Druid.io通过NiFi摄取流数据
NiFi是一个易于使用,功能强大且可靠的系统来处理和分发数据。
本文讲述如何用NiFi将Http的Json数据传到Druid。国外的一篇文章讲到如何用NiFi将推文传到Druid,https://community.hortonworks.com/articles/177561/streaming-tweets-with-nifi-kafka-tranquility-druid.html,数据来源稍有不同,但是走下来的流程大同小异,国情的原因我们使用自己Http来源代替:)
1、系统和环境
系统环境
- centos7
- jdk1.8.0_131
Http数据来源
关键软件
- NiFi.1.2.0汉化版
- Druid.0.12.0
- tranquility.0.8.0
2、摄取步骤
软件安装
略。网上可查,问题不大。
整体流程图
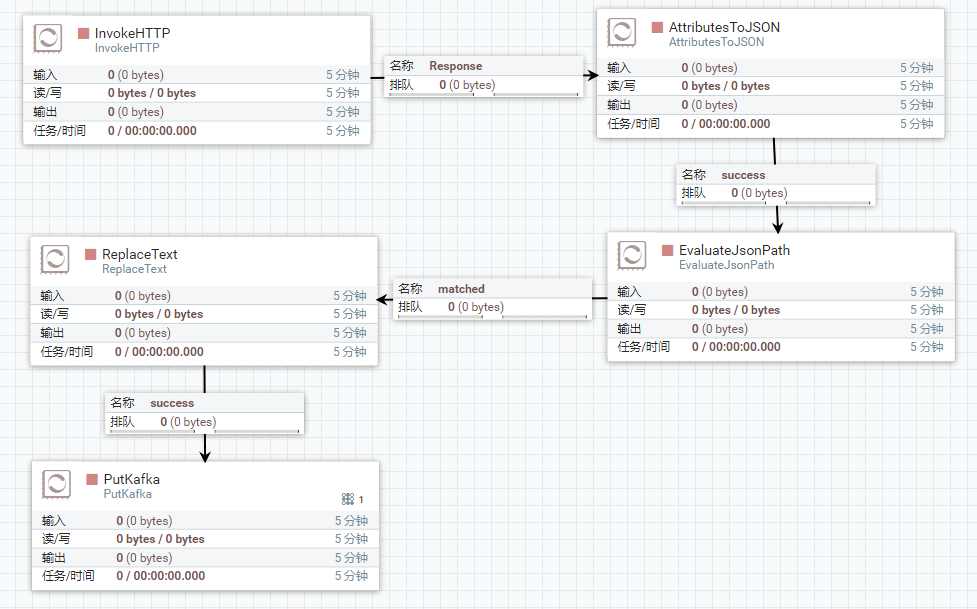
数据来源
2.1、之所以选用IPProxyTool,一是数据返回json,二是较短时间可以产生新的数据。如果有更好的模拟数据,可以替换这个数据来源。

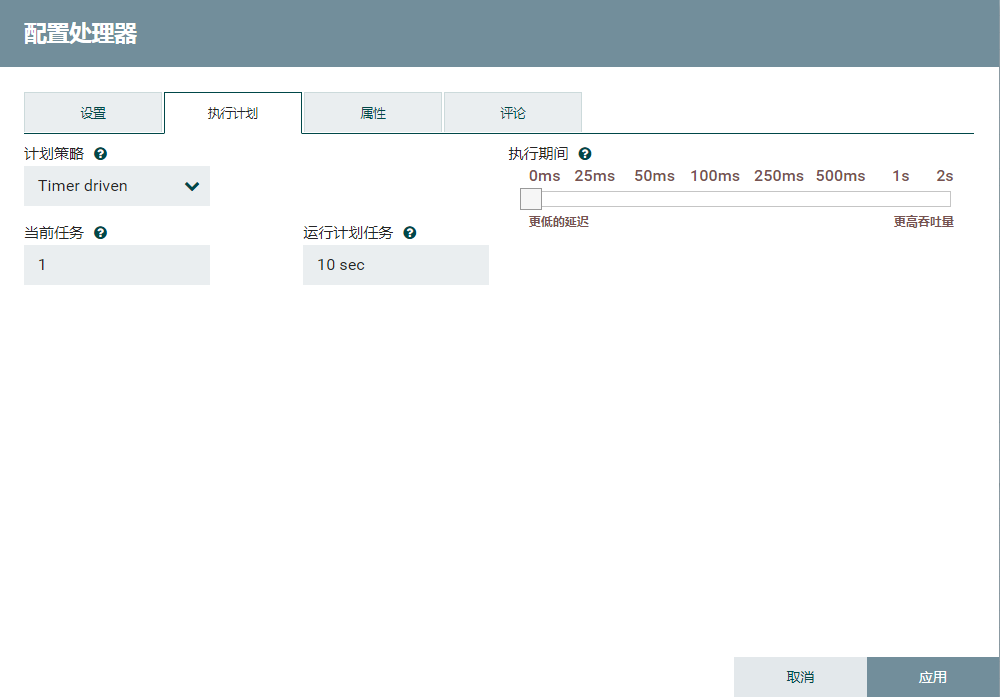
schedule的tab页改为10s,即10s后同步一次数据。
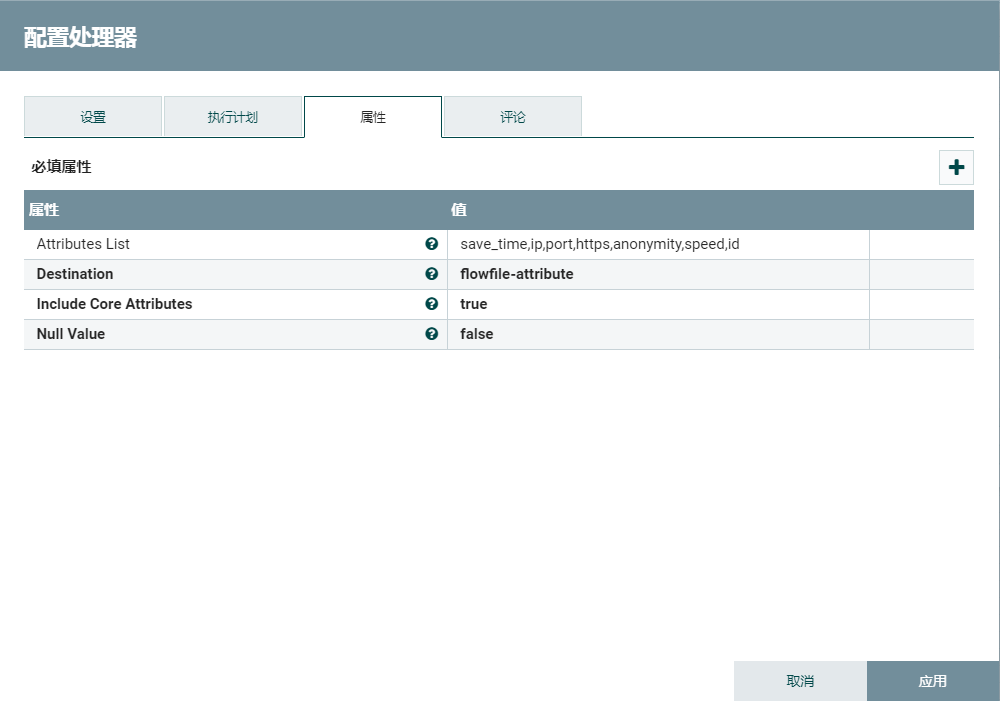
2.1、转换json
使用AttributesToJSON提取相关的json字段。
2.2、提取json
EvaluateJsonPath只提取json数组中第一个json对象。Druid不接受json数组,相关Druid数据格式支持http://druid.io/docs/0.12.1/ingestion/data-formats.html

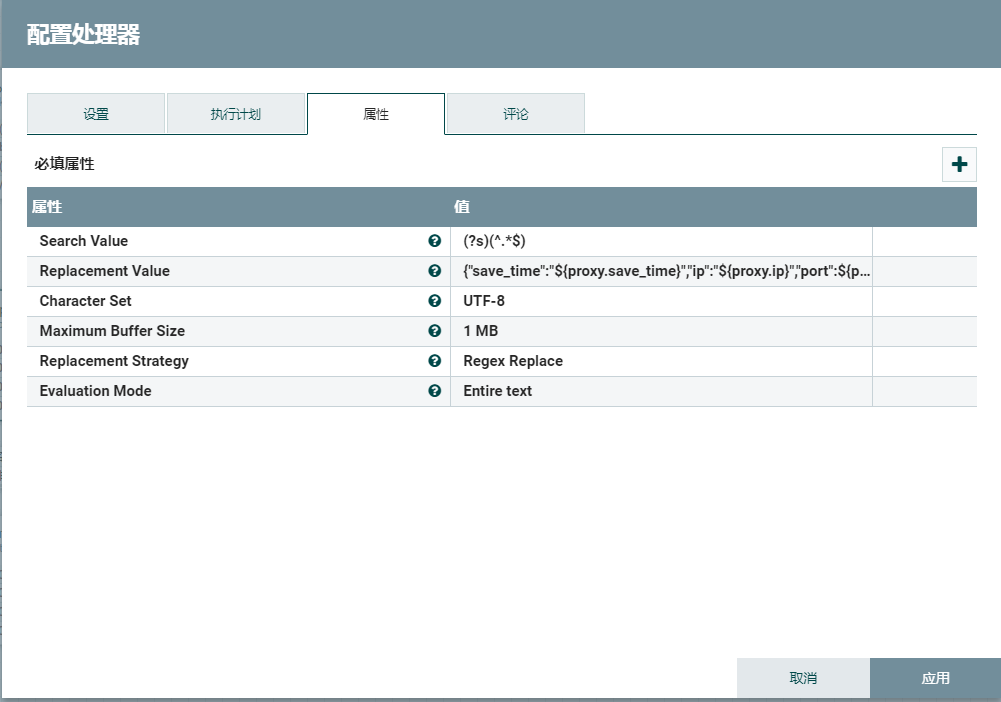
2.3、扁平化json
ReplaceText将格式化的json转为单行的json。Druid不能识别格式化的json,相关Druid数据格式支持http://druid.io/docs/0.12.1/ingestion/data-formats.html
2.4、输出数据到kafka
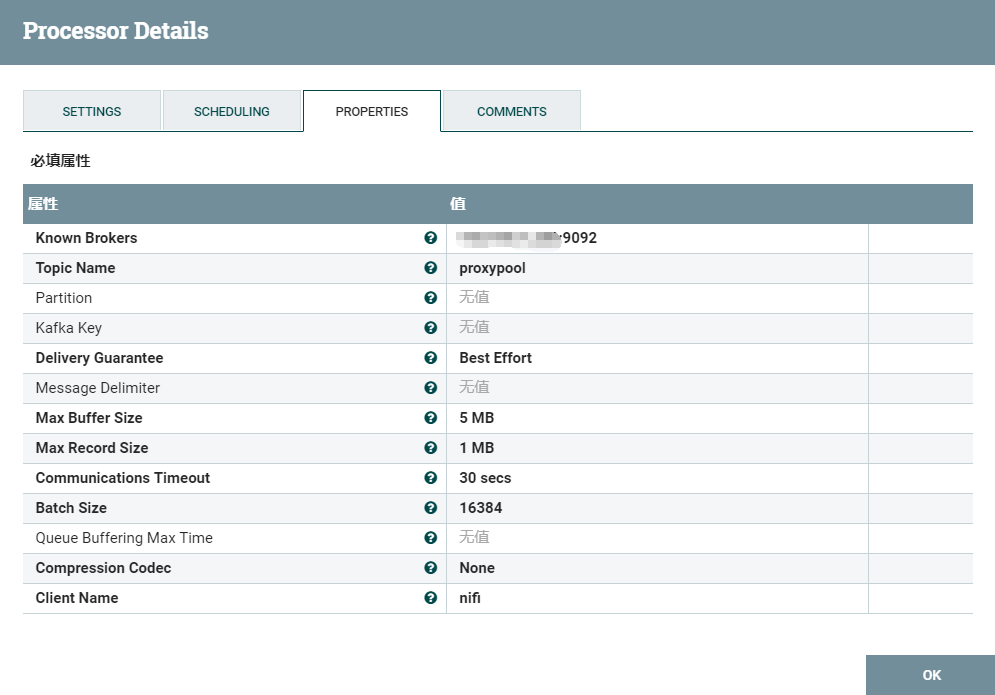
2.5、kafka创建新的主题
cd /opt/kafka
# 启动kafka
./bin/kafka-server-start.sh config/server.properties
./kafka-topics.sh --create \
--zookeeper localhost:2181 \
--replication-factor 1 \
--partitions 1 \
--topic proxypool
2.6、创建Druid流任务json
{
"dataSources" : {
"proxypool" : {
"spec" : {
"dataSchema" : {
"dataSource" : "proxypool",
"parser" : {
"type" : "string",
"parseSpec" : {
"timestampSpec" : {
"column" : "save_time",
"format" : "yyyy-MM-dd HH:mm:ss"
},
"dimensionsSpec" : {
"dimensions" : [
"ip",
"port",
"https",
"anonymity",
"id"
]
},
"format" : "json"
}
},
"granularitySpec" : {
"type" : "uniform",
"segmentGranularity" : "day",
"queryGranularity" : "none"
},
"metricsSpec" : [
{
"name" : "count",
"type" : "count"
},
{
"name" : "speed",
"type" : "doubleSum",
"fieldName" : "speed"
}
]
},
"ioConfig" : {
"type" : "realtime"
},
"tuningConfig" : {
"type" : "realtime",
"maxRowsInMemory" : "100000",
"intermediatePersistPeriod" : "PT10M",
"windowPeriod" : "PT720000M"
}
},
"properties" : {
"task.partitions" : "1",
"task.replicants" : "1",
"topicPattern" : "proxypool"
}
}
},
"properties" : {
"zookeeper.connect" : "localhost:2181",
"druid.discovery.curator.path" : "/druid/discovery",
"druid.selectors.indexing.serviceName" : "druid/overlord",
"commit.periodMillis" : "15000",
"consumer.numThreads" : "2",
"kafka.zookeeper.connect" : "localhost:2181",
"kafka.group.id" : "tranquility-kafka"
}
}
复制这个json到:
cp proxypool-kafka.json /opt/druid/conf-quickstart/tranquility/
2.7、安装tranquility
cd /opt/druid/conf-quickstart/tranquility
curl -O http://static.druid.io/tranquility/releases/tranquility-distribution-0.8.0.tgz
tar xzvf tranquility-distribution-0.8.0.tgz
tranquility-distribution-0.8.0
cd tranquility-distribution-0.8.0/
bin/tranquility kafka -configFile ../proxypool-kafka.json
在NiFi右键运行,Druid就能间隔10s摄取Http的数据了:)
转换json的步骤可以视情况去掉(例如非json数组或者非格式化的json)
Druid.io通过NiFi摄取流数据的更多相关文章
- Druid.io系列(九):数据摄入
1. 概述 Druid的数据摄入主要包括两大类: 1. 实时输入摄入:包括Pull,Push两种 - Pull:需要启动一个RealtimeNode节点,通过不同的Firehose摄取不同种类的数据源 ...
- Druid.io索引过程分析——时间窗,列存储,LSM树,充分利用内存,concise压缩
Druid底层不保存原始数据,而是借鉴了Apache Lucene.Apache Solr以及ElasticSearch等检索引擎的基本做法,对数据按列建立索引,最终转化为Segment,用于存储.查 ...
- Druid.io系列(一):简介
原文链接: https://blog.csdn.net/njpjsoftdev/article/details/52955676 Druid.io(以下简称Druid)是面向海量数据的.用于实时查询与 ...
- Druid.io系列(七):架构剖析
1. 前言 Druid 的目标是提供一个能够在大数据集上做实时数据摄入与查询的平台,然而对于大多数系统而言,提供数据的快速摄入与提供快速查询是难以同时实现的两个指标.例如对于普通的RDBMS,如果想要 ...
- Druid.io系列(四):索引过程分析
原文链接: https://blog.csdn.net/njpjsoftdev/article/details/52956083 Druid底层不保存原始数据,而是借鉴了Apache Lucene.A ...
- kafka实时流数据架构
初识kafka https://www.cnblogs.com/wenBlog/p/9550039.html 简介 Kafka经常用于实时流数据架构,用于提供实时分析.本篇将会简单介绍kafka以及它 ...
- Java nio 笔记:系统IO、缓冲区、流IO、socket通道
一.Java IO 和 系统 IO 不匹配 在大多数情况下,Java 应用程序并非真的受着 I/O 的束缚.操作系统并非不能快速传送数据,让 Java 有事可做:相反,是 JVM 自身在 I/O 方面 ...
- io系列之字符流
java中io流系统庞大,知识点众多,作为小白通过五天的视频书籍学习后,总结了io系列的随笔,以便将来复习查看. 本篇为此系列随笔的第一篇:io系列之字符流. IO流 :对数据的传输流向进行操作,ja ...
- druid.io本地集群搭建 / 扩展集群搭建
druid.io 是一个比较重型的数据库查询系统,分为5种节点 . 在此就不对数据库进行介绍了,如果有疑问请参考白皮书: http://pan.baidu.com/s/1eSFlIJS 单台机器的集群 ...
随机推荐
- syntax error:unexpected end of file
将window上编辑的xxy1.sh脚本上传到linux上,并执行的时候提示 xxy1.sh: line 17: syntax error: unexpected end of file 但是通过ca ...
- 工作中常用到的Linux命令
ps: (ps的参数分成basic, list, output, thread, miscellaneous) (basic) -e / -A 显示所有进程 (output) -o 输出指定字段 ls ...
- Hadoop 2.6.0 HIVE 2.1.1配置
我用的hadoop 是2.6.0 版本 ,hive 是 2.1.1版本进入:/home/zkpk/apache-hive-2.1.1-bin/执行hive 后报错: (1)Exception in t ...
- Lottie开源库实现Android动画效果
Lottie简介 Lottie是一个支持Android.iOS.React Native,并由Adobe After Effects制作aep格式的动画,然后经由bodymovin插件转化渲染为jso ...
- 第215天:Angular---指令
指令(Directive) AngularJS 有一套完整的.可扩展的.用来帮助 Web 应用开发的指令集 在 DOM 编译期间,和 HTML 关联着的指令会被检测到,并且被执行 在 AngularJ ...
- BZOJ4519 CQOI2016不同的最小割(最小割+分治)
最小割树:新建一个图,包含原图的所有点,初始没有边.任取两点跑最小割,给两点连上权值为最小割的边,之后对于两个割集分别做同样的操作.最后会形成一棵树,树上两点间路径的最小值即为两点最小割.证明一点都不 ...
- Java参数引用传递之例外:null
今天写链表的时候写了一个函数,实参是一个空链表,应该是按引用传参,但是在函数内修改了链表,外部的链表没有变化. 原来是null作为参数传递的时候,就不是引用传参了. 引自:http://blog.cs ...
- MT【150】源自斐波那契数列
(清华2017.4.29标准学术能力测试7) 已知数列$\{x_n\}$,其中$x_1=a$,$x_2=b$,$x_{n+1}=x_n+x_{n-1}$($a,b$是正整数),若$2008$为数列中的 ...
- 2017 3 11 分治FFT
考试一道题的递推式为$$f[i]=\sum_{j=1}^{i} j^k \times (i-1)! \times \frac{f[i-j]}{(i-j)!}$$这显然是一个卷积的形式,但$f$需要由自 ...
- 【THUSC2017】杜老师
题目描述 杜老师可是要打+∞年World Final的男人,虽然规则不允许,但是可以改啊! 但是今年WF跟THUSC的时间这么近,所以他造了一个idea就扔下不管了…… 给定L,R,求从L到R的这R− ...