神经网络中Epoch、Iteration、Batchsize相关理解
batch
深度学习的优化算法,说白了就是梯度下降。每次的参数更新有两种方式。
第一种,遍历全部数据集算一次损失函数,然后算函数对各个参数的梯度,更新梯度。这种方法每更新一次参数都要把数据集里的所有样本都看一遍,计算量开销大,计算速度慢,不支持在线学习,这称为Batch gradient descent,批梯度下降。
另一种,每看一个数据就算一下损失函数,然后求梯度更新参数,这个称为随机梯度下降,stochastic gradient descent。这个方法速度比较快,但是收敛性能不太好,可能在最优点附近晃来晃去,hit不到最优点。两次参数的更新也有可能互相抵消掉,造成目标函数震荡的比较剧烈。
为了克服两种方法的缺点,现在一般采用的是一种折中手段,mini-batch gradient decent,小批的梯度下降,这种方法把数据分为若干个批,按批来更新参数,这样,一个批中的一组数据共同决定了本次梯度的方向,下降起来就不容易跑偏,减少了随机性。另一方面因为批的样本数与整个数据集相比小了很多,计算量也不是很大。
基本上现在的梯度下降都是基于mini-batch的,所以深度学习框架的函数中经常会出现batch_size,就是指这个。
关于如何将训练样本转换从batch_size的格式可以参考训练样本的batch_size数据的准备。
iterations
iterations(迭代):每一次迭代都是一次权重更新,每一次权重更新需要batch_size个数据进行Forward运算得到损失函数,再BP算法更新参数。1个iteration等于使用batchsize个样本训练一次。
epochs
epochs被定义为向前和向后传播中所有批次的单次训练迭代。这意味着1个周期是整个输入数据的单次向前和向后传递。简单说,epochs指的就是训练过程中数据将被“轮”多少次,就这样。
举个例子
batchsize:中文翻译为批大小(批尺寸)。
简单点说,批量大小将决定我们一次训练的样本数目。
batch_size将影响到模型的优化程度和速度。
为什么需要有Batch_Size:
batchsize的正确选择是为了在内存效率和内存容量之间寻找最佳平衡。
Batch_Size的取值:
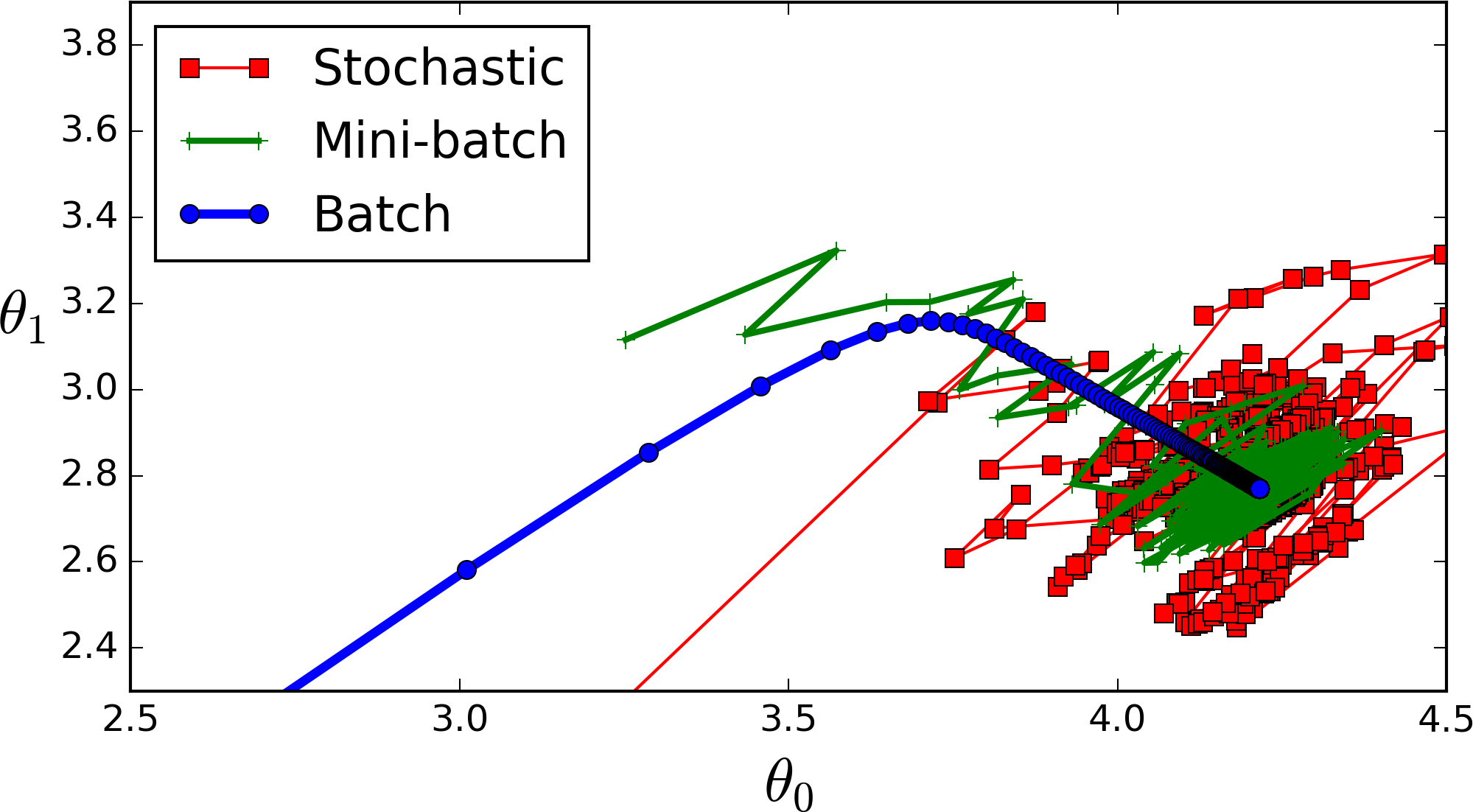
全批次(蓝色)
如果数据集比较小,我们就采用全数据集。全数据集确定的方向能够更好的代表样本总体,从而更准确的朝向极值所在的方向。
注:对于大的数据集,我们不能使用全批次,因为会得到更差的结果。
迷你批次(绿色)
选择一个适中的Batch_Size值。就是说我们选定一个batch的大小后,将会以batch的大小将数据输入深度学习的网络中,然后计算这个batch的所有样本的平均损失,即代价函数是所有样本的平均。
随机(Batch_Size等于1的情况)(红色)
每次修正方向以各自样本的梯度方向修正,横冲直撞各自为政,难以达到收敛。
适当的增加Batch_Size的优点:
1.通过并行化提高内存利用率。
2.单次epoch的迭代次数减少,提高运行速度。(单次epoch=(全部训练样本/batchsize)/iteration=1)
3.适当的增加Batch_Size,梯度下降方向准确度增加,训练震动的幅度减小。(看上图便可知晓)
经验总结:
相对于正常数据集,如果Batch_Size过小,训练数据就会非常难收敛,从而导致underfitting。
增大Batch_Size,相对处理速度加快。
增大Batch_Size,所需内存容量增加(epoch的次数需要增加以达到最好的结果)
这里我们发现上面两个矛盾的问题,因为当epoch增加以后同样也会导致耗时增加从而速度下降。因此我们需要寻找最好的Batch_Size。
再次重申:Batch_Size的正确选择是为了在内存效率和内存容量之间寻找最佳平衡。
iteration:中文翻译为迭代。
迭代是重复反馈的动作,神经网络中我们希望通过迭代进行多次的训练以达到所需的目标或结果。
每一次迭代得到的结果都会被作为下一次迭代的初始值。
一个迭代=一个正向通过+一个反向通过。
epoch:中文翻译为时期。
一个时期=所有训练样本的一个正向传递和一个反向传递。
深度学习中经常看到epoch、iteration和batchsize,下面按照自己的理解说说这三个区别:
(1)batchsize:批大小。在深度学习中,一般采用SGD训练,即每次训练在训练集中取batchsize个样本训练;
(2)iteration:1个iteration等于使用batchsize个样本训练一次;
(3)epoch:1个epoch等于使用训练集中的全部样本训练一次;
举个例子,训练集有1000个样本,batchsize=10,那么:
训练完整个样本集需要:
100次iteration,1次epoch。
神经网络中Epoch、Iteration、Batchsize相关理解的更多相关文章
- epoch iteration batchsize
深度学习中经常看到epoch. iteration和batchsize,下面按自己的理解说说这三个的区别: (1)batchsize:批大小.在深度学习中,一般采用SGD训练,即每次训练在训练集中取b ...
- ActiveMQ中Session设置的相关理解
名词解释: P:生产者 C:消费者 服务端:P 或者 ActiveMQ服务 客户端:ActiveMQ服务 或者 C 客户端成功接收一条消息的标志是这条消息被签收.成功接收一条消息一般包括如下三个阶段: ...
- 3.对神经网络训练中Epoch的理解
代表的是迭代的次数,如果过少会欠拟合,反之过多会过拟合 EPOCHS 当一个完整的数据集通过了神经网络一次并且返回了一次,这个过程称为一个 epoch. 然而,当一个 epoch 对于计算机而言太 ...
- 理解交叉熵(cross_entropy)作为损失函数在神经网络中的作用
交叉熵的作用 通过神经网络解决多分类问题时,最常用的一种方式就是在最后一层设置n个输出节点,无论在浅层神经网络还是在CNN中都是如此,比如,在AlexNet中最后的输出层有1000个节点: 而即便是R ...
- 神经网络中batch_size参数的含义及设置方法
本文作者Key,博客园主页:https://home.cnblogs.com/u/key1994/ 本内容为个人原创作品,转载请注明出处或联系:zhengzha16@163.com 在进行神经网络训练 ...
- 如何选取一个神经网络中的超参数hyper-parameters
1.什么是超参数 所谓超参数,就是机器学习模型里面的框架参数.比如聚类方法里面类的个数,或者话题模型里面话题的个数等等,都称为超参数.它们跟训练过程中学习的参数(权重)是不一样的,通常是手工设定的,经 ...
- [AI]神经网络章2 神经网络中反向传播与梯度下降的基本概念
反向传播和梯度下降这两个词,第一眼看上去似懂非懂,不明觉厉.这两个概念是整个神经网络中的重要组成部分,是和误差函数/损失函数的概念分不开的. 神经网络训练的最基本的思想就是:先“蒙”一个结果,我们叫预 ...
- 神经网络中的激活函数tanh sigmoid RELU softplus softmatx
所谓激活函数,就是在神经网络的神经元上运行的函数,负责将神经元的输入映射到输出端.常见的激活函数包括Sigmoid.TanHyperbolic(tanh).ReLu. softplus以及softma ...
- 循环神经网络中BFTT的公式推导
一.变量定义 此文是我学习BFTT算法的笔记,参考了雷明<机器学习与应用>中的BFTT算法推导,将该本书若干个推导串联起来,下列所有公式都是结合书和资料,手动在PPT上码的,很费时间,但是 ...
随机推荐
- python学习之老男孩python全栈第九期_day014知识点总结
# 迭代器和生成器# 迭代器 # 双下方法:很少直接调用的方法,一般情况下,是通过其他语法触发的# 可迭代的 --> 可迭代协议:含有__iter__的方法( '__iter__' in dir ...
- PHP通用分页类page.php[仿google分页]
<?php /** ** 通用php分页类.(仿Google样式) ** 只需提供记录总数与每页显示数两个参数.(已附详细使用说明..) ** 无需指定URL,链接由程序生成.方便用于检索结果分 ...
- Django REST Framework应用
一. 什么是RESTful REST与技术无关,代表的是一种软件架构风格,REST是Representational State Transfer的简称,中文翻译为“表征状态转移” REST从资源的角 ...
- mybatis逆向文件
一.mapper接口中的方法解析 mapper接口中的函数及方法 方法 功能说明 int countByExample(UserExample example) thorws SQLException ...
- x86项目中读取注册表Register数据项的方法
x86项目中使用Registry读取key/value的时候,会出现重定向的问题,解决方法如下: public static string GetMachineGuid() { string guid ...
- linux 命令及配置文件搜索命令which、whereis
which /usr/bin/which 搜索命令所在目录及别名信息 which lsalias ls='ls --color=auto'/usr/bin/ls which rmalias rm='r ...
- selenium&phantom实战--获取代理数据
获取快代理网站的数据 注意: #!/usr/bin/env python # _*_ coding: utf-8 _*_ # __author__ ='kong' # 导入模块 from seleni ...
- Oracle EBS 应收事务处理取值
SELECT ct.org_id ,ct.attribute1 bu_id --核算主体编号 ,ct.attribute2 dept_id --部门编号 ,hca.account_number ,hp ...
- bug管理工具
1..禅道 禅道项目管理软件(简称:禅道)集产品管理.项目管理.质量管理.文档管理.组织管理和事务管理于一体,是一款功能完备的项目管理软件,完美地覆盖了项目管理的核心流程. 禅道的主要管理思想基于国际 ...
- C# 实现水印
直接上源码 public class WaterTextBox : TextBox { //private const int EM_SETCUEBANNER = 0x1501; //[DllImpo ...