字节跳动基于ClickHouse优化实践之Upsert
更多技术交流、求职机会、试用福利,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
相信大家都对大名鼎鼎的ClickHouse有一定的了解,它强大的数据分析性能让人印象深刻。但在字节大量生产使用中,发现了ClickHouse依然存在了一定的限制。例如:
缺少完整的upsert和delete操作
多表关联查询能力弱
集群规模较大时可用性下降(对字节尤其如此)
没有资源隔离能力
因此,我们决定将ClickHouse能力进行全方位加强,打造一款更强大的数据分析平台。
本篇将详细介绍我们是如何为ClickHouse补全更新删除能力的。
实时人群圈选场景遇到的难题
在电商业务中,人群圈选是非常常见的一个场景。字节原有的离线圈选的方案是以T+1的方式更新数据,而不是实时更新,这很影响业务侧的体验。现在希望能够基于实时标签,在数据管理平台中构建实时人群圈选的能力。整体数据链路如下:
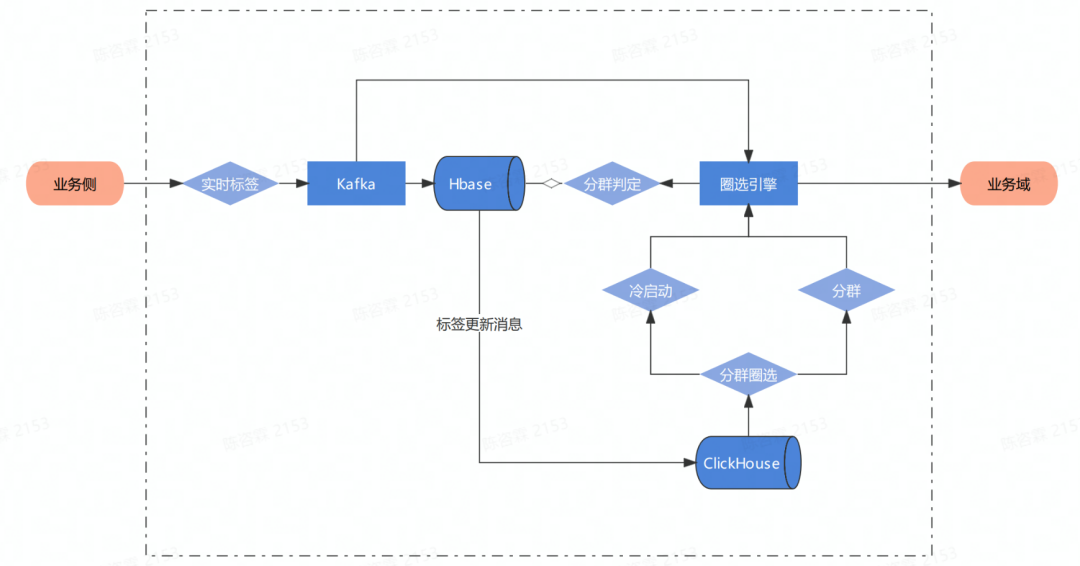
为了保证实时数据和离线数据同时提供服务,在标签接入完毕后,在ClickHouse中完成宽表加工任务。但是原生ClickHouse只支持追加写的能力,只有ReplacingMergeTree这种方案。但是选用ReplacingMergeTree引擎的限制比较多,不能满足业务的需求,主要体现在:
性能下降严重,ReplacingMergeTree采用的是写优先的设计逻辑,这导致读性能损失严重。表现是在进行查询时性能较ClickHouse其他引擎的性能下降严重,涉及ReplacingMergeTree的查询响应时间过慢。
ReplacingMergeTree引擎只支持数据的更新,并不支持数据的删除。只能通过额外的定制处理来实现数据清除,但这样会进一步拖慢了查询的性能。
ReplacingMergeTree中的去重是 Merge 触发的,在刚导入的数据时是不去重的,过一段时间后才会在分区内去重。
解决方案:UniqueMergeTree
在这种情况下,字节在ByteHouse(字节基于ClickHouse能力增强的版本)中开发了一种支持实时更新删除的表引擎:UniqueMergeTree。UniqueMergeTree与以往的表引擎有什么差别呢?下面介绍两种支持实时更新的常见技术方案:
原生ClickHouse选择的技术方案
原生ClickHouse的更新表引擎ReplacingMergeTree使用Merge on Read的实现逻辑,整个思想比较类似LSMTree。对于写入,数据先根据key排序,然后生成对应的列存文件。每个Batch写入的文件对应一个版本号,版本号能用来表示数据的写入顺序。
同一批次的数据不包含重复key,但不同批次的数据包含重复key,这就需要在读的时候去做合并,对key相同的数据返回去最新版本的值,所以叫merge on read方案。原生ClickHouse ReplacingMergeTree用的就是这种方案。
大家可以看到,它的写路径是非常简单的,是一个很典型的写优化方案。它的问题是读性能比较差,有几方面的原因。首先,key-based merge通常是单线程的,比较难并行。其次merge过程需要非常多的内存比较和内存拷贝。最后这种方案对谓词下推也会有一些限制。大家用过ReplacingMergeTree的话,应该对读性能问题深有体会。
这个方案也有一些变种,比如说可以维护一些index来加速merge过程,不用每次merge都去做key的比较。
面向读优化的新方案
UniqueMergeTree使用的技术方案Mark-Delete + Insert方案刚好反过来,是一个读优化方案。在这个方案中,更新是通过先删除再插入的方式实现的。
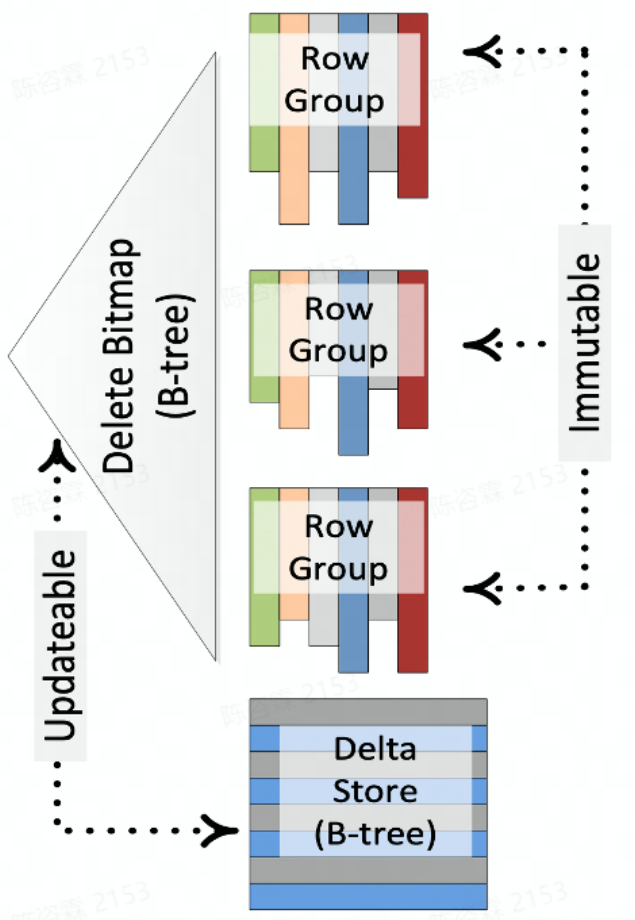
Ref “Enhancements to SQLServer Column Stores”
下面以SQLServer的Column Stores为例介绍下这个方案。图中,每个RowGroup对应一个不可变的列存文件,并用Bitmap来记录每个RowGroup中被标记删除的行号,即DeleteBitmap。处理更新的时候,先查找key所属的RowGroup以及它在RowGroup中行号,更新RowGroup的DeleteBitmap,最后将更新后的数据写入Delta Store。查询的时候,不同RowGroup的扫描可以完全并行,只需要基于行号过滤掉属于DeleteBitmap的数据即可。
这个方案平衡了写和读的性能。一方面写入时需要去定位key的具体位置,另一方面需要处理write-write冲突问题。
这个方案也有一些变种。比如说写入时先不去查找更新key的位置,而是先将这些key记录到一个buffer中,使用后台任务将这些key转成DeleteBitmap。然后在查询的时候通过merge on read的方式处理buffer中的增量key。
Upsert和Delete使用示例
首先我们建了一张UniqueMergeTree的表,表引擎的参数和ReplacingMergeTree是一样的,不同点是可以通过UNIQUE KEY关键词来指定这张表的唯一键,它可以是多个字段,可以包含表达式等等。

下面对这张表做写入操作就会用到upsert的语义,比如说第6行写了四条数据,但只包含1和2两个key,所以对于第7行的select,每个key只会返回最高版本的数据。对于第11行的写入,key 2是一个已经存在的key,所以会把key 2对应的name更新成B3; key 3是新key,所以直接插入。最后对于行删除操作,我们增加了一个delete flag的虚拟列,用户可以通过这个虚拟列标记Batch中哪些是要删除,哪些是要upsert。
UniqueMergeTree表引擎的亮点
对于Unique表的写入,我们会采用upsert的语义,即如果写入的是新key,那就直接插入数据;如果写入的key已经存在,那就更新对应的数据。
UniqueMergeTree表引擎既支持行更新的模式,也支持部分列更新的模式,用户可以根据业务要求开启或关闭。
ByteHouse也支持指定Unique Key的value来删除数据,满足实时行删除的需求。支持指定一个版本字段来解决回溯场景可能出现的低版本数据覆盖高版本数据的问题。
最后ByteHouse也支持数据在多副本的同步,避免整体系统存在单点故障。
在性能方面,我们对UniqueMergeTree的写入和查询性能做了性能测试,结果如下图(箭头前是ReplacingMergeTree的消耗时间,箭头后是UniqueMergeTree的消耗时间)。
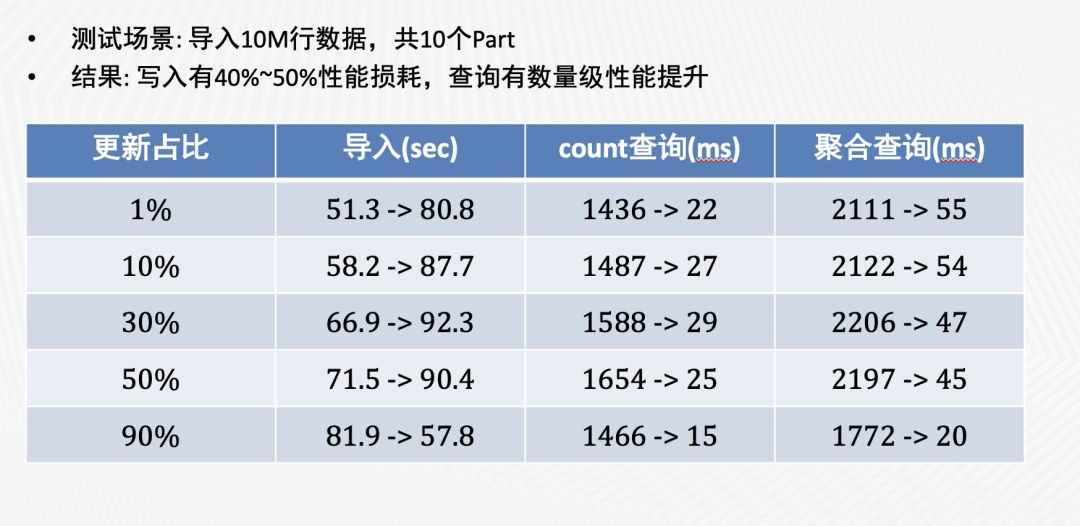
可以看到,与ReplacingMergeTree相比,UniqueMergeTree的写入性能虽然略有下降,但在查询性能上取得了数量级的提升。我们进一步对比了UniqueMergeTree和普通MergeTree的查询性能,发现两者是非常接近的。
增强后的实施人群圈选
经过UniqueMergeTree的加持,在原有架构不变的情况下,完美的满足了实时人群圈选场景的要求。
1、通过Unique Key配置唯一键,提供upsert更新写语义,查询自动返回每个唯一键的最新值
2、性能:单shard写入吞吐可以达到10k+行/s;查询性能与原生CH表几乎相同
3、支持根据Unique Key实时删除数据
此外,ByteHouse还通过UniqueMergeTree支持了一些其他特性:
1、唯一键支持多字段和表达式
2、支持分区级别唯一和表级别唯一两种模式
3、支持自定义版本字段,写入低版本数据时自动忽略
4、支持多副本部署,通过主备异步复制保障数据可靠性
不仅在实时人群圈选场景,ByteHouse提供的upsert能力已经服务于字节内部众多应用,线上应用的表数量有数千张,受到实时类应用的广泛欢迎。
除Upsert能力外,ByteHouse在为原生ClickHouse的企业级能力进行了全方位的增强。
字节跳动基于ClickHouse优化实践之Upsert的更多相关文章
- 字节跳动基于ClickHouse优化实践之“多表关联查询”
更多技术交流.求职机会.试用福利,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 相信大家都对大名鼎鼎的ClickHouse有一定的了解了,它强大的数据分析性能让人印象深刻.但在字节大量 ...
- 字节跳动基于Apache Hudi构建EB级数据湖实践
来自字节跳动的管梓越同学一篇关于Apache Hudi在字节跳动推荐系统中EB级数据量实践的分享. 接下来将分为场景需求.设计选型.功能支持.性能调优.未来展望五部分介绍Hudi在字节跳动推荐系统中的 ...
- 字节跳动数据平台技术揭秘:基于 ClickHouse 的复杂查询实现与优化
更多技术交流.求职机会.试用福利,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 ClickHouse 作为目前业内主流的列式存储数据库(DBMS)之一,拥有着同类型 DBMS 难以企及 ...
- 字节跳动流式数据集成基于Flink Checkpoint两阶段提交的实践和优化
背景 字节跳动开发套件数据集成团队(DTS ,Data Transmission Service)在字节跳动内基于 Flink 实现了流批一体的数据集成服务.其中一个典型场景是 Kafka/ByteM ...
- Presto 在字节跳动的内部实践与优化
在字节跳动内部,Presto 主要支撑了 Ad-hoc 查询.BI 可视化分析.近实时查询分析等场景,日查询量接近 100 万条.本文是字节跳动数据平台 Presto 团队-软件工程师常鹏飞在 Pre ...
- Go RPC 框架 KiteX 性能优化实践 原创 基础架构团队 字节跳动技术团队 2021-01-18
Go RPC 框架 KiteX 性能优化实践 原创 基础架构团队 字节跳动技术团队 2021-01-18
- 从 ClickHouse 到 ByteHouse:实时数据分析场景下的优化实践
本文来自火山引擎公众号,原文发布于2021-09-06. 近日,字节跳动旗下的企业级技术服务平台火山引擎正式对外发布「ByteHouse」,作为 ClickHouse 企业版,解决开源技术上手难 &a ...
- 深度介绍Flink在字节跳动数据流的实践
本文是字节跳动数据平台开发套件团队在1月9日Flink Forward Asia 2021: Flink Forward 峰会上的演讲分享,将着重分享Flink在字节跳动数据流的实践. 字节跳动数据流 ...
- 以字节跳动内部 Data Catalog 架构升级为例聊业务系统的性能优化
背景 字节跳动 Data Catalog 产品早期,是基于 LinkedIn Wherehows 进行二次改造,产品早期只支持 Hive 一种数据源.后续为了支持业务发展,做了很多修修补补的工作,系统 ...
- 字节跳动在 Go 网络库上的实践
https://mp.weixin.qq.com/s/wSaJYg-HqnYY4SdLA2Zzaw RPC 框架作为研发体系中重要的一环,承载了几乎所有的服务流量.本文将简单介绍字节跳动自研网络库 n ...
随机推荐
- CF1610B [Kalindrome Array]
Problem 题目简述 给你一个数列 \(a\),有这两种情况,这个数列是「可爱的」. 它本身就是回文的. 定义变量 \(x\),满足:序列 \(a\) 中所有值等于 \(x\) 的元素删除之后,它 ...
- Java实现两字符串相似度算法
1.编辑距离 编辑距离:是衡量两个字符串之间差异的度量,它表示将一个字符串转换为另一个字符串所需的最少编辑操作次数(插入.删除.替换). 2.相似度 计算方法可以有多种,其中一种常见的方法是将编辑距离 ...
- rt-thread Env 预处理配置方法
简介 rt-thread 是我非常喜欢的一款RTOS,近期在使用Env更新工程的时候发现,keil MDK 中的预处理型号和器件型号不符. 这就导致我每次更新工程后都需要进入keil MDK手动修改一 ...
- SNN_文献阅读_Text Classification in Memristor-based Spiking Neural Networks
SNN中局部学习和非局部学习,基于梯度的规则都需要对用于表示单个连续值的脉冲训练窗口上的累积误差进行平均,这种方法在更新权重时考虑了每一个脉冲的影响.在计算速度和空间效率等方面,特别是当代表单个数值的 ...
- 3.1 IDA Pro编写IDC脚本入门
IDA Pro内置的IDC脚本语言是一种灵活的.C语言风格的脚本语言,旨在帮助逆向工程师更轻松地进行反汇编和静态分析.IDC脚本语言支持变量.表达式.循环.分支.函数等C语言中的常见语法结构,并且还提 ...
- Weight Balanced Leafy Tree 学习笔记
前言: 在这里十分十分感谢 \(\text{lxl}\) 和王思齐发明和总结了 \(\text{WBLT}\). 因为网上关于 \(\text{WBLT}\) 的正确讲解(已除去那篇国家集训队论文,不 ...
- 视觉BEV基本原理和方案解析
BEV(Bird's-Eye-View)是一种鸟瞰视图的传感器数据表示方法,它的相关技术在自动驾驶领域已经成了"标配",纷纷在新能源汽车.芯片设计等行业相继量产落地.BEV同样在高 ...
- 期望最大化(EM)算法:从理论到实战全解析
本文深入探讨了期望最大化(EM)算法的原理.数学基础和应用.通过详尽的定义和具体例子,文章阐释了EM算法在高斯混合模型(GMM)中的应用,并通过Python和PyTorch代码实现进行了实战演示. 关 ...
- java如何导入导出excel
在Java中,可以使用多种方式导入和导出Excel文件.下面将详细介绍几种常见的方法及其实现步骤: 1. Apache POI库: Apache POI是一个开源的Java库,提供了许多类和方法用于处 ...
- Java自定义ClassLoader实现插件类隔离加载 - 原理篇
书接上回 在 Java自定义ClassLoader实现插件类隔离加载文章中,我们通过 自定义ClassLoader + 插件独立打包引入的方式,实现了同依赖不同版本的隔离加载 这次咱们来分析下具体实现 ...