无锁HashMap的原理与实现
转载自: http://coolshell.cn/articles/9703.html
在《疫苗:Java HashMap的死循环》中,我们看到,java.util.HashMap并不能直接应用于多线程环境。对于多线程环境中应用HashMap,主要有以下几种选择:
- 使用线程安全的java.util.Hashtable作为替代。
- 使用java.util.Collections.synchronizedMap方法,将已有的HashMap对象包装为线程安全的。
- 使用java.util.concurrent.ConcurrentHashMap类作为替代,它具有非常好的性能。
而以上几种方法在实现的具体细节上,都或多或少地用到了互斥锁。互斥锁会造成线程阻塞,降低运行效率,并有可能产生死锁、优先级翻转等一系列问题。
CAS(Compare And Swap)是一种底层硬件提供的功能,它可以将判断并更改一个值的操作原子化。关于CAS的一些应用,《无锁队列的实现》一文中有很详细的介绍。
Java中的原子操作
在java.util.concurrent.atomic包中,Java为我们提供了很多方便的原子类型,它们底层完全基于CAS操作。
例如我们希望实现一个全局公用的计数器,那么可以:
|
1
2
3
4
5
6
7
8
9
10
|
private AtomicInteger counter = new AtomicInteger(3);public void addCounter() { for (;;) { int oldValue = counter.get(); int newValue = oldValue + 1; if (counter.compareAndSet(oldValue, newValue)) return; }} |
其中,compareAndSet方法会检查counter现有的值是否为oldValue,如果是,则将其设置为新值newValue,操作成功并返回true;否则操作失败并返回false。
当计算counter新值时,若其他线程将counter的值改变,compareAndSwap就会失败。此时我们只需在外面加一层循环,不断尝试这个过程,那么最终一定会成功将counter值+1。(其实AtomicInteger已经为常用的+1/-1操作定义了incrementAndGet与decrementAndGet方法,以后我们只需简单调用它即可)
除了AtomicInteger外,java.util.concurrent.atomic包还提供了AtomicReference和AtomicReferenceArray类型,它们分别代表原子性的引用和原子性的引用数组(引用的数组)。
无锁链表的实现
在实现无锁HashMap之前,让我们先来看一下比较简单的无锁链表的实现方法。
以插入操作为例:
- 首先我们需要找到待插入位置前面的节点A和后面的节点B。
- 然后新建一个节点C,并使其next指针指向节点B。(见图1)
- 最后使节点A的next指针指向节点C。(见图2)
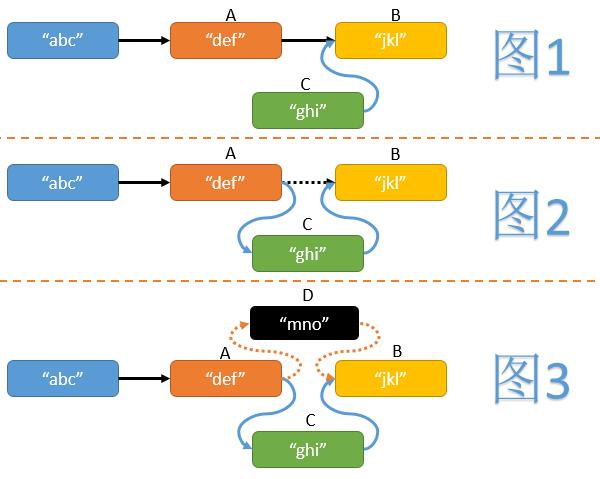
但在操作中途,有可能其他线程在A与B直接也插入了一些节点(假设为D),如果我们不做任何判断,可能造成其他线程插入节点的丢失。(见图3)我们可以利用CAS操作,在为节点A的next指针赋值时,判断其是否仍然指向B,如果节点A的next指针发生了变化则重试整个插入操作。大致代码如下:
|
1
2
3
4
5
6
7
8
|
private void listInsert(Node head, Node c) { for (;;) { Node a = findInsertionPlace(head), b = a.next.get(); c.next.set(b); if (a.next.compareAndSwap(b,c)) return; }} |
(Node类的next字段为AtomicReference<Node>类型,即指向Node类型的原子性引用)
无锁链表的查找操作与普通链表没有区别。而其删除操作,则需要找到待删除节点前方的节点A和后方的节点B,利用CAS操作验证并更新节点A的next指针,使其指向节点B。
无锁HashMap的难点与突破
HashMap主要有插入、删除、查找以及ReHash四种基本操作。一个典型的HashMap实现,会用到一个数组,数组的每项元素为一个节点的链表。对于此链表,我们可以利用上文提到的操作方法,执行插入、删除以及查找操作,但对于ReHash操作则比较困难。
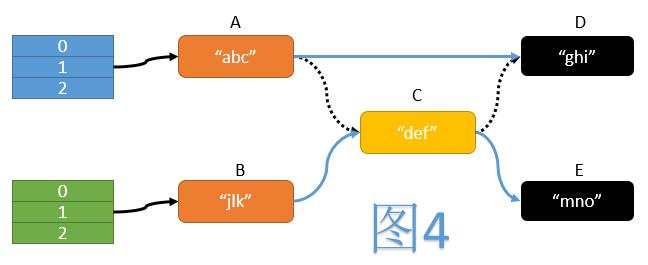
如图4,在ReHash过程中,一个典型的操作是遍历旧表中的每个节点,计算其在新表中的位置,然后将其移动至新表中。期间我们需要操纵3次指针:
- 将A的next指针指向D
- 将B的next指针指向C
- 将C的next指针指向E
而这三次指针操作必须同时完成,才能保证移动操作的原子性。但我们不难看出,CAS操作每次只能保证一个变量的值被原子性地验证并更新,无法满足同时验证并更新三个指针的需求。
于是我们不妨换一个思路,既然移动节点的操作如此困难,我们可以使所有节点始终保持有序状态,从而避免了移动操作。在典型的HashMap实现中,数组的长度始终保持为2i,而从Hash值映射为数组下标的过程,只是简单地对数组长度执行取模运算(即仅保留Hash二进制的后i位)。当ReHash时,数组长度加倍变为2i+1,旧数组第j项链表中的每个节点,要么移动到新数组中第j项,要么移动到新数组中第j+2i项,而它们的唯一区别在于Hash值第i+1位的不同(第i+1位为0则仍为第j项,否则为第j+2i项)。
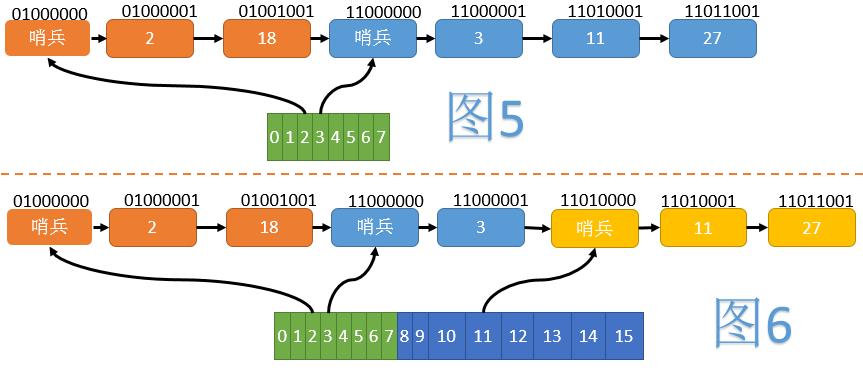
如图5,我们将所有节点按照Hash值的翻转位序(如1101->1011)由小到大排列。当数组大小为8时,2、18在一个组内;3、11、27在另一个组内。每组的开始,插入一个哨兵节点,以方便后续操作。为了使哨兵节点正确排在组的最前方,我们将正常节点Hash的最高位(翻转后变为最低位)置为1,而哨兵节点不设置这一位。
当数组扩容至16时(见图6),第二组分裂为一个只含3的组和一个含有11、27的组,但节点之间的相对顺序并未改变。这样在ReHash时,我们就不需要移动节点了。
实现细节
由于扩容时数组的复制会占用大量的时间,这里我们采用了将整个数组分块,懒惰建立的方法。这样,当访问到某下标时,仅需判断此下标所在块是否已建立完毕(如果没有则建立)。
另外定义size为当前已使用的下标范围,其初始值为2,数组扩容时仅需将size加倍即可;定义count代表目前HashMap中包含的总节点个数(不算哨兵节点)。
初始时,数组中除第0项外,所有项都为null。第0项指向一个仅有一个哨兵节点的链表,代表整条链的起点。初始时全貌见图7,其中浅绿色代表当前未使用的下标范围,虚线箭头代表逻辑上存在,但实际未建立的块。
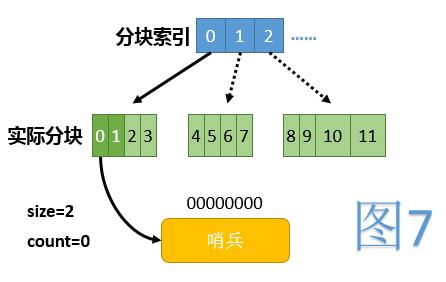
初始化下标操作
数组中为null的项都认为处于未初始化状态,初始化某个下标即代表建立其对应的哨兵节点。初始化是递归进行的,即若其父下标未初始化,则先初始化其父下标。(一个下标的父下标是其移除最高二进制位后得到的下标)大致代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
|
private void initializeBucket(int bucketIdx) { int parentIdx = bucketIdx ^ Integer.highestOneBit(bucketIdx); if (getBucket(parentIdx) == null) initializeBucket(parentIdx); Node dummy = new Node(); dummy.hash = Integer.reverse(bucketIdx); dummy.next = new AtomicReference<>(); setBucket(bucketIdx, listInsert(getBucket(parentIdx), dummy));} |
其中getBucket即封装过的获取数组某下标内容的方法,setBucket同理。listInsert将从指定位置开始查找适合插入的位置插入给定的节点,若链表中已存在hash相同的节点则返回那个已存在的节点;否则返回新插入的节点。
插入操作
- 首先用HashMap的size对键的hashCode取模,得到应插入的数组下标。
- 然后判断该下标处是否为null,如果为null则初始化此下标。
- 构造一个新的节点,并插入到适当位置,注意节点中的hash值应为原hashCode经过位翻转并将最低位置1之后的值。
- 将节点个数计数器加1,若加1后节点过多,则仅需将size改为size*2,代表对数组扩容(ReHash)。
查找操作
- 找出待查找节点在数组中的下标。
- 判断该下标处是否为null,如果为null则返回查找失败。
- 从相应位置进入链表,顺次寻找,直至找出待查找节点或超出本组节点范围。
删除操作
- 找出应删除节点在数组中的下标。
- 判断该下标处是否为null,如果为null则初始化此下标。
- 找到待删除节点,并从链表中删除。(注意由于哨兵节点的存在,任何正常元素只被其唯一的前驱节点所引用,不存在被前驱节点与数组中指针同时引用的情况,从而不会出现需要同时修改多个指针的情况)
- 将节点个数计数器减1。
参考文献
《Split-Ordered Lists: Lock-Free Extensible Hash Tables》
(全文完)
无锁HashMap的原理与实现的更多相关文章
- HashMap实现原理、核心概念、关键问题的总结
简单罗列一下较为重要的点: 同步的问题 碰撞处理问题 rehash的过程 put和get的处理过程 HashMap基础: HashMap的理论基础:维基百科哈希表 JDK中HashMap的描述:Has ...
- java 多线程12 : 无锁 实现CAS原子性操作----原子类
由于java 多线程11:volatile关键字该文讲道可以使用不带锁的情况也就是无锁使变量变成可见,这里就理解下如何在无锁的情况对线程变量进行CAS原子性及可见性操作 我们知道,在并发的环境下,要实 ...
- Java高并发程序设计学习笔记(四):无锁
转自:https://blog.csdn.net/dataiyangu/article/details/86440836#1__3 1. 无锁类的原理详解简介:1.1. CAS1.2. CPU指令2. ...
- Java高并发-无锁
一.无锁类的原理 1.1 CAS CAS算法的过程是这样:它包含3个参数CAS(V,E,N).V表示要更新的变量,E表示预期值,N表示新值.仅当V值等于E值时,才会将V的值设为N,如果V值和E值不同, ...
- HashMap的原理与实 无锁队列的实现Java HashMap的死循环 red black tree
http://www.cnblogs.com/fornever/archive/2011/12/02/2270692.html https://zh.wikipedia.org/wiki/%E7%BA ...
- Java CAS同步机制 原理详解(为什么并发环境下的COUNT自增操作不安全): Atomic原子类底层用的不是传统意义的锁机制,而是无锁化的CAS机制,通过CAS机制保证多线程修改一个数值的安全性。
精彩理解: https://www.jianshu.com/p/21be831e851e ; https://blog.csdn.net/heyutao007/article/details/19 ...
- 【Java并发编程】2、无锁编程:lock-free原理;CAS;ABA问题
转自:http://blog.csdn.net/kangroger/article/details/47867269 定义 无锁编程是指在不使用锁的情况下,在多线程环境下实现多变量的同步.即在没有线程 ...
- CAS无锁实现原理以及ABA问题
CAS(比较与交换,Compare and swap) 是一种有名的无锁算法.无锁编程,即不使用锁的情况下实现多线程之间的变量同步,也就是在没有线程被阻塞的情况下实现变量的同步,所以也叫非阻塞同步(N ...
- CAS无锁机制原理
原子类 java.util.concurrent.atomic包:原子类的小工具包,支持在单个变量上解除锁的线程安全编程 原子变量类相当于一种泛化的 volatile 变量,能够支持原子的和有条件的读 ...
随机推荐
- C/C++ -- Gui编程 -- Qt库的使用 -- 构造函数中添加组件
在构造函数中定义一个标签,设置自动换行和样式表 -----mywidget.cpp----- #include "mywidget.h" #include "ui_myw ...
- 深度学习--RNN,LSTM
一.RNN 1.定义 递归神经网络(RNN)是两种人工神经网络的总称.一种是时间递归神经网络(recurrent neural network),另一种是结构递归神经网络(recursive neur ...
- c++ ‘nullptr’ 在此作用域中尚未声明
编译加上如下选项:-std=c++11 g++ 1.cpp -o k -std=c++11
- XML CData 处理
调研了 JAXB.XMLMapper(jackson) 具体方式 实现 优势 JAXB 1. 需要增加 CDATA 的Adaptor 2. 需要增加对非CDATA 的 CharacterEscapeH ...
- C++11中右值引用和移动语义
目录 左值.右值.左值引用.右值引用 右值引用和统一引用 使用右值引用,避免深拷贝,优化程序性能 std::move()移动语义 std::forward()完美转发 容器中的emplace_back ...
- Calendar详解
(在文章的最后,将会介绍Date类,如果有兴趣,可以直接翻到最后去阅读) 究竟什么是一个 Calendar 呢?中文的翻译就是日历,那我们立刻可以想到我们生活中有阳(公)历.阴(农)历之分.它们的区别 ...
- Kaggle(一):房价预测
Kaggle(一) 房价预测 (随机森林.岭回归.集成学习) 项目介绍:通过79个解释变量描述爱荷华州艾姆斯的住宅的各个方面,然后通过这些变量训练模型, 来预测房价. kaggle项目链接:ht ...
- unity编辑器之自动提示订外卖
1.问题来源 事情一忙,忘记叫外卖是常有的事,到了12点同事们都吃上了饭,你却只能挨饿,估计很多程序员都有这种经历吧,这里我们来做一个unity编辑器准点提示订外卖服务的功能. 2. ...
- 三种数据库访问——原生JDBC
原生的JDBC编程主要分一下几个步骤: (原生的JDBC编程指,仅应用java.sql包下的接口和数据库驱动类编程,而不借助任何框架) 1. 加载JDBC驱动程序: 2. 负责管理JDBC驱动程序的类 ...
- 什么是memcached?
缓存是一种常驻与内存的内存数据库,内存的读取速度远远快于程序在磁盘读取数据的速度.我们在设计程序的时候常常会考虑使用缓存,将经常访问的数据放到内存上面这样可以提高访问数据的速度,同时可以降低磁盘或数据 ...