再谈《强化学习算法之DQN算法中的经验池的实现》 experience_replay_buffer模块的实现
去年曾写过一篇DQN经验池模块编写的博文:
强化学习算法之DQN算法中的经验池的实现,experience_replay_buffer部分的实现
最近又看到了一个经验池实现的代码,把这两个实现做了一下对比:
memory.py 新的经验池实现代码:


import numpy as np Transition_dtype = np.dtype([
('timestep', np.int32),
('state', np.uint8, (84, 84)),
('action', np.uint8),
('reward', np.float32),
('nonterminal', np.bool_)]) blank_trans = (
0,
np.zeros((84, 84), dtype=np.uint8),
0,
0.0,
False) class ArrayMemory():
def __init__(self, size):
self.index = 0
self.size = size
self.full = False # Used to track actual capacity
# Build structured array
self.data = np.array(
[blank_trans] * size,
dtype=Transition_dtype) def append(self, sarst_data):
# Store data in underlying data structure
self.data[self.index] = sarst_data
self.index = (self.index + 1) % self.size # Update index
# Save when capacity reached
if self.index == 0:
self.full = True # Returns data given a data index
def get(self, data_index):
return self.data[data_index % self.size] def total(self):
if self.full:
return self.size
else:
return self.index class Replay():
def __init__(self, args):
self.transitions = ArrayMemory(args.memory_capacity) self.t = 0 # Internal episode timestep counter
self.n = 1 # td(0)
self.history_length = args.history_length
self.discount = args.discount
self.capacity = args.memory_capacity self.reward_n_step_scaling = np.array([self.discount ** i for i in range(self.n)]) def append(self, frame_data, action, reward, terminal):
""" Adds state and action at time t, reward and terminal at time t + 1 """
# Only store last frame and discretise to save memory
self.transitions.append((self.t, frame_data, action, reward, not terminal))
if terminal:
self.t = 0 # Start new episodes with t = 0
else:
self.t += 1 # Returns the transitions with blank states where appropriate
def _get_transitions(self, idxs):
transition_idxs = np.arange(-self.history_length + 1, self.n + 1) \
+ np.expand_dims(idxs, axis=1)
transitions = self.transitions.get(transition_idxs) transitions_firsts = transitions['timestep'] == 0
blank_mask = np.zeros_like(
transitions_firsts,
dtype=np.bool_) for t in range(self.history_length - 2, -1, -1): # e.g. 2 1 0
# True if future frame has timestep 0
blank_mask[:, t] = np.logical_or(
blank_mask[:, t + 1], transitions_firsts[:, t + 1]) for t in range(self.history_length, self.history_length + self.n): # e.g. 4 5 6
# True if current or past frame has timestep 0
blank_mask[:, t] = np.logical_or(
blank_mask[:, t - 1], transitions_firsts[:, t]) transitions[blank_mask] = blank_trans return transitions # Returns a batch of valid samples
def _get_samples(self, batch_size, n_total):
idxs = []
while len(idxs) < batch_size:
idx = np.random.randint(0, n_total - 1) # Uniformly sample
if (self.transitions.index - idx) % self.capacity >= self.n and \
(idx - self.transitions.index) % self.capacity >= self.history_length - 1:
idxs.append(idx) # Retrieve all required transition data (from t - h to t + n)
transitions = self._get_transitions(idxs) # Create un-discretised states and nth next states
all_states = transitions['state']
states = all_states[:, :self.history_length]
next_states = all_states[:, self.n:self.n + self.history_length] # Discrete actions to be used as index
actions = transitions['action'][:, self.history_length - 1] # Calculate truncated n-step discounted returns
rewards = transitions['reward'][:, self.history_length - 1: -1]
ret = np.matmul(rewards, self.reward_n_step_scaling) # Mask for non-terminal nth next states
nonterminals = transitions['nonterminal'][:, self.history_length + self.n - 1] return states, actions, ret, next_states, nonterminals def sample(self, batch_size):
n_total = self.transitions.total() states, actions, returns, next_states, nonterminals = \
self._get_samples(batch_size, n_total) # (np.uint8, (84, 84)), np.int32, np.float32, (np.uint8, (84, 84)), np.uint8
# s,a,r,s_next,non_terminal
return np.asarray(states, np.uint8), \
np.asarray(actions, np.int32), \
np.asarray(returns, np.float32), \
np.asarray(next_states, np.uint8), \
np.asarray(nonterminals, np.uint8)
原博文中给出的经验池实现代码:
mem.py
# encoding:UTF-8
"""Code from https://github.com/tambetm/simple_dqn/blob/master/src/replay_memory.py""" import random
import numpy as np class ReplayBuffer(object):
def __init__(self, config):
self.s = 0 self.cnn_format = config.cnn_format # buffer中数据的格式,'NCHW'或'NHWC'
self.buffer_size = config.replay_buffer_size # 缓存池的最大容量
self.history_length = config.history_length # 一个状态,state的历史数据长度
self.dims = (config.screen_height, config.screen_width) # 一帧图像的高、宽
self.batch_size = config.batch_size # mini_batch_size 大小
self.count = 0 # 当前缓存池中现有存储数据的大小
self.current = 0 # 指针指向的索引号,下一帧新数据存储的位置 """ expericence replay buffer 定义经验池 pre_state->a,r,s,terminal """
self.actions = np.empty(self.buffer_size, dtype=np.uint8)
self.rewards = np.empty(self.buffer_size, dtype=np.int8) # 这里我们设定reward为:0,+1,-1,三个种类
self.screens = np.empty((self.buffer_size, config.screen_height, config.screen_width), \
dtype=np.float32) # 设定屏幕截图汇总,states
self.terminals = np.empty(self.buffer_size, dtype=np.bool) # terminal对应同索引号的screen # pre-allocate prestates and poststates for minibatch
# 选择动作前的状态 s,a,s+1,中的状态s,当前状态
self.prestates = np.empty((self.batch_size, self.history_length) + self.dims, \
dtype=np.float32)
# 选择动作前的状态 s,a,s+1,中的状态s+1,下一状态
self.poststates = np.empty((self.batch_size, self.history_length) + self.dims, \
dtype=np.float32) # 判断设置是否正确
assert self.history_length >= 1 # history_length,状态state由几个图像组成,大小至少为1 def add(self, action, reward, screen, terminal):
""" 向experience buffer中加入新的a,r,s,terminal操作 """
assert screen.shape == self.dims # 判断传入的screen变量维度是否符合设定
# screen is post-state, after action and reward
# screen 是动作后的图像,前一状态执行动作action后获得reward,screen
# current指示当前的加入位置
self.actions[self.current] = action
self.rewards[self.current] = reward
self.screens[self.current, ...] = screen
self.terminals[self.current] = terminal
# experience buffer没有满时,current等于count,current自加一后赋值给count
# buffer满时,count等于buffer容量,固定不变,count=buffer_size, current自加一,进行指针平移
self.count = max(self.count, self.current + 1)
# 加入新值后,指针位置自动加一
self.current = (self.current + 1) % self.buffer_size # buffer_size经验池大小 def getState(self, index):
return self.screens[(index - (self.history_length - 1)):(index + 1), ...] def sample(self):
# memory must include poststate, prestate and history
assert self.count > self.history_length # history_length至少为1,由于要考虑前后两个状态所以count至少为2
# sample random indexes
indexes = []
while len(indexes) < self.batch_size:
# find random index
while True:
# sample one index (ignore states wraping over
index = random.randint(self.history_length, self.count - 1)
# if wraps over current pointer, then get new one
if index - self.history_length < self.current <= index:
continue
# if wraps over episode end, then get new one
# poststate (last screen) can be terminal state!
if self.terminals[(index - self.history_length):index].any():
self.s += 1
continue
# otherwise use this index
break # having index first is fastest in C-order matrices
self.prestates[len(indexes), ...] = self.getState(index - 1)
self.poststates[len(indexes), ...] = self.getState(index)
indexes.append(index) actions = self.actions[indexes]
rewards = self.rewards[indexes]
terminals = self.terminals[indexes] # return s,a,s,a+1,terminal
if self.cnn_format == 'NHWC':
return np.transpose(self.prestates, (0, 2, 3, 1)), actions, \
rewards, np.transpose(self.poststates, (0, 2, 3, 1)), terminals
else: # format is 'NCHW', faster than 'NHWC'
return self.prestates, actions, rewards, self.poststates, terminals
运行对比的代码:
speed.py
# encoding:UTF-8
import numpy as np
import time class Config(object):
def __init__(self):
self.cnn_format = "NCHW"
self.replay_buffer_size = 5*10000#100*10000
self.history_length= 4
self.screen_height = 84#100
self.screen_width = 84#100
self.batch_size = 32 self.memory_capacity = 5*10000#100*10000
self.discount = 0.1 config = Config() def last_year():
from mem import ReplayBuffer as ReplayBuffer_1
rf = ReplayBuffer_1(config) state = np.random.random([config.screen_height, config.screen_width])
action = np.uint8(0)
reward = np.int8(1) for i in range(5000*10000): #总步数
terminal =np.random.choice([True, False], size=1, p=[0.1, 0.9])[0]
rf.add(action, reward, state, terminal)
if rf.count >= 5*10000: # 开始抽样的步数
rf.sample()
if i%10000 == 0:
print(i)
if i == 5*10000:
a = time.time()
if i ==55*10000:
b = time.time()
break
print(b-a)
print(rf.s) def this_year():
from memory import Replay
rf = Replay(config) state = np.random.random([config.screen_height, config.screen_width])
action = np.uint8(0)
reward = np.int8(1) for i in range(5000 * 10000): # 总步数
terminal = np.random.choice([True, False], size=1, p=[0.1, 0.9])[0]
rf.append(state, action, reward, terminal)
if rf.transitions.total() >= 5 * 10000: # 开始抽样的步数
rf.sample(32)
if i % 10000 == 0:
print(i)
if i == 5 * 10000:
a = time.time()
if i == 55 * 10000:
b = time.time()
break
print(b - a) last_year()
this_year()
==============================
原博文的老的实现运行性能:
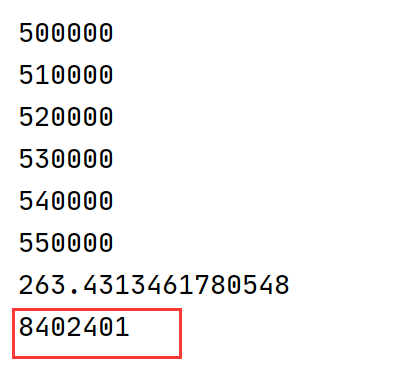
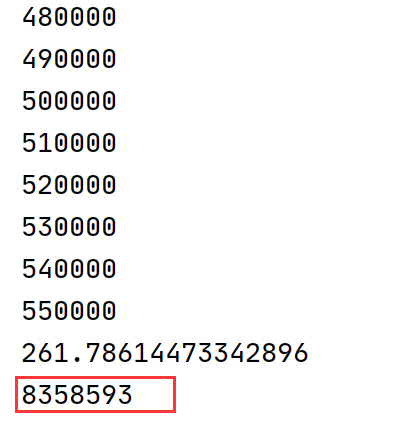

======================================
新的实现运行性能:

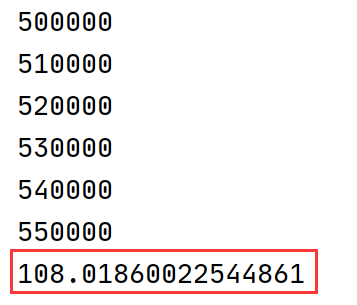
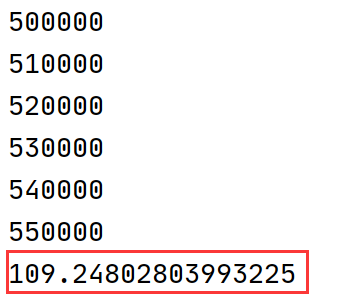
======================================
可以看到原实现代码需运行250秒,而新实现代码需运行100秒左右,这两个实现的区别主要在于抽样出的一个状态(4帧画面)之中如果有一个episode的起始帧该如何处理。
原实现中对于一个抽样状态(4帧)中有episode起始帧时就放弃掉这个状态重新选择,而新实现中对该种情况进行处理而不是放弃这个抽样状态。
原始实现代码中50万次的成功抽样是从大约830万+50万=880万中进行的,可以看到原始实现代码中失败的次数是成功抽样次数的十多倍,由于有过多的失败抽样所以原实现代码性能要慢1.5倍。
分析后我们知道关键的区别在于对于抽样状态中有episode起始帧的情况是否应该放弃重新抽样,如果像原始实现中放弃后重新抽样虽然会损耗掉一点性能但是抽样质量较高,而且对于十几小时甚至几十小时的总运行时间多运行3分钟的抽样其实对于总的运行性能影响不大。新实现的代码虽然可以提高一丢丢的运行性能但是抽样的样本质量会差于原实现代码,因此总的分析下来还是原实现代码更为好一些。
==================================
运行硬件CPU:intel 10700k
==================================
以上这两个实现对于边界条件并不是很严格,对此又修订了一版本,采用对state状态中有episode起始帧的情况进行放弃重新抽样:
# encoding:UTF-8
"""Code from https://github.com/tambetm/simple_dqn/blob/master/src/replay_memory.py""" import random
import numpy as np class ReplayBuffer(object):
def __init__(self, args):
self.capacity = args.buffer_capacity # 缓存池的总容量
self.dims = (args.screen_height, args.screen_width) # 一帧图像的高、宽
self.history_length = args.history_length # 一个状态,state的历史数据长度
self.n = args.multi_steps # multi steps 步数
self.discount = args.discount # reward的折扣率
# 判断设置是否正确
assert self.history_length >= 1 # history_length,状态state由几帧图像组成,大小至少为1
assert self.n >= 1 self.index = 0 # 指针指向的索引号,下一帧数据插入的位置
self.total = 0 # buffer中已填充的个数
self.reward_n_step_scaling = np.array([self.discount ** i for i in range(self.n)]) """ replay buffer 定义经验池 s,a,r,s_next,terminal """
self.states = np.empty((self.capacity,) + self.dims, dtype=np.uint8)
self.actions = np.empty(self.capacity, dtype=np.uint8)
self.rewards = np.empty(self.capacity, dtype=np.float32)
self.non_terminals = np.empty(self.capacity, dtype=np.uint8) def append(self, state, action, reward, terminal):
assert state.shape == self.dims # 判断传入的游戏画面维度是否符合设定
self.states[self.index, ...] = state
self.actions[self.index] = action
self.rewards[self.index] = reward
self.non_terminals[self.index] = not terminal self.total = max(self.total, self.index + 1) # 当前buffer中现有存储数据的大小
# 加入新值后,指针位置自动加一
self.index = (self.index + 1) % self.capacity def _get_samples(self, index_array):
all_states = self.states[index_array, ...]
all_actions = self.actions[index_array]
all_rewards = self.rewards[index_array]
all_non_terminals = self.non_terminals[index_array] ### s, s_next
states = all_states[:, :self.history_length, ...]
next_states = all_states[:, self.n:self.n + self.history_length, ...] ### a
actions = all_actions[:, self.history_length - 1]
actions = np.asarray(actions, dtype=np.int32) ### r
_rewards = all_rewards[:, self.history_length - 1: -1]
rewards = np.matmul(_rewards, self.reward_n_step_scaling) ### non_terminals
non_terminals = all_non_terminals[:, self.history_length + self.n - 1] return states, actions, rewards, next_states, non_terminals def sample(self, batch_size):
assert self.total > self.history_length + self.n # 最小容量大于一次抽样的数据大小
# sample random indexes
idxes = [] if self.total == self.capacity: ### full
while len(idxes) < batch_size:
idx = random.randint(0, self.capacity - 1)
if (self.index - idx) % self.capacity > self.n and \
(idx - self.index) % self.capacity >= self.history_length - 1:
ab = np.arange(idx - self.history_length + 1, idx + self.n + 1) % self.capacity
cd = ab[:-1]
if np.any(self.non_terminals[cd] == 0):
continue
else:
idxes.append(ab)
else: ### not full
while len(idxes) < batch_size:
idx = random.randint(self.history_length - 1, self.index - 1 - self.n)
ab = np.arange(idx - self.history_length + 1, idx + self.n + 1)
cd = ab[:-1]
if np.any(self.non_terminals[cd] == 0):
continue
else:
idxes.append(ab) idxes = np.asarray(idxes) return self._get_samples(idxes)
运行性能:

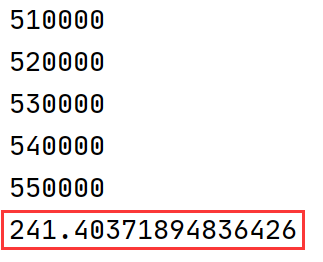
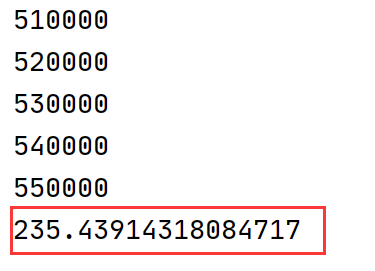
可以看到性能得到保持,但是修改版对边界条件有了更好的判断,该修订版作为DQN的experience buffer的最新推荐实践版本。
再谈《强化学习算法之DQN算法中的经验池的实现》 experience_replay_buffer模块的实现的更多相关文章
- 【论文研读】强化学习入门之DQN
最近在学习斯坦福2017年秋季学期的<强化学习>课程,感兴趣的同学可以follow一下,Sergey大神的,有英文字幕,语速有点快,适合有一些基础的入门生. 今天主要总结上午看的有关DQN ...
- 再谈MFC学习——模态对话框的数据传递
学习c++的目的就是为了使用封装好的类.而最最经典的封装类当然是微软的MFC窗体程序类. 学习MFC编程之前要学习c++的主要知识,掌握c++的基本编程思想. 以下就看下我学习的MFC模态对话框的数据 ...
- android开发学习 ------- 【转】 android中的线程池
线程很常见 , https://blog.csdn.net/seu_calvin/article/details/52415337 参考,保证能看懂.
- 【强化学习】DQN 算法改进
DQN 算法改进 (一)Dueling DQN Dueling DQN 是一种基于 DQN 的改进算法.主要突破点:利用模型结构将值函数表示成更加细致的形式,这使得模型能够拥有更好的表现.下面给出公式 ...
- 强化学习(Reinforcement Learning)中的Q-Learning、DQN,面试看这篇就够了!
1. 什么是强化学习 其他许多机器学习算法中学习器都是学得怎样做,而强化学习(Reinforcement Learning, RL)是在尝试的过程中学习到在特定的情境下选择哪种行动可以得到最大的回报. ...
- 强化学习系列之:Deep Q Network (DQN)
文章目录 [隐藏] 1. 强化学习和深度学习结合 2. Deep Q Network (DQN) 算法 3. 后续发展 3.1 Double DQN 3.2 Prioritized Replay 3. ...
- DQN(Deep Q-learning)入门教程(一)之强化学习介绍
什么是强化学习? 强化学习(Reinforcement learning,简称RL)是和监督学习,非监督学习并列的第三种机器学习方法,如下图示: 首先让我们举一个小时候的例子: 你现在在家,有两个动作 ...
- 【转】强化学习(一)Deep Q-Network
原文地址:https://www.hhyz.me/2018/08/05/2018-08-05-RL/ 1. 前言 虽然将深度学习和增强学习结合的想法在几年前就有人尝试,但真正成功的开端就是DeepMi ...
- 基于Keras的OpenAI-gym强化学习的车杆/FlappyBird游戏
强化学习 课程:Q-Learning强化学习(李宏毅).深度强化学习 强化学习是一种允许你创造能从环境中交互学习的AI Agent的机器学习算法,其通过试错来学习.如上图所示,大脑代表AI Agent ...
- Flink + 强化学习 搭建实时推荐系统
如今的推荐系统,对于实时性的要求越来越高,实时推荐的流程大致可以概括为这样: 推荐系统对于用户的请求产生推荐,用户对推荐结果作出反馈 (购买/点击/离开等等),推荐系统再根据用户反馈作出新的推荐.这个 ...
随机推荐
- 夜莺监控(Nightingale)上线内置指标功能
Prometheus 生态里如果要查询数据,需要编写 promql,对于普通用户来说,门槛有点高.通常有两种解法,一个是通过 AI 的手段做翻译,你用大白话跟 AI 提出你的诉求,让 AI 帮你写 p ...
- 正式开启全站HTTPS加密之旅
Tips:当你看到这个提示的时候,说明当前的文章是由原emlog博客系统搬迁至此的,文章发布时间已过于久远,编排和内容不一定完整,还请谅解` 正式开启全站HTTPS加密之旅 日期:2017-7-14 ...
- resttemplate调用
Map<String, Object> queryForHttp(String url, Map<String, Object> header, Map<String, ...
- mysql这个垃圾迁移数据费劲半天
mysql垃圾得很! 对于一些小系统还可以.大型系统自己找麻烦--必须有高昂的人工费! 没有高昂的人工(必须有好的程序员和工程师才能解决一些复杂的问题),构建基于大量数据的应用,非常麻烦. 而这些费 ...
- 08-Linux计划任务
什么是计划任务 周期性或者定时执行某个命令或者脚本. crontab 安装 yum install crontabs #安装crontabs systemctl enable crond #开机启动 ...
- dig 命令详解及使用示例
一.背景知识 CNAME CNAME 是 Canonical Name 的缩写,它是 DNS(域名系统)记录的一种类型.CNAME 记录用于将一个域名映射(别名)到另一个域名.换句话说,当你访问一个设 ...
- Vue2 整理(二):核心篇(组件化开发)
前言 上一篇连接:vue2 整理:基础篇. 组件化开发 组件概念 组件,对于学Java的人来说的话,这个词所要表达的意思再熟悉不过了. 所谓组件就是:面向对象中的抽象.封装思想:而所谓的组件化就是:把 ...
- 手把手教你解决spring boot导入swagger2版本冲突问题,刘老师教编程
手把手教你解决spring boot导入swagger2版本冲突问题 本文仅为个人理解,欢迎大家批评指错 首先Spring Boot 3 和 Swagger 2 不兼容.在 Spring Boot 3 ...
- ELK Stack - Elasticsearch · 搜索引擎 · 部署应用 · 内部结构 · 倒排索引 · 服务接入
系列目录 ELK Stack - Elasticsearch · 搜索引擎 · 全文检索 · 部署应用 · 内部结构 · 倒排索引 · 服务接入 ELK Stack - Kibana (待续) ELK ...
- 内部网关协议RIP
RIP协议的特点:仅和相邻路由器交换信息:交换自己现在的路由表:按固定的时间周期. 对每一个相邻路由器发送的RIP报文,执行以下步骤: 1.对地址为x的相邻路由器发来的报文,修改此报文中的所有项目,把 ...