Iceberg概述
背景
随着大数据领域的不断发展, 越来越多的概念被提出并应用到生产中而数据湖概念就是其中之一, 其概念参照阿里云的简介: 数据湖是一个集中式存储库, 可存储任意规模结构化和非结构化数据, 支持大数据和AI计算.数据湖构建服务(Data Lake Formation, DLF)作为云原生数据湖架构核心组成部分, 帮助用户简单快速地构建云原生数据湖解决方案. 数据湖构建提供湖上元数据统一管理、企业级权限控制, 并无缝对接多种计算引擎, 打破数据孤岛, 洞察业务价值.
数据湖解决方案中关键的一个环节就是数据存储和计算引擎之间的适配. 为了解决这个问题Netflix开发了Iceberg, 目前已经是Apache的顶级项目.
定义
Iceberg是一个面向海量数据分析场景的开放表格式(Table Format). 定义中所说的表格式(Table Format), 可以理解为元数据以及数据文件的一种组织方式, 处于计算框架(Flink, Spark...)之下, 数据文件之上. 如图所示:
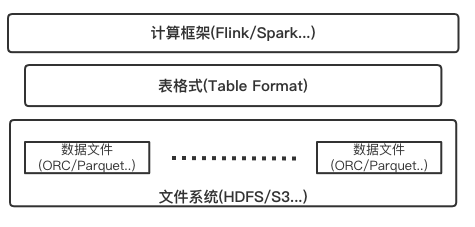
表格式(Table Format)属于数据库系统在实现层面上的一个抽象概念, 一般表格式会定义出一些表元数据信息以及API接口, 比如表中包含哪些字段, 表下面文件的组织形式、表索引信息、统计信息以及上层查询引擎读取、写入表中文件的接口.
特性
数据存储、计算引擎插件化
Iceberg在设计之初的目标就是提供一个开放通用的表格式(Table Format)实现方案.因此, 它不和特定的数据存储、计算引擎绑定. 目前大数据领域的常见数据存储(HDFS、S3...), 计算引擎(Flink、Spark...)都可以接入Iceberg. 在生产环境中, 技术人员可以根据公司的实际情况, 选择不同的组件搭使用.甚至, 可以不通过计算引擎,直接读取存在文件系统上的数据.
实时流批一体
Iceberg上游组件将数据写入完成后, 下游组件及时可读, 可查询.可以满足实时场景.并且Iceberg同时提供了流/批读接口、流/批写接口. 技术人员可以在同一个流程里, 同时处理流数据和批数据, 大大简化了ETL链路.
数据表演化(Table Evolution)
Iceberg可以通过SQL的方式进行表级别模式演进. 进行这些操作的时候, 代价极低. 不存在读出数据重新写入或者迁移数据这种费时费力的操作.
比如在常用的Hive中, 如果我们需要把一个按天分区的表, 改成按小时分区. 此时, 不能再原表之上直接修改, 只能新建一个按小时分区的表, 然后再把数据Insert到新的小时分区表. 而且, 即使我们通过Rename的命令把新表的名字改为原表, 使用原表的上次层应用, 也可能由于分区字段修改, 导致需要修改 SQL. 这样花费的经历是非常繁琐的.
模式演化(Schema Evolution)
Iceberg支持下面几种模式演化
ADD
向表或者嵌套结构增加新列
Drop
从表中或者嵌套结构中移除一列
Rename
重命名表中或者嵌套结构中的一列
Update
将复杂结构(struct, map<key, value>, list)中的基本类型扩展类型长度, 比如tinyint修改成int.
Reorder
改变列或者嵌套结构中字段的排列顺序
这里, 需要注意的是Map结构不支持ADD和Drop.
Iceberg保证模式演化(Schema Evolution)是没有副作用的独立操作流程, 一个元数据操作, 不会涉及到重写数据文件的过程. 具体的如下:
增加列时候, 不会从另外一个列中读取已存在的的数据
删除列或者嵌套结构中字段的时候, 不会改变任何其他列的值
更新列或者嵌套结构中字段的时候, 不会改变任何其他列的值
改变列列或者嵌套结构中字段顺序的时候, 不会改变相关联的值
在表中Iceberg 使用唯一ID来定位每一列的信息.新增一个列的时候,会新分配给它一个唯一ID, 并且绝对不会使用已经被使用的ID.
使用名称或者位置信息来定位列的, 都会存在一些问题, 比如使用名称的话,名称可能会重复, 使用位置的话, 不能修改顺序并且废弃的字段也不能删除.
分区演化(Partition Evolution)
Iceberg可以在一个已存在的表上直接修改, 因为Iceberg的查询流程并不和分区信息直接关联.
当我们改变一个表的分区策略时, 对应修改分区之前的数据不会改变, 依然会采用老的分区策略, 新的数据会采用新的分区策略, 也就是说同一个表会有两种分区策略, 旧数据采用旧分区策略, 新数据采用新新分区策略, 在元数据里两个分区策略相互独立,不重合.
在技术人员查询数据的时候, 如果存在跨分区策略的情况, 则会解析成两个不同执行计划, 如Iceberg官网提供图所示:
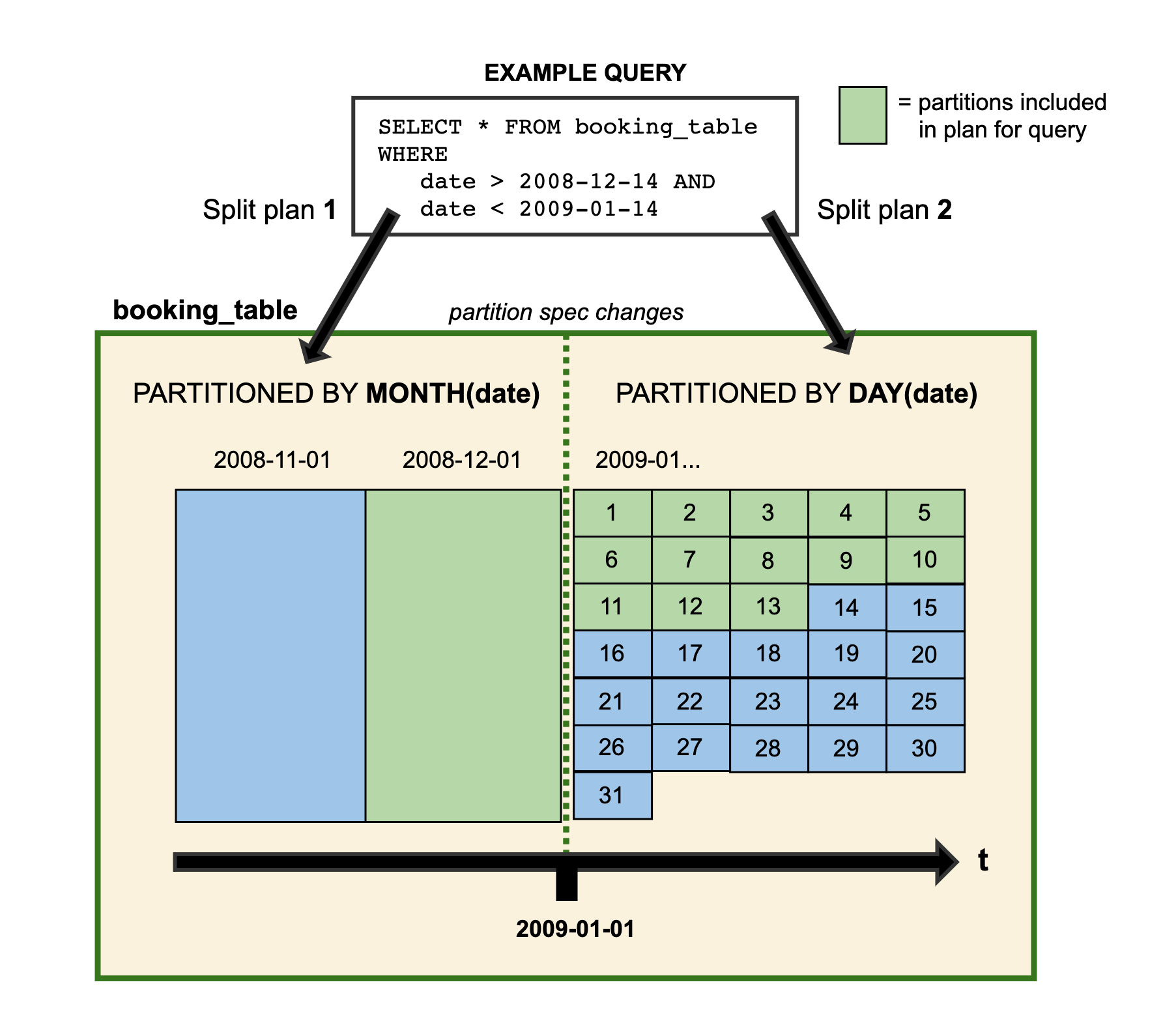
图中booking_table表2008年按月分区, 进入2009年后改为按天分区, 这两中分区策略共存于该表中.
得益于Iceberg的隐藏分区(Hidden Partition), 技术人员在写SQL 查询的时候, 不需要在SQL中特别指定分区过滤条件, Iceberg会自动分区, 过滤掉不需要的数据.
Iceberg分区演化操作同样是一个元数据操作, 不会重写数据文件.
列顺序演化(Sort Order Evolution)
Iceberg可以在一个已经存在的表上修改排序策略.修改了排序策略之后, 旧数据依旧采用老排序策略不变.往Iceberg里写数据的计算引擎总是会选择最新的排序策略, 但是当排序的代价极其高昂的时候, 就不进行排序了.
隐藏分区(Hidden Partition)
Iceberg的分区信息并不需要人工维护, 它可以被隐藏起来. 不同其他类似Hive 的分区策略, Iceberg的分区字段/策略(通过某一个字段计算出来), 可以不是表的字段和表数据存储目录也没有关系. 在建表或者修改分区策略之后, 新的数据会自动计算所属于的分区.在查询的时候同样不用关系表的分区是什么字段/策略, 只需要关注业务逻辑, Iceberg会自动过滤不需要的分区数据.
PS: 正是由于Iceberg的分区信息和表数据存储目录是独立的, 使得Iceberg的表分区可以被修改,而且不和涉及到数据迁移.
镜像数据查询(Time Travel)
Iceberg提供了查询表历史某一时间点数据镜像(snapshot)的能力. 通过该特性技术人员可以将最新的SQL逻辑, 应用到历史数据上.
支持事务(ACID)
Iceberg通过提供事务(ACID)的机制, 使其具备了upsert的能力并且使得边写边读成为可能, 从而数据可以更快的被下游组件消费.通过事务保证了下游组件只能消费已commit的数据, 而不会读到部分甚至未提交的数据.
基于乐观锁的并发支持
Iceberg基于乐观锁提供了多个程序并发写入的能力并且保证数据线性一致.
文件级数据剪裁
Iceberg的元数据里面提供了每个数据文件的一些统计信息, 比如最大值, 最小值, Count计数等等. 因此, 查询SQL的过滤条件除了常规的分区, 列过滤, 甚至可以下推到文件级别, 大大加快了查询效率.
不足
Iceberg虽然拥有高度抽象和优雅的设计,但是在功能上还不够完善, 比如行级删除的能力, FlinkSQL的适配性, FlinkSQL的V2表流式读取能力, 以及行级更新还存在BUG等等. 不过, 社区方面已经已经在全力完善相关功能.一些生产中需要的重要特性, 已经规划到Iceberg的Roadmap了. 随着, 相关功能的完善, Iceberg 在国内的前景是非常值得期待的.
Iceberg概述的更多相关文章
- 【AR实验室】ARToolKit之概述篇
0x00 - 前言 我从去年就开始对AR(Augmented Reality)技术比较关注,但是去年AR行业一直处于偶尔发声的状态,丝毫没有其"异姓同名"的兄弟VR(Virtual ...
- Recurrent Neural Network系列1--RNN(循环神经网络)概述
作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 本文翻译自 RECURRENT NEURAL NETWORKS T ...
- Swift3.0服务端开发(一) 完整示例概述及Perfect环境搭建与配置(服务端+iOS端)
本篇博客算是一个开头,接下来会持续更新使用Swift3.0开发服务端相关的博客.当然,我们使用目前使用Swift开发服务端较为成熟的框架Perfect来实现.Perfect框架是加拿大一个创业团队开发 ...
- .Net 大型分布式基础服务架构横向演变概述
一. 业务背景 构建具备高可用,高扩展性,高性能,能承载高并发,大流量的分布式电子商务平台,支持用户,订单,采购,物流,配送,财务等多个项目的协作,便于后续运营报表,分析,便于运维及监控. 二. 基础 ...
- [C#] 进阶 - LINQ 标准查询操作概述
LINQ 标准查询操作概述 序 “标准查询运算符”是组成语言集成查询 (LINQ) 模式的方法.大多数这些方法都在序列上运行,其中的序列是一个对象,其类型实现了IEnumerable<T> ...
- 【基于WinForm+Access局域网共享数据库的项目总结】之篇一:WinForm开发总体概述与技术实现
篇一:WinForm开发总体概述与技术实现 篇二:WinForm开发扇形图统计和Excel数据导出 篇三:Access远程连接数据库和窗体打包部署 [小记]:最近基于WinForm+Access数据库 ...
- Java消息队列--JMS概述
1.什么是JMS JMS即Java消息服务(Java Message Service)应用程序接口,是一个Java平台中关于面向消息中间件(MOM)的API,用于在两个应用程序之间,或分布式系统中发送 ...
- [AlwaysOn Availability Groups]健康模型 Part 1——概述
健康模型概述 在成功部署AG之后,跟踪和维护健康状况是很重要的. 1.AG健康模型概述 AG的健康模型是基于策略管理(Policy Based Management PBM)的.如果不熟悉这个特性,可 ...
- μCos-ii学习笔记1_概述
一.μCos-ii _概述 网上关于μCosii的文章多不胜数,本人学习的过程中也参考了很多人的理解和想法,看的是卢有亮老师的<嵌入式实时操作系统-μC/OS原理与实践>(第2版),同时也 ...
随机推荐
- Java学习之随堂笔记系列——day04
今日内容1.break和continue关键字以及循环嵌套 1.1 break和continue的区别? continue表示跳过当前循环,继续执行下一次循环break表示结束整个 ...
- Python守护线程简述
thread模块不支持守护线程的概念,当主线程退出时,所有的子线程都将终止,不管它们是否仍在工作,如果你不希望发生这种行为,就要引入守护线程的概念. threading模块支持守护线程,其工作方式是: ...
- 疏忽Bug
仅供自己留存备份 错误: vector不是模板 解决: 头文件未包含 头文件: #include <vector> using namespace std; 错误: 多字节字符 ...
- ARC122C-Calculator【乱搞,构造】
正题 题目链接:https://atcoder.jp/contests/arc122/tasks/arc122_c 题目大意 一个数对开始是\((0,0)\),每次可以选择一个数加一或者让一个数加上另 ...
- Redis核心原理与实践--散列类型与字典结构实现原理
Redis散列类型可以存储一组无序的键值对,它特别适用于存储一个对象数据. > HSET fruit name apple price 7.6 origin china 3 > HGET ...
- Appium+Python自动化环境搭建-1
前言 appium可以说是做app最火的一个自动化框架,它的主要优势是支持android和ios,另外脚本语言也是支持java和Python. 小编擅长Python,所以接下来的教程是appium+p ...
- 深入浅出WPF-12.绘图与动画
绘图 1)Brush(画刷) SolidColorBrush实心画刷,直接使用颜色赋值 LinearGradientBrush线性渐变画刷,色彩沿设定的直线方向.按设定的变化点进行渐变 RadialG ...
- 安全通信协议SSH应用与分析
一.实验简介: 本次实验属于安全协议应用与分析系列 二 实验环境: Windows server 2003 server windows xp 做client 三.实验目的 通过该实验了解SSH服务器 ...
- 洛谷4719 【模板】动态dp 学习笔记(ddp 动态dp)
qwq大概是混乱的一个题. 首先,还是从一个比较基础的想法开始想起. 如果每次暴力修改的话,那么每次就可以暴力树形dp 令\(dp[x][0/1]\)表示\(x\)的子树中,是否选择\(x\)这个点的 ...
- bzoj3073Journeys(线段树优化最短路)
这里还是一道涉及到区间连边的问题. 如果暴力去做,那么就会爆炸 那么这时候就需要线段树来优化了. 因为是双向边 所以需要两颗线段树来分别对应入边和出边 QwQ然后做就好了咯 不过需要注意的是,这个边数 ...