Kafka设计解析(五)Kafka性能测试方法及Benchmark报告
摘要
本文主要介绍了如何利用Kafka自带的性能测试脚本及Kafka Manager测试Kafka的性能,以及如何使用Kafka Manager监控Kafka的工作状态,最后给出了Kafka的性能测试报告。
目录
一、性能测试及集群监控工具
1. Kafka性能测试脚本
2. Kafka Metrics
2.1 使用JConsole查看单服务器Metrics
2.2 通过Kafka Manager查看整个集群的Metrics
三、Kafka Benchmark
1. Producer Only
1.1 Producer Number VS. Throughput
1.2 Message Size VS. Throughput
1.3 Partition Number VS. Throughput
1.4 Replica Number VS. Throughput
2. Consumer Only
3. Producer Consumer pair
一、性能测试及集群监控工具
Kafka提供了非常多有用的工具,如Kafka设计解析(三)Kafka High Availability (下)中提到的运维类工具——Partition Reassign Tool,Preferred Replica Leader Election Tool,Replica Verification Tool,State Change Log Merge Tool。本文将介绍Kafka提供的性能测试工具,Metrics报告工具及Yahoo开源的Kafka Manager。
1. Kafka性能测试脚本
- $KAFKA_HOME/bin/kafka-producer-perf-test.sh 该脚本被设计用于测试Kafka Producer的性能,主要输出4项指标,总共发送消息量(以MB为单位),每秒发送消息量(MB/second),发送消息总数,每秒发送消息数(records/second)。除了将测试结果输出到标准输出外,该脚本还提供CSV Reporter,即将结果以CSV文件的形式存储,便于在其它分析工具中使用该测试结果
- $KAFKA_HOME/bin/kafka-consumer-perf-test.sh 该脚本用于测试Kafka Consumer的性能,测试指标与Producer性能测试脚本一样
2. Kafka Metrics
Kafka使用Yammer Metrics来报告服务端和客户端的Metric信息。Yammer Metrics 3.1.0提供6种形式的Metrics收集——Meters,Gauges,Counters,Histograms,Timers,Health Checks。与此同时,Yammer Metrics将Metric的收集与报告(或者说发布)分离,可以根据需要自由组合。目前它支持的Reporter有Console Reporter,JMX Reporter,HTTP Reporter,CSV Reporter,SLF4J Reporter,Ganglia Reporter,Graphite Reporter。因此,Kafka也支持通过以上几种Reporter输出其Metrics信息。
2.1 使用JConsole查看单服务器Metrics
使用JConsole通过JMX,是在不安装其它工具(既然已经安装了Kafka,就肯定安装了Java,而JConsole是Java自带的工具)的情况下查看Kafka服务器Metrics的最简单最方便的方法之一。
首先必须通过为环境变量JMX_PORT设置有效值来启用Kafka的JMX Reporter。如export JMX_PORT=19797。然后即可使用JConsole通过上面设置的端口来访问某一台Kafka服务器来查看其Metrics信息,如下图所示。
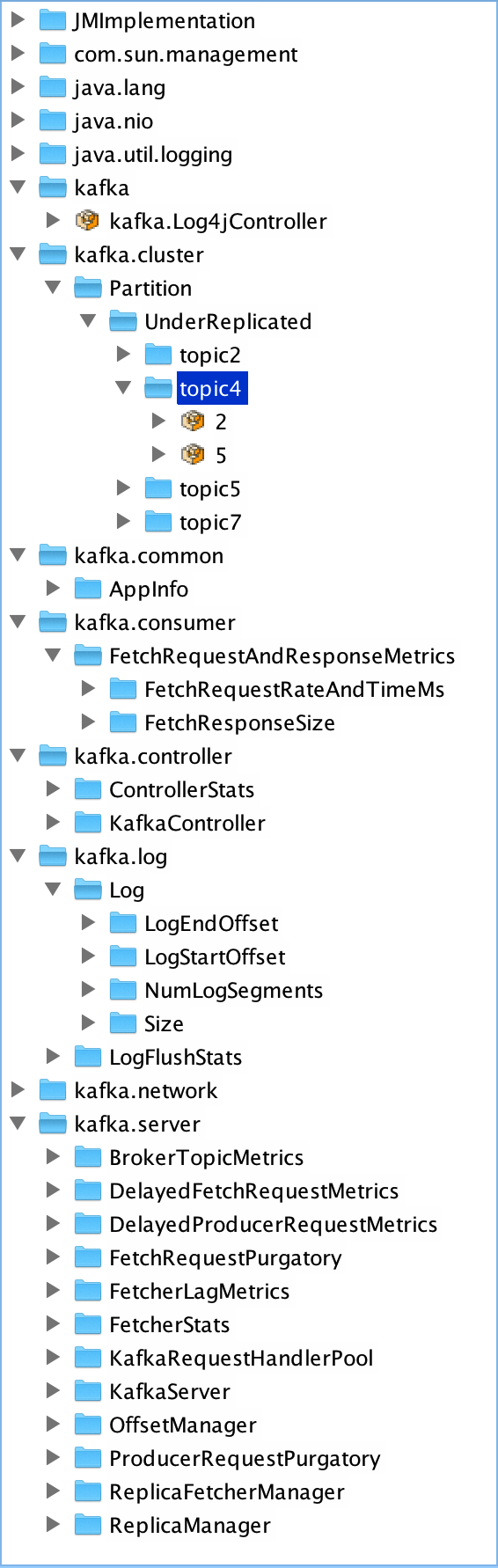
使用JConsole的一个好处是不用安装额外的工具,缺点很明显,数据展示不够直观,数据组织形式不友好,更重要的是不能同时监控整个集群的Metrics。在上图中,在kafka.cluster->Partition->UnderReplicated->topic4下,只有2和5两个节点,这并非因为topic4只有这两个Partition的数据是处于复制状态的。事实上,topic4在该Broker上只有这2个Partition,其它Partition在其它Broker上,所以通过该服务器的JMX Reporter只看到了这两个Partition。
2.2 通过Kafka Manager查看整个集群的Metrics
Kafka Manager是Yahoo开源的Kafka管理工具。它支持如下功能
- 管理多个集群
- 方便查看集群状态
- 执行preferred replica election
- 批量为多个Topic生成并执行Partition分配方案
- 创建Topic
- 删除Topic(只支持0.8.2及以上版本,同时要求在Broker中将
delete.topic.enable设置为true) - 为已有Topic添加Partition
- 更新Topic配置
- 在Broker JMX Reporter开启的前提下,轮询Broker级别和Topic级别的Metrics
- 监控Consumer Group及其消费状态
- 支持添加和查看LogKafka
安装好Kafka Manager后,添加Cluster非常方便,只需指明该Cluster所使用的Zookeeper列表并指明Kafka版本即可,如下图所示。
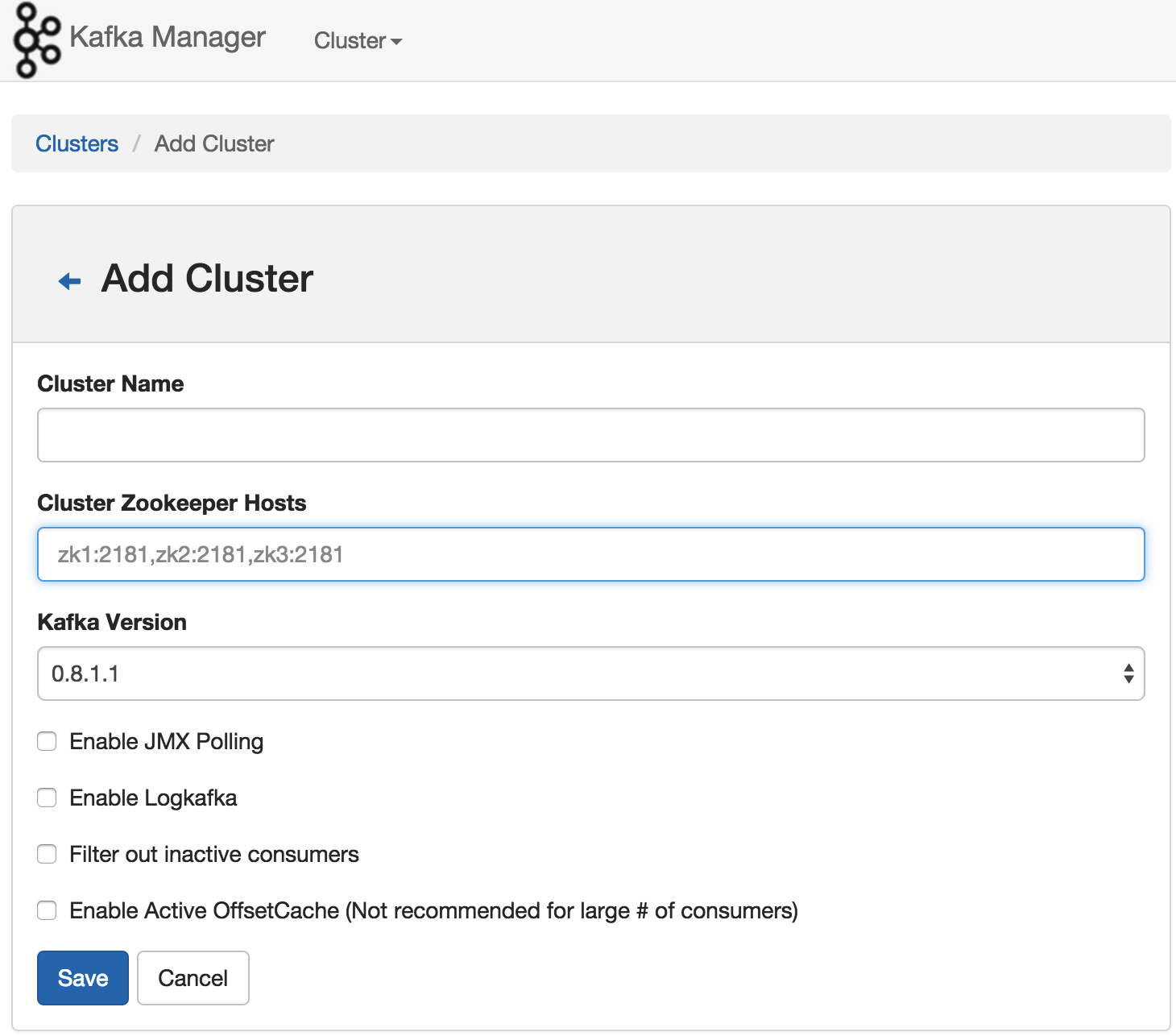
这里要注意,此处添加Cluster是指添加一个已有的Kafka集群进入监控列表,而非通过Kafka Manager部署一个新的Kafka Cluster,这一点与Cloudera Manager不同。
三、Kafka Benchmark
Kafka的一个核心特性是高吞吐率,因此本文的测试重点是Kafka的吞吐率。
本文的测试共使用6台安装Red Hat 6.6的虚拟机,3台作为Broker,另外3台作为Producer或者Consumer。每台虚拟机配置如下
- CPU:8 vCPU, Intel(R) Xeon(R) CPU E5-2680 v2 @ 2.80GHz,2 Sockets,4 Cores per socket,1 Thread per core
- 内存:16 GB
- 磁盘:500 GB
开启Kafka JMX Reporter并使用19797端口,利用Kafka-Manager的JMX polling功能监控性能测试过程中的吞吐率。
本文主要测试如下四种场景,测试的指标主要是每秒多少兆字节数据,每秒多少条消息。
1. Producer Only
这组测试不使用任何Consumer,只启动Broker和Producer。
1.1 Producer Number VS. Throughput
实验条件:3个Broker,1个Topic,6个Partition,无Replication,异步模式,消息Payload为100字节
测试项目:分别测试1,2,3个Producer时的吞吐量
测试目标:如Kafka设计解析(一)Kafka背景及架构介绍所介绍,多个Producer可同时向同一个Topic发送数据,在Broker负载饱和前,理论上Producer数量越多,集群每秒收到的消息量越大,并且呈线性增涨。本实验主要验证该特性。同时作为性能测试,本实验还将监控测试过程中单个Broker的CPU和内存使用情况
测试结果:使用不同个数Producer时的总吞吐率如下图所示
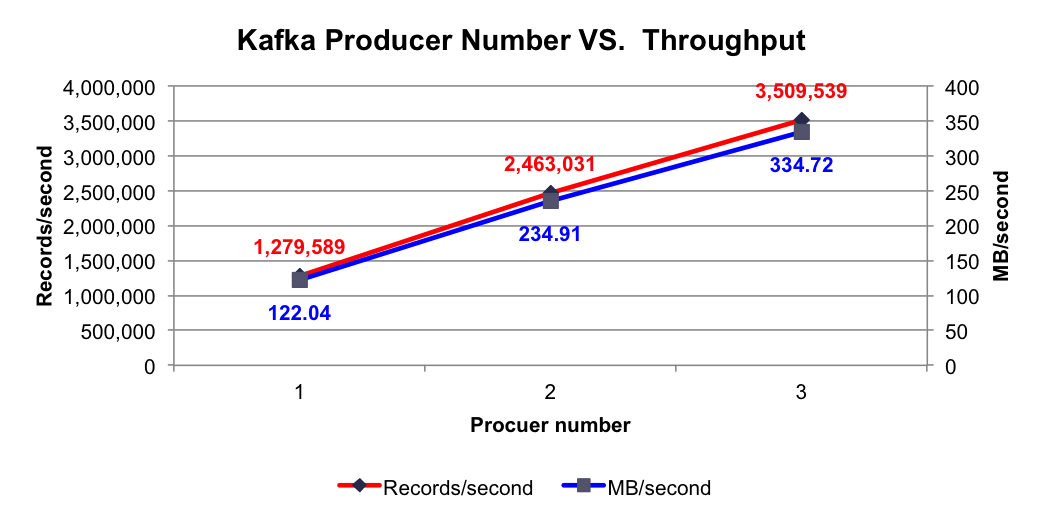
由上图可看出,单个Producer每秒可成功发送约128万条Payload为100字节的消息,并且随着Producer个数的提升,每秒总共发送的消息量线性提升,符合之前的分析。
性能测试过程中,Broker的CPU和内存使用情况如下图所示。

由上图可知,在每秒接收约117万条消息(3个Producer总共每秒发送350万条消息,平均每个Broker每秒接收约117万条)的情况下,一个Broker的CPU使用量约为248%,内存使用量为601 MB。
1.2 Message Size VS. Throughput
实验条件:3个Broker,1个Topic,6个Partition,无Replication,异步模式,3个Producer
测试项目:分别测试消息长度为10,20,40,60,80,100,150,200,400,800,1000,2000,5000,10000字节时的集群总吞吐量
测试结果:不同消息长度时的集群总吞吐率如下图所示

由上图可知,消息越长,每秒所能发送的消息数越少,而每秒所能发送的消息的量(MB)越大。另外,每条消息除了Payload外,还包含其它Metadata,所以每秒所发送的消息量比每秒发送的消息数乘以100字节大,而Payload越大,这些Metadata占比越小,同时发送时的批量发送的消息体积越大,越容易得到更高的每秒消息量(MB/s)。其它测试中使用的Payload为100字节,之所以使用这种短消息(相对短)只是为了测试相对比较差的情况下的Kafka吞吐率。
1.3 Partition Number VS. Throughput
实验条件:3个Broker,1个Topic,无Replication,异步模式,3个Producer,消息Payload为100字节
测试项目:分别测试1到9个Partition时的吞吐量
测试结果:不同Partition数量时的集群总吞吐率如下图所示
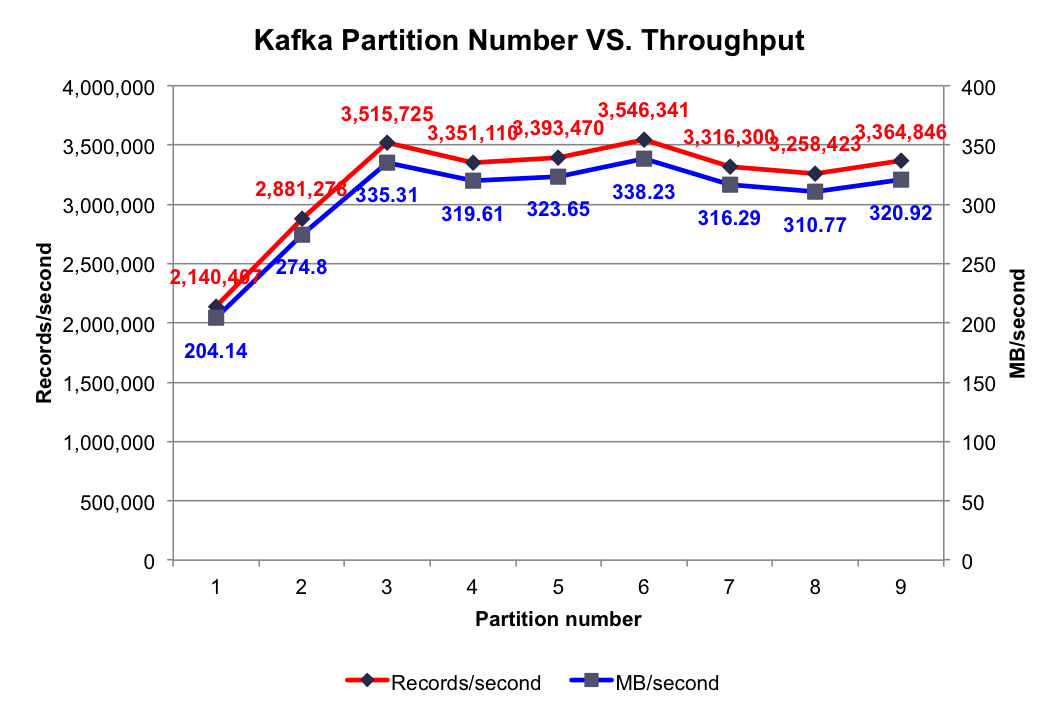
由上图可知,当Partition数量小于Broker个数(3个)时,Partition数量越大,吞吐率越高,且呈线性提升。本文所有实验中,只启动3个Broker,而一个Partition只能存在于1个Broker上(不考虑Replication。即使有Replication,也只有其Leader接受读写请求),故当某个Topic只包含1个Partition时,实际只有1个Broker在为该Topic工作。如之前文章所讲,Kafka会将所有Partition均匀分布到所有Broker上,所以当只有2个Partition时,会有2个Broker为该Topic服务。3个Partition时同理会有3个Broker为该Topic服务。换言之,Partition数量小于等于3个时,越多的Partition代表越多的Broker为该Topic服务。如前几篇文章所述,不同Broker上的数据并行插入,这就解释了当Partition数量小于等于3个时,吞吐率随Partition数量的增加线性提升。
当Partition数量多于Broker个数时,总吞吐量并未有所提升,甚至还有所下降。可能的原因是,当Partition数量为4和5时,不同Broker上的Partition数量不同,而Producer会将数据均匀发送到各Partition上,这就造成各Broker的负载不同,不能最大化集群吞吐量。而上图中当Partition数量为Broker数量整数倍时吞吐量明显比其它情况高,也证实了这一点。
1.4 Replica Number VS. Throughput
实验条件:3个Broker,1个Topic,6个Partition,异步模式,3个Producer,消息Payload为100字节
测试项目:分别测试1到3个Replica时的吞吐率
测试结果:如下图所示
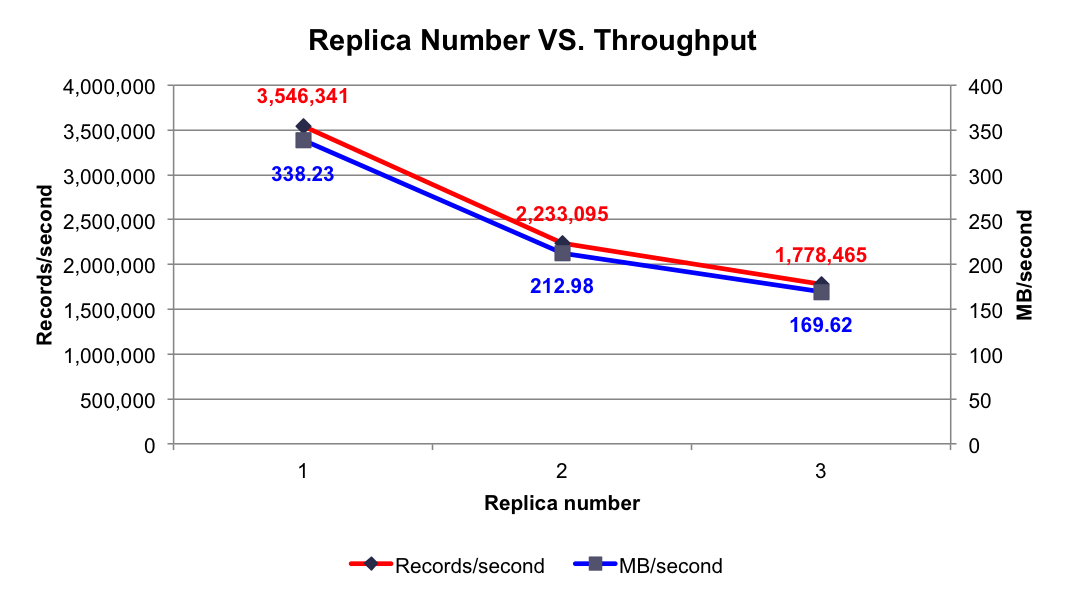
由上图可知,随着Replica数量的增加,吞吐率随之下降。但吞吐率的下降并非线性下降,因为多个Follower的数据复制是并行进行的,而非串行进行。
2. Consumer Only
实验条件:3个Broker,1个Topic,6个Partition,无Replication,异步模式,消息Payload为100字节
测试项目:分别测试1到3个Consumer时的集群总吞吐率
测试结果:在集群中已有大量消息的情况下,使用1到3个Consumer时的集群总吞吐量如下图所示
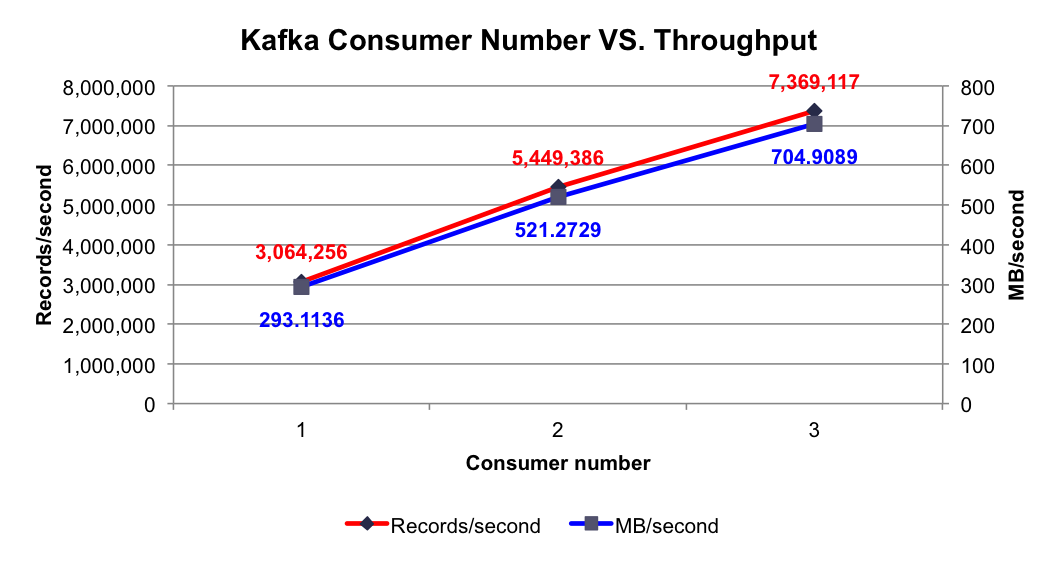
由上图可知,单个Consumer每秒可消费306万条消息,该数量远大于单个Producer每秒可消费的消息数量,这保证了在合理的配置下,消息可被及时处理。并且随着Consumer数量的增加,集群总吞吐量线性增加。
根据Kafka设计解析(四)Kafka Consumer设计解析所述,多Consumer消费消息时以Partition为分配单位,当只有1个Consumer时,该Consumer需要同时从6个Partition拉取消息,该Consumer所在机器的I/O成为整个消费过程的瓶颈,而当Consumer个数增加至2个至3个时,多个Consumer同时从集群拉取消息,充分利用了集群的吞吐率。
3. Producer Consumer pair
实验条件:3个Broker,1个Topic,6个Partition,无Replication,异步模式,消息Payload为100字节
测试项目:测试1个Producer和1个Consumer同时工作时Consumer所能消费到的消息量
测试结果:1,215,613 records/second
Kafka设计解析(五)Kafka性能测试方法及Benchmark报告的更多相关文章
- Kafka设计解析(五)- Kafka性能测试方法及Benchmark报告
本文转发自Jason’s Blog,原文链接 http://www.jasongj.com/2015/12/31/KafkaColumn5_kafka_benchmark 摘要 本文主要介绍了如何利用 ...
- Kafka学习笔记之Kafka性能测试方法及Benchmark报告
0x00 概述 本文主要介绍了如何利用Kafka自带的性能测试脚本及Kafka Manager测试Kafka的性能,以及如何使用Kafka Manager监控Kafka的工作状态,最后给出了Kafka ...
- Kafka设计解析:Kafka High Availability
Kafka在0.8以前的版本中,并不提供High Availablity机制,一旦一个或多个Broker宕机,则宕机期间其上所有Partition都无法继续提供服务.若该Broker永远不能再恢复,亦 ...
- 揭秘Kafka高性能架构之道 - Kafka设计解析(六)
原创文章,同步首发自作者个人博客.转载请务必在文章开头处以超链接形式注明出处http://www.jasongj.com/kafka/high_throughput/ 摘要 上一篇文章<Kafk ...
- 流式处理的新贵 Kafka Stream - Kafka设计解析(七)
原创文章,转载请务必将下面这段话置于文章开头处. 本文转发自技术世界,原文链接 http://www.jasongj.com/kafka/kafka_stream/ Kafka Stream背景 Ka ...
- Kafka设计解析(八)- Exactly Once语义与事务机制原理
原创文章,首发自作者个人博客,转载请务必将下面这段话置于文章开头处. 本文转发自技术世界,原文链接 http://www.jasongj.com/kafka/transaction/ 写在前面的话 本 ...
- Kafka设计解析(六)- Kafka高性能架构之道
本文从宏观架构层面和微观实现层面分析了Kafka如何实现高性能.包含Kafka如何利用Partition实现并行处理和提供水平扩展能力,如何通过ISR实现可用性和数据一致性的动态平衡,如何使用NIO和 ...
- Kafka设计解析(六)Kafka高性能架构之道
转载自 技术世界,原文链接 Kafka设计解析(六)- Kafka高性能架构之道 本文从宏观架构层面和微观实现层面分析了Kafka如何实现高性能.包含Kafka如何利用Partition实现并行处理和 ...
- [Big Data - Kafka] Kafka设计解析(五):Kafka Benchmark
性能测试及集群监控工具 Kafka提供了非常多有用的工具,如Kafka设计解析(三)- Kafka High Availability (下)中提到的运维类工具——Partition Reassign ...
随机推荐
- CentOS 7 搭建PXC 数据库集群
CentOS 7 搭建PXC 数据库集群 PXC( Percona XtraDB Cluster ) 特点如下: 1.同步复制,事务要么在所有节点提交或不提交,保证了数据的强一致性. 2.多主复制,可 ...
- Javaweb查询客户&分页部分代码
pageBean工具类代码(分页工具) package com.home.domain; import java.util.List; /** * 分页的JavaBean * @author Admi ...
- HTML meta标签总结,HTML5 head meta属性整理
原文链接:http://caibaojian.com/mobile-meta.html <!DOCTYPE html> <!-- 使用 HTML5 doctype,不区分大小写 -- ...
- Getting Started with Erlang
Getting Started with Erlang Erlang is a great language that lets you build highly concurrent applica ...
- React Native常用组件样式总结
在react 中,有时要使用 style 指定样式 ,如要跟随放大比例关系,展示图标. const stylebutton = {width:25*scalesize, height:25*scale ...
- python学习笔记之——python函数
1.定义一个函数 你可以定义一个自己想要功能的函数,以下是简单的规则: 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号(). 任何传入参数和自变量必须放在圆括号中间.圆括号之间可以用于定 ...
- samba 使用tips
安装: 推荐使用新立德包管理器安装 SAMBA配置文件: /etc/samba/smb.conf Samba服务器的启动与关闭: sudo /etc/init.d/smbd start ubuntu访 ...
- 在android工程中,res目录下又有anim、drawable、layout、menu、raw、values和xml文件夹,分别用来保存?
res目录主要是存放资源文件的!layout 布局 这个就是你经常看到的与用户交互的界面的 xml 文件,就是各个 view 的排列和嵌套,没什 么好说的啦 风格和主题. 风格主要是指 view 的显 ...
- Play-with-chrome之环境搭建
前言 浏览器漏洞在 APT 攻击中用的比较多,而且这基本上是用户上网的标配了,所以研究浏览器的漏洞是十分有前景的,我认为.我选择 chrome 浏览器 ( chromium和 chrome之间的关系请 ...
- 团队项目个人进展——Day04
一.昨天工作总结 冲刺第四天,昨天继续忙着整理数据结构与算法的知识,在项目上看了看有关视频,学习了有关视图的地方和文档说明 二.遇到的问题 无 三.今日工作规划 学习并实现地图的放大与缩小