HashMap扩容和ConcurrentHashMap
HashMap
存储结构
HashMap是数组+链表+红黑树(1.8)实现的。
(1)Node[] table,即哈希桶数组。Node是内部类,实现了Map.Entry接口,本质是键值对。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; //用来定位数组索引位置
final K key;
V value;
Node<K,V> next; //链表的下一个node
Node(int hash, K key, V value, Node<K,V> next) { ... }
public final K getKey(){ ... }
public final V getValue() { ... }
public final String toString() { ... }
public final int hashCode() { ... }
public final V setValue(V newValue) { ... }
public final boolean equals(Object o) { ... }
}
下图链表中的Node节点
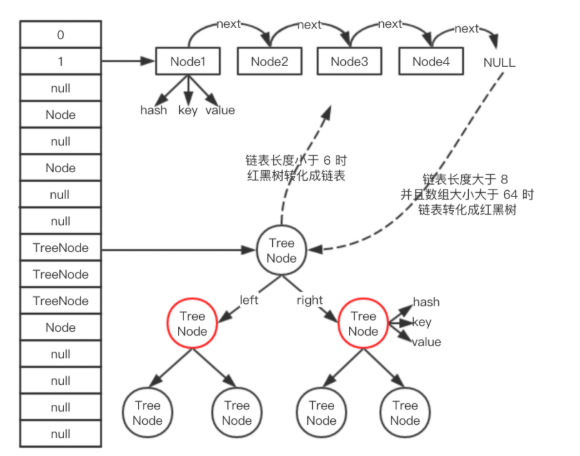
(2)Node[] table初始化长度为16,负载因子是0.75,threshold是HashMap容纳的最大Node个数,threshold = length * Load factor。
int threshold; // 所能容纳的key-value对极限
final float loadFactor; // 负载因子
int modCount;
int size;
功能实现-方法
扩容机制
1.7
1 void resize(int newCapacity) { //传入新的容量
2 Entry[] oldTable = table; //引用扩容前的Entry数组
3 int oldCapacity = oldTable.length;
4 if (oldCapacity == MAXIMUM_CAPACITY) { //扩容前的数组大小如果已经达到最大(2^30)了
5 threshold = Integer.MAX_VALUE; //修改阈值为int的最大值(2^31-1),这样以后就不会扩容了
6 return;
7 }
8
9 Entry[] newTable = new Entry[newCapacity]; //初始化一个新的Entry数组
10 transfer(newTable); //!!将数据转移到新的Entry数组里
11 table = newTable; //HashMap的table属性引用新的Entry数组
12 threshold = (int)(newCapacity * loadFactor);//修改阈值
13 }
这里就是使用一个容量更大的数组来代替已有的容量小的数组,transfer()方法将原有Entry数组的元素拷贝到新的Entry数组里。
1 void transfer(Entry[] newTable) {
2 Entry[] src = table; //src引用了旧的Entry数组
3 int newCapacity = newTable.length;
4 for (int j = 0; j < src.length; j++) { //遍历旧的Entry数组
5 Entry<K,V> e = src[j]; //取得旧Entry数组的每个元素
6 if (e != null) {
7 src[j] = null;//释放旧Entry数组的对象引用(for循环后,旧的Entry数组不再引用任何对象)
8 do {
9 Entry<K,V> next = e.next;
10 int i = indexFor(e.hash, newCapacity); //!!重新计算每个元素在数组中的位置
11 e.next = newTable[i]; //标记[1]
12 newTable[i] = e; //将元素放在数组上
13 e = next; //访问下一个Entry链上的元素
14 } while (e != null);
15 }
16 }
17 }
newTable[i]的引用赋给e.next,也就是头插法。
扩容过程:假设hash算法是简单的用key mod一下表的大小(数组长度)。数组长度为2,所以key=3、7、5,put顺序为5、7、3。在mod 2以后都冲突在table[1]这里了。这里假设负载因子 loadFactor=1,即当键值对的实际大小size 大于 table的实际大小时进行扩容。接下来的三个步骤是哈希桶数组 resize成4,然后所有的Node重新rehash的过程。

1.8
使用2次幂的扩展,所以,元素的位置要么是原位置,要么是在原位置再移动2次幂的位置。
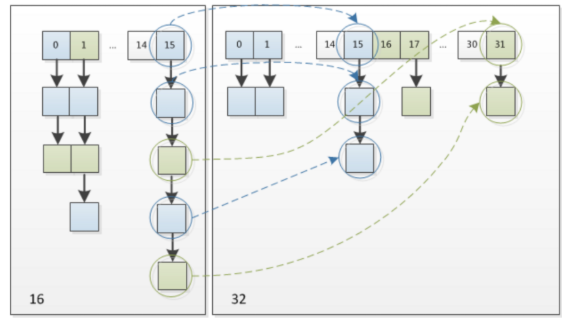
这个设计既省去了重新计算hash值的时间,而且同时,由于新增的1bit是0还是1可以认为是随机的,因此resize的
过程,均匀的把之前的冲突的节点分散到新的bucket了。这一块就是JDK1.8新增的优化点。
有一点注意区别,JDK1.7中rehash的时候,旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表
元素会倒置,但是从DK1.8不会倒置(尾插法)。
ConcurrentHashMap
1.put方法
1.1 数组初始化时的线程安全
数组初始化时,首先通过自旋保证一定可以初始化成功,然后通过CAS设置SIZECTL变量的值,保证同一时刻只能
有一个线程对数组进行初始化,CAS成功之后,会再次判断当前数组是够初始化完成。通过自旋 + CAS + 双重
check保证了数组初始化时的线程安全。
1.2 新增槽点值时的线程安全
通过自旋死循环保证一定可以新增成功。
当前槽点为空时,通过CAS新增。
当前槽点有值,锁住当前槽点。
put 时,如果当前槽点有值,就是 key 的 hash 冲突的情况,此时槽点上可能是链表或红黑树,我们通过锁住槽点,来保证同一时刻只会有一个线程能对槽点进行修改。
- 红黑树旋转时,锁住红黑树的根节点,保证同一时刻,当前红黑树只能被一个线程旋转。
以上4点保证在各种情况下,都是线程安全的,通过自旋 + CAS + 锁。
1.3 扩容时的线程安全
ConcurrentHashMap 扩容的方法交transfer,思路:
- 首先把老数组的值全部拷贝到扩容的新数组上,从数组的队尾开始拷贝;
- 拷贝数组的槽点时,先把原数组槽点锁住,保证原数组槽点不能操作,拷贝到新数组时,把原数组槽点复制为转移节点;
- 这时如果有新数据正好put到此槽点时,发现槽点为转移节点,就会一直等待,所以在扩容完成之前,槽点对应的数据不会变化;
- 从数组的尾部拷贝到头部,每拷贝成功一次,就把原数组中的节点设置为转移节点;
- 直到所有数组数据都拷贝到新数组时,直接把新数组整个复制给数组容器,拷贝完成。
资料
- 美团HashMap
- 慕课网专栏Java源码解析
HashMap扩容和ConcurrentHashMap的更多相关文章
- HashMap扩容死循环问题
原文:https://blog.csdn.net/Leon_cx/article/details/81911223 下面我们来模拟一下多线程场景下扩容会出现的问题: 假设在扩容过程中旧hash桶中有一 ...
- 面试笔记--HashMap扩容机制
转载请注明出处 http://www.cnblogs.com/yanzige/p/8392142.html 扩容必须满足两个条件: 1. 存放新值的时候当前已有元素的个数必须大于等于阈值 2. 存放新 ...
- JDK1.8 HashMap 扩容 对链表(长度小于默认的8)处理时重新定位的过程
关于HashMap的扩容过程,请参考源码或百度. 我想记录的是1.8 HashMap扩容是对链表中节点的Hash计算分析. 对术语先明确一下: hash计算指的确定节点在table[index]中的链 ...
- Redis的字典扩容与ConcurrentHashMap的扩容策略比较
本文介绍Redis的字典(是种Map)扩容与ConcurrentHashMap的扩容策略,并比较它们的优缺点. (不讨论它们的实现细节) 首先Redis的字典采用的是一种‘’单线程渐进式rehash‘ ...
- 关于JDK1.8 HashMap扩容部分源码分析
今天回顾hashmap源码的时候发现一个很有意思的地方,那就是jdk1.8在hashmap扩容上面的优化. 首先大家可能都知道,1.8比1.7多出了一个红黑树化的操作,当然在扩容的时候也要对红黑树进行 ...
- Java8中HashMap扩容算法小计
Java8的HashMap扩容过程主要就是集中在resize()方法中 final Node<K,V>[] resize() { // ...省略不重要的 } 其中,当HashMap扩容完 ...
- ArrayList && HashMap扩容策略
ArrayList扩容策略:默认10 扩容时是base + base/2, 即10 15 22 33 49...扩容时不安全:grow方法扩容时,赋值 elementData = Arrays.cop ...
- HashSet保证元素唯一原理以及HashMap扩容机制
一.HashSet保证元素唯一原理: 依赖于hashCode()和equals()方法1.唯一原理: 1.1 当HashSet集合要存储元素的时候,会调用该元素的hashCode()方法计算哈希值 1 ...
- HashMap的扩容机制, ConcurrentHashMap和Hashtable主要区别
源代码查看,有三个常量, static final int DEFAULT_INITIAL_CAPACITY = 16; static final int MAXIMUM_CAPACITY = 1 & ...
随机推荐
- git push&pull命令详解
git pull的作用是从一个仓库或者本地的分支拉取并且整合代码. git pull [<options>] [<repository> [<refspec>-] ...
- wpf toggleSwitch 的只读属性
xml code --------------------------------------------- <Page x:Class="UWPDemo.MainPage" ...
- css - rem和vw
css - rem和vw 物理像素 物理像素在不同的设备中1px里可以容纳的像素颗粒是不相同的,所以1px这个单位其实也是有N个像素颗粒填充的.同一尺寸屏幕的每个像素点所能容纳的像素颗粒越多显示效果越 ...
- hdfs数据迁移
有时候可能会进行hadoop集群数据拷贝的情况,可用以下命令进行拷贝 需要在目标集群上来进行操作 hadoop distcp hdfs://192.168.1.233:8020/user/hive/w ...
- 详细解读go语言中的map
Map map底层是由哈希表实现的 Go使用链地址法来解决键冲突. map本质上是一个指针,指向hmap 这里的buckets就是桶,bmap 每一个bucket最多可以放8个键值对,但是为了让内存排 ...
- promise例题
let promise = new Promise(resolve => { console.log('Promise'); resolve(); }); promise.then(functi ...
- Gogs (Go git server) 使用笔记
issue: 话题,一个新特性,BUG或其他关注的任何话题,都可创建issure,便于讨论,明确目标. label: 标签,一般用于描述issue的类型,如:bug.feature.enhanceme ...
- ES6中函数调用自身需要注意的问题
在传统的递归调用中,可以采用如下方式 function sum(n) { return sum(n - 1) + n;} 但如今es6盛行,为了保持代码一致性,可以采用两种解决方式. 第一种,将thi ...
- Qt之类反射机制
在java语言中,可以使用getObject(String)函数,从类型直接构建新的对象. 而在C++中是没有这种机制的,Qt虽然提供了元对象机制,但只可以获取对象的类名,不能反向构建. 所以搜索一下 ...
- WEB漏洞——RCE
RCE(remote command/code execute)远程命令/代码执行漏洞,可以让攻击者直接向后台服务器远程注入操作系统命令或者代码,从而控制后台系统. RCE漏洞 应用程序有时需要调用一 ...