hbase系列之:独立模式部署hbase
一、概述
在上一篇博文中,我简要介绍了hbase的部分基础概念,如果想初步了解hbase的理论,可以参看上一篇博文 hbase系列之:初识hbase 。本博文主要介绍独立模式下部署hbase及hbase的几个基本操作,需要具备一定的Linux基础。
二、部署前准备
1、纯净的Linux系统,本文使用CentOS7.5,IP地址为:192.168.200.31。
2、安装jdk并配置环境变量,本文使用jdk1.8。参看下文“java对hbase的版本支持”小节的内容。

3、新建hbase用户,并设置密码为hbase123。
4、使用命令 mkdir -p /data/softwares 创建软件包存放目录,使用命令 mkdir -p /data/modules/hbase 创建hbase部署目录。
5、使用root用户进入到 /data/modules 目录下,把 hbase 目录的属主设为hbase用户。

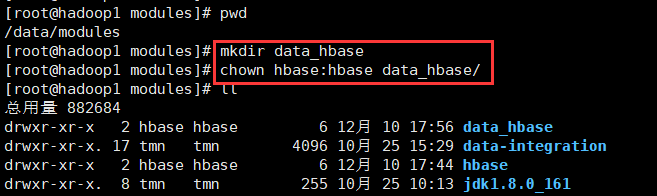
6、使用root用户,进入到/data/modules目录下,新建data_hbase目录并切换属主为hbase用户,用于存放hbase数据。
三、下载hbase并部署
1、java对hbase的版本支持。
hbase官方文档上面有java对hbase版本支持的详细介绍,我这儿贴出一张表作为参考。
| hbase版本 | jdk1.6 | jdk1.7 | jdk1.8 |
| 1.2 | 不支持 | 支持 | 支持 |
| 1.1 | 不支持 | 支持 | 支持,但未经过充分测试 |
| 1.0 | 不支持 | 支持 | 支持,但未经过充分测试 |
| 0.98 | 支持 | 支持 | 支持,但未经过充分测试(不建议使用) |
| 0.94 | 支持 | 支持 | 未知 |
2、下载hbase。
通过上表可以看出,jdk1.8对hbase1.2有良好的支持,所以我选择下载hbase1.2,一般情况下,我选择到Apache档案馆去选择对应的版本下载,下载地址:http://archive.apache.org/dist/hbase/1.2.0/,选择下载 hbase-1.2.0-bin.tar.gz 文件。
3、上传hbase部署包到/data/softwares目录下。
4、解压hbase到/data/modules/hbase/
tar -vxzf hbase-1.2.0-bin.tar.gz -C /data/modules/hbase/
解压hbase
5、进入/data/modules/hbase/目录下,使用命令chown -hR hbase:hbase hbase-1.2.0/切换hbase-1.2.0及子文件和子文件夹的属主为hbase。
6、配置hbase全局环境变量。
6.1、使用root用户编辑 /etc/profile文件,在文件末尾加入下面代码
export HBASE_HOME=/data/modules/hbase/hbase-1.2.0
export PATH=$HBASE_HOME/bin:$PATH
hbase环境变量配置
加入之后,入下图所示:

6.2、使用命令 source /etc/profile 使配置立即生效。
6.3、测试hbase全局环境变量是否配置成功。
在任意用户、任意目录下执行hbase命令,如果出现下图所示的提示,则配置成功。

7、为hbase指定java位置:如果配置java环境变量可跳过此步骤,如果未配置java环境变量,编辑$HBASE_HOME$/conf/hbase-env.sh文件,取消# export JAVA_HOME=/usr/java/jdk1.8.0/ 行的注释,并设置JAVA_HOME为实际的$JAVA_HOME$。
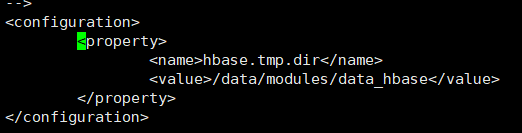
8、指定hbase数据存储位置:因为是独立安装,不能使用hdfs,只能使用默认文件系统(本地文件系统),所以需要手动指定hbase数据存储的位置。编辑$HBASE_HOME$/conf/hbase-site.xml文件,在<configuration>节点中添加一下内容。
<property>
<name>hbase.tmp.dir</name>
<value>/data/modules/data_hbase</value>
</property>
指定hbase数据存储位置
如图所示:
四、启动hbase
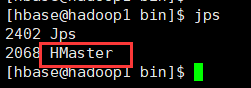
1、执行start-hbase.sh命令启动hbase,可在$HBASE_HOME$/log中查看hbase相关日志信息。

2、使用命令jps查看进程,出现HMaster表示hbase启动成功。
五、hbase简单命令行操作
1、在任意目录下执行 hbase shell 命令进入到hbase的命令行界面。
2、创建一张只有一个列族info的表hbase_test。
命令模板:create 'tableName','columnFamily';
示例:create 'hbase_test','info';
创建表
3、使用list命令查看当前hbase下已有的表,如下图所示:

4、使用put命令向hbase_test表中加载一行三列数据。如图。
模板:put '表名','rowkey','列族名:列明','值'
示例:
put 'hbase_test','key01','info:name','xiaoming';
put 'hbase_test','key01','info:age','ten';
put 'hbase_test','key01','info:sex','man';
加载数据

5、使用scan命令查看表的所有数据。如图。

6、使用get命令精确查找某一个单元格的数据。如图。
模板:get '表名','rowkey','列族:列名'
示例:
get 'hbase_test','key01','info:name'
get查找数据

7、删除表
7.1、删除表之前,先禁用表。命令:disable 'hbase_test'
7.2、删除表:drop 'hbase_test'
8、使用命令 quit 退出hbase命令行界面。
六、使用命令 stop-hbase.sh 停止hbase实例。
七、小结
至此,独立模式下部署hbase已经完成,整个过程中还有很多细节可以更加深入的讨论,但是,先把应用搭建起来,在使用中探究细节,会更直观,不至于那么抽象。
由于本人能力有限,文中若有不足之处,还望指出,谢谢!
hbase系列之:独立模式部署hbase的更多相关文章
- zookeeper系列之:独立模式部署zookeeper服务
一.简述 独立模式是部署zookeeper服务的三种模式中最简单和最基础的模式,只需一台机器即可,独立模式仅适用于学习,开发和生产都不建议使用独立模式.本文介绍以独立模式部署zookeeper服务器的 ...
- Hbase系列-Hbase简介
自1970年以来,关系数据库用于数据存储和维护有关问题的解决方案.大数据的出现后,好多公司实现处理大数据并从中受益,并开始选择像 Hadoop 的解决方案.Hadoop使用分布式文件系统,用于存储大数 ...
- HBase 架构与工作原理2 - HBase 组件
本文系转载,如有侵权,请联系我:likui0913@gmail.com 一.HBase 组件概览 Master-Slave 模式: HBase 体系结构遵循传统的 master-slave 模式,由一 ...
- HBase 系列(二)安装部署
HBase 系列(二)安装部署 本节以 Hadoop-2.7.6,HBase-1.4.5 为例安装 HBase 环境.HBase 也有三种模式:本地模式.伪分布模式.分布模式. 一.环境准备 (1) ...
- hadoop和hbase高可用模式部署
记录apache版本的hadoop和hbase的安装,并启用高可用模式. 1. 主机环境 我这里使用的操作系统是centos 6.5,安装在vmware上,共三台. 主机名 IP 操作系统 用户名 安 ...
- hbase集群安装与部署
1.相关环境 centos7 hadoop2.6.5 zookeeper3.4.9 jdk1.8 hbase1.2.4 本篇文章仅涉及hbase集群的搭建,关于hadoop与zookeeper的相关部 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- hbase高可用集群部署(cdh)
一.概要 本文记录hbase高可用集群部署过程,在部署hbase之前需要事先部署好hadoop集群,因为hbase的数据需要存放在hdfs上,hadoop集群的部署后续会有一篇文章记录,本文假设had ...
- Hbase 系列(一)基本概念
Hbase 系列(一)基本概念 HBase 是 Apache 旗下一个高可靠性.高性能.面向列.可伸缩的分布式存储系统.利用 HBase 技术可在廉价 PC 服务器上搭建起大规模的存储化集群.使用 H ...
随机推荐
- Java中实现PCA降维
package com.excellence.splitsentence; import java.net.UnknownHostException; import java.util.ArrayLi ...
- opencv的安装和卸载
安装 测试环境为centos 安装依赖 yum install cmake gcc gcc-c++ gtk2-devel gimp-develgimp-devel-tools gimp-help-br ...
- Gradle入门(4):依赖管理
在现实生活中,要创造一个没有任何外部依赖的应用程序并非不可能,但也是极具挑战的.这也是为什么依赖管理对于每个软件项目都是至关重要的一部分. 这篇教程主要讲述如何使用Gradle管理我们项目的依赖,我们 ...
- Effective Modern C++翻译(5)-条款4:了解如何观察推导出的类型
条款4:了解如何观察推导出的类型 那些想要知道编译器推导出的类型的人通常分为两种,第一种是实用主义者,他们的动力通常来自于软件产生的问题(例如他们还在调试解决中),他们利用编译器进行寻找,并相信这个能 ...
- Word Ladder II Graph
Given two words (start and end), and a dictionary, find all shortest transformation sequence(s) from ...
- <context-param> 标签引出的 web.xml 文件的加载顺序 [转]
代码示例 : <context-param> <param-name>contextConfigLocation</param-name> <param-va ...
- 多线程同步与并发访问共享资源工具—Lock、Monitor、Mutex、Semaphore
“线程同步”的含义 当一个进程启动了多个线程时,如果需要控制这些线程的推进顺序(比如A线程必须等待B和C线程执行完毕之后才能继续执行),则称这些线程需要进行“线程同步(thread synchro ...
- UVA10054_The Necklace
很简单,求欧拉回路.并且输出. 只重点说一下要用栈来控制输出. 为啥,如图: 如果不用栈,那么1->2->3->1就回来了,接着又输出4->5,发现这根本连接不上去,所以如果用 ...
- 2018 南京icpc现场赛总结
Day 0 提前5个小时从学校出发,在登机口坐下时,飞机还有1个多小时起飞. 航班准时起飞,到了南京以后直接坐地铁到学校附近(南京地铁票也太精致了吧). 因为天已经黑了,就只在学校附近转了一圈就回酒店 ...
- python模拟浏览器爬取数据
爬虫新手大坑:爬取数据的时候一定要设置header伪装成浏览器!!!! 在爬取某财经网站数据时由于没有设置Header信息,直接被封掉了ip 后来设置了Accept.Connection.User-A ...