Netty源码分析第4章(pipeline)---->第5节: 传播outbound事件
Netty源码分析第五章: pipeline
第五节: 传播outBound事件
了解了inbound事件的传播过程, 对于学习outbound事件传输的流程, 也不会太困难
在我们业务代码中, 有可能使用wirte方法往写数据:
public void channelActive(ChannelHandlerContext ctx) throws Exception {
ctx.channel().write("test data");
}
当然, 直接调用write方法是不能往对方channel中写入数据的, 因为这种方式只能写入到缓冲区, 还要调用flush方法才能将缓冲区数据刷到channel中, 或者直接调用writeAndFlush方法, 有关逻辑, 我们会在后面章节中详细讲解, 这里只是以wirte方法为例为了演示outbound事件的传播的流程
这里我们同样给出两种写法:
public void channelActive(ChannelHandlerContext ctx) throws Exception {
//写法1
ctx.channel().write("test data");
//写法2
ctx.write("test data");
}
这两种写法有什么区别, 我们首先跟到第一种写法中去:
ctx.channel().write("test data");
这里获取ctx所绑定的channel
我们跟到AbstractChannel的write方法中:
public ChannelFuture write(Object msg) {
return pipeline.write(msg);
}
这里pipeline是DefaultChannelPipeline
跟到其write方法中:
public final ChannelFuture write(Object msg) {
//从tail节点开始(从最后的节点往前写)
return tail.write(msg);
}
这里调用tail节点write方法, 这里我们应该能分析到, outbound事件, 是通过tail节点开始往上传播的, 带着这点猜想, 我们继往下看
其实tail节点并没有重写write方法, 最终会调用其父类AbstractChannelHandlerContext的write方法
AbstractChannelHandlerContext的write方法:
public ChannelFuture write(Object msg) {
return write(msg, newPromise());
}
我们看到这里有个newPromise()这个方法, 这里是创建一个Promise对象, 有关Promise的相关知识我们会在以后的章节剖析
我们继续跟write:
public ChannelFuture write(final Object msg, final ChannelPromise promise) {
//代码省略
write(msg, false, promise);
return promise;
}
继续跟write:
private void write(Object msg, boolean flush, ChannelPromise promise) {
AbstractChannelHandlerContext next = findContextOutbound();
final Object m = pipeline.touch(msg, next);
EventExecutor executor = next.executor();
if (executor.inEventLoop()) {
if (flush) {
next.invokeWriteAndFlush(m, promise);
} else {
//没有调flush
next.invokeWrite(m, promise);
}
} else {
AbstractWriteTask task;
if (flush) {
task = WriteAndFlushTask.newInstance(next, m, promise);
} else {
task = WriteTask.newInstance(next, m, promise);
}
safeExecute(executor, task, promise, m);
}
}
这里跟我们上一小节剖析过channelRead方法有点类似, 但是事件传输的方向有所不同, 这里findContextOutbound()是获取上一个标注outbound事件的HandlerContext
跟到findContextOutbound中:
private AbstractChannelHandlerContext findContextOutbound() {
AbstractChannelHandlerContext ctx = this;
do {
ctx = ctx.prev;
} while (!ctx.outbound);
return ctx;
}
这里的逻辑我们似曾相识, 跟我们上一小节的findContextInbound()方法有点像, 只是过程是反过来的
在这里, 会找到当前context的上一个节点, 如果标注的事件不是outbound事件, 则继续往上找, 意思就是找到上一个标注outbound事件的节点
回到write方法:
AbstractChannelHandlerContext next = findContextOutbound();
这里将找到节点赋值到next属性中
因为我们之前分析的write事件是从tail节点传播的, 所以上一个节点就有可能是用户自定的handler所属的context
然后判断是否为当前eventLoop线程, 如果是不是, 则封装成task异步执行, 如果不是, 则继续判断是否调用了flush方法, 因为我们这里没有调用, 所以会执行到next.invokeWrite(m, promise),
我们继续跟invokeWrite:
private void invokeWrite(Object msg, ChannelPromise promise) {
if (invokeHandler()) {
invokeWrite0(msg, promise);
} else {
write(msg, promise);
}
}
这里会判断当前handler的状态是否是添加状态, 这里返回的是true, 将会走到invokeWrite0(msg, promise)这一步
继续跟invokeWrite0:
private void invokeWrite0(Object msg, ChannelPromise promise) {
try {
//调用当前handler的wirte()方法
((ChannelOutboundHandler) handler()).write(this, msg, promise);
} catch (Throwable t) {
notifyOutboundHandlerException(t, promise);
}
}
这里的逻辑也似曾相识, 调用了当前节点包装的handler的write方法, 如果用户没有重写write方法, 则会交给其父类处理
我们跟到ChannelOutboundHandlerAdapter的write方法中看:
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
ctx.write(msg, promise);
}
这里调用了当前ctx的write方法, 这种写法和我们小节开始的写法是相同的, 我们回顾一下:
public void channelActive(ChannelHandlerContext ctx) throws Exception {
//写法1
ctx.channel().write("test data");
//写法2
ctx.write("test data");
}
我们跟到其write方法中, 这里走到的是AbstractChannelHandlerContext类的write方法:
private void write(Object msg, boolean flush, ChannelPromise promise) {
AbstractChannelHandlerContext next = findContextOutbound();
final Object m = pipeline.touch(msg, next);
EventExecutor executor = next.executor();
if (executor.inEventLoop()) {
if (flush) {
next.invokeWriteAndFlush(m, promise);
} else {
//没有调flush
next.invokeWrite(m, promise);
}
} else {
AbstractWriteTask task;
if (flush) {
task = WriteAndFlushTask.newInstance(next, m, promise);
} else {
task = WriteTask.newInstance(next, m, promise);
}
safeExecute(executor, task, promise, m);
}
}
又是我们所熟悉逻辑, 找到当前节点的上一个标注事件为outbound事件的节点, 继续执行invokeWrite方法, 根据之前的剖析, 我们知道最终会执行到上一个handler的write方法中
走到这里已经不难理解, ctx.channel().write("test data")其实是从tail节点开始传播写事件, 而ctx.write("test data")是从自身开始传播写事件
所以, 在handler中如果重写了write方法要传递write事件, 一定采用ctx.write("test data")这种方式或者交给其父类处理处理, 而不能采用ctx.channel().write("test data")这种方式, 因为会造成每次事件传输到这里都会从tail节点重新传输, 导致不可预知的错误
如果用代码中没有重写handler的write方法, 则事件会一直往上传输, 当传输完所有的outbound节点之后, 最后会走到head节点的wirte方法中
我们跟到HeadContext的write方法中:
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
unsafe.write(msg, promise);
}
我们看到write事件最终会流向这里, 通过unsafe对象进行最终的写操作
有关inbound事件和outbound事件的传输, 可通过下图进行说明:
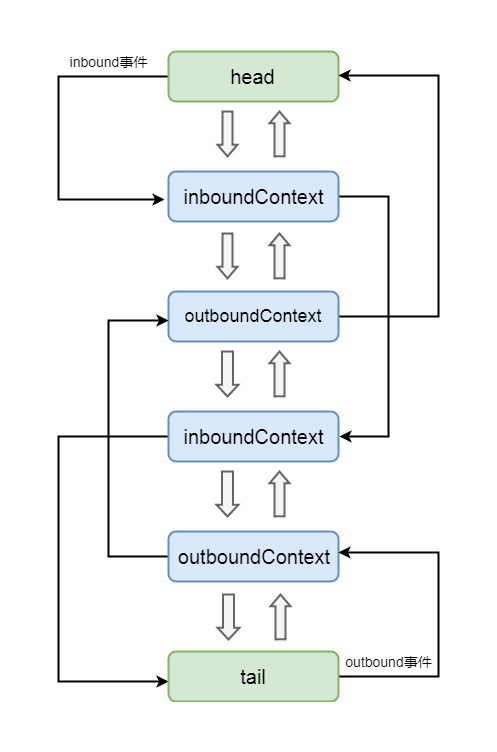
4-5-1
Netty源码分析第4章(pipeline)---->第5节: 传播outbound事件的更多相关文章
- Netty源码分析第4章(pipeline)---->第4节: 传播inbound事件
Netty源码分析第四章: pipeline 第四节: 传播inbound事件 有关于inbound事件, 在概述中做过简单的介绍, 就是以自己为基准, 流向自己的事件, 比如最常见的channelR ...
- Netty源码分析第4章(pipeline)---->第6节: 传播异常事件
Netty源码分析第四章: pipeline 第6节: 传播异常事件 讲完了inbound事件和outbound事件的传输流程, 这一小节剖析异常事件的传输流程 首先我们看一个最最简单的异常处理的场景 ...
- Netty源码分析第4章(pipeline)---->第7节: 前章节内容回顾
Netty源码分析第四章: pipeline 第七节: 前章节内容回顾 我们在第一章和第三章中, 遗留了很多有关事件传输的相关逻辑, 这里带大家一一回顾 首先看两个问题: 1.在客户端接入的时候, N ...
- Netty源码分析第4章(pipeline)---->第1节: pipeline的创建
Netty源码分析第四章: pipeline 概述: pipeline, 顾名思义, 就是管道的意思, 在netty中, 事件在pipeline中传输, 用户可以中断事件, 添加自己的事件处理逻辑, ...
- Netty源码分析第4章(pipeline)---->第2节: handler的添加
Netty源码分析第四章: pipeline 第二节: Handler的添加 添加handler, 我们以用户代码为例进行剖析: .childHandler(new ChannelInitialize ...
- Netty源码分析第4章(pipeline)---->第3节: handler的删除
Netty源码分析第四章: pipeline 第三节: handler的删除 上一小节我们学习了添加handler的逻辑操作, 这一小节我们学习删除handler的相关逻辑 如果用户在业务逻辑中进行c ...
- Netty源码分析第2章(NioEventLoop)---->第7节: 处理IO事件
Netty源码分析第二章: NioEventLoop 第七节:处理IO事件 上一小节我们了解了执行select()操作的相关逻辑, 这一小节我们继续学习select()之后, 轮询到io事件的相关 ...
- Netty源码分析第5章(ByteBuf)---->第10节: SocketChannel读取数据过程
Netty源码分析第五章: ByteBuf 第十节: SocketChannel读取数据过程 我们第三章分析过客户端接入的流程, 这一小节带大家剖析客户端发送数据, Server读取数据的流程: 首先 ...
- Netty源码分析第5章(ByteBuf)---->第4节: PooledByteBufAllocator简述
Netty源码分析第五章: ByteBuf 第四节: PooledByteBufAllocator简述 上一小节简单介绍了ByteBufAllocator以及其子类UnPooledByteBufAll ...
随机推荐
- Hadoop学习之路(十一)HDFS的读写详解
HDFS的写操作 <HDFS权威指南>图解HDFS写过程 详细文字说明(术语) 1.使用 HDFS 提供的客户端 Client,向远程的 namenode 发起 RPC 请求 2.name ...
- Core WebAPI 入门
官方文档地址 https://docs.microsoft.com/zh-cn/aspnet/?view=aspnetcore-2.2#pivot=core 使用 ASP.NET Core 构建 We ...
- App性能测试-GT
无意之间发现了GT(随身调)这个性能测试工具,该工具是由腾讯出品的开源测试工具,直接运行在手机上的“集成调测环境”. 1.下载:下载地址:开源地址:https://github.com/Tencent ...
- ajax和原生ajax、文件的上传
ajax理解: ajax发送的请求是异步处理的.也就是说如下形式: function f1(){ $.ajax( { ....... success:function(){ a= return a } ...
- 700. Search in a Binary Search Tree
# Definition for a binary tree node. # class TreeNode(object): # def __init__(self, x): # self.val = ...
- P1470 最长前缀 Longest Prefix
题目描述 在生物学中,一些生物的结构是用包含其要素的大写字母序列来表示的.生物学家对于把长的序列分解成较短的序列(即元素)很感兴趣. 如果一个集合 P 中的元素可以通过串联(元素可以重复使用,相当于 ...
- P1169 [ZJOI2007]棋盘制作
题目描述 国际象棋是世界上最古老的博弈游戏之一,和中国的围棋.象棋以及日本的将棋同享盛名.据说国际象棋起源于易经的思想,棋盘是一个8*8大小的黑白相间的方阵,对应八八六十四卦,黑白对应阴阳. 而我们的 ...
- python 位置参数和关键字参数 *args **kwargs
#!/usr/bin/env pythondef foo(*args,**kwargs): print('args: {0}'.format(args)) print('kwargs {0}'.for ...
- 内部元素一一相应的集合的算法优化,从list到hashmap
说是算法优化,基本上是在吹牛,仅仅只是算是记录下,我写代码时候的思路.毕竟还是小菜鸟. 我要开一个party,与会者都是情侣,可是情侣并非一起过来的,而是有先有后,可是每位与会者来的时候都拿着一束鲜花 ...
- 【OC底层】KVO原理
KVO的原理是什么?底层是如何实现的? KVO是Key-value observing的缩写. KVO是Objective-C是使用观察者设计模式实现的. Apple使用了isa混写(isa-swiz ...