HBase混布MapReduce集群学习记录
一、准备工作
1.1 部署环境
集群规模大概260多台,TSC10机型,机型参数如下:
> 1个8核CPU(E5-2620v4)
> 64G内存
> HBA,12*4T SATA,1*240G SSD,
> 2*10G网口
1.2 机器分配
HBase和Hadoop的主结点共用,子结点也共用。
| 角色 | 机型 | 数量 |
|---|---|---|
| HBase Master&Hadoop Namenode | B6 | 2 |
| HBase RegionServer&Hadoop Datanode | TSC10 | 265 |
| ZooKeeper | B6 | 5 |
| ResourceManager(MR) | B6 | 1 |
| HistoryServer(MR) | B6 | 1 |
| NodeManager(MR) | TSC10 | 265 |
1.3 版本说明
| 角色 | 版本 |
|---|---|
| HBase | 1.2.5 |
| Hadoop | 2.7.2 |
| Zookeeper | 3.4.6 |
1.4 配置说明
1.4.1 内存参数配置说明
配置参数主要是内存方面,对于主结点来说,机型为B6,给主结点分配的内存是50G。数据结点方面,RegionServer分配了24G内存,DataNode分配2G内存。这样,对于混布的MR来说,主要是NodeManager,也还有24G内存, MR的ResourceManager单独部署在B6,内存分配24G。
1 HBase内存配置
HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -Xms10g -Xmx10g -Xmn4g"
HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -Xms24g -Xmx24g -Xmn4g"
2 Hadoop内存参数
HADOOP_NAMENODE_OPTS="-Dcom.sun.management.jmxremote -server -Xmx50g -Xms50g -Xmn4g
HADOOP_DATANODE_OPTS="-Dcom.sun.management.jmxremote -server -Xmx3g -Xmn1g
3 Yarn内存参数
YARN_RESOURCEMANAGER_OPTS="-Dcom.sun.management.jmxremote -server -Xmx24g -Xmn16g
YARN_NODEMANAGER_OPTS="-Dcom.sun.management.jmxremote -Xmx24g
1.4.2 系统参数说明
涉及swap方面,主要如下:
vm.swappiness=1
vm.dirty_background_ratio=1
vm.dirty_ratio=4
这里面采过一个坑,由于我们老集群机器内在只有32G,内存的限制,所以我们配置是打开swap内存。但tlinux不同版本这个参数的含义是不一样的,对于tlinux1.2版本,vm.swappinesss=0表示开启swap内存,但在tlinux2.2版本,这个参数如果设置为0则表示禁用swap内存,设置为1才表示开启swap内存。所以对于很多新tlinux版本的机器一开始这个参数被设置成了0,在运行一段时间发现,结点极不稳定,GC频繁,机器负载也较高,regionserver容易掉,阻塞集群读写,影响还是比较大的。后面将vm.swappiness设置成1后,集群才比较稳定。
二、MR部署过程
2.1 部署需求
混布MR的主要目的是在未接入业务的前期过程中,利用集群空闲资源通过MR方式将老集群数据同步至新集群。对于HBase而言,集群间数据拷贝如果想高效率,有两种方式可考虑,一类就是直接文件拷贝方式,通过distcp将HFile进行拷贝,拷贝完后再通过bulkload方式将数据Load到新集群HBase表中;另一类是snapshot快照方式,先在老集群创建表快照,通过ExportSnapshot将快照数据拷贝到新集群临时目录,快照数据在新集群上线也可以用bulkload方式将临时目录下的hfile文件load到线上,也可通过restore_snapshot的方式将快照表恢复到线上正式表,不过还需要作major_compact才算正式完成load。 这两种方式都需要借用MR才能完成数据拷贝,同时又没有额外的机器资源来单独部署MR,所以需要在现有集群上混布MR。
2.2 部署步骤
2.2.1 配置准备
MR的配置主要涉及2个如下:
mapred-site.xml
yarn-site.xml
在引言中提到,在部署过程中遇到最多的问题出现在配置Cgroup中出现。至于什么是Cgroup,简单讲是用于作资源隔离的,具体是基于物理资源Linux 内核提供的一种可以限制、记录、隔离进程组 (process groups) 所使用的物理资源 (如 cpu memory i/o 等等) 的机制。网上有很多关于Cgroup的介绍,是目前像docker,虚拟化等技术的基石,大家可以网上自行查找相关资料。
Yarn也是支持Cgroup隔离的,所以重点说下关于这部分的配置。
2.2.1.1 mapred-site.xml
关于这个配置的配置项说明如下:
| 配置项 | 说明 |
|---|---|
| mapreduce.framework.name | 指定MR所使用的调度框架,一般为yarn |
| fs.defaultFS | 指定hadoop的文件系统名称,与dfs.nameservices的要保持一致 |
| dfs.nameservices | HDFS NN的逻辑名称 |
| mapreduce.jobhistory.webapp.address | 历史作业web页面查询地址端口 |
| mapreduce.jobhistory.address | 历史作业启动地址 |
| mapreduce.jobhistory.uselocaldir | 历史作业本地存储目录 |
上面大部分是关于historyserver的配置项,那作业日志生成过程是怎么样的呢,主要涉及如下步骤:
- 1 yarn的资源调度器resourcemanager会启动一个MRAppMaster的进程,这个进程存在于具体执行作业的结点机器上;
- 2 MRAppMaster这个进程会将作业运行日志存储到
yarn.app.mapreduce.am.staging-dir所配置的目录下,这个目录的默认值是/tmp/hadoop-yarn/staging/[username]/.staging;- 3 作业运行完后,会将上述目录下相应作业的日志拷贝到
mapreduce.jobhistory.intermediate-done-dir配置的目录中, 并定期启动扫描线程去将此目录下日志再拷贝到/history/done-dir目录下,并把原目录相应日志删除;- 4 MRAppMaster进程将staging目录相应作业目录移除。
对于NodeManager来说,其执行过程中所产生的日志是保存在本地磁盘的,保存目录由yarn.nodemanager.local-dirs参数来控制。完整的mapred-site.xml配置如下。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hbase-hdfs-yarn</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>hbase-hdfs-yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>mr-master-host:19888</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>mr-master-host:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.uselocaldir</name>
<value>false</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/history/intermediate-done-dir</value>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/history/done-dir</value>
</property>
2.2.1.2 yarn-site.xml
这个配置项比较关键,涉及很多,这里将几个主要的配置项进行说明。
1) resourcemanager部分
指定资源调度器相关地址。
<property>
<name>yarn.resourcemanager.address</name>
<value>mr-historyserver-host:8090</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>mr-historyserver-host:8091</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>mr-historyserver-host:8093</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>mr-historyserver-host:8088</value>
</property>
<property>
<name>yarn.nodemanager.address</name>
<value>0.0.0.0:8041</value>
</property>
2) scheduler部分
指定调度器相关资源使用限制
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>128</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>51200</value>
</property>
<property>
<name>yarn.scheduler.increment-allocation-mb</name>
<value>128</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>1</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>8</value>
</property>
<property>
<name>yarn.scheduler.increment-allocation-vcores</name>
<value>1</value>
</property>
3) cgroup部分
这部分因为配置采用的是LinuxContainerExecutor方式。涉及的配置比较复杂,需要配置很多额外的东西。配置步骤如下:
- 1 创建cgroup目录,根据
yarn.nodemanager.linux-container-executor.cgroups.mount-path配置的目录先创建好,如/cgroup,这里主要是指定MR所使用的隔离组,如果不指定,默认是用/sys/fs/cgroup中的隔离参数。- 2 将系统cgroup中的cpu和memory mount到自定义的/cgroup目录,如下命令所示:
mount -t cgroup -o memory cgroup /cgroup/memory
mount -t cgroup -o cpu cgroup /cgroup/cpu
- 3 mount之后,会在/cgroup下生成两个目录,cpu,memory,如下所示:
root@node1:/cgroup#ll
total 0
drwxrwx--x 3 hdfsadmin users 0 Jun 14 16:13 cpu
drwxrwx--x 3 hdfsadmin users 0 Jun 14 16:13 memory
- 4 创建子目录,目录名由参数
yarn.nodemanager.linux-container-executor.cgroups.hierarchy指定,这里是hadoop-yarn, 并指定771权限和MR运行用户属主,如MR相关进程是运行在hdfsadmin用户下,需要把相关目录赋予hdfsadmin 属主;
mkdir -p /cgroup/cpu/hadoop-yarn
mkdir -p /cgroup/memory/hadoop-yarn
chmod -R 771 /cgroup/cpu/hadoop-yarn
chmod -R 771 /cgroup/memory/hadoop-yarn
chown -R hdfsadmin.users /cgroup/cpu
chown -R hdfsadmin.users /cgroup/memory
- 5 将users组的MR运行用户hdfsadmin的属组增加root属性, 这个主要是因为cgroup必须在root组用户下才能运行,修改如下:
usermod -G users,root hdfsadmin
- 6 创建资源调度相关目录,这个主要是由参数``yarn.nodemanager.local-dirs
确认,本集群中配置是的/data1/yarnenv/local,/data2/yarnenv/local,......,/data12/yarnenv/local; 同时还需要在这些目录下创建三个子目录,分别为filecache,usercache和nmPrivate`,并对filecache和usercache目录权限设置为755,对nmPrivate目录权限设置为700,这里的权限很关键,不然作业是执行不成功的。
mkdir -p /data1/yarnenv/local/filecache ....... /data12/yarnenv/local/filecache
mkdir -p /data1/yarnenv/local/usercache ........ /data12/yarnenv/local/usercache
mkdir -p /data1/yarnenv/local/nmPrivate ........ /data12/yarnenv/local/nmPrivate
chown -R hdfsadmin.users /data1/yarnenv/local....../data12/yarnenv/local
chmod -R 755 /data1/yarnenv/local/filecache....../data12/yarnenv/local/filecache
chmod -R 755 /data1/yarnenv/local/usercache....../data12/yarnenv/local/usercache
chmod -R 700 /data1/yarnenv/local/nmPrivate....../data12/yarnenv/local/nmPrivate
关于Cgroup os层面的部署步骤就如下所未,下面介绍关于Cgroup 集群层面的配置。
其中,yarn-env.xml中的关于cgroup的配置项如下:
<property>
<name>yarn.nodemanager.emc.enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.container-executor.class</name>
<value>org.apache.hadoop.yarn.server.nodemanager.LinuxContainerExecutor</value>
</property>
<property>
<name>yarn.nodemanager.linux-container-executor.resources-handler.class</name>
<value>org.apache.hadoop.yarn.server.nodemanager.util.CgroupsLCEResourcesHandler</value>
</property>
<property>
<name>yarn.nodemanager.linux-container-executor.cgroups.delete-timeout-ms</name>
<value>30000</value>
</property>
<property>
<name>yarn.nodemanager.linux-container-executor.cgroups.memory-control.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.linux-container-executor.cgroups.oom.policy</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.linux-container-executor.cgroups.hierarchy</name>
<value>/hadoop-yarn</value>
</property>
<property>
<name>yarn.nodemanager.linux-container-executor.cgroups.mount</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.linux-container-executor.cgroups.mount-path</name>
<value>/cgroup</value>
</property>
<property>
<name>yarn.nodemanager.linux-container-executor.nonsecure-mode.limit-users</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.linux-container-executor.nonsecure-mode.local-user</name>
<value>yarn</value>
</property>
<property>
<name>yarn.nodemanager.linux-container-executor.cgroups.strict-resource-usage</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.linux-container-executor.group</name>
<value>users</value>
</property>
如果用LinuxContainerExecutor作为容器隔离方式的话,还需要配置另一个文件:container-executor.cfg。主要 配置项如下:
yarn.nodemanager.linux-container-executor.group=users
banned.users=root
min.user.id=1000
allowed.system.users=hdfsadmin,hbaseadmin,yarn
这个配置文件在配置过程中也遇到一些问题,主要是解析格式问题,需要把原来的配置后面带#号的注释删除,不然会提示无法找到group。
关于配置部分就说到这,剩下的就是启动nodemanager进程和resourcemanager进程和historyserver进程。启动方式如下:
登录datanode结点机器,执行如下命令:
su - hdfsadmin #切换至mr运行用户
cd [hadoop-home]/sbin
./yarn-daemon.sh start nodemanager
登录MR资源管理调度机器,执行如下命令:
su - hdfsadmin
cd [hadoop-home]/sbin
./yarn-daemon.sh start resourcemanager
./mr-jobhistory-daemon.sh start historyserver
到此,MR部署层面已经介绍完了,当然 这里面还涉及比如DNS配置,策略申请等,这些也是需要提前准备的。部署过程中,问题也是不少的,下面分别介绍下。
三、问题记录
3.1 问题1:cgroup目录找不到文件错误
3.1.1 问题描述
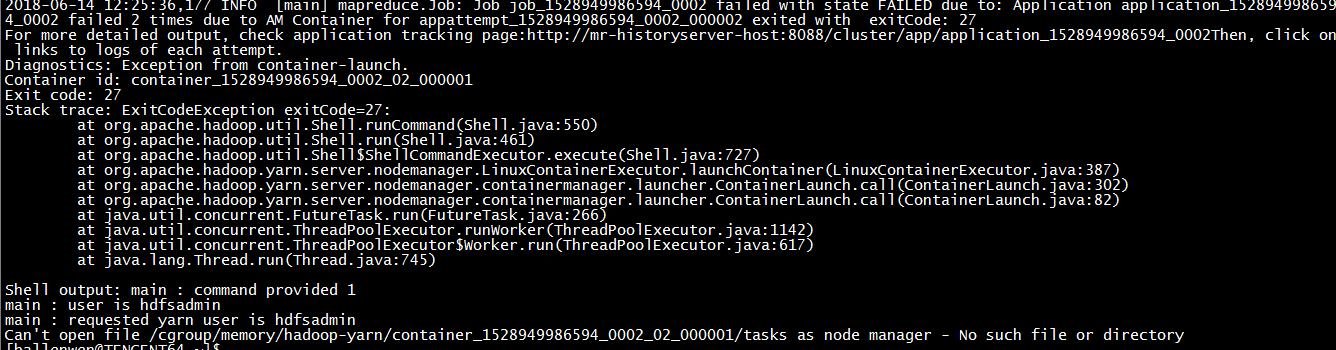
3.1.2 问题原因
cgroup 目录挂载错了,通过mount命令发现,默认挂载到了/sys/fs/cgroup/systemd,如下图所示。

因我们集群参数配置的是cgroup挂载到/cgroup目录,挂载异常导致hdfs无法识别到/cgroup目录,自然会提示目录文件不存在。上面截图只是提示/cgroup/memory这个下的目录不存在,在实际过程中一开始也遇到了/cgroup/cpu目录不存在,所以要一并处理,同时注意目录属主和权限,不然也会有问题。
3.1.3 解决方案
mount -t cgroup -o memory cgroup /cgroup/memory
mount -t cgroup -o cpu cgroup /cgroup/cpu
mkdir -p /cgroup/cpu/hadoop-yarn /cgroup/memory/hadoop-yarn;
chown hdfsadmin.users /cgroup/cpu/hadoop-yarn /cgroup/memory/hadoop-yarn;
chmod -R 771 /cgroup/cpu /cgroup/memory
3.2 filecache&usercache&nmPrivate目录找不到错误
3.2.1问题描述
在作业运行过程中,出现找不到filecache,usercache,nmPrivate子目录的错误,这个子目录是在由参数yarn.nodemanager.local-dirs配置的/data1/yarnenv/local类似这种目录,分别存储在12块盘中。
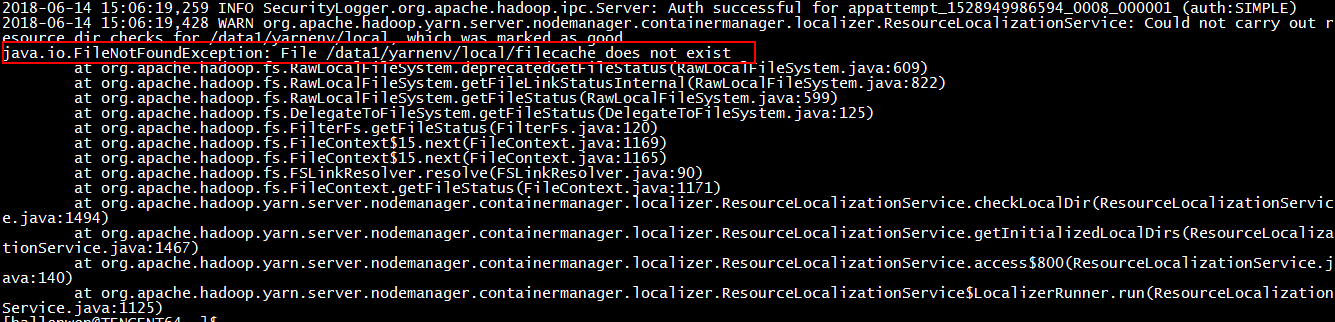
3.2.2 问题原因
上述问题主要是因在作业启动之前,集群所有结点机器没有预先创建好/data1/yarnenv/local/目录下的filecache, usercache, nmPrivate目录。
3.2.3 解决方案:
提前创建好这些子目录就行,同时权限这块也要设置ok,否则会提示permission denied问题。对于filecache,usercache,目录权限为755,而对于nmPrivate子目录,权限则要为700, 即只允许hdfsadmin用户往里写数据。
3.3 问题3-Wrong FS问题
3.3.1 问题描述
在启动作业过程中,提示fs异常,如下图所示。作业报错日志:

这个运行日志看不出啥,具体还要看container日志,这个日志路径是在yarn.nodemanager.log-dirs配置的目录下。不同application日志放在以application命名的目录下。具体如下:
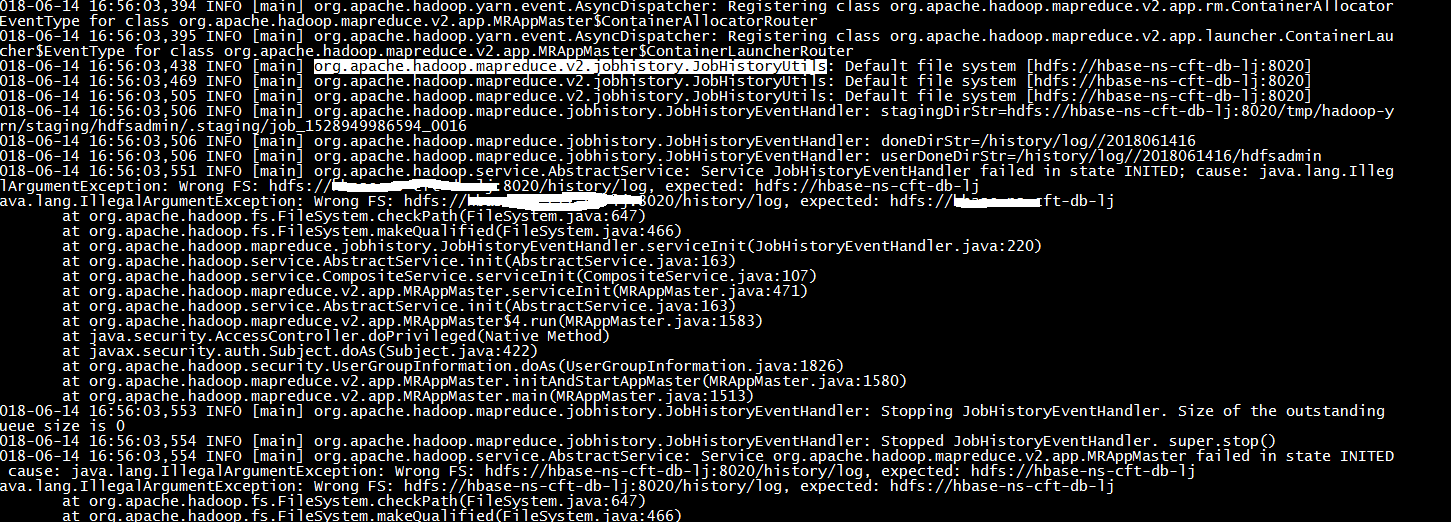
container日志会更详细,从截图中可看出,提示的是wrong Fs错误,这个错误已经把提示的wrong fs的路径出来了。
3.3.2 问题原因
最终分析是jobhistory的相关配置参数有问题,mapreduce.jobhistory.userlocaldir这个参数一开始配置是True,表示用的是本地目录,也建了相关的本地目录,但一直提示wrong fs问题。这个问题和配置的jobhistory的目录有关,如果用本地目录,然而实际还是去获取的Hdfs路径 ,根源在运行作业时,无法识别到fs.defaultFS配置的路径。
3.3.3 解决方案
修改mapred-site.xml,将mapreduce.jobhistory.uselocaldir设置为false。
<property>
<name>mapreduce.jobhistory.uselocaldir</name>
<value>false</value>
</property>
3.4 ExportSnapshot问题
3.4.1 问题描述
在执行快照导出过程中,出现如下错误。

3.4.2 问题原因
主要是Export过程中,内存配置太少,用的默认值 ,导致出现内存不足现象,导致无法支持作业完成。
3.4.3 解决方案
在ExportSnapshot过程中,增加一个参数,如下:
-Dmapred.child.java.opts=-Xmx3072M
四、总结
上面从MR集群部署方面展开介绍,并对MR任务执行过程中出现的一些问题进行分析。希望能对大家有所帮助。
HBase混布MapReduce集群学习记录的更多相关文章
- tomcat集群学习记录1--初识apache http server
起因 平时开发的时候我都是用eclipse把代码部署到本地tomcat的,当然只会去跑1台tomcat啦... 偶尔有时候解决问题需要去公司测试环境找日志.连上公司测试环境以后发现竟然有2台weblo ...
- Elasticsearch学习总结 (Centos7下Elasticsearch集群部署记录)
一. ElasticSearch简单介绍 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticse ...
- 使用Cloudera Manager搭建MapReduce集群及MapReduce HA
使用Cloudera Manager搭建MapReduce集群及MapReduce HA 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.通过CM部署MapReduce On ...
- k8s集群问题记录
k8s集群问题记录 k8s学习方案 问题解决思路 主要学习路径: rancher(k8s)->rke->helm->kubectl->k8s(k8s中文api) 常见问题总结: ...
- ElasticSearch 5学习(7)——分布式集群学习分享2
前面主要学习了ElasticSearch分布式集群的存储过程中集群.节点和分片的知识(ElasticSearch 5学习(6)--分布式集群学习分享1),下面主要分享应对故障的一些实践. 应对故障 前 ...
- ElasticSearch 5学习(6)——分布式集群学习分享1
在使用中我们把文档存入ElasticSearch,但是如果能够了解ElasticSearch内部是如何存储的,将会对我们学习ElasticSearch有很清晰的认识.本文中的所使用的ElasticSe ...
- RocketMQ集群部署记录
RocketMQ集群部署记录 #引用 https://cloud.tencent.com/developer/article/1147765 一.RocketMQ基础知识介绍 A ...
- Centos6下zookeeper集群部署记录
ZooKeeper是一个开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等. Zookeeper设计目的 最终一致性:client不论 ...
- Redis集群学习笔记
Redis集群学习笔记 前言 最近有个需求,就是将一个Redis集群中数据转移到某个单机Redis上. 迁移Redis数据的话,如果是单机Redis,有两种方式: a. 执行redis-cli shu ...
随机推荐
- centos systemctl daemon-reload 提示 no such file or directory 的一个原因
service 的文件名写错了 比如 mongodb.service 写成了 mongodb.srvice 真的是坑,居然没有提示具体的路径,只是提示一个 no such file or direct ...
- D65光源
D65光源是标准光源中最常用的人工日光,其色温为6500K.英文名:Artificial Daylight 6500K.标准光源箱中的D65光源是模拟人工日光,保证在室内.阴雨天观测物品的颜色效果时, ...
- linux命令总结sed命令详解
Sed 简介 sed 是一种新型的,非交互式的编辑器.它能执行与编辑器 vi 和 ex 相同的编辑任务.sed 编辑器没有提供交互式使用方式,使用者只能在命令行输入编辑命令.指定文件名,然后在屏幕上查 ...
- Struts2 01---环境搭配
开发工具:Eclipse Struts版本:2.3.24 最近在学SSH框架,SSH是 struts+spring+hibernate的一个集成框架,是目前比较流行的一种Web应用程序开源框架. ...
- C语言第九节进制
进制 什么是进制 是一种计数的方式,数值的表示形式 数一下方块的个数 汉字:十一 十进制:11 二进制:1011 八进制:13 多种进制:十进制.二进制.八进制.十六进制.也就是说,同一个整数,我们至 ...
- sql 2012之后分页查询速度问题
一.SQL Server 2012使用OFFSET/FETCH NEXT分页,比SQL Server 2005/2008中的RowNumber()有显著改进.今天特地作了简单测试,现将过程分享如下: ...
- 最长递增子序列(LIS)(转)
最长递增子序列(LIS) 本博文转自作者:Yx.Ac 文章来源:勇幸|Thinking (http://www.ahathinking.com) --- 最长递增子序列又叫做最长上升子序列 ...
- C++中getline()和cin()同时使用时的注意事项
今天做tju的oj,遇到一个问题,想前部分用cin函数一个一个的读入数据,中间部分利用getline()一起读入一行,但是测试发现,cin之后的getline函数并无作用,遂谷歌之.原来cin只是在缓 ...
- 【leetcode 简单】 第六十题 反转链表
反转一个单链表. 示例: 输入: 1->2->3->4->5->NULL 输出: 5->4->3->2->1->NULL 进阶: 你可以迭代 ...
- Django框架下的小人物--Cookie
1. 什么是Cookie,它的用途是什么? Cookies是一些存储在用户电脑上的小文件.它是被设计用来保存一些站点的用户数据,这样能够让服务器为这样的用户定制内容,后者页面代码能够获取到Cookie ...