字棋
在文章 强化学习实战 | 自定义Gym环境 中 ,我们了解了一个简单的环境应该如何定义,并使用 print 简单地呈现了环境.在本文中,我们将学习自定义一个稍微复杂一点的环境--井字棋.回想一下井字棋 ...
- 强化学习实战 | 自定义Gym环境之扫雷
开始之前 先考虑几个问题: Q1:如何展开无雷区? Q2:如何计算格子的提示数? Q3:如何表示扫雷游戏的状态? A1:可以使用递归函数,或是堆栈. A2:一般的做法是,需要打开某格子时,再去统计周围 ...
- 强化学习中的无模型 基于值函数的 Q-Learning 和 Sarsa 学习
强化学习基础: 注: 在强化学习中 奖励函数和状态转移函数都是未知的,之所以有已知模型的强化学习解法是指使用采样估计的方式估计出奖励函数和状态转移函数,然后将强化学习问题转换为可以使用动态规划求解的 ...
- 深度强化学习中稀疏奖励问题Sparse Reward
Sparse Reward 推荐资料 <深度强化学习中稀疏奖励问题研究综述>1 李宏毅深度强化学习Sparse Reward4 强化学习算法在被引入深度神经网络后,对大量样本的需求更加 ...
- 强化学习中REIINFORCE算法和AC算法在算法理论和实际代码设计中的区别
背景就不介绍了,REINFORCE算法和AC算法是强化学习中基于策略这类的基础算法,这两个算法的算法描述(伪代码)参见Sutton的reinforcement introduction(2nd). A ...
- UNICODE环境下读写txt文件操作
内容转载自http://blog.sina.com.cn/s/blog_5d2bad130100t0x9.html UNICODE环境下读写txt文件操作 (2011-07-26 17:40:05) ...
- 强化学习中的经验回放(The Experience Replay in Reinforcement Learning)
一.Play it again: reactivation of waking experience and memory(Trends in Neurosciences 2010) SWR发放模式不 ...
- 强化学习实战 | 自定义Gym环境
新手的第一个强化学习示例一般都从Open Gym开始.在这些示例中,我们不断地向环境施加动作,并得到观测和奖励,这也是Gym Env的基本用法: state, reward, done, info = ...
- Go学习笔记(一):Ubuntu 环境下Go的安装
本文是根据<Go Web 编程>,逐步学习 Ubuntu 环境下go的安装的笔记. <Go Web 编程>的URL地址如下: https://github.com/astaxi ...
- 强化学习应用于游戏Tic-Tac-Toe
Tic-Tac-Toe游戏为3*3格子里轮流下棋,一方先有3子成直线的为赢家. 参考代码如下,我只删除了几个没用的地方: ####################################### ...
随机推荐
- 【Java异常】Variable used in lambda expression should be final or effectively final
[Java异常]Variable used in lambda expression should be final or effectively final 从字面上来理解这句话,意思是:*lamb ...
- http请求方式-HttpURLConnection
http请求方式-HttpURLConnection import com.alibaba.fastjson.JSON; import com.example.core.mydemo.http.Ord ...
- 【原创】EtherCAT主站IgH解析(二)-- Linux/Windows/RTOS等多操作系统IgH EtherCAT主站移植指南
版权声明:本文为本文为博主原创文章,转载请注明出处.如有问题,欢迎指正.博客地址:https://www.cnblogs.com/wsg1100/ 前言 目前,EtherCAT商用主站有:Aconti ...
- 09-Python模块
导入模块 通过import导入模块 import time #导入模块time time.sleep(50) #睡眠50s 导入模块并重命名 import time as t #导入模块time重命名 ...
- Linux系统的硬件信息
查看Linux系统的硬件信息 [1]查看内核信息 uname 用于显示系统的内核信息 option -s:显示内核名称 -r:显示内核版本 [root@bogon /]# uname -a Linux ...
- [翻译] PySide6.QtCore.Qt.ConnectionType
翻译 (自用,不保证对) PySide6.QtCore.Qt.ConnectionType 这个 enum 描述了 signals 和 slots 连接(connection) 的类型. 在一些特殊情 ...
- Idea 2020.1 编译SpringBoot项目Kotlin报错
导读 今天公司有个项目莫名其妙的运行不起来,提示Kotlin版本兼容问题,网上找到解决方案后,整理下来. 错误信息 Error:Kotlin: Module was compiled with an ...
- yb课堂 vue里面的状态管理vuex 《四十》
文档:https://vuex.vuejs.org/zh/ 在store/下index.js import Vue from 'vue' import Vuex from 'vuex' Vue.use ...
- 解决方案 | winrar 使用命令行解压到同名文件夹 (QTTabBar 中创建一个【解压文件】命令按钮的设置)
需求:我们经常需要把rar或者zip解压到当前文件夹,如果是直接解压的话可能会解压出来很多文件,事实上我们当然可以通过右键解压到这个指定文件夹. 但是 经过查询知道,如果是指定文件夹好说,直接指定.\ ...
- SQL常用数据过滤---IN操作符
在SQL中,IN操作符常用于过滤数据,允许在WHERE子句中指定多个可能的值.如果列中的值匹配IN操作符后面括号中的任何一个值,那么该行就会被选中. 以下是使用IN操作符的基本语法: SELECT c ...