python中的数据结构-链表
一.什么是链表
链表是由一系列节点构成,每个节点由一个值域和指针域构成,值域中存储着用户数据,指针域中存储这指向下一个节点的指针.根据结构的不同,链表可以分为单向链表、单向循环链表、双向链表、双向循环链表等。单向链表的结构如下图所示:
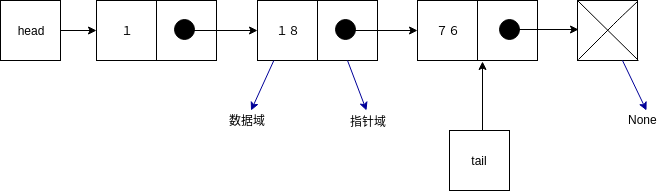
head 节点永远指向第一个节点, tail节点永远指向最后一个节点,节点中最后一个指针指向的是None 值,链表本质上就是由指针链接起来的一系列值.
二.为什么使用链表
我们经常拿链表和数组作比较,实际上数组是一组固定长度的序列,链表可以动态地分配元素,下面我们了解一下使用链表的优缺点
优点:
链表节省内存.它只针对待存储数据分配所需内存,在创建数组时,必须预先设置数组的大小,然后再添加数据,这可能会浪费内存。
缺点
查找或访问特定节点的时间是O(n). 在链接列表中查找值时,必须从头开始,并一次检查一每个元素以找到要查找的值。 如果链接列表的长度为n,则最多花费O(n)。
而很多语言中在数组中查找特定的元素则需花费O(1)时间
三.python 实现链表
1)节点
python 用类来实现链表的数据结构,节点(Node)是链表中存储数据的地方,除了数据之外节点中还有指向下一个节点的指针。节点是实现链表的基本模块,下边用python代码来实现一个节点类
class Node:
def _init_(self,val):
self.val=val
self.next_node = None #the pointer initially points to pointer def get_val(self):
return self.val #returns the stored data def get_next(self):
return self.next_node #returns the next node (the node to which the object node points) def set_val(self, new_val):
self.val = new_val # reset the vaue to a new value
def set_next(self, new_next):
self.next_node = new_next # reset the pointer to a new node
此节点类只有一个构建函数,接收一个数据参数,其中next表示指针域的指针,接下来我们用如下方式去初始化一个链表:
node1 = Node(4)
node2 = Node(21)
node3 = Node(90)
node1.next = node2 #4->21
node2.next = node3 #21->90
# the entire linked list now looks like: 4->21->90
借助上边的节点类我们可以很方便的构造出链表
2)链表
单向链表的实现包含了如下几个方法:
append(): 向链表中增加一个元素
insert(): 向链表中插入一个新节点
size(): 返回链表的长度
search(): 在链表中查找数据项是否存在
delete(): 删除链表中的数据项
empty(): 判断链表是否为空
iterate(): 遍历链表
链表的头结点:
首先构建链表的头结点也就是链表中的第一个节点,当链表在初始化时不包含任何节点,所以它的头节点设置为空
class LinkedList:
def _init_(self):
self.head = None
self.tail = None
实例化代码如下
linklist = LinkedList()
append()
append方法表示增加元素到链表,这和insert方法不同,前者使新增加的元素成为链表中第一个节点,而后者是根据索引值来判断插入到链表的哪个位置。代码如下:
def append(self, val):
new_node = Node(val)
if self.head is None:
self.head = new_node
self.tail = new_node
else:
self.tail.set_next(new_node)
self.tail = new_node
insert()
该方法获得一个数据,对于给定数据初始化一个节点,并将该节点添加到链表中去。最简单的实现方法是把它插入到链表头处,并让新节点指向原来的头结点,该方法二时间复杂度为O(1):
def insert(self, val):
new_node = Node(val)
new_node.set_next(self.head)
self.head = new_node
如果要在特定位置插入节点要提前找到这个位置,在链表中只能采用遍历的方法,时间复杂度为O(n). 同时我们还要考虑额外的三种情况:
1)空链表时
2)插入位置超出链表节点的长度时
3)插入位置是链表的最后一个节点时,需要移动tail
def insert(self, index, val):
current_node = self.head
current_node_index = 9
if current_node is None:
raise Exception('This is an empty linked list')
while current_node_index < index-1:
current_node = current_node.next
if current_node is None:
raise Exception('exceed the length of the list')
current_node_index += 1
node = Node(val)
node.next = current_node.next
current_node.next = node
if node.next is None:
self.tail = node
size()
返回链表长度的方法非常简单,统计链表中的节点数目直到找不到更多的节点为止返回遍历的节点的数目。该方法从表头开始,直到最后一个节点的next指针指向None时链表遍历完成。同时用计数器记录下已经遍历的节点的数目
def size(self):
current_node = self.head
count = 0
if current_node is None:
return 'This is an empty linked list'
while current_node:
count += 1
current_node = current_node.get_next()
return count
search()
search()与size() 方法很相似,但是除了要遍历整个链表,search()还要检查他遍历的每一个节点是否包含要查找的数据,并返回含有该数据的节点。如果该方法遍历整个链表没有找到包含该数据的节点,它将会抛出一个异常并通知用户该数据不在链表中
def search(self, val):
current_node = self.head
found = false
while current_node and found is false:
if current_node.get_val == val:
found = True
else:
current_node = current_node.get_next()
if current_node is None:
raise ValueError('Data not in list')
delete()
delete()与search()方法非常相似,它采用与serch()相同的方法遍历整个链表,但除了要记录下当前节点之外, delete()还要记住当前节点的上一个节点,当deleta()方法遍历到要删除的节点时,它会将待删除节点的上一个节点的指针指向待删除节点的下一个节点,此时链表中将没有节点指向待删除节点。该方法的时间复杂度为O(n),因为在最坏情况下该方法要访问链表中的所有节点。同时我们还需要考虑如下几种情况:
1) 空链表,直接抛出异常
2) 删除第一个节点时,移动head到删除节点的next指针指向的对象
3) 链表只有一个节点时,把head与tail都指向None即可
4) 删除最后一个节点时,需要移动tail到上一个节点
5) 遍历链表时要判断给定的索引是否大于链表的长度,如果大于则抛出异常信息
def delete(self, val):
curent_node = self.head
previous = None
found = False
while current_node and found is False:
if current_node.get_val() == val:
found = True
else:
previous = current_node
current_node = current_node.get_next()
if current_node is None:
raise ValueError('Data not in list')
if self.head is self.tail: # when there is only one node in the list
self.head = None
self.tail = None
if current_node is None: #when delete the tail node
self.tail = current_node
if previous is None: #when delete the first node
self.head = current_node.get_next()
else :
previous.set_next(current.get_next())
empty()
判断链表是否为空就看他的头指针是否为空
def empty(self):
return return self.head is None
iterate()
遍历链表从头结点开始,直到节点的指针指向None为止
def iterate(self):
if not self.head: # if the linked list is empty
return
current_node = self.head
yield current_node.val
while current_node.next
current_node = current_node.next
yield current_node.val
完整代码如下
1 class Node:
2 def __init__(self,val):
3 self.val=val
4 self.next = None #the pointer initially points to pointer
5 def get_val(self):
6 return self.val
7 def get_next(self):
8 return self.next
9 def set_val(self, new_val):
10 self.val = new_val
11 def set_next(self, new_next):
12 self.next = new_next
13
14 class LinkedList:
15 def __init__(self):
16 self.head = None
17 self.tail = None
18
19 def insert(self, index, val):
20 current_node = self.head
21 current_node_index = 0
22 if current_node is None:
23 raise Exception('This is an empty linked list')
24 while current_node_index < index-1:
25 current_node = current_node.next
26 if current_node is None:
27 raise Exception('exceed the length of the list')
28 current_node_index += 1
29 node = Node(val)
30 node.next = current_node.next
31 current_node.next = node
32 if node.next is None:
33 self.tail = node
34 def size(self):
35 current_node = self.head
36 count = 0
37 if current_node is None:
38 return 'This is an empty linked list'
39 while current_node:
40 count += 1
41 current_node = current_node.get_next()
42 return count
43
44 def search(self, val):
45 current_node = self.head
46 found = False
47 while current_node and found is False:
48 if current_node.get_val() == val:
49 found = True
50 else:
51 current_node = current_node.get_next()
52 if current_node is None:
53 raise ValueError('Data not in list')
54 return found
55
56 def delete(self, val):
57 current_node = self.head
58 previous = None
59 found = False
60 while current_node and found is False:
61 if current_node.get_val() == val:
62 found = True
63 else:
64 previous = current_node
65 current_node = current_node.get_next()
66
67 if current_node is None:
68 raise ValueError('Data not in list')
69
70 if self.head is self.tail:
71 self.head = None
72 self.tail = None
73
74 if current_node is None:
75 self.tail = current_node
76
77 if previous is None:
78 self.head = current_node.get_next()
79 else :
80 previous.set_next(current.get_next())
81
82 def iterate(self):
83 if not self.head:
84 return
85 current_node = self.head
86 yield current_node.val
87 while current_node.next:
88 current_node = current_node.next
89 yield current_node.val
90
91 def append(self, val):
92 new_node = Node(val)
93 if self.head is None:
94 self.head = new_node
95 self.tail = new_node
96 else:
97 self.tail.set_next(new_node)
98 self.tail = new_node
99 def empty(self):
100 return self.head is None
101
102 if __name__ == '__main__':
103 linklist = LinkedList()
104 for i in range(50):
105 linklist.append(i)
106 print(linklist.empty())
107 linklist.insert(20,20)
108 linklist.delete(0)
109 for node in linklist.iterate():
110 print('node is {0}'.format(node))
111 print(linklist.size())
112 print(linklist.search(13))
参考链接:
http://zhaochj.github.io/2016/05/12/2016-05-12-%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84-%E9%93%BE%E8%A1%A8/
https://www.codefellows.org/blog/implementing-a-singly-linked-list-in-python/
python中的数据结构-链表的更多相关文章
- Python 中的数据结构总结(一)
Python 中的数据结构 “数据结构”这个词大家肯定都不陌生,高级程序语言有两个核心,一个是算法,另一个就是数据结构.不管是c语言系列中的数组.链表.树和图,还是java中的各种map,随便抽出一个 ...
- Python中的数据结构
Python中的数据结构 这里总结一下Python中的内置数据结构(Built-in Data Structure):列表list.元组tuple.字典dict.集合set,涵盖的仅有部分重点,详细地 ...
- Python中的数据结构 --- 列表(list)
列表(list)是Python中最基本的.最常用的数据结构(相当于C语言中的数组,与C语言不同的是:列表可以存储任意数据类型的数据). 列表中的每一个元素分配一个索引号,且索引的下标是从0开始. ...
- Python中的数据结构和算法
一.算法 1.算法的时间复杂度 大 O 记法,是描述算法复杂度的符号O(1) 常数复杂度,最快速的算法. 取数组第 1000000 个元素 字典和集合的存取都是 O(1) 数组的存取是 O(1) O( ...
- python中的单向链表实现
引子 数据结构指的是是数据的组织的方式.从单个数据到一维结构(线性表),二维结构(树),三维结构(图),都是组织数据的不同方式. 为什么需要链表? 顺序表的构建需要预先知道数据大小来申请连续的存储空间 ...
- Python中的数据结构 --- 集合(set)
1.集合(set)里面的元素是不可以重复的 s={1,2,3,3,4,3,4} ## 输出之后,没有重复的 2.定义一个空集合 s = set([]) print s,type(s)3 ...
- Python中的数据结构 --- 元组(tuple)、字典(tuple)
元组(tuple)本身是不可变数据类型,没有增删改查:元组内可以存储任意数据类型一.元组的创建 例:t = (1,2.3,'star',[1,2,3]) ## 元组里面包含可变类型,故 ...
- Python中常用模块一
random模块 import random # 应用数学计算 print(random.random()) # 取随机小数 范围是 0-1之间 # 应用抽奖 , 彩票 print(random.ra ...
- 在python中使用json
在服务器和客户端的数据交互的时候,要找到一种数据格式,服务端好处理,客户端也好处理,这种数据格式应该是一种统一的标准,不管在哪里端处理起来都是统一的,现在这种数据格式非常的多,比如最早的xml,再后来 ...
随机推荐
- 阿里面试这样问:redis 为什么把简单的字符串设计成 SDS?
2021开工第一天,就有小伙伴私信我,还给我分享了一道他面阿里的redis题(这家伙绝比已经拿到年终奖了),我看了以后觉得挺有意思,题目很简单,是那种典型的似懂非懂,常常容易被大家忽略的问题.这里整理 ...
- 超详细Openstack核心组件——nova部署
目录 OpenStack-nova组件部署 nova组件部署位置 计算节点Nova服务配置(CT配置) 计算节点配置Nova服务-c1节点配置 计算节点-c2(与c1相同)(除了IP地址) contr ...
- TERSUS无代码开发(笔记01)-按装下载和基础语法
1.中国官网 https://tersus.cn/ 2.下载:https://tersus.cn/download/ 3.开发文档:https://tersus.cn/docs/ 4.基本元件说明 图 ...
- Vue学习笔记-chrome84版本浏览器跨域设置
一 使用环境: windows 7 64位操作系统 二 chrome84版本浏览器跨域设置 报错问题:Indicate whether to send a cookie in a cross- ...
- 微信小程序:post请求参数放在请求体中还是拼接到URL中需要看后台是如何接收的
前端发送post请求时,请求参数可以放在请求中,代码如下: function post(url, data, callback) { wx.request({ method: 'POST', url: ...
- Jmeter的脚本参数化
一.变量 Jmeter中的变量用法:${变量名称} 变量定义:两种 1.用户定义变量 User Defined Variables 2.用户参数 User Parameters 1.1用户定义变量 ...
- WPF绑定资源文件错误(error in binding resource string with a view in wpf)
报错:无法将"***Properties.Resources.***"StaticExtension 值解析为枚举.静态字段或静态属性 解决办法:尝试右键单击在Visual Stu ...
- Linux常用操作命令之文件权限(二)
一.基本概念 Linux/Unix是多用户系统:root是超级用户,拥有最高权限,其他用户及权限由root管理.文件/目录的权限有三种,可读read(r)可写write(w)可执行excute(x). ...
- ELK----elasticsearch7.10.1安装配置
环境: vmware centos7 1.下载适合自己的es版本 https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7-1 ...
- 剑指 Offer 49. 丑数 + 小根堆 + 动态规划
剑指 Offer 49. 丑数 Offer_49 题目详情 解法一:小根堆+哈希表/HashSet 根据丑数的定义,如果a是丑数,那么a2, a3以及a*5都是丑数 可以使用小根堆存储按照从小到大排序 ...