推荐系统[三]:粗排算法常用模型汇总(集合选择和精准预估),技术发展历史(向量內积,Wide&Deep等模型)以及前沿技术
1.前言:召回排序流程策略算法简介
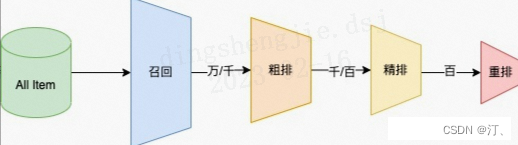
推荐可分为以下四个流程,分别是召回、粗排、精排以及重排:
- 召回是源头,在某种意义上决定着整个推荐的天花板;
- 粗排是初筛,一般不会上复杂模型;
- 精排是整个推荐环节的重中之重,在特征和模型上都会做的比较复杂;
- 重排,一般是做打散或满足业务运营的特定强插需求,同样不会使用复杂模型;
召回层:召回解决的是从海量候选item中召回千级别的item问题
- 统计类,热度,LBS;
- 协同过滤类,UserCF、ItemCF;
- U2T2I,如基于user tag召回;
- I2I类,如Embedding(Word2Vec、FastText),GraphEmbedding(Node2Vec、DeepWalk、EGES);
- U2I类,如DSSM、YouTube DNN、Sentence Bert;
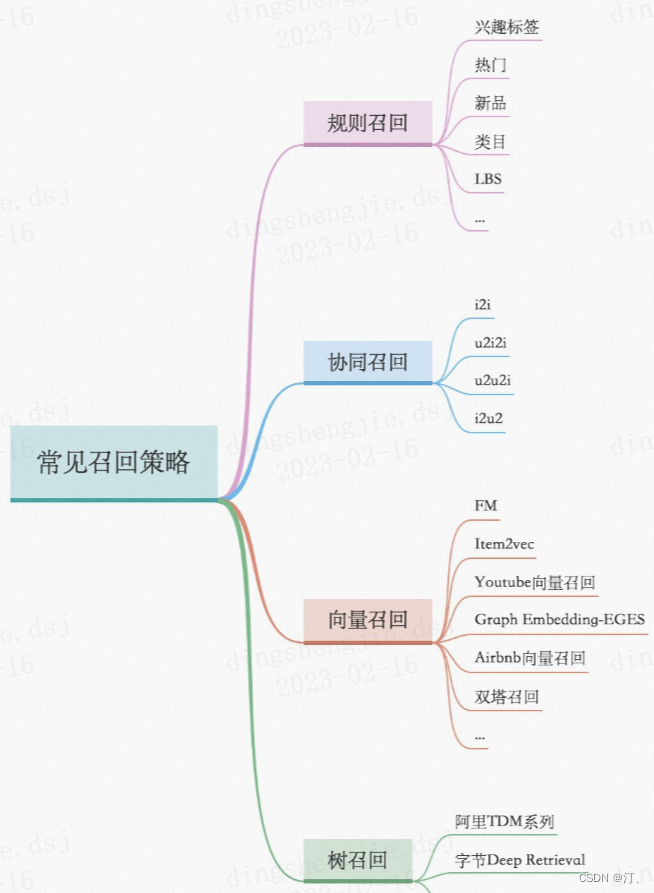
模型类:模型类的模式是将用户和item分别映射到一个向量空间,然后用向量召回,这类有itemcf,usercf,embedding(word2vec),Graph embedding(node2vec等),DNN(如DSSM双塔召回,YouTubeDNN等),RNN(预测下一个点击的item得到用户emb和item emb);向量检索可以用Annoy(基于LSH),Faiss(基于矢量量化)。此外还见过用逻辑回归搞个预估模型,把权重大的交叉特征拿出来构建索引做召回
排序策略,learning to rank 流程三大模式(pointwise、pairwise、listwise),主要是特征工程和CTR模型预估;
- 粗排层:本质上跟精排类似,只是特征和模型复杂度上会精简,此外也有将精排模型通过蒸馏得到简化版模型来做粗排
- 常见的特征挖掘(user、item、context,以及相互交叉);
- 精排层:精排解决的是从千级别item到几十这个级别的问题
- CTR预估:lr,gbdt,fm及其变种(fm是一个工程团队不太强又对算法精度有一定要求时比较好的选择),widedeep,deepfm,NCF各种交叉,DIN,BERT,RNN
- 多目标:MOE,MMOE,MTL(多任务学习)
- 打分公式融合: 随机搜索,CEM(性价比比较高的方法),在线贝叶斯优化(高斯过程),带模型CEM,强化学习等
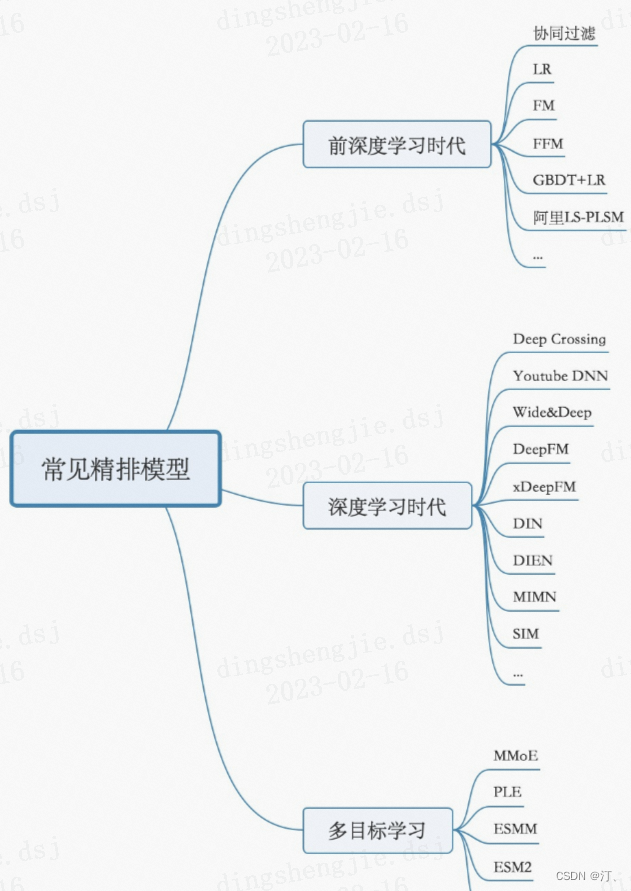
- 粗排层:本质上跟精排类似,只是特征和模型复杂度上会精简,此外也有将精排模型通过蒸馏得到简化版模型来做粗排
重排层:重排层解决的是展示列表总体最优,模型有 MMR,DPP,RNN系列(参考阿里的globalrerank系列)
展示层:
- 推荐理由:统计规则、行为规则、抽取式(一般从评论和内容中抽取)、生成式;排序可以用汤普森采样(简单有效),融合到精排模型排等等
- 首图优选:CNN抽特征,汤普森采样
探索与利用:随机策略(简单有效),汤普森采样,bandit,强化学习(Q-Learning、DQN)等
产品层:交互式推荐、分tab、多种类型物料融合
2.粗排
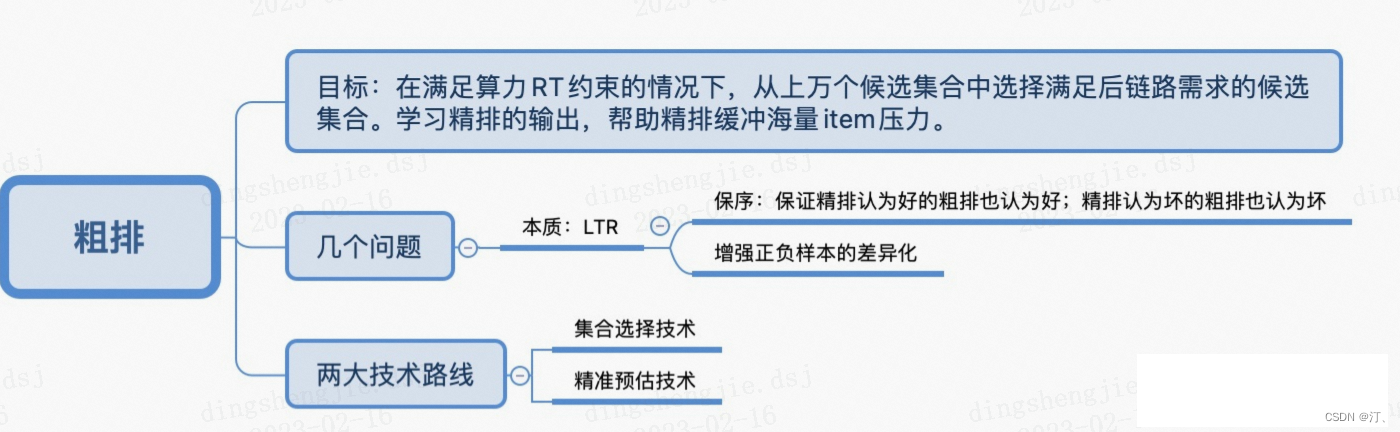
在搜索、推荐、广告等需要进行大规模排序的场景,级联排序架构得到了非常广泛的应用。以在线广告系统为例,按顺序一般包含召回、粗排、精排、重排等模块。粗排在召回和精排之间,一般需要从上万个广告集合中选择出几百个符合后链路目标的候选广告,并送给后面的精排模块。粗排有很严格的时间要求,一般需要在10~20ms内完成打分。在如此巨大的打分量以及如此严格的RT需求下,粗排是如何平衡算力、RT以及最后的打分效果呢?
2.1 粗排的发展历史
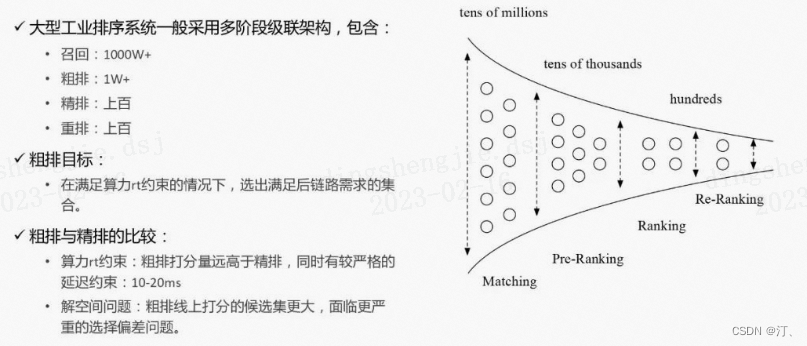
粗排和精排有两点不同:
算力和RT的约束更严格:粗排的打分量远高于精排,同时有更严格的延迟约束,阿里巴巴定向广告的要求是10-20ms
解空间问题更严重:粗排和精排训练的时候使用的都是展现样本,但是线上打分环节粗排打分候选集更大,打分阶段距离展现环节更远,因此粗排阶段打分集合的分布和展现集合差距相比精排更大,解空间问题也更严重。
2.1.1 粗排的两大技术路线(集合选择和精准预估)
粗排的技术路线其实就是解决粗排一般该怎么迭代的问题,由于粗排是处于召回和精排之间的一个模块,因此粗排本身的迭代会受到前后链路的制约,因此需要站在整个链路的视角来看待这个问题。纵观整个链路,粗排一般存在两种技术路线:集合选择和精准值预估。

集合选择技术
集合选择技术是以集合为建模目标,选出满足后续链路需求的集合的方法,该技术路线在召回非常典型,这其实也非常符合粗排的定位。该方法优点是算力消耗一般比较少,缺点是依赖于对后链路的学习,可控性较弱。
什么叫可控性?也就是说如果希望进行一些调整的话,由于这种方式依赖于通过数据回流对后链路进行学习,而数据回流往往比较慢,同时对数据量也有要求,可能需要后面链路的这些策略调整影响到比较大的流量之后,粗排才可以学习到,因此这种方式可控性比较弱,是偏被动的一种方式。
这种技术路线有以下常见的几种方法:
多通道方法:类似于召回,针对不同的目标构建不同的通道,然后分别选出不同的集合,然后再进行合并选择。
Listwise方法:一般是直接建模集合的损失,典型算法如LamdaMART。为了更好理解listwise算法,这里提一下pointwise算法和pairwise算法,pointwise算法一般是点估计的方式,训练过程只考虑单条样本;而pairwise算法训练过程中会考虑当前样本和其它样本的相互关系,会构造这样的pair,并在训练的过程中引入这方面的pairwise loss,训练目标可能是正pair排在负pair的前面;Listwise更近一步,在训练的时候会考虑整个集合,会希望整个集合的指标如NDCG等达到最大化,如LamdaMART算法。
序列生成方法:直接做集合选择。一般包含集合评估器和集合生成器,算法过程如下:首先,用评估器对所有的item进行打分并选择一个得分最高的,作为集合中的第一个商品。接下来,再挑选第二个商品,把第一个商品和所有可能的第二个商品进行组合,并用评估器进行打分。之后,选择得分最高的集合,并持续使用类似于贪心的方式不断的搜索,最终得到一个最优的集合。
精准值预估技术
精准值预估技术直接对最终系统目标进行精确值预估,其实也就是pointwise的方式。以广告系统为例,建模的目标一般是ECPM,即
$ECPM=pCTR*bid$
pCTR是广告点击率预估,ECPM:EFFECPM:EFFECTIVE COST Per
Mille,每1000次展览可用的广告收入,ECPM是流量端,媒体角度,Bid Request【竞价请求】
利用预估技术预估pCTR,然后预估bid,最终根据ECPM来进行排序,在粗排的话就是取排序的分最高的topK作为最终的集合。这种方式的优点是可控性强,因为是直接对整个目标进行建模,如果建模方式做了调整的话,可以直接调整排序公式,调整预估模型,对整个链路的掌控力更强。缺点就是算力消耗比较大,而且预估越准确,算力消耗也越大。
2.1.2 粗排的技术发展历史(向量內积,Wide&Deep等模型)
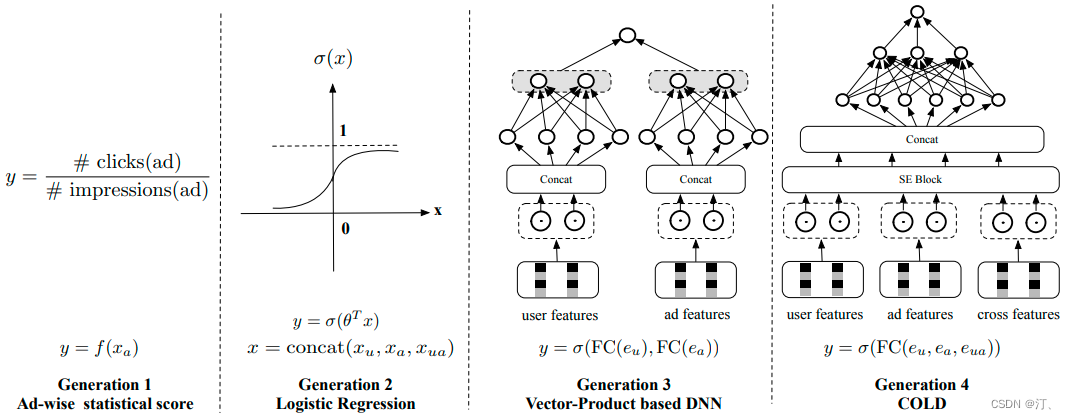
粗排在工业界的发展历程可以分成下面几个阶段:
① 最早期的第一代粗排是静态质量分,一般是统计广告的历史平均CTR,只使用了广告侧的信息,表达能力有限,但是更新上可以做到很快。
② 第二代粗排是以LR为代表的早期机器学习模型,模型结构比较简单,有一定的个性化表达能力,可以在线更新和服务。
其中①②可以合称为“粗排的前深度学习时代(2016年以前)”。
③ 当前应用最广泛的第三代粗排模型,是基于向量内积的深度模型。一般为双塔结构,两侧分别输入用户特征和广告特征,经过深度网络计算后,分别产出用户向量和广告向量,再通过内积等运算计算得到排序分数,③ 称为“粗排的深度时代-向量内积模型(2016)”。
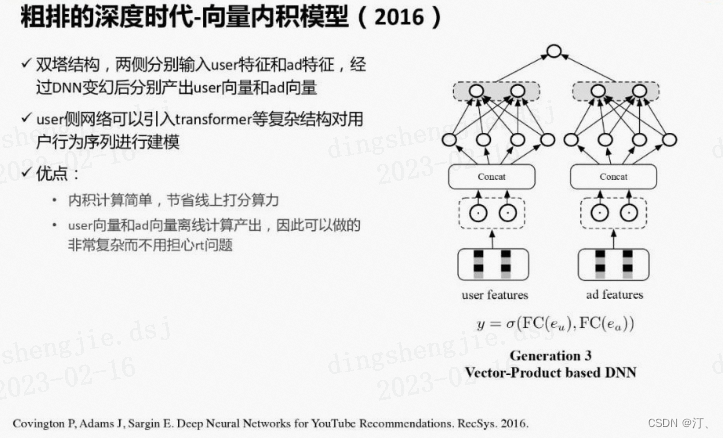
向量内积模型相比之前的粗排模型,表达能力有了很显著的提升,其优点:
内积计算简单,节省线上打分算力
User向量和Ad向量离线计算产出,因此可以做的非常复杂而不用担心在线RT问题
双塔结构的user侧网络可以引入transformer等复杂结构对用户行为序列进行建模

然而仍然有许多问题:
模型表达能力仍然受限:向量内积虽然极大的提升了运算速度,节省了算力,但是也导致了模型无法使用交叉特征,能力受到极大限制。
模型实时性较差:因为用户向量和广告向量一般需要提前计算好,而这种提前计算的时间会拖慢整个系统的更新速度,导致系统难以对数据分布的快速变化做出及时响应,这个问题在双十一等场景尤为明显。
存在冷启动问题,对新广告、新用户不友好
迭代效率:user向量和item向量的版本同步影响迭代效率。因为每次迭代一个新版本的模型,分别要把相应user和item向量产出,其本身迭代流程就非常长,尤其是对于一个比较大型的系统来说,如果把user和item都做到了上亿的这种级别的话,可能需要一天才能把这些产出更新到线上,这种迭代效率很低。
针对向量内积模型的问题,也有很多相关的改进,典型的如下面这个方法。
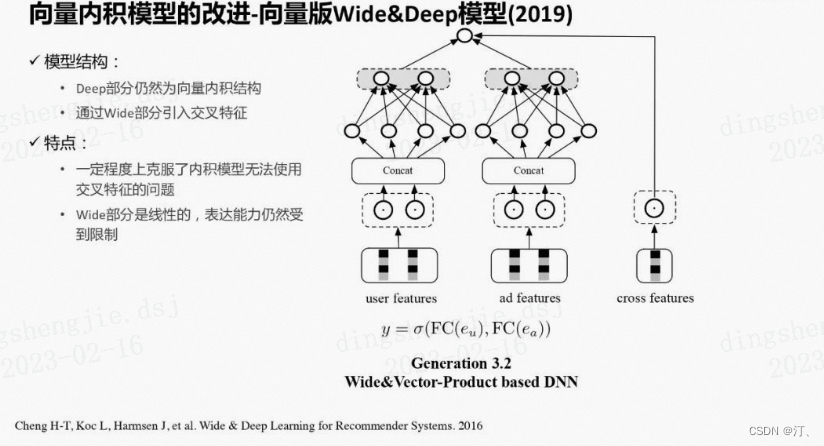
另外一个典型的改进方法是向量内积模型的实时化, user向量通过线上打分实时产出,ad向量仍然离线产出,但是更新频次增加。
通过实时打分,可以引入实时特征,实时性加强。然而实时打分使向量内积模型的RT和算力优势减弱,user模型处于RT的约束不能设计的很复杂,而且该方法还引入了新的打分模型和ad向量版本不一致的问题。
④第四代COLD,下一代粗排框架(2019)-算力感知的在线轻量级的深度粗排系统。下面将详细介绍该模型。
2.2 粗排的最新进展COLD(框架)
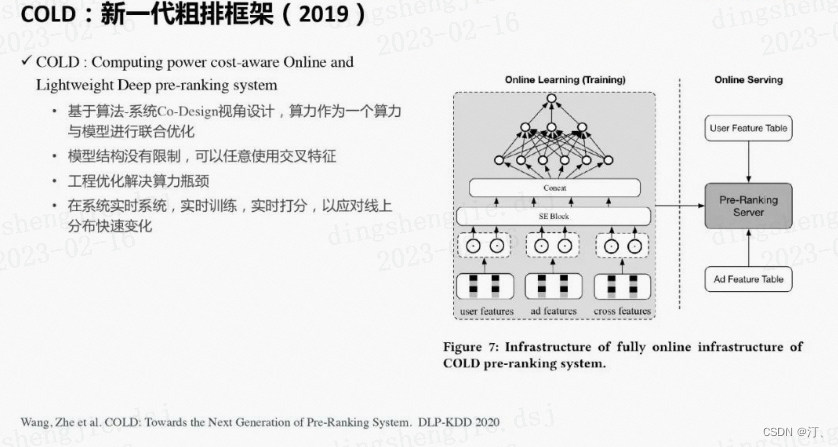
前面粗排的相关工作仅仅把算力看做系统的一个常量,模型和算力的优化是分离的。这里重新思考了模型和算力的关系,从两者联合设计优化的视角出发,提出了新一代的粗排架构COLD ( Computing power cost-aware Online and Lightweight Deep pre-ranking system )。它可以灵活地对模型效果和算力进行平衡。COLD没有对模型结构进行限制,可以支持任意复杂的深度模型。这里我们把GwEN ( group-wise embedding network ) 作为我们的初始模型结构。它以拼接好的特征embedding作为输入,后面是多层全连接网络,支持交叉特征。当然,如果特征和模型过于复杂,算力和延时都会难以接受。因此我们一方面设计了一个灵活的网络架构可以进行效果和算力的平衡。另一方面进行了很多工程上的优化以节省算力。
总结为以下几点:
基于算法-系统Co-Design视角设计,算力作为一个变量与模型进行联合优化
模型结构没有限制,可以任意使用交叉特征
工程优化解决算力瓶颈
在线实时系统,实时训练,实时打分,以应对线上分布快速变化
2.2.1模型结构
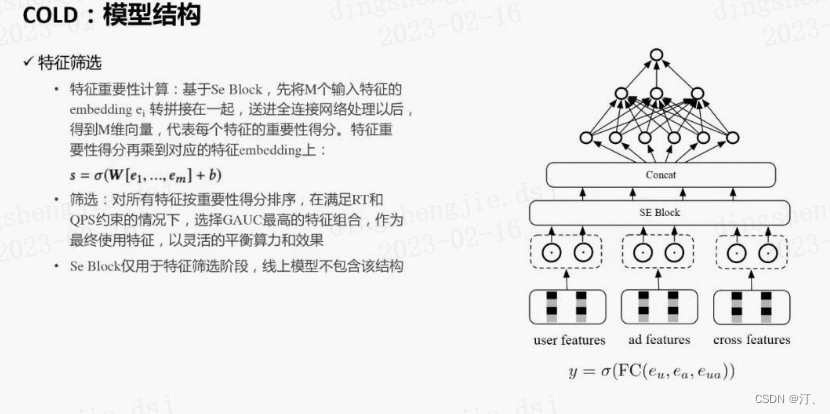
① 特征筛选
精简网络的方法有很多,例如网络剪枝 ( network pruning)、特征筛选 ( feature selection)、网络结构搜索 ( neural architecture search)等。我们选择了特征筛选以实现效果和算力的平衡,当然其他技术也可以进行尝试。具体来说,我们把SE (Squeeze-and-Excitation) block引入到了特征筛选过程中,它最初被用于计算机视觉领域以便对不同通道间的内部关系进行建模。这里我们用SE block来得到特征重要性分数。假设一共有M个特征,ei表示第i个特征的embedding向量,SE block把ei压缩成一个实数si。具体来说先将M个特征的embedding拼接在一起,经过全连接层并用sigmoid函数激活以后,得到M维的向量s:
$s=\sigma(W[e_1,...,e_m]+b)$
这里向量s的第i维对应第i个特征的重要得分,然后再将s_i乘回到e_i,得到新的加权后的特征向量用于后续计算。
在得到特征的重要性得分之后,我们把所有特征按重要性选择最高的top K个特征作为候选特征,并基于GAUC、QPS和RT指标等离线指标,对效果和算力进行平衡,最终在满足QPS和RT要求情况下,选择GAUC最高的一组特征组合,作为COLD最终使用的特征。后续的训练和线上打分都基于选择出来的特征组合。通过这种方式,可以灵活的进行效果和算力的平衡。
注意Se Block仅用于特征筛选阶段,线上模型不包含该结构。
② 基于scaling factor的结构化剪枝
此外COLD还会进行剪枝,做法是在每个神经元的输出后面乘上一个gamma,然后在训练的loss上对gamma进行稀疏惩罚,当某一神经元的gamma为0时,此时该神经元的输出为0,对此后的模型结构不再有任何影响,即视为该神经元被剪枝。
在训练时,会选用循环剪枝的方式,每隔t轮训练会对gamma为0的神经元进行mask,这样可以保证整个剪枝过程中模型的稀疏率是单调递减的。
这种剪枝方法在效果基本不变的情况下,粗排GPU的QPS提升20%。最终模型是7层全连接网络。
2.2.2工程优化
更多内容参考:https://blog.csdn.net/sinat_39620217/article/details/129049467?spm=1001.2014.3001.5501
2.3粗排技术的总结与展望
更多内容参考:https://blog.csdn.net/sinat_39620217/article/details/129049467?spm=1001.2014.3001.5501
2.3.1 总结!
2.3.2COLD的进一步发展以及展望
3. 相关文章推荐:
更多内容参考:https://blog.csdn.net/sinat_39620217/article/details/129049467?spm=1001.2014.3001.5501
推荐系统[三]:粗排算法常用模型汇总(集合选择和精准预估),技术发展历史(向量內积,Wide&Deep等模型)以及前沿技术的更多相关文章
- 深度学习在美团点评推荐平台排序中的应用&& wide&&deep推荐系统模型--学习笔记
写在前面:据说下周就要xxxxxxxx, 吓得本宝宝赶紧找些广告的东西看看 gbdt+lr的模型之前是知道怎么搞的,dnn+lr的模型也是知道的,但是都没有试验过 深度学习在美团点评推荐平台排序中的运 ...
- 巨经典论文!推荐系统经典模型Wide & Deep
今天我们剖析的也是推荐领域的经典论文,叫做Wide & Deep Learning for Recommender Systems.它发表于2016年,作者是Google App Store的 ...
- 【RS】Wide & Deep Learning for Recommender Systems - 广泛和深度学习的推荐系统
[论文标题]Wide & Deep Learning for Recommender Systems (DLRS'16) [论文作者] Heng-Tze Cheng, Levent Koc, ...
- 推荐系统系列(六):Wide&Deep理论与实践
背景 在CTR预估任务中,线性模型仍占有半壁江山.利用手工构造的交叉组合特征来使线性模型具有"记忆性",使模型记住共现频率较高的特征组合,往往也能达到一个不错的baseline,且 ...
- Deep Learning模型之:CNN卷积神经网络(一)深度解析CNN
http://m.blog.csdn.net/blog/wu010555688/24487301 本文整理了网上几位大牛的博客,详细地讲解了CNN的基础结构与核心思想,欢迎交流. [1]Deep le ...
- 推荐系统[八]算法实践总结V0:腾讯音乐全民K歌推荐系统架构及粗排设计
1.前言:召回排序流程策略算法简介 推荐可分为以下四个流程,分别是召回.粗排.精排以及重排: 召回是源头,在某种意义上决定着整个推荐的天花板: 粗排是初筛,一般不会上复杂模型: 精排是整个推荐环节的重 ...
- 【PHP】最详细PHP从入门到精通(三)——PHP中的数组常用函数汇总
PHP从入门到精通 之PHP中的数组常用函数详解 数组作为PHP中最常用的结构之一,PHP强大的数组函数功能,给数组的相关操作带来了极大的便利.今天给大家介绍的PHP中数组函数,是PHP数组中重要的 ...
- 模型汇总24 - 深度学习中Attention Mechanism详细介绍:原理、分类及应用
模型汇总24 - 深度学习中Attention Mechanism详细介绍:原理.分类及应用 lqfarmer 深度学习研究员.欢迎扫描头像二维码,获取更多精彩内容. 946 人赞同了该文章 Atte ...
- Java常用英语汇总(面试必备)
Java常用英语汇总(面试必备) abstract (关键字) 抽象 ['.bstr.kt] access vt.访问,存 ...
- 最小角回归 LARS算法包的用法以及模型参数的选择(R语言 )
Lasso回归模型,是常用线性回归的模型,当模型维度较高时,Lasso算法通过求解稀疏解对模型进行变量选择.Lars算法则提供了一种快速求解该模型的方法.Lars算法的基本原理有许多其他文章可以参考, ...
随机推荐
- 【Django drf】认证类 权限类 频率类 过滤类 排序类 分页类
目录 认证类 前期准备 自定义认证类 配置认证类 全局配置 局部禁用 认证组件使用步骤 基于类中方法的认证(了解) 权限类 前期准备 重写has_permission() 添加权限不足信息 权限组件使 ...
- ORM执行SQL 双下划线查询 ORM外键字段创建 外键字段相关操作 ORM跨表查询 跨表查询进阶操作
目录 ORM执行SQL语句 方式1:使用pymysql模块 方式2:使用raw方法 方式3:django connection 双下划线查询 __gt(>) __lt(<) queryse ...
- three.js 视频融合
MixVideo.js代码: //视频融合 import * as THREE from '../build/three.module.js'; import { API } from '../js. ...
- Mac 配置 OpenCV C++ 版本
今天紀錄一下如何在 Mac 上安裝 OpenCV for C++ 開發環境 使用 Brew 安装,pkgconfig 检测,2023.5.17 Mac x86 ( Intel ) , Mac M1 ( ...
- 换架 3D 飞机,继续飞呀飞
相信大多数图扑 HT 用户都曾见过这个飞机的 Demo,在图扑发展的这十年,这个 Demo 是许多学习 HT 用户一定会参考的经典 Demo 之一. 这个 Demo 用简洁的代码生动地展示了 OBJ ...
- 更省更快,如何使用 Serverless 搭建个人专属网盘?
作者| 西流 阿里云 Serverless 技术专家 1分钟 Serverless 部署个人网盘,赠好礼 随着全球大数据不断增长,未来数据云存储容量需求也将不断扩大,iiMedia Research( ...
- 运行vue项目时报错“ValidationError: Progress Plugin Invalid Options”
https://blog.csdn.net/M_Nobody/article/details/123135041?spm=1001.2101.3001.6650.1&utm_medium=di ...
- C语言基础之理论概述
C语言介绍 C语言是一种高级程序设计语言,由贝尔实验室的Dennis Ritchie在1972年开发.C语言是结构化编程语言,支持变量.数据类型.运算符.表达式.流程控制语句和函数等基本程序设计元素. ...
- kafka Linux环境搭建安装及命令创建队列生产消费消息
本文为博主原创,未经允许不得转载: 1. 安装JDK 由于Kafka是用Scala语言开发的,运行在JVM上,因此在安装Kafka之前需要先安装JDK. yum install java‐1.8.0‐ ...
- Oracle12c新增max_idle_time参数的学习与感触
Oracle12c新增max_idle_time参数的学习与感触 TLDR 其实任何软件出了新版本.readme 是很重要的. 尤其是数据库, 涉及到底层问题的. 比如这次遇到的Oracle的max_ ...