ScaleIO与XtremSW Cache如何集成呢?
在ScaleIO上, XtremSW Cache主要有两种部署方式:
- 把XtremSW Cache在每台server的内部用作cache - 在ScaleIO Data Server(SDS)下做cache. 这个和传统的SAN世界中的VNX Fast cache或VMAX cache的概念差不多.
- 把XtremSW Cache用在应用程序端作cache - 在ScaleIO Data Client(SDC)下做cache. 这个在概念上与数据中心里的server side caching差不多.
Caching inside each server (caching below the SDS)
===============
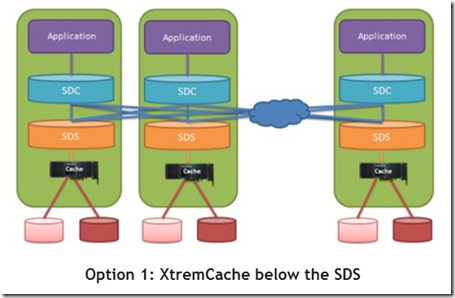
这么配置的优势如下:
- 数据一致性更佳: 对于数据共享要求较高的应用程序来说, 数据一致性至关重要. 如果有一片数据被一台Applicaiton Host改掉了, 与此同时这环境中的另一台host正在修改共享存储上的相同的这一片数据. 这种情形会导致数据毁坏和各种各样的不一致. 把XtremCache放在SDS下面, 我们就可以在不冒这种风险的前提下进行加速了, 如此就获得了一致性.
- 不存在冷缓存(cold cache): 由于缓存是在存储端而不是应用程序端进行的,缓存是不会被应用程序主机的failover所影响. 所以, 也就不会有冷缓存需要"预热"(warm up)的时间了, 所以性能也就更加稳定. 有很多环境中failover是的确会发生的, 不光是由于出错(failure),(可以被认为是较少发生的情况), 还有主要是为了负载均衡做的failover. 在ScaleIO控制的节点集群中, 这就很有关系了, 因为scaleIO中的计算资源被赋予计算任务是很有弹性的.
- 缓存会有更好的利用率: 通过把缓存部署在每个节点的SDS之下, 我们生成了一个很大的共享的缓存层, 从而cluster中的所有的应用程序都可以使用cache了. 比如说你有20个节点, 有20个不同的应用程序, 有20块350GB的XtremCache卡. 你一共有7 TB的flash 缓存. 有些应用程序缓存会用的多一些, 有些由于需求少,所以比较少的缓存就可以满足它了 - 这都跟应用程序的数据集的大小有关. 通过在每台server中设置缓存, 你得到了一个7 TB的flash cache可以被动态的分派给需要的用户. 所以, 对于活跃的需要消耗上TB的缓存的应用程序, 这可以极大地提高缓存的命中率和整体性能.
Application side caching (caching above the SDC)
=================
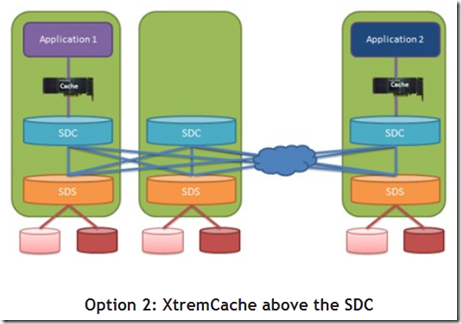
缓存仅被部署在某台applicaiton server下, 如此配置的优势如下:
- 性能: 如果环境对于磁盘延迟非常敏感(零点几毫秒的提高就能明显的体现出来), 那么这种部署方式就比较合适了, 因为数据比较靠近应用, 缓存并不会消耗网络带宽.
- 部署考虑: 这种部署的颗粒度更细. 如果仅有某几个应用需要加速, 那么部署XtremCache专门加速某几台虚机就可以了. 而且这里也没有前面提到的一致性问题.
- 数据一致: 缓存卡的软件必须支持对data corruption的保护, XtremCache是有原生支持的(支持Oracle RAC, 和active / passive clusters 诸如MSCS, VCS 或 native Linux clustering).
总之, 要么Xtrem卡部署在SDS之下, 要么部署在SDC之上. 部署在SDS之下, ScaleIO是知晓Xtrem卡的存在的; 部署在SDC之上, 那么这就跟ScaleIO没啥关系了, 没有ScaleIO的时候怎么样, 还是怎么样.
资料来源
=================
The Whole is Greater than the Sum
http://www.scaleio.com/blog/entry/the-whole-is-greater-than-the-sum
ScaleIO与XtremSW Cache如何集成呢?的更多相关文章
- spring boot redis 缓存(cache)集成
Spring Boot 集成教程 Spring Boot 介绍 Spring Boot 开发环境搭建(Eclipse) Spring Boot Hello World (restful接口)例子 sp ...
- Linux Free命令各数字含义及Buffer和Cache的区别
Linux Free命令各数字含义及Buffer和Cache的区别 Free 命令的各数字含义 命令演示 [root@vm1 ~]# free total used free shared buffe ...
- 002-spring cache 基于声明式注解的缓存-02-CachePut、CacheEvict、Caching、CacheConfig、EnableCaching、自定义
1.2.CachePut annotation 在支持Spring Cache的环境下,对于使用@Cacheable标注的方法,Spring在每次执行前都会检查Cache中是否存在相同key的缓存元素 ...
- SpringBoot | 第十一章:Redis的集成和简单使用
前言 上几节讲了利用Mybatis-Plus这个第三方的ORM框架进行数据库访问,在实际工作中,在存储一些非结构化或者缓存一些临时数据及热点数据时,一般上都会用上mongodb和redis进行这方面的 ...
- 一个缓存使用案例:Spring Cache VS Caffeine 原生 API
最近在学习本地缓存发现,在 Spring 技术栈的开发中,既可以使用 Spring Cache 的注解形式操作缓存,也可用各种缓存方案的原生 API.那么是否 Spring 官方提供的就是最合适的方案 ...
- ARM之cache
一. 什么是cache 1.1. cache简介 a. Cache 即高速缓冲存储器,是位于 CPU 与内存之间的高速存储器,它的容量比内存小但交换速度快. b. ARM处理器的主频为上百M甚至几G, ...
- spring boot集成mybatis(1)
Spring Boot 集成教程 Spring Boot 介绍 Spring Boot 开发环境搭建(Eclipse) Spring Boot Hello World (restful接口)例子 sp ...
- spring boot rest 接口集成 spring security(2) - JWT配置
Spring Boot 集成教程 Spring Boot 介绍 Spring Boot 开发环境搭建(Eclipse) Spring Boot Hello World (restful接口)例子 sp ...
- spring boot rest 接口集成 spring security(1) - 最简配置
Spring Boot 集成教程 Spring Boot 介绍 Spring Boot 开发环境搭建(Eclipse) Spring Boot Hello World (restful接口)例子 sp ...
随机推荐
- HashMap+双向链表手写LRU缓存算法/页面置换算法
import java.util.Hashtable; class DLinkedList { String key; //键 int value; //值 DLinkedList pre; //双向 ...
- 关于table边框,设置了border-collapse:collapse之后,设置border-radius没效果
做项目遇到边框需要设置圆角,然后发现在设置了border-collapse:collapse之后,border-radius:10px不起作用了,发现这个是css本身的问题,两者不能混在一起使用. 代 ...
- Json格式String类型字符串转为Map工具类
package agriculture_implement.util; import com.google.gson.Gson; import com.google.gson.JsonSyntaxEx ...
- java面试数据类型
1. Java的数据类型? 2. Java的封装类型? 3. 基本类型和封装类型的区别? 基本类型只能按值传递,而对应的封装类是按引用传递的. 基本类型是在堆栈上创建的,而所有的对象类型都是在堆上创建 ...
- 网站(Web)压测工具Webbench源码分析
一.我与webbench二三事 Webbench是一个在linux下使用的非常简单的网站压测工具.它使用fork()模拟多个客户端同时访问我们设定的URL,测试网站在压力下工作的性能.Webbench ...
- UVALive 4425 Another Brick in the Wall 暴力
C - Another Brick in the Wall Time Limit:3000MS Memory Limit:0KB 64bit IO Format:%lld & ...
- Jmeter+JDK的安装学习笔记
第一步:首先从jmeter的官网下载jmeter,目前最新版本为3.3,支持的JDK最高为1.8 下载地址: jmeter:http://jmeter.apache.org/download_jmet ...
- [JAVA] JAVA JDK 安装配置
JDK 安装 下载安装 下载JDK 从oracle官方网站下载并安装JDK. 下载使用文档 从oracle官方网站下载使用帮助文档. 安装库源文件 源文件位于安装目录的 /Library/Java/J ...
- [Dynamic Language] Python定时任务框架
APScheduler是一个Python定时任务框架,使用起来十分方便.提供了基于日期.固定时间间隔以及crontab类型的任务,并且可以持久化任务.并以daemon方式运行应用. 在APSchedu ...
- Effective JavaScript Item 35 使用闭包来保存私有数据
本系列作为EffectiveJavaScript的读书笔记. JavaScript的对象系统从其语法上而言并不鼓舞使用信息隐藏(Information Hiding).由于当使用诸如this.name ...