hadoop安装入门
1.jdk安装和配置
1.1下载最新jdk文件
http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html
1.2配置环境变量
vi /etc/profile
在文件末尾加入如下内容
JAVA_HOME=/usr/local/jdk
JAVA_CLASSPATH=$JAVA_HOME/lib
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME JAVA_CLASSPATH PATH
并使上面文件生效
source /etc/profile
java -version
2.hadoop安装
首先需要配置运行环境,在etc/hadoop/hadoop-env.sh文件中增加
export JAVA_HOME=/usr/local/hadoop
一、配置core-site.xml
/usr/local/hadoop/etc/hadoop/core-site.xml 包含了hadoop启动时的配置信息。
编辑器中打开此文件
sudo gedit /usr/local/hadoop/etc/hadoop/core-site.xml

在该文件的<configuration></configuration>之间增加如下内容:
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
保存、关闭编辑窗口。
最终修改后的文件内容如下:
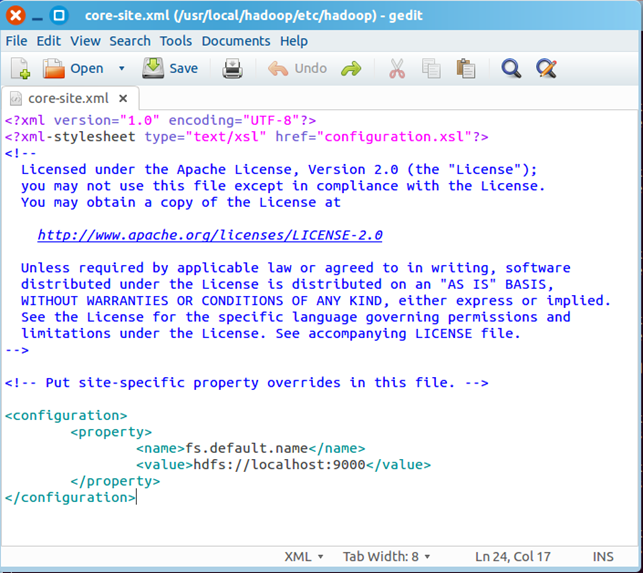
二、配置yarn-site.xml
/usr/local/hadoop/etc/hadoop/yarn-site.xml包含了MapReduce启动时的配置信息。
编辑器中打开此文件
sudo gedit yarn-site.xml

在该文件的<configuration></configuration>之间增加如下内容:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
保存、关闭编辑窗口
最终修改后的文件内容如下
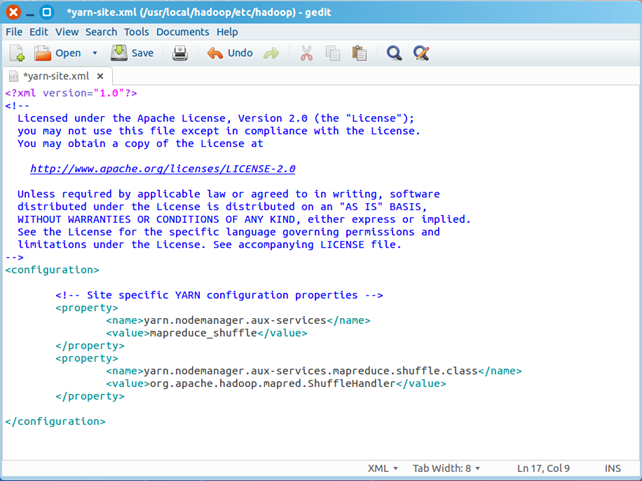
三、创建和配置mapred-site.xml
默认情况下,/usr/local/hadoop/etc/hadoop/文件夹下有mapred.xml.template文件,我们要复制该文件,并命名为mapred.xml,该文件用于指定MapReduce使用的框架。
复制并重命名
cp mapred-site.xml.template mapred-site.xml
编辑器打开此新建文件
sudo gedit mapred-site.xml

在该文件的<configuration></configuration>之间增加如下内容:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
保存、关闭编辑窗口
最终修改后的文件内容如下
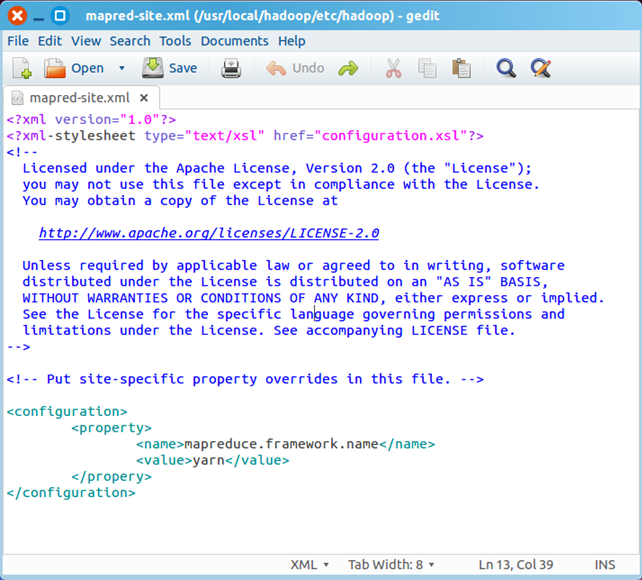
四、配置hdfs-site.xml
/usr/local/hadoop/etc/hadoop/hdfs-site.xml用来配置集群中每台主机都可用,指定主机上作为namenode和datanode的目录。
创建文件夹,如下图所示
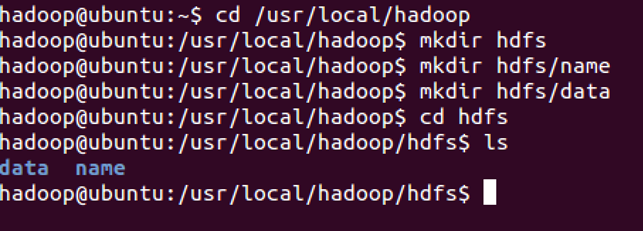
你也可以在别的路径下创建上图的文件夹,名称也可以与上图不同,但是需要和hdfs-site.xml中的配置一致。
编辑器打开hdfs-site.xml
在该文件的<configuration></configuration>之间增加如下内容:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hdfs/data</value>
</property>
保存、关闭编辑窗口
最终修改后的文件内容如下:
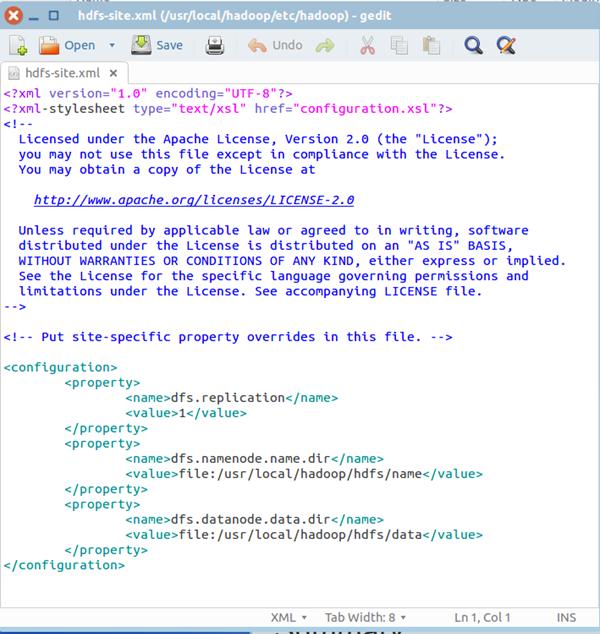
五、格式化hdfs
hdfs namenode -format
只需要执行一次即可,如果在hadoop已经使用后再次执行,会清除掉hdfs上的所有数据。
六、启动Hadoop
经过上文所描述配置和操作后,下面就可以启动这个单节点的集群
执行启动命令:
sbin/start-dfs.sh
执行该命令时,如果有yes /no提示,输入yes,回车即可。
接下来,执行:
sbin/start-yarn.sh
执行完这两个命令后,Hadoop会启动并运行
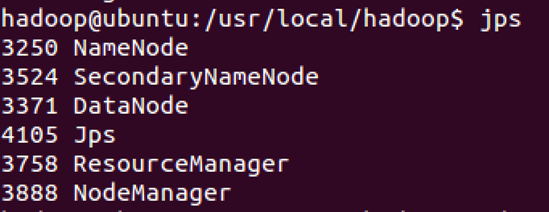
执行 jps命令,会看到Hadoop相关的进程,如下图:
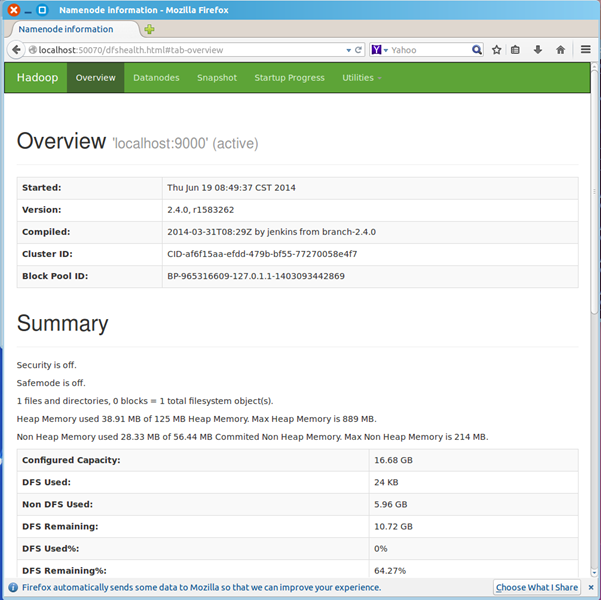
浏览器打开 http://localhost:50070/,会看到hdfs管理页面
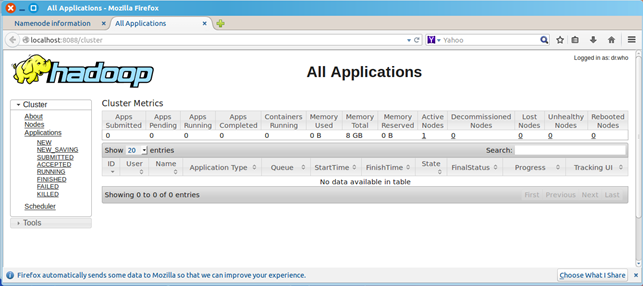
浏览器打开http://localhost:8088,会看到hadoop进程管理页面
七、WordCount验证
dfs上创建input目录
bin/hadoop fs -mkdir -p input

把hadoop目录下的README.txt拷贝到dfs新建的input里
hadoop fs -copyFromLocal README.txt input

运行WordCount
hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.4.0-sources.jar org.apache.hadoop.examples.WordCount input output

可以看到执行过程
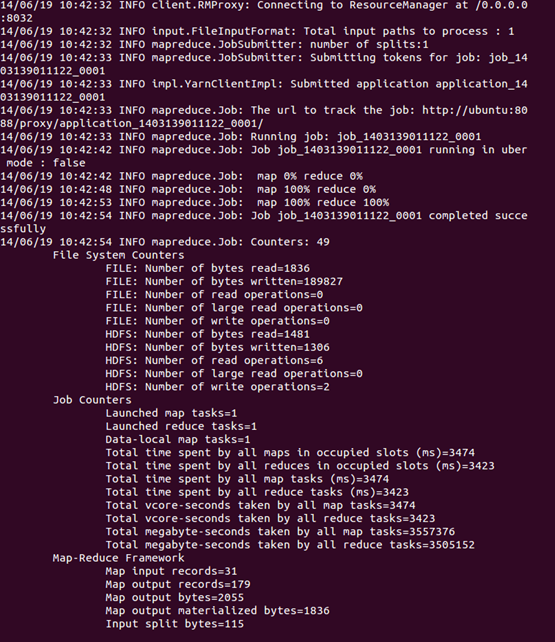
运行完毕后,查看单词统计结果
hadoop fs -cat output/*

hadoop安装入门的更多相关文章
- 大数据入门:Hadoop安装、环境配置及检测
目录 1.导包Hadoop包 2.配置环境变量 3.把winutil包拷贝到Hadoop bin目录下 4.把Hadoop.dll放到system32下 5.检测Hadoop是否正常安装 5.1在ma ...
- [Hadoop入门] - 2 ubuntu安装与配置 hadoop安装与配置
ubuntu安装(这里我就不一一捉图了,只引用一个网址, 相信大家能力) ubuntu安装参考教程: http://jingyan.baidu.com/article/14bd256e0ca52eb ...
- Hadoop快速入门
目的 这篇文档的目的是帮助你快速完成单机上的Hadoop安装与使用以便你对Hadoop分布式文件系统(HDFS)和Map-Reduce框架有所体会,比如在HDFS上运行示例程序或简单作业等. 先决条件 ...
- Hadoop高速入门
Hadoop高速入门 先决条件 支持平台 GNU/Linux是产品开发和执行的平台. Hadoop已在有2000个节点的GNU/Linux主机组成的集群系统上得到验证. Win32平台是作为开发平台支 ...
- linux hadoop安装
linux hadoop安装 本文介绍如何在Linux下安装伪分布式的hadoop开发环境. 在一开始想利用cgywin在 windows下在哪, 但是一直卡在ssh的安装上.所以最后换位虚拟机+ub ...
- 转载:Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
原文 http://www.powerxing.com/install-hadoop/ 当开始着手实践 Hadoop 时,安装 Hadoop 往往会成为新手的一道门槛.尽管安装其实很简单,书上有写到, ...
- hadoop安装遇到的各种异常及解决办法
hadoop安装遇到的各种异常及解决办法 异常一: 2014-03-13 11:10:23,665 INFO org.apache.hadoop.ipc.Client: Retrying connec ...
- hadoop安装实战(mac实操)
集群环境配置参考(http://blog.csdn.net/zcf1002797280/article/details/49500027) 参考:http://www.cnblogs.com/liul ...
- Solr安装入门、查询详解
Solr安装入门:http://www.importnew.com/12607.html 查询详解:http://www.360doc.com/content/14/0306/18/203871_35 ...
随机推荐
- 矩阵链乘(UVa 442)
结构体 struct matrix 用来保存矩阵的行和列: map<string,matrix> 用来保存矩阵名和相应的行列数: stack<string> 用来保存表达式中遇 ...
- 【LOJ】#2537. 「PKUWC2018」Minimax
题解 加法没写取模然后gg了QwQ,de了半天 思想还是比较自然的,线段树合并的维护方法我是真的很少写,然后没想到 很显然,我们有个很愉快的想法是,对于每个节点枚举它所有的叶子节点,对于一个叶子节点的 ...
- EcOS安装
从ubuntu 拷贝到 centos cd /media ls cd ./sf_EcOS 这个目录就是共享目录,名字可能不一样 cp -r studio.zip /home/ 1. 查看版本 cent ...
- mysql proxy代理安装和配置
mysql proxy代理安装和配置 服务器说明: 192.168.1.219 mysql主库(主从复制) 192.168.1.177 mysql从库(主从复制) 192.168.1.202 ...
- Python之路【第十一篇】: 进程与线程理论篇
阅读目录 一 背景知识二 进程2.1 什么是进程2.2 进程与程序的区别2.3 并发与并行2.4 同步与异步2.5 进程的创建2.6 进程的终止2.7 进程的层次结构2.8 进程的状态2.9 进程并发 ...
- React Native踩坑之The SDK directory 'xxxxx' does not exist
相信和我一样,自己摸索配置环境的过程中,第一次配,很可能就遇到了这个比较简单地错误,没有配置sdk环境 解决办法 在电脑,系统环境变量中,添加一个sdk的环境变量 uploading-image-95 ...
- CSUOJ 1726 你经历过绝望吗?两次!BFS+优先队列
Description 4月16日,日本熊本地区强震后,受灾严重的阿苏市一养猪场倒塌,幸运的是,猪圈里很多头猪依然坚强存活.当地15名消防员耗时一天解救围困的"猪坚强".不过与在废 ...
- android studio 汉化包 美化包
韩梦飞沙 韩亚飞 313134555@qq.com yue31313 han_meng_fei_sha 汉化包 百度云盘 下载地址:https://pan.baidu.com/s/1pLjwy ...
- EL表达式和JSTL标准标签库
一.EL表达式 什么是EL表达式 EL(Express Lanuage)表达式可以嵌入在jsp页面内部 减少jsp脚本的编写 EL出现的目的是要替代jsp页面中脚本的编写. EL表达式的作用 EL最主 ...
- 数据准备<5>:变量筛选-实战篇
在上一篇文章<数据准备<4>:变量筛选-理论篇>中,我们介绍了变量筛选的三种方法:基于经验的方法.基于统计的方法和基于机器学习的方法,本文将介绍后两种方法在Python(skl ...