SKLearn数据集API(二)
注:本文是人工智能研究网的学习笔记
计算机生成的数据集
用于分类任务和聚类任务,这些函数产生样本特征向量矩阵以及对应的类别标签集合。
| 数据集 | 简介 |
|---|---|
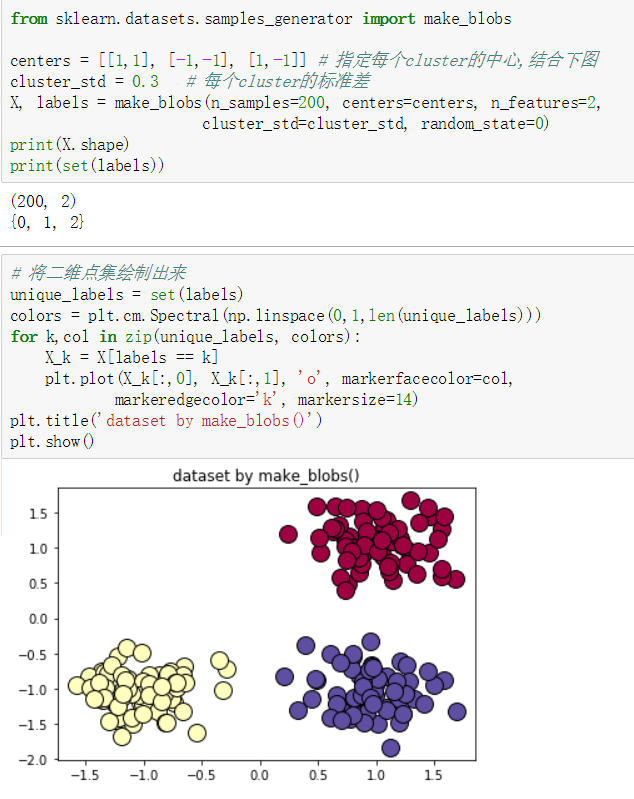
| make_blobs | 多类单标签数据集,为每个类分配一个或者多个正态分布的点集,提供了控制每个数据点的参数:中心点(均值),标准差,常用于聚类算法。 |
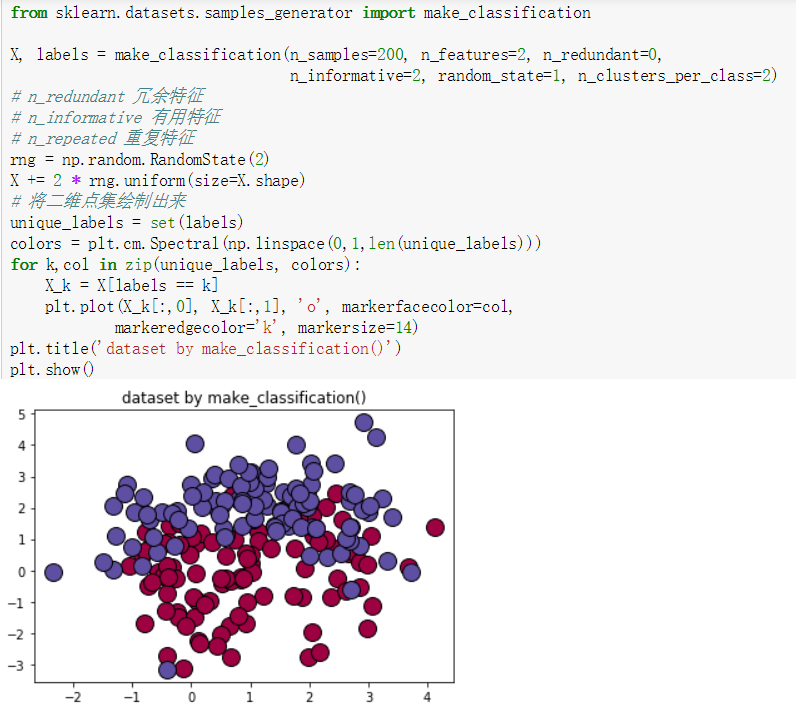
| make_classification | 多类单标签数据集,为每个类分配了一个或者多个正态分布的点集。提供了为数据集添加噪声的方式,包括维度相性,无效特征和冗余特征等。 |
| make_gaussian_quantiles | 将一个单高斯分布的点集活粉为两个数量均等的点集,作为两类。 |
| make_hastie_10_2 | 产生一个相似的二元分类器数据集,有10个维度。 |
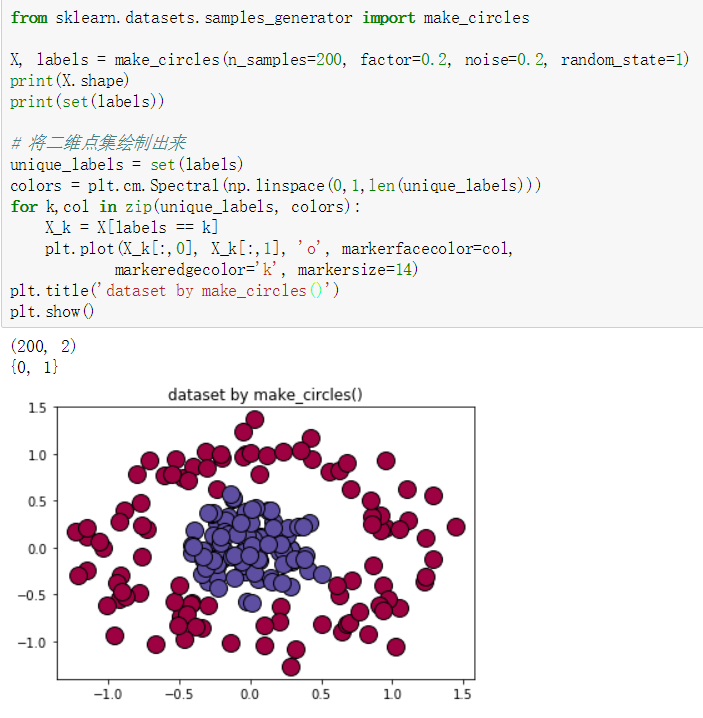
| make_circles/make_moons | 产生二维分类数据集来测试某些算法(e.g.centroid-based clustering或linear classfication)的性能。可以为数据集添加噪声,可以为二元分类器产生一些球形判决表面的数据。 |
用于多标签分类任务
| 数据集 | 简介 |
|---|---|
| make_multilabel_classification | 产生多类多标签随机样本,这些样本模拟了从很多话题的混合分布中抽取的词袋模型,每个文档的话题数量符合泊松分布,话题本身则从一个固定的随机分布中抽取出来,同样的,单词数量也是泊松分布抽取,句子则是从多项式抽取。 |
用于回归任务的
| 数据集 | 简介 |
|---|---|
| make_regression | 产生回归任务的数据集,期望目标输出是随机特征的稀疏随机线性组合,并且附带有噪声,它的有用的特征可能是不相关的,或者低秩的(引起目标值的变动的只有少量的集合特征) |
| make_sparse_uncorrelated | 产生四个特征的线性组合(固定参数)作为期望目标输出 |
| make_friedman1 | 采用了多项式和正弦变换 |
| make_friedman2 | 包含了特征的乘积和互换操作 |
| make_friedman3 | 类似于arctan变换 |
用于流行学习的
| 数据集 | 简介 |
|---|---|
| make_s_curve | 生成S型曲线数据集 |
| make_swiss_roll | 生成瑞士卷曲线数据集 |
用于因子分解的
| 数据集 | 简介 |
|---|---|
| make_low_rank_matrix | |
| make_sparse_coded_signal | |
| nake_spd_matrix | 产生的是随机的堆成的正定矩阵 |
| make_sparse_spd_matrix | 产生的是稀疏的堆成正定矩阵 |
make_blobs()
make_classification()
make_moons()

make_circles()
svmlight/libsvm格式的数据集
svmlight/libsvm的每一行样本的存放格式
<label> <feature-id>:<feature-value> <feature-id>:<feature-value>...
使用下面的方式导入该格式的数据集
X_train, y_train = sklearn.datasets.load_svmlight_file('train.txt')
还可以使用下面的方式将训练集和测试集一起导入,可以保证X_train和X_test有同样数目的特征
X_train, y_train, X_test, y_test = sklearn.datasets.load_svmlight_file(('train.txt', 'test.txt'))
SKLearn数据集API(二)的更多相关文章
- SKLearn数据集API(一)
注:本文是人工智能研究网的学习笔记 数据集一览 类型 获取方式 自带的小数据集 sklearn.datasets.load_ 在线下载的数据集 sklearn.datasets.fetch_ 计算机生 ...
- 【学习笔记】sklearn数据集与估计器
数据集划分 机器学习一般的数据集会划分为两个部分: 训练数据:用于训练,构建模型 测试数据:在模型检验时使用,用于评估模型是否有效 训练数据和测试数据常用的比例一般为:70%: 30%, 80%: 2 ...
- 机器学习笔记(四)--sklearn数据集
sklearn数据集 (一)机器学习的一般数据集会划分为两个部分 训练数据:用于训练,构建模型. 测试数据:在模型检验时使用,用于评估模型是否有效. 划分数据的API:sklearn.model_se ...
- sklearn——数据集调用及应用
忙了许久,总算是又想起这边还没写完呢. 那今天就写写sklearn库的一部分简单内容吧,包括数据集调用,聚类,轮廓系数等等. 自带数据集API 数据集函数 中文翻译 任务类型 数据规模 load_ ...
- Sklearn数据集与机器学习
sklearn数据集与机器学习组成 机器学习组成:模型.策略.优化 <统计机器学习>中指出:机器学习=模型+策略+算法.其实机器学习可以表示为:Learning= Representati ...
- sklearn数据集
数据集划分: 机器学习一般的数据集会划分为两个部分 训练数据: 用于训练,构建模型 测试数据: 在模型检验时使用,用于评估模型是否有效 sklearn数据集划分API: 代码示例文末! scikit- ...
- Civil 3D API二次开发学习指南
Civil 3D构建于AutoCAD 和 Map 3D之上,在学习Civil 3D API二次开发之前,您至少需要了解AutoCAD API的二次开发,你可以参考AutoCAD .NET API二次开 ...
- 用JSON-server模拟REST API(二) 动态数据
用JSON-server模拟REST API(二) 动态数据 上一篇演示了如何安装并运行 json server , 在这里将使用第三方库让模拟的数据更加丰满和实用. 目录: 使用动态数据 为什么选择 ...
- Express4.x API (二):Request (译)
写在前面 最近学习express想要系统的过一遍API,www.expressjs.com是express英文官网(进入www.epxressjs.com.cn发现也是只有前几句话是中文呀~~),所以 ...
随机推荐
- Django-Form表单(验证、定制、错误信息、Select)
Django form 流程 1.创建类,继承form.Form 2.页面根据类的对象自动创建html标签 3.提交,request.POST 封装到类的对象里,obj=UserInf ...
- Android笔记之开机自启
有时候需要应用具有开机自启的能力,或者更常见的场景是开机时悄悄在后台启动一个Service. 关键点: 1. Android系统在开机的时候会发送一条广播消息,只需要接收这条广播消息即可,不过需要注意 ...
- 2016.5.15——leetcode:Number of 1 Bits ,
leetcode:Number of 1 Bits 代码均测试通过! 1.Number of 1 Bits 本题收获: 1.Hamming weight:即二进制中1的个数 2.n &= (n ...
- 【codeforces】【比赛题解】#937 CF Round #467 (Div. 2)
没有参加,但是之后几天打了哦,第三场AK的CF比赛. CF大扫荡计划正在稳步进行. [A]Olympiad 题意: 给\(n\)个人颁奖,要满足: 至少有一个人拿奖. 如果得分为\(x\)的有奖,那么 ...
- imperva-指定url禁止访问
指定url禁止访问 应用到那个网站 访问一下查看告警
- 如何调整Linux内核启动中的驱动初始化顺序-驱动加载优先级
Linux内核为不同驱动的加载顺序对应不同的优先级,定义了一些宏: include\linux\init.h #define pure_initcall(fn) __define_initcall(& ...
- HttpClient使用
1.HttpClient 是 Apache Jakarta Common 下的子项目,可以用来提供高效的.最新的.功能丰富的支持 HTTP 协议的客户端编程工具包 2.主要的功能 (1)实现了所有 H ...
- centos7 安装java和tomcat9
centos7 安装java 下载好java安装包后,首先是解压,然后配置环境变量. 在usr下新建Java文件夹,把java解压到Java文件夹中 新建文件夹 # mkdir /usr/Java 键 ...
- python_接口自动化测试框架
本文总结分享介绍接口测试框架开发,环境使用python3+selenium3+unittest+ddt+requests测试框架及ddt数据驱动,采用Excel管理测试用例等集成测试数据功能,以及使用 ...
- Centos之常见目录作用介绍
我们先切换到系统根目录 / 看看根目录下有哪些目录 [root@localhost ~]# cd / [root@localhost /]# ls bin dev home lib64 mn ...