解析WeNet云端推理部署代码
摘要:WeNet是一款开源端到端ASR工具包,它与ESPnet等开源语音项目相比,最大的优势在于提供了从训练到部署的一整套工具链,使ASR服务的工业落地更加简单。
本文分享自华为云社区《WeNet云端推理部署代码解析》,作者:xiaoye0829 。
WeNet是一款开源端到端ASR工具包,它与ESPnet等开源语音项目相比,最大的优势在于提供了从训练到部署的一整套工具链,使ASR服务的工业落地更加简单。如图1所示,WeNet工具包完全依赖于PyTorch生态:使用TorchScript进行模型开发,使用Torchaudio进行动态特征提取,使用DistributedDataParallel进行分布式训练,使用torch JIT(Just In Time)进行模型导出,使用LibTorch作为生产环境运行时。本系列将对WeNet云端推理部署代码进行解析。
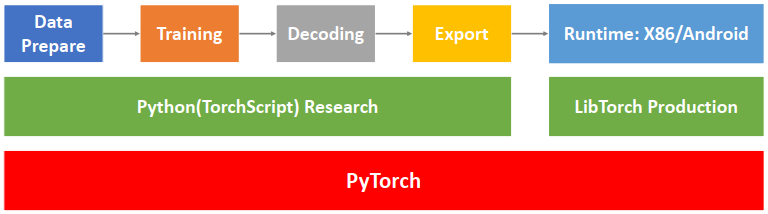
图1:WeNet系统设计[1]
1. 代码结构
WeNet云端推理和部署代码位于wenet/runtime/server/x86路径下,编程语言为C++,其结构如下所示:

其中:
- 语音文件读入与特征提取相关代码位于frontend文件夹下;
- 端到端模型导入、端点检测与语音解码识别相关代码位于decoder文件夹下,WeNet支持CTC prefix beam search和融合了WFST的CTC beam search这两种解码算法,后者的实现大量借鉴了Kaldi,相关代码放在kaldi文件夹下;
- 在服务化方面,WeNet分别实现了基于WebSocket和基于gRPC的两套服务端与客户端,基于WebSocket的实现位于websocket文件夹下,基于gRPC的实现位于grpc文件夹下,两种实现的入口main函数代码都位于bin文件夹下。
- 日志、计时、字符串处理等辅助代码位于utils文件夹下。
WeNet提供了CMakeLists.txt和Dockerfile,使得用户能方便地进行项目编译和镜像构建。
2. 前端:frontend文件夹
1)语音文件读入
WeNet只支持44字节header的wav格式音频数据,wav header定义在WavHeader结构体中,包括音频格式、声道数、采样率等音频元信息。WavReader类用于语音文件读入,调用fopen打开语音文件后,WavReader先读入WavHeader大小的数据(也就是44字节),再根据WavHeader中的元信息确定待读入音频数据的大小,最后调用fread把音频数据读入buffer,并通过static_cast把数据转化为float类型。
struct WavHeader {
char riff[4]; // "riff"
unsigned int size;
char wav[4]; // "WAVE"
char fmt[4]; // "fmt "
unsigned int fmt_size;
uint16_t format;
uint16_t channels;
unsigned int sample_rate;
unsigned int bytes_per_second;
uint16_t block_size;
uint16_t bit;
char data[4]; // "data"
unsigned int data_size;
};
这里存在的一个风险是,如果WavHeader中存放的元信息有误,则会影响到语音数据的正确读入。
2)特征提取
WeNet使用的特征是fbank,通过FeaturePipelineConfig结构体进行特征设置。默认帧长为25ms,帧移为10ms,采样率和fbank维数则由用户输入。
用于特征提取的类是FeaturePipeline。为了同时支持流式与非流式语音识别,FeaturePipeline类中设置了input_finished_属性来标志输入是否结束,并通过set_input_finished()成员函数来对input_finished_属性进行操作。
提取出来的fbank特征放在feature_queue_中,feature_queue_的类型是BlockingQueue<std::vector<float>>。BlockingQueue类是WeNet实现的一个阻塞队列,初始化的时候需要提供队列的容量(capacity),通过Push()函数向队列中增加特征,通过Pop()函数从队列中读取特征:
- 当feature_queue_中的feature数量超过capacity,则Push线程被挂起,等待feature_queue_.Pop()释放出空间。
- 当feature_queue_为空,则Pop线程被挂起,等待feature_queue_.Push()。
线程的挂起和恢复是通过C++标准库中的线程同步原语std::mutex、std::condition_variable等实现。
线程同步还用在AcceptWaveform和ReadOne两个成员函数中,AcceptWaveform把语音数据提取得到的fbank特征放到feature_queue_中,ReadOne成员函数则把特征从feature_queue_中读出,是经典的生产者消费者模式。
3. 解码器:decoder文件夹
1)TorchAsrModel
通过torch::jit::load对存在磁盘上的模型进行反序列化,得到一个ScriptModule对象。
torch::jit::script::Module model = torch::jit::load(model_path);
2)SearchInterface
WeNet推理支持的解码方式都继承自基类SearchInterface,如果要新增解码算法,则需继承SearchInterface类,并提供该类中所有纯虚函数的实现,包括:
// 解码算法的具体实现
virtual void Search(const torch::Tensor& logp) = 0;
// 重置解码过程
virtual void Reset() = 0;
// 结束解码过程
virtual void FinalizeSearch() = 0;
// 解码算法类型,返回一个枚举常量SearchType
virtual SearchType Type() const = 0;
// 返回解码输入
virtual const std::vector<std::vector<int>>& Inputs() const = 0;
// 返回解码输出
virtual const std::vector<std::vector<int>>& Outputs() const = 0;
// 返回解码输出对应的似然值
virtual const std::vector<float>& Likelihood() const = 0;
// 返回解码输出对应的次数
virtual const std::vector<std::vector<int>>& Times() const = 0;
目前WeNet只提供了SearchInterface的两种子类实现,也即两种解码算法,分别定义在CtcPrefixBeamSearch和CtcWfstBeamSearch两个类中。
3)CtcEndpoint
WeNet支持语音端点检测,提供了一种基于规则的实现方式,用户可以通过CtcEndpointConfig结构体和CtcEndpointRule结构体进行规则配置。WeNet默认的规则有三条:
- 检测到了5s的静音,则认为检测到端点;
- 解码出了任意时长的语音后,检测到了1s的静音,则认为检测到端点;
- 解码出了20s的语音,则认为检测到端点。
一旦检测到端点,则结束解码。另外,WeNet把解码得到的空白符(blank)视作静音。
4)TorchAsrDecoder
WeNet提供的解码器定义在TorchAsrDecoder类中。如图3所示,WeNet支持双向解码,即叠加从左往右解码和从右往左解码的结果。在CTC beam search之后,用户还可以选择进行attention重打分。
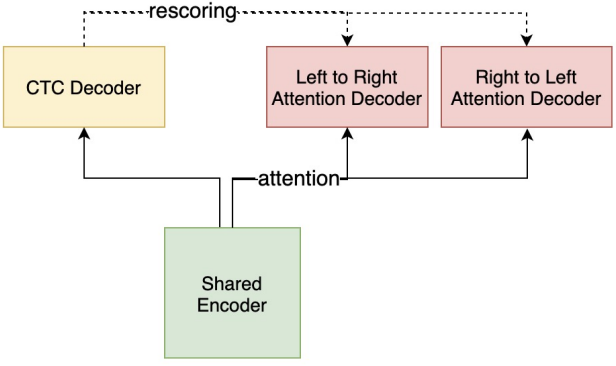
图2:WeNet解码计算流程[2]
可以通过DecodeOptions结构体进行解码参数配置,包括如下参数:
struct DecodeOptions {
int chunk_size = 16;
int num_left_chunks = -1;
float ctc_weight = 0.0;
float rescoring_weight = 1.0;
float reverse_weight = 0.0;
CtcEndpointConfig ctc_endpoint_config;
CtcPrefixBeamSearchOptions ctc_prefix_search_opts;
CtcWfstBeamSearchOptions ctc_wfst_search_opts;
};
其中,ctc_weight表示CTC解码权重,rescoring_weight表示重打分权重,reverse_weight表示从右往左解码权重。最终解码打分的计算方式为:
final_score = rescoring_weight * rescoring_score + ctc_weight * ctc_score;
rescoring_score = left_to_right_score * (1 - reverse_weight) +
right_to_left_score * reverse_weight
TorchAsrDecoder对外提供的解码接口是Decode(),重打分接口是Rescoring()。Decode()返回的是枚举类型DecodeState,包括三个枚举常量:kEndBatch,kEndpoint和kEndFeats,分别表示当前批数据解码结束、检测到端点、所有特征解码结束。
为了支持长语音识别,WeNet还提供了连续解码接口ResetContinuousDecoding(),它与解码器重置接口Reset()的区别在于:连续解码接口会记录全局已经解码的语音帧数,并保留当前feature_pipeline_的状态。
由于流式ASR服务需要在客户端和服务端之间进行双向的流式数据传输,WeNet实现了两种支持双向流式通信的服务化接口,分别基于WebSocket和gRPC。
4. 基于WebSocket
1)WebSocket简介
WebSocket是基于TCP的一种新的网络协议,与HTTP协议不同,WebSocket允许服务器主动发送信息给客户端。 在连接建立后,客户端和服务端可以连续互相发送数据,而无需在每次发送数据时重新发起连接请求。因此大大减小了网络带宽的资源消耗 ,在性能上更有优势。
WebSocket支持文本和二进制两种格式的数据传输 。
2)WeNet的WebSocket接口
WeNet使用了boost库的WebSocket实现,定义了WebSocketClient(客户端)和WebSocketServer(服务端)两个类。
在流式ASR过程中,WebSocketClient给WebSocketServer发送数据可以分为三个步骤:1)发送开始信号与解码配置;2)发送二进制语音数据:pcm字节流;3)发送停止信号。从WebSocketClient::SendStartSignal()和WebSocketClient::SendEndSignal()可以看到,开始信号、解码配置和停止信号都是包装在json字符串中,通过WebSocket文本格式传输。pcm字节流则通过WebSocket二进制格式进行传输。
void WebSocketClient::SendStartSignal() {
// TODO(Binbin Zhang): Add sample rate and other setting surpport
json::value start_tag = {{"signal", "start"},
{"nbest", nbest_},
{"continuous_decoding", continuous_decoding_}};
std::string start_message = json::serialize(start_tag);
this->SendTextData(start_message);
}
void WebSocketClient::SendEndSignal() {
json::value end_tag = {{"signal", "end"}};
std::string end_message = json::serialize(end_tag);
this->SendTextData(end_message);
}
WebSocketServer在收到数据后,需要先判断收到的数据是文本还是二进制格式:如果是文本数据,则进行json解析,并根据解析结果进行解码配置、启动或停止,处理逻辑定义在ConnectionHandler::OnText()函数中。如果是二进制数据,则进行语音识别,处理逻辑定义在ConnectionHandler::OnSpeechData()中。
3)缺点
WebSocket需要开发者在WebSocketClient和WebSocketServer写好对应的消息构造和解析代码,容易出错。另外,从以上代码来看,服务需要借助json格式来序列化和反序列化数据,效率没有protobuf格式高。
对于这些缺点,gRPC框架提供了更好的解决方法。
5. 基于gRPC
1)gRPC简介
gRPC是谷歌推出的开源RPC框架,使用HTTP2作为网络传输协议,并使用protobuf作为数据交换格式,有更高的数据传输效率。在gRPC框架下,开发者只需通过一个.proto文件定义好RPC服务(service)与消息(message),便可通过gRPC提供的代码生成工具(protoc compiler)自动生成消息构造和解析代码,使开发者能更好地聚焦于接口设计本身。
进行RPC调用时,gRPC Stub(客户端)向gRPC Server(服务端)发送.proto文件中定义的Request消息,gRPC Server在处理完请求之后,通过.proto文件中定义的Response消息将结果返回给gRPC Stub。
gRPC具有跨语言特性,支持不同语言写的微服务进行互动,比如说服务端用C++实现,客户端用Ruby实现。protoc compiler支持12种语言的代码生成。
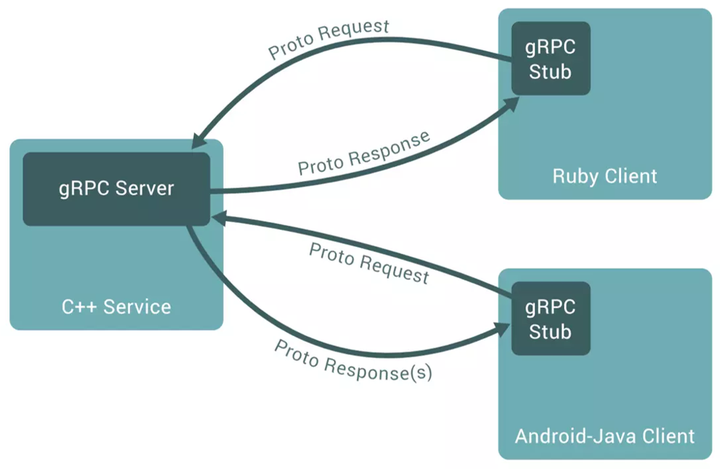
图1:gRPC Server和gRPC Stub交互[1]
2)WeNet的proto文件
WeNet定义的服务为ASR,包含一个Recognize方法,该方法的输入(Request)、输出(Response)都是流式数据(stream)。在使用protoc compiler编译proto文件后,会得到4个文件:wenet.grpc.pb.h,http://wenet.grpc.pb.cc,wenet.pb.h,http://wenet.pb.cc。其中,wenet.pb.h/cc中存储了protobuf数据格式的定义,wenet.grpc.pb.h中存储了gRPC服务端/客户端的定义。通过在代码中包括wenet.pb.h和wenet.grpc.pb.h两个头文件,开发者可以直接使用Request消息和Response消息类,访问其字段。
service ASR {
rpc Recognize (stream Request) returns (stream Response) {}
}
message Request {
message DecodeConfig {
int32 nbest_config = 1;
bool continuous_decoding_config = 2;
}
oneof RequestPayload {
DecodeConfig decode_config = 1;
bytes audio_data = 2;
}
}
message Response {
message OneBest {
string sentence = 1;
repeated OnePiece wordpieces = 2;
}
message OnePiece {
string word = 1;
int32 start = 2;
int32 end = 3;
}
enum Status {
ok = 0;
failed = 1;
}
enum Type {
server_ready = 0;
partial_result = 1;
final_result = 2;
speech_end = 3;
}
Status status = 1;
Type type = 2;
repeated OneBest nbest = 3;
}
3)WeNet的gRPC实现
WeNet gRPC服务端定义了GrpcServer类,该类继承自wenet.grpc.pb.h中的纯虚基类ASR::Service。
语音识别的入口函数是GrpcServer::Recognize,该函数初始化一个GRPCConnectionHandler实例来进行语音识别,并通过ServerReaderWriter类的stream对象来传递输入输出。
Status GrpcServer::Recognize(ServerContext* context,
ServerReaderWriter<Response, Request>* stream) {
LOG(INFO) << "Get Recognize request" << std::endl;
auto request = std::make_shared<Request>();
auto response = std::make_shared<Response>();
GrpcConnectionHandler handler(stream, request, response, feature_config_,
decode_config_, symbol_table_, model_, fst_);
std::thread t(std::move(handler));
t.join();
return Status::OK;
}
WeNet gRPC客户端定义了GrpcClient类。客户端在建立与服务端的连接时需实例化ASR::Stub,并通过ClientReaderWriter类的stream对象,实现双向流式通信。
void GrpcClient::Connect() {
channel_ = grpc::CreateChannel(host_ + ":" + std::to_string(port_),
grpc::InsecureChannelCredentials());
stub_ = ASR::NewStub(channel_);
context_ = std::make_shared<ClientContext>();
stream_ = stub_->Recognize(context_.get());
request_ = std::make_shared<Request>();
response_ = std::make_shared<Response>();
request_->mutable_decode_config()->set_nbest_config(nbest_);
request_->mutable_decode_config()->set_continuous_decoding_config(
continuous_decoding_);
stream_->Write(*request_);
}
http://grpc_client_main.cc中,客户端分段传输语音数据,每0.5s进行一次传输,即对于一个采样率为8k的语音文件来说,每次传4000帧数据。为了减小传输数据的大小,提升数据传输速度,先在客户端将float类型转为int16_t,服务端在接受到数据后,再将int16_t转为float。c++中float为32位。
int main(int argc, char *argv[]) {
...
// Send data every 0.5 second
const float interval = 0.5;
const int sample_interval = interval * sample_rate;
for (int start = 0; start < num_sample; start += sample_interval) {
if (client.done()) {
break;
}
int end = std::min(start + sample_interval, num_sample);
// Convert to short
std::vector<int16_t> data;
data.reserve(end - start);
for (int j = start; j < end; j++) {
data.push_back(static_cast<int16_t>(pcm_data[j]));
}
// Send PCM data
client.SendBinaryData(data.data(), data.size() * sizeof(int16_t));
...
}
总结
本文主要对WeNet云端部署代码进行解析,介绍了WeNet基于WebSocket和基于gRPC的两种服务化接口。
WeNet代码结构清晰,简洁易用,为语音识别提供了从训练到部署的一套端到端解决方案,大大促进了工业落地效率,是非常值得借鉴学习的语音开源项目。
参考
[1] https://grpc.io/docs/what-is-grpc/introduction/
[2]WeNet: Production First and Production Ready End-to-End Speech Recognition Toolkit
[3]WeNet源码
[4]WeNet: Production First and Production Ready End-to-End Speech Recognition Toolkit
[5] U2++: Unified Two-pass Bidirectional End-to-end Model for Speech Recognition
解析WeNet云端推理部署代码的更多相关文章
- Paddle Inference推理部署
Paddle Inference推理部署 飞桨(PaddlePaddle)是集深度学习核心框架.工具组件和服务平台为一体的技术先进.功能完备的开源深度学习平台,已被中国企业广泛使用,深度契合企业应用需 ...
- 在linux服务器上装svn版本管理,自动部署代码到项目
在linux服务器上装svn版本管理,自动部署代码到项目 http://bbs.aliyun.com/read/9715.html?spm=5176.7114037.1996646101.1.W3zw ...
- NodeJS”热部署“代码,实现动态调试(hotnode,可以实现热更新)
NodeJS”热部署“代码,实现动态调试 开发中遇到的问题 如果你有 PHP 开发经验,会习惯在修改 PHP 脚本后直接刷新浏览器以观察结果,而你在开发 Node.js 实现的 HTTP 应用时会 ...
- 在linux服务器上装svn版本管理,自动部署代码到web项目
在linux服务器上装svn版本管理,自动部署代码到项目 1.安装svn服务器端 yum install subversion 从镜像下载安装svn服务器端 中间会提示是否ok,输入y,确认 ...
- 使用git代替FTP部署代码到服务器的例子
这篇文章主要介绍了使用git代替FTP部署代码到服务器的例子,这种方法可以节省流量.节省时间,需要的朋友可以参考下 本地开发完成后,通常会在服务器上部署,有人会使用ftp,有人会使用scp, ftp和 ...
- git一键部署代码到远程服务器(linux)(采坑总结)
原来一直使用FileZilla来代码部署,去年使用git,代码版本管理,真TM好用,一起回顾下历程! 一. 代码部署方式及思路: 1. 使用FTP/SFTP工具,上传代码 2. git人工部署.1. ...
- vueJs 源码解析 (三) 具体代码
vueJs 源码解析 (三) 具体代码 在之前的文章中提到了 vuejs 源码中的 架构部分,以及 谈论到了 vue 源码三要素 vm.compiler.watcher 这三要素,那么今天我们就从这三 ...
- 关于Jenkins部署代码权限三种方案
关于Jenkins部署代码权限三种方案 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.修改Jenkins进程用户为root [root@jenkins ~]# cat /etc ...
- 持续集成+自动化部署[代码流水线管理及Jenkins和gitlab集成]
转载:https://www.abcdocker.com/abcdocker/2065 一.代码流水线管理 Pipeline名词顾名思义就是流水线的意思,因为公司可能会有很多项目.如果使用jenkin ...
- Git github webhook 自动更新/部署代码 php自动更新脚本
这几天尝试了利用github的webhook,当代码更新到github,我们的测试服务器自动更新最新的gitbub仓库代码. 先列几个大概步骤,有时间再补充详细 1 . 服务器生成ssh key,一般 ...
随机推荐
- Unity - UIWidgets 7. Redux接入(二) 把Redux划分为不同数据模块
参考QF.UIWidgets 参考Unity官方示例 - ConnectAppCN 前面说过,当时没想明白一个问题,在reducer中每次返回一个new State(), 会造成极大浪费,没想到用什么 ...
- MicroSIP-3.21.3+pjproject-2.13.1+ opus-1.3.1+VS2019
本文记录了我通过VS2019编译MicroSIP-3.21.3开源项目的过程. Microsip:MicroSIP source code pjproject:Download PJSIP - Ope ...
- 这次弄一下maven 多模块项目,用vscode新建一下,便于管理项目
首先 创建一个mvn项目, 直接在命令行执行, 原型生成: mvn archetype:generate 选一个maven quick start的template, 然后删除src和target文件 ...
- MySQL锁:InnoDB行锁需要避免的坑
前言 换了工作之后,接近半年没有发博客了(一直加班),emmmm.....今天好不容易有时间,记录下工作中遇到的一些问题,接下来应该重拾知识点了.因为新公司工作中MySQL库经常出现查询慢,锁等待,节 ...
- 怎样阅读 h2 数据库源码
阅读 h2 数据库的源码是一项复杂的任务,需要对数据库原理.Java 语言和操作系统有深入的理解.可以从以下几方面入手来完成. 环境准备 首先,你需要在你的机器上安装和配置好开发环境,包括 JDK.M ...
- 神经网络入门篇:详解核对矩阵的维数(Getting your matrix dimensions right)
核对矩阵的维数 当实现深度神经网络的时候,其中一个常用的检查代码是否有错的方法就是拿出一张纸过一遍算法中矩阵的维数. \(w\)的维度是(下一层的维数,前一层的维数),即\({{w}^{[l]}}\) ...
- 吉特日化MES系统--通过浏览器调用标签打印
三年来做制造行业,差不多做了近30个工厂,也由纯软件转入到了大量的硬件对接,包含厂房设计(这个目前还只是小菜鸟),硬件设计(只是提提意见),安装实施调试(软件和硬件撕逼操作),当然面向的对象也由计算机 ...
- 通过 VS Code 优雅地编辑 Pod 内的代码(非 NodePort)
目录 1. 概述 2. NodePort 方式 3. Ingress 方式 4. 救命稻草 5. 其他 1. 概述 今天聊点啥呢,话说,你有没有想过怎样用 VS Code 连上 K8s 集群内的某个 ...
- springBoot——整合mybatis
spring整合mybatis springBoot整合mybaits 配置文件 spring: datasource: url: jdbc:mysql://localhost:3306/test d ...
- PyTorch 中自定义数据集的读取方法
显然我们在学习深度学习时,不能只局限于通过使用官方提供的MNSIT.CIFAR-10.CIFAR-100这样的数据集,很多时候我们还是需要根据自己遇到的实际问题自己去搜集数据,然后制作数据集(收集数据 ...