Hadoop学习之路(四)Hadoop集群搭建和简单应用
概念了解
主从结构:在一个集群中,会有部分节点充当主服务器的角色,其他服务器都是从服务器的角色,当前这种架构模式叫做主从结构。
主从结构分类:
1、一主多从
2、多主多从
Hadoop中的HDFS和YARN都是主从结构,主从结构中的主节点和从节点有多重概念方式:
1、主节点 从节点
2、master slave
3、管理者 工作者
4、leader follower
Hadoop集群中各个角色的名称:
| 服务 | 主节点 | 从节点 |
| HDFS | NameNode | DataNode |
| YARN | ResourceManager | NodeManager |
集群服务器规划
使用4台CentOS-6.7虚拟机进行集群搭建

软件安装步骤概述
1、获取安装包
2、解压缩和安装
3、修改配置文件
4、初始化,配置环境变量,启动,验证
Hadoop安装
1、规划
规划安装用户:hadoop
规划安装目录:/home/hadoop/apps
规划数据目录:/home/hadoop/data
注:apps和data文件夹需要自己单独创建
2、上传解压缩
注:使用hadoop用户
[hadoop@hadoop1 apps]$ ls
hadoop-2.7.-centos-6.7.tar.gz
[hadoop@hadoop1 apps]$ tar -zxvf hadoop-2.7.-centos-6.7.tar.gz
3、修改配置文件
配置文件目录:/home/hadoop/apps/hadoop-2.7.5/etc/hadoop

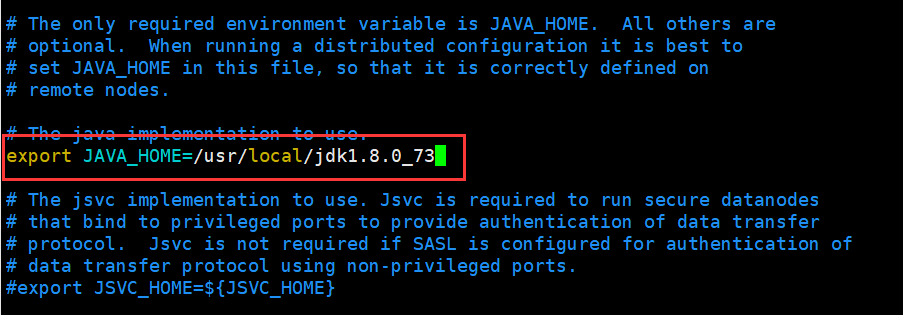
A. hadoop-env.sh
[hadoop@hadoop1 hadoop]$ vi hadoop-env.sh
修改JAVA_HOME
export JAVA_HOME=/usr/local/jdk1..0_73
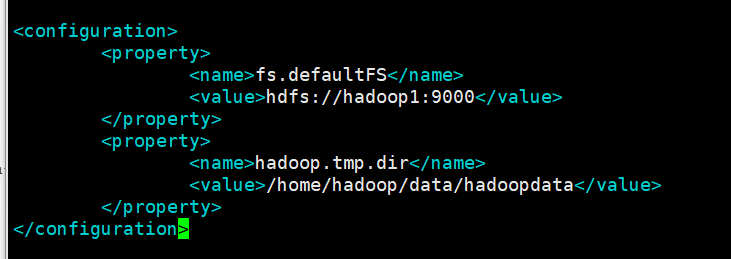
B. core-site.xml
[hadoop@hadoop1 hadoop]$ vi core-site.xml
fs.defaultFS : 这个属性用来指定namenode的hdfs协议的文件系统通信地址,可以指定一个主机+端口,也可以指定为一个namenode服务(这个服务内部可以有多台namenode实现ha的namenode服务
hadoop.tmp.dir : hadoop集群在工作的时候存储的一些临时文件的目录
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/hadoopdata</value>
</property>
</configuration>
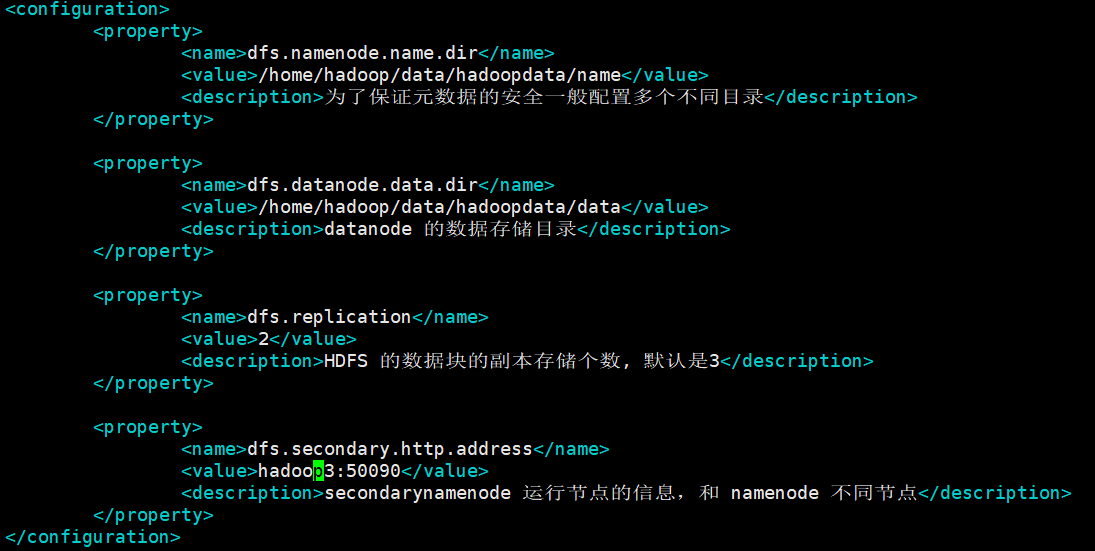
C. hdfs-site.xml
[hadoop@hadoop1 hadoop]$ vi hdfs-site.xml
dfs.namenode.name.dir:namenode数据的存放地点。也就是namenode元数据存放的地方,记录了hdfs系统中文件的元数据。
dfs.datanode.data.dir: datanode数据的存放地点。也就是block块存放的目录了。
dfs.replication:hdfs的副本数设置。也就是上传一个文件,其分割为block块后,每个block的冗余副本个数,默认配置是3。
dfs.secondary.http.address:secondarynamenode 运行节点的信息,和 namenode 不同节点
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/data/hadoopdata/name</value>
<description>为了保证元数据的安全一般配置多个不同目录</description>
</property> <property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/hadoopdata/data</value>
<description>datanode 的数据存储目录</description>
</property> <property>
<name>dfs.replication</name>
<value></value>
<description>HDFS 的数据块的副本存储个数, 默认是3</description>
</property> <property>
<name>dfs.secondary.http.address</name>
<value>hadoop3:</value>
<description>secondarynamenode 运行节点的信息,和 namenode 不同节点</description>
</property>
</configuration>
D. mapred-site.xml
[hadoop@hadoop1 hadoop]$ cp mapred-site.xml.template mapred-site.xml
[hadoop@hadoop1 hadoop]$ vi mapred-site.xml
mapreduce.framework.name:指定mr框架为yarn方式,Hadoop二代MP也基于资源管理系统Yarn来运行 。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>

E. yarn-site.xml
[hadoop@hadoop1 hadoop]$ vi yarn-site.xml
yarn.resourcemanager.hostname:yarn总管理器的IPC通讯地址
yarn.nodemanager.aux-services:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop4</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>YARN 集群为 MapReduce 程序提供的 shuffle 服务</description>
</property>
</configuration>

F. slaves
[hadoop@hadoop1 hadoop]$ vi slaves
hadoop1
hadoop2
hadoop3
hadoop4

4、把安装包分别分发给其他的节点
重点强调: 每台服务器中的hadoop安装包的目录必须一致, 安装包的配置信息还必须保持一致
重点强调: 每台服务器中的hadoop安装包的目录必须一致, 安装包的配置信息还必须保持一致
重点强调: 每台服务器中的hadoop安装包的目录必须一致, 安装包的配置信息还必须保持一致
[hadoop@hadoop1 hadoop]$ scp -r ~/apps/hadoop-2.7./ hadoop2:~/apps/
[hadoop@hadoop1 hadoop]$ scp -r ~/apps/hadoop-2.7./ hadoop3:~/apps/
[hadoop@hadoop1 hadoop]$ scp -r ~/apps/hadoop-2.7./ hadoop4:~/apps/
注意:上面的命令等同于下面的命令
[hadoop@hadoop1 hadoop]$ scp -r ~/apps/hadoop-2.7./ hadoop@hadoop2:~/apps/
5、配置Hadoop环境变量
千万注意:
1、如果你使用root用户进行安装。 vi /etc/profile 即可 系统变量
2、如果你使用普通用户进行安装。 vi ~/.bashrc 用户变量
[hadoop@hadoop1 ~]$ vi .bashrc
export HADOOP_HOME=/home/hadoop/apps/hadoop-2.7.
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
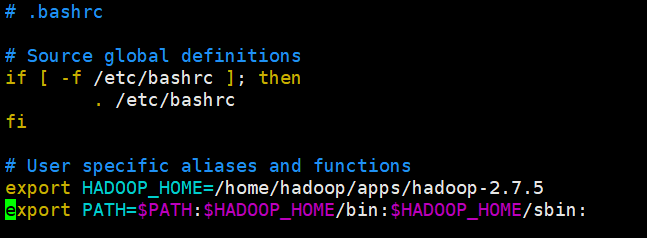
使环境变量生效
[hadoop@hadoop1 bin]$ source ~/.bashrc
6、查看hadoop版本
[hadoop@hadoop1 bin]$ hadoop version
Hadoop 2.7.
Subversion Unknown -r Unknown
Compiled by root on --24T05:30Z
Compiled with protoc 2.5.
From source with checksum 9f118f95f47043332d51891e37f736e9
This command was run using /home/hadoop/apps/hadoop-2.7./share/hadoop/common/hadoop-common-2.7..jar
[hadoop@hadoop1 bin]$
7、Hadoop初始化
注意:HDFS初始化只能在主节点上进行
[hadoop@hadoop1 ~]$ hadoop namenode -format
[hadoop@hadoop1 ~]$ hadoop namenode -format
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it. // :: INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = hadoop1/192.168.123.102
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.7.5
STARTUP_MSG: classpath = /home/hadoop/apps/hadoop-2.7.5/etc/hadoop:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/paranamer-2.3.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/httpclient-4.2.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jackson-mapper-asl-1.9.13.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jets3t-0.9.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/commons-net-3.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/apacheds-i18n-2.0.0-M15.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jetty-sslengine-6.1.26.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jetty-6.1.26.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/commons-math3-3.1.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jsr305-3.0.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jaxb-impl-2.2.3-1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jsch-0.1.54.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/commons-cli-1.2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jsp-api-2.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/hadoop-auth-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/servlet-api-2.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/mockito-all-1.8.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/zookeeper-3.4.6.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jackson-core-asl-1.9.13.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/commons-io-2.4.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/commons-logging-1.1.3.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jaxb-api-2.2.2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jersey-server-1.9.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/log4j-1.2.17.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/guava-11.0.2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jersey-json-1.9.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/xz-1.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/commons-lang-2.6.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/gson-2.2.4.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/httpcore-4.2.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/commons-compress-1.4.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/java-xmlbuilder-0.4.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/commons-httpclient-3.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jettison-1.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/slf4j-api-1.7.10.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/api-asn1-api-1.0.0-M20.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/api-util-1.0.0-M20.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/xmlenc-0.52.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/hadoop-annotations-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/commons-beanutils-core-1.8.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/commons-codec-1.4.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/protobuf-java-2.5.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/asm-3.2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/curator-framework-2.7.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/apacheds-kerberos-codec-2.0.0-M15.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/htrace-core-3.1.0-incubating.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/curator-client-2.7.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/commons-digester-1.8.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/activation-1.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jackson-xc-1.9.13.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/commons-beanutils-1.7.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jetty-util-6.1.26.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/stax-api-1.0-2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/avro-1.7.4.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jersey-core-1.9.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/junit-4.11.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/netty-3.6.2.Final.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/jackson-jaxrs-1.9.13.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/commons-collections-3.2.2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/hamcrest-core-1.3.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/curator-recipes-2.7.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/commons-configuration-1.6.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/snappy-java-1.0.4.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/hadoop-common-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/hadoop-nfs-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/hadoop-common-2.7.5-tests.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/jackson-mapper-asl-1.9.13.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/xercesImpl-2.9.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/jetty-6.1.26.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/jsr305-3.0.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/commons-cli-1.2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/servlet-api-2.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/netty-all-4.0.23.Final.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/jackson-core-asl-1.9.13.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/commons-io-2.4.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/commons-logging-1.1.3.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/jersey-server-1.9.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/log4j-1.2.17.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/guava-11.0.2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/commons-daemon-1.0.13.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/commons-lang-2.6.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/leveldbjni-all-1.8.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/xml-apis-1.3.04.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/xmlenc-0.52.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/commons-codec-1.4.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/protobuf-java-2.5.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/asm-3.2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/htrace-core-3.1.0-incubating.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/jetty-util-6.1.26.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/jersey-core-1.9.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/lib/netty-3.6.2.Final.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/hadoop-hdfs-nfs-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/hadoop-hdfs-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/hdfs/hadoop-hdfs-2.7.5-tests.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/jackson-mapper-asl-1.9.13.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/jetty-6.1.26.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/jsr305-3.0.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/jaxb-impl-2.2.3-1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/guice-servlet-3.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/commons-cli-1.2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/servlet-api-2.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/zookeeper-3.4.6.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/jackson-core-asl-1.9.13.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/commons-io-2.4.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/zookeeper-3.4.6-tests.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/commons-logging-1.1.3.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/jaxb-api-2.2.2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/jersey-server-1.9.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/log4j-1.2.17.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/aopalliance-1.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/guava-11.0.2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/jersey-json-1.9.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/javax.inject-1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/xz-1.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/commons-lang-2.6.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/leveldbjni-all-1.8.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/commons-compress-1.4.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/jersey-client-1.9.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/jersey-guice-1.9.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/jettison-1.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/commons-codec-1.4.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/protobuf-java-2.5.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/guice-3.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/asm-3.2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/activation-1.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/jackson-xc-1.9.13.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/jetty-util-6.1.26.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/stax-api-1.0-2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/jersey-core-1.9.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/netty-3.6.2.Final.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/jackson-jaxrs-1.9.13.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/lib/commons-collections-3.2.2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/hadoop-yarn-server-resourcemanager-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/hadoop-yarn-client-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/hadoop-yarn-server-nodemanager-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/hadoop-yarn-server-tests-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/hadoop-yarn-common-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/hadoop-yarn-server-web-proxy-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/hadoop-yarn-api-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/hadoop-yarn-server-sharedcachemanager-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/hadoop-yarn-server-common-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/hadoop-yarn-registry-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/hadoop-yarn-applications-unmanaged-am-launcher-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/hadoop-yarn-server-applicationhistoryservice-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/yarn/hadoop-yarn-applications-distributedshell-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/paranamer-2.3.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/jackson-mapper-asl-1.9.13.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/guice-servlet-3.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/jackson-core-asl-1.9.13.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/commons-io-2.4.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/jersey-server-1.9.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/log4j-1.2.17.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/aopalliance-1.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/javax.inject-1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/xz-1.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/leveldbjni-all-1.8.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/commons-compress-1.4.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/jersey-guice-1.9.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/hadoop-annotations-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/protobuf-java-2.5.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/guice-3.0.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/asm-3.2.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/avro-1.7.4.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/jersey-core-1.9.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/junit-4.11.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/netty-3.6.2.Final.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/hamcrest-core-1.3.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/lib/snappy-java-1.0.4.1.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-client-app-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.5-tests.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-client-shuffle-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-plugins-2.7.5.jar:/home/hadoop/apps/hadoop-2.7.5/contrib/capacity-scheduler/*.jar:/home/hadoop/apps/hadoop-2.7.5/contrib/capacity-scheduler/*.jar
STARTUP_MSG: build = Unknown -r Unknown; compiled by 'root' on 2017-12-24T05:30Z
STARTUP_MSG: java = 1.8.0_73
************************************************************/
// :: INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
// :: INFO namenode.NameNode: createNameNode [-format]
// :: WARN common.Util: Path /home/hadoop/data/hadoopdata/name should be specified as a URI in configuration files. Please update hdfs configuration.
// :: WARN common.Util: Path /home/hadoop/data/hadoopdata/name should be specified as a URI in configuration files. Please update hdfs configuration.
Formatting using clusterid: CID-5cc0d14d--4a01-b12c-d1ebfdbd8531
// :: INFO namenode.FSNamesystem: No KeyProvider found.
// :: INFO namenode.FSNamesystem: fsLock is fair: true
// :: INFO namenode.FSNamesystem: Detailed lock hold time metrics enabled: false
// :: INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit=
// :: INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true
// :: INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to :::00.000
// :: INFO blockmanagement.BlockManager: The block deletion will start around 三月 ::
// :: INFO util.GSet: Computing capacity for map BlocksMap
// :: INFO util.GSet: VM type = -bit
// :: INFO util.GSet: 2.0% max memory 966.7 MB = 19.3 MB
// :: INFO util.GSet: capacity = ^ = entries
// :: INFO blockmanagement.BlockManager: dfs.block.access.token.enable=false
// :: INFO blockmanagement.BlockManager: defaultReplication =
// :: INFO blockmanagement.BlockManager: maxReplication =
// :: INFO blockmanagement.BlockManager: minReplication =
// :: INFO blockmanagement.BlockManager: maxReplicationStreams =
// :: INFO blockmanagement.BlockManager: replicationRecheckInterval =
// :: INFO blockmanagement.BlockManager: encryptDataTransfer = false
// :: INFO blockmanagement.BlockManager: maxNumBlocksToLog =
// :: INFO namenode.FSNamesystem: fsOwner = hadoop (auth:SIMPLE)
// :: INFO namenode.FSNamesystem: supergroup = supergroup
// :: INFO namenode.FSNamesystem: isPermissionEnabled = true
// :: INFO namenode.FSNamesystem: HA Enabled: false
// :: INFO namenode.FSNamesystem: Append Enabled: true
// :: INFO util.GSet: Computing capacity for map INodeMap
// :: INFO util.GSet: VM type = -bit
// :: INFO util.GSet: 1.0% max memory 966.7 MB = 9.7 MB
// :: INFO util.GSet: capacity = ^ = entries
// :: INFO namenode.FSDirectory: ACLs enabled? false
// :: INFO namenode.FSDirectory: XAttrs enabled? true
// :: INFO namenode.FSDirectory: Maximum size of an xattr:
// :: INFO namenode.NameNode: Caching file names occuring more than times
// :: INFO util.GSet: Computing capacity for map cachedBlocks
// :: INFO util.GSet: VM type = -bit
// :: INFO util.GSet: 0.25% max memory 966.7 MB = 2.4 MB
// :: INFO util.GSet: capacity = ^ = entries
// :: INFO namenode.FSNamesystem: dfs.namenode.safemode.threshold-pct = 0.9990000128746033
// :: INFO namenode.FSNamesystem: dfs.namenode.safemode.min.datanodes =
// :: INFO namenode.FSNamesystem: dfs.namenode.safemode.extension =
// :: INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets =
// :: INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users =
// :: INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = ,,
// :: INFO namenode.FSNamesystem: Retry cache on namenode is enabled
// :: INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is millis
// :: INFO util.GSet: Computing capacity for map NameNodeRetryCache
// :: INFO util.GSet: VM type = -bit
// :: INFO util.GSet: 0.029999999329447746% max memory 966.7 MB = 297.0 KB
// :: INFO util.GSet: capacity = ^ = entries
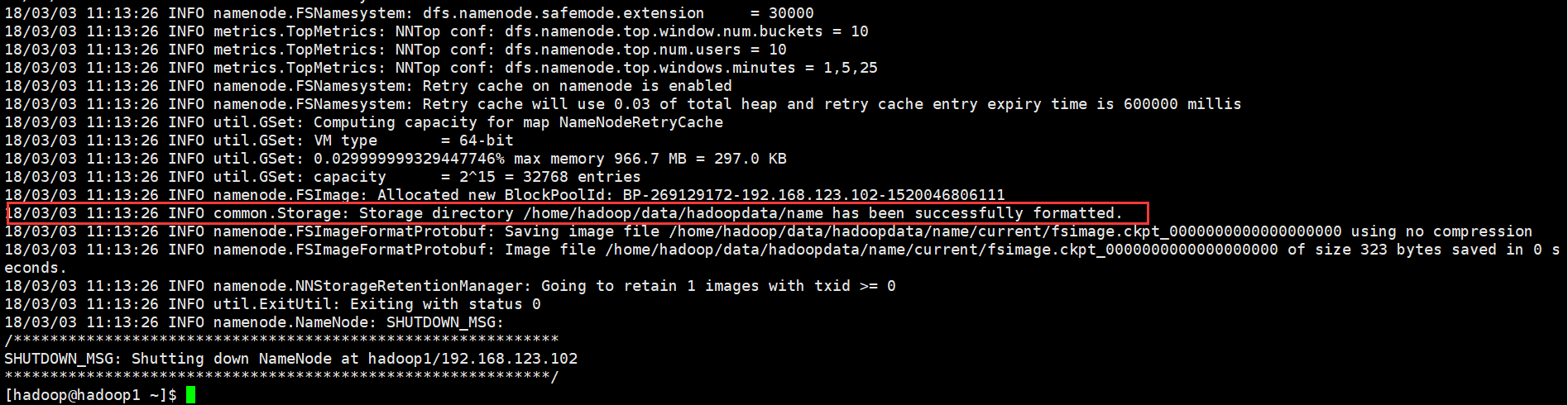
// :: INFO namenode.FSImage: Allocated new BlockPoolId: BP--192.168.123.102-
// :: INFO common.Storage: Storage directory /home/hadoop/data/hadoopdata/name has been successfully formatted.
// :: INFO namenode.FSImageFormatProtobuf: Saving image file /home/hadoop/data/hadoopdata/name/current/fsimage.ckpt_0000000000000000000 using no compression
// :: INFO namenode.FSImageFormatProtobuf: Image file /home/hadoop/data/hadoopdata/name/current/fsimage.ckpt_0000000000000000000 of size bytes saved in seconds.
// :: INFO namenode.NNStorageRetentionManager: Going to retain images with txid >=
// :: INFO util.ExitUtil: Exiting with status
// :: INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop1/192.168.123.102
************************************************************/
[hadoop@hadoop1 ~]$
8、启动
A. 启动HDFS
注意:不管在集群中的那个节点都可以
[hadoop@hadoop1 ~]$ start-dfs.sh
Starting namenodes on [hadoop1]
hadoop1: starting namenode, logging to /home/hadoop/apps/hadoop-2.7./logs/hadoop-hadoop-namenode-hadoop1.out
hadoop3: starting datanode, logging to /home/hadoop/apps/hadoop-2.7./logs/hadoop-hadoop-datanode-hadoop3.out
hadoop2: starting datanode, logging to /home/hadoop/apps/hadoop-2.7./logs/hadoop-hadoop-datanode-hadoop2.out
hadoop4: starting datanode, logging to /home/hadoop/apps/hadoop-2.7./logs/hadoop-hadoop-datanode-hadoop4.out
hadoop1: starting datanode, logging to /home/hadoop/apps/hadoop-2.7./logs/hadoop-hadoop-datanode-hadoop1.out
Starting secondary namenodes [hadoop3]
hadoop3: starting secondarynamenode, logging to /home/hadoop/apps/hadoop-2.7./logs/hadoop-hadoop-secondarynamenode-hadoop3.out
[hadoop@hadoop1 ~]$

B. 启动YARN
注意:只能在主节点中进行启动
[hadoop@hadoop4 ~]$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/apps/hadoop-2.7./logs/yarn-hadoop-resourcemanager-hadoop4.out
hadoop2: starting nodemanager, logging to /home/hadoop/apps/hadoop-2.7./logs/yarn-hadoop-nodemanager-hadoop2.out
hadoop3: starting nodemanager, logging to /home/hadoop/apps/hadoop-2.7./logs/yarn-hadoop-nodemanager-hadoop3.out
hadoop4: starting nodemanager, logging to /home/hadoop/apps/hadoop-2.7./logs/yarn-hadoop-nodemanager-hadoop4.out
hadoop1: starting nodemanager, logging to /home/hadoop/apps/hadoop-2.7./logs/yarn-hadoop-nodemanager-hadoop1.out
[hadoop@hadoop4 ~]$

9、查看4台服务器的进程
hadoop1
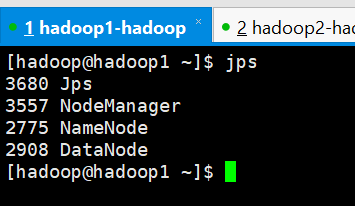
hadoop2
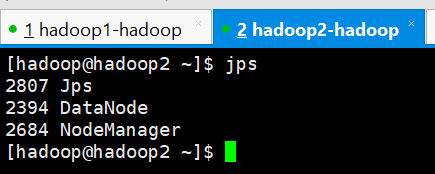
hadoop3
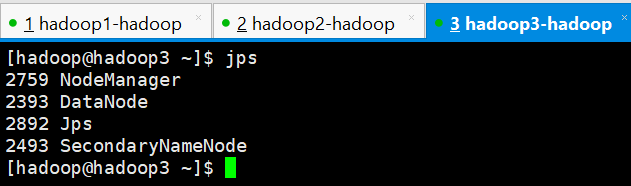
hadoop4
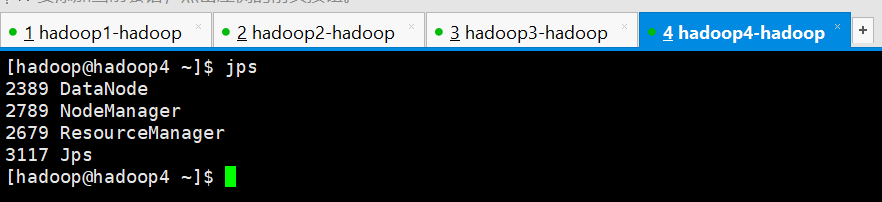
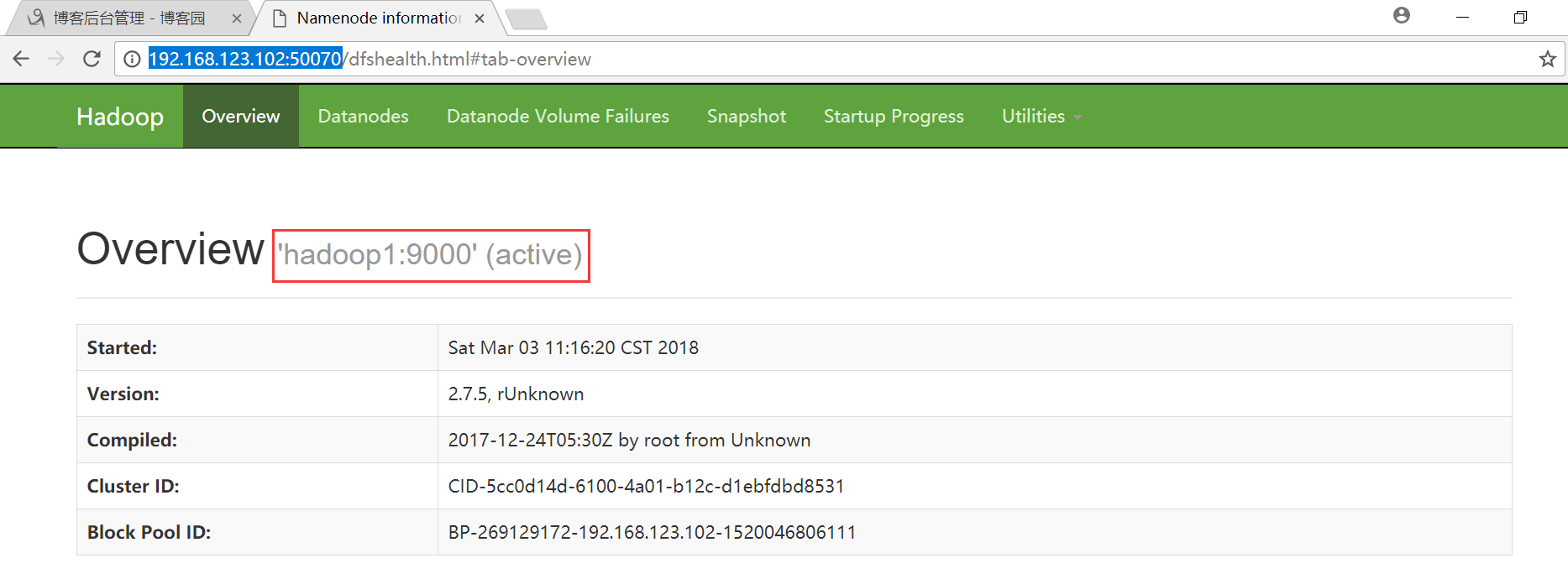
10、启动HDFS和YARN的web管理界面
HDFS : http://192.168.123.102:50070
YARN : http://hadoop05:8088
疑惑: fs.defaultFS = hdfs://hadoop02:9000
解答:客户单访问HDFS集群所使用的URL地址
同时,HDFS提供了一个web管理界面 端口:50070
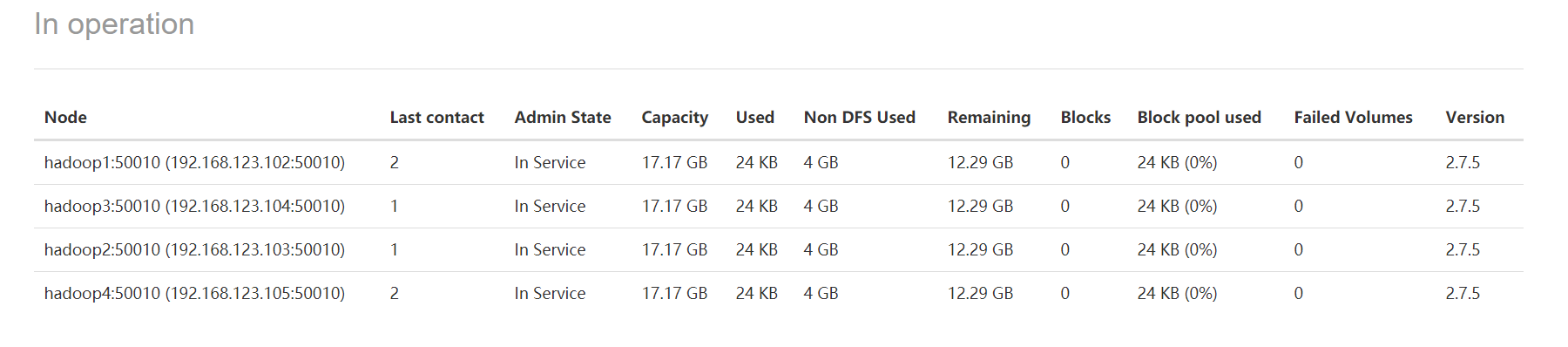
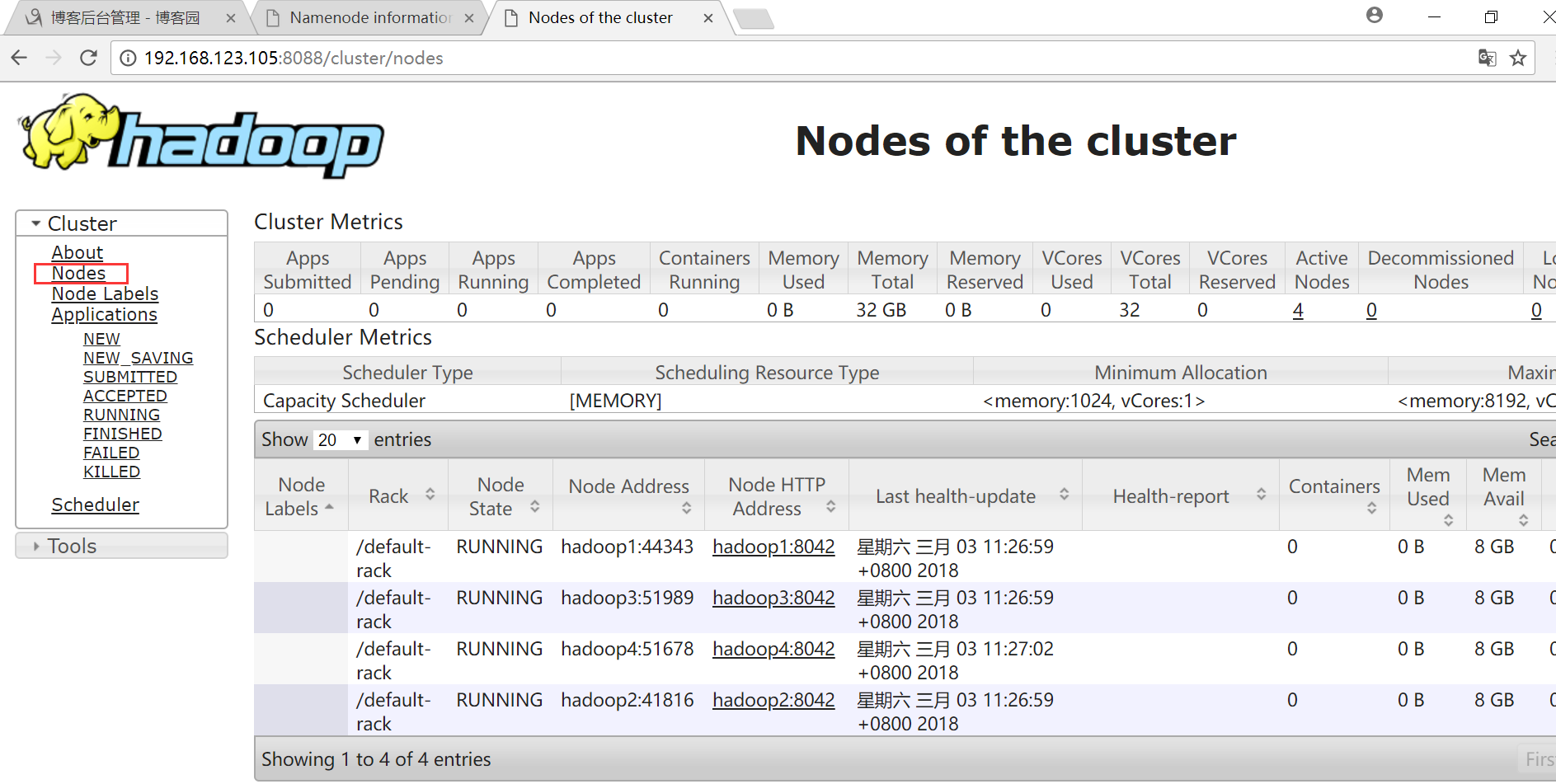
HDFS界面
点击Datanodes可以查看四个节点
YARN界面
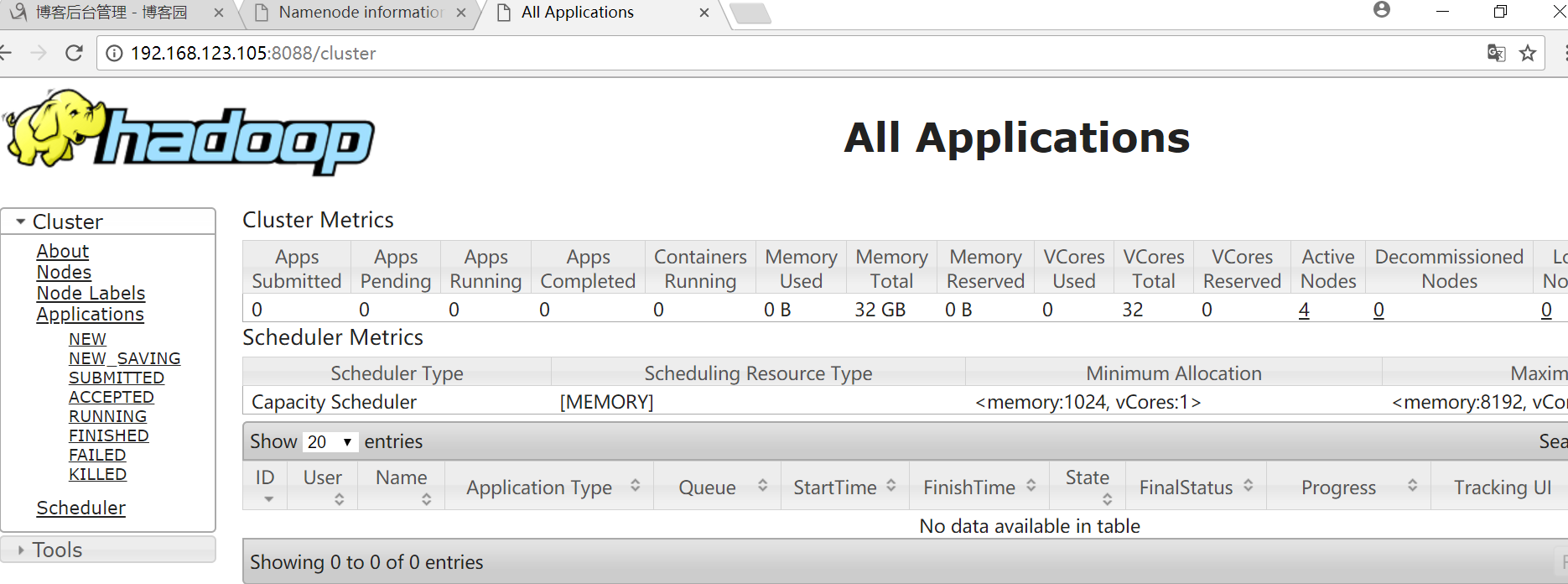
点击Nodes可以查看节点
Hadoop的简单使用
创建文件夹
在HDFS上创建一个文件夹/test/input
[hadoop@hadoop1 ~]$ hadoop fs -mkdir -p /test/input
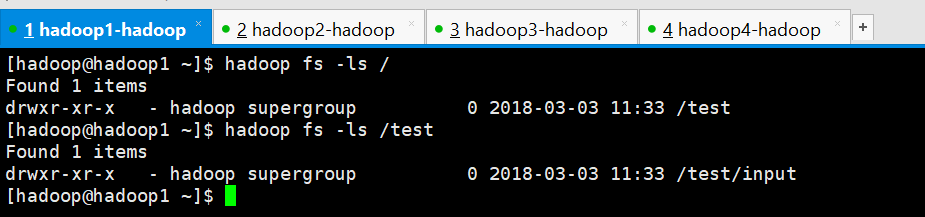
查看创建的文件夹
[hadoop@hadoop1 ~]$ hadoop fs -ls /
Found items
drwxr-xr-x - hadoop supergroup -- : /test
[hadoop@hadoop1 ~]$ hadoop fs -ls /test
Found items
drwxr-xr-x - hadoop supergroup -- : /test/input
[hadoop@hadoop1 ~]$
上传文件
创建一个文件words.txt
[hadoop@hadoop1 ~]$ vi words.txt
hello zhangsan
hello lisi
hello wangwu
上传到HDFS的/test/input文件夹中
[hadoop@hadoop1 ~]$ hadoop fs -put ~/words.txt /test/input
查看是否上传成功
[hadoop@hadoop1 ~]$ hadoop fs -ls /test/input
Found items
-rw-r--r-- hadoop supergroup -- : /test/input/words.txt
[hadoop@hadoop1 ~]$

下载文件
将刚刚上传的文件下载到~/data文件夹中
[hadoop@hadoop1 ~]$ hadoop fs -get /test/input/words.txt ~/data
查看是否下载成功
[hadoop@hadoop1 ~]$ ls data
hadoopdata words.txt
[hadoop@hadoop1 ~]$

运行一个mapreduce的例子程序: wordcount
[hadoop@hadoop1 ~]$ hadoop jar ~/apps/hadoop-2.7./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7..jar wordcount /test/input /test/output

在YARN Web界面查看
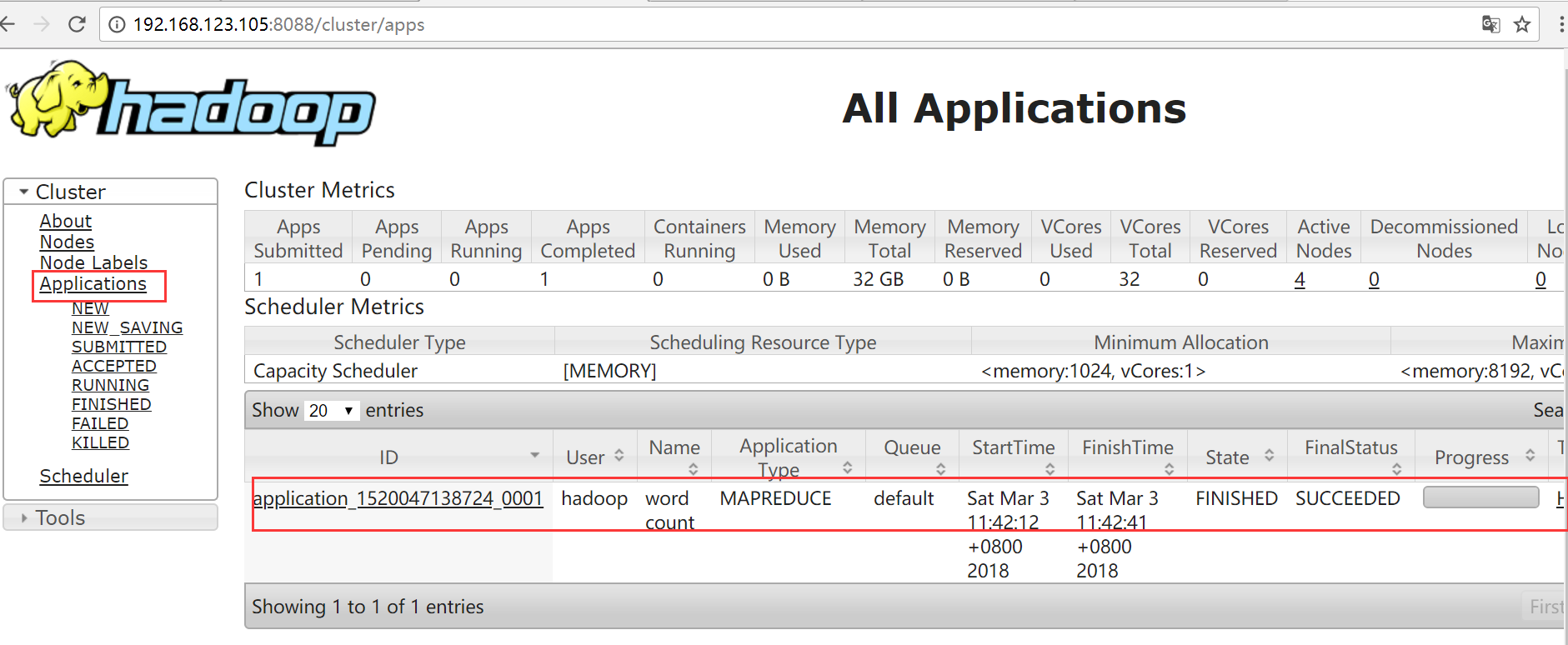
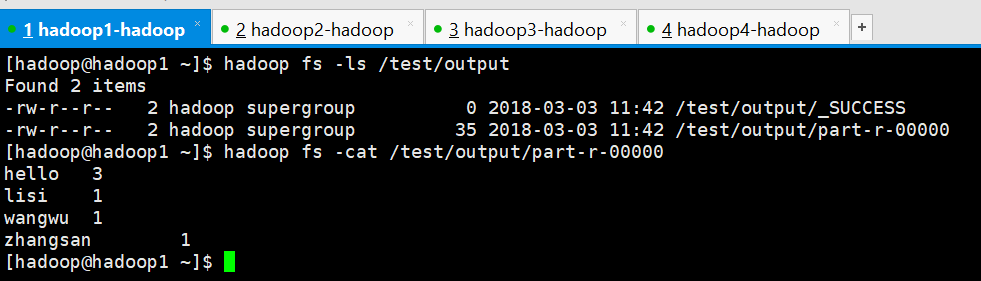
查看结果
[hadoop@hadoop1 ~]$ hadoop fs -ls /test/output
Found items
-rw-r--r-- hadoop supergroup -- : /test/output/_SUCCESS
-rw-r--r-- hadoop supergroup -- : /test/output/part-r-
[hadoop@hadoop1 ~]$ hadoop fs -cat /test/output/part-r-
hello
lisi
wangwu
zhangsan
[hadoop@hadoop1 ~]$
Hadoop学习之路(四)Hadoop集群搭建和简单应用的更多相关文章
- Hadoop学习记录(5)|集群搭建|节点动态添加删除
集群概念 计算机集群是一种计算机系统,通过一组松散继承的计算机软件或硬件连接连接起来高度紧密地协作完成计算工作. 集群系统中的单个计算机通常称为节点,通过局域网连接. 集群特点: 1.效率高,通过多态 ...
- Redis集群搭建与简单使用【转】
Redis集群搭建与简单使用 安装环境与版本 用两台虚拟机模拟6个节点,一台机器3个节点,创建出3 master.3 salve 环境. redis 采用 redis-3.2.4 版本. 两台虚拟机都 ...
- 基于Hadoop 2.2.0的高可用性集群搭建步骤(64位)
内容概要: CentSO_64bit集群搭建, hadoop2.2(64位)编译,安装,配置以及测试步骤 新版亮点: 基于yarn计算框架和高可用性DFS的第一个稳定版本. 注1:官网只提供32位re ...
- 【kafka学习之二】Kafka集群搭建
安装环境 jdk1.7 zookeeper-3.4.5(参考 https://www.cnblogs.com/cac2020/p/9426531.html) VM虚拟机redhat6.5-x64 ...
- redis集群搭建(简单简单)一台机器多redis
redis集群搭建 在开始redis集群搭建之前,我们先简单回顾一下redis单机版的搭建过程 下载redis压缩包,然后解压压缩文件: 进入到解压缩后的redis文件目录(此时可以看到Makef ...
- 【整理学习Hadoop】Hadoop学习基础之一:服务器集群技术
服务器集群就是指将很多服务器集中起来一起进行同一种服务,在客户端看来就像是只有一个服务器.集群可以利用多个计算机进行并行计算从而获得很高的计算速度,也可以用多个计算机做备份,从而使得任 ...
- 布式实时日志系统(三) 环境搭建之centos 6.4下hadoop 2.5.2完全分布式集群搭建最全资料
最近公司业务数据量越来越大,以前的基于消息队列的日志系统越来越难以满足目前的业务量,表现为消息积压,日志延迟,日志存储日期过短,所以,我们开始着手要重新设计这块,业界已经有了比较成熟的流程,即基于流式 ...
- spark学习7(spark2.0集群搭建)
第一步:安装spark 将官网下载好的spark-2.0.0-bin-hadoop2.6.tgz上传到/usr/spark目录下.这里需注意的是spark和hadoop有对应版本关系 [root@sp ...
- spark学习4(zookeeper3.4集群搭建)
第一步:zookeeper安装 通过WinSCP软件将zookeeper-3.4.8.tar.gz软件传送到/usr/zookeeper/目录下 [root@spark1 zookeeper]# ch ...
随机推荐
- input 控件监听回车确认按钮。
前端开发的同学捕捉回车按键经常会用到 if(event.keyCode == 13){ console.log("点击了回车按键");} 但是在微信上面,我们一般会用到指令 bin ...
- 【转】Apache服务器的下载与安装
PHP的运行必然少不了服务器的支持,何为服务器?通俗讲就是在一台计算机上,安装个服务器软件,这台计算机便可以称之为服务器,服务器软件和计算机本身的操作系统是两码事,计算机自身的操作系统可以为linux ...
- day-01mysql数据库下载安装卸载及基本操作
MySQL5.5.40破解版地址(永久有效):链接:https://pan.baidu.com/s/1n-sODjoCdeSGP8bDGxl23Q 密码:qjjy 第2节 数据库的介绍 MySQL:开 ...
- db2存储过程迁移
一.导出存储过程 EXPORT TO D:/PROCUDURE/procudure.del OF del MODIFIED BY LOBSINFILE SELECT 'SET CURRENT SCHE ...
- 涉及到【分页】的table的请求模式
step:1 点击分页器的内容 trigger事件句柄 (pagination, filters, sorter) => {//或者(page, pageSize)等 this.props.on ...
- CSS 画一个八卦
效果图: 实现原理: 设置高度为宽度的2倍的一个框,利用 border 补全另一半的宽度,设置圆角 用两个 div 设置不同的颜色,定位到圆的上下指定位置. 最后只剩下里面的小圆圈了.设个宽高,圆角即 ...
- springboot 文件上传 java.io.IOException: The temporary upload location [/tmp/xx] is not valid
转自:http://meia.fun/article/1541578061808 首先分析下出现问题的原因:linux 下的 /tmp 目录,是用来存储由各种程序创建的临时文件的地方.一些配置,导致系 ...
- SQL Server 索引知识-应用,维护
创建聚集索引 a索引键最好唯一(如果不唯一会隐形建立uniquier列(4字节)确保唯一,也就是这列都会复制到所有非聚集索引中) b聚集索引列所占空间应尽量小(否则也会使非聚集索引的空间变大) c聚集 ...
- Linux wget安装详解
Wget是一个十分常用命令行下载工具,多数Linux发行版本都默认包含这个工具.如果没有安装可在 http://www.gnu.org/software/wget/wget.html下载最新版本,并使 ...
- 【Kettle】2、文件夹与界面介绍
1.文件夹介绍 下载Kettle6.1解压后出现下图相关文件夹以及文件夹介绍说明: Lib:存放Kettle的核心(core)jar包.工作引擎(engine)jar包.数据库(DB) jar包.图形 ...