springcloud优雅停止上下线与熔断
SpringCloud 服务优雅上下线
Spring Boot 框架使用“约定大于配置”的特性,优雅流畅的开发过程,应用部署启动方式也很优雅。
但是我们通常使用的停止应用的方式是 kill -9 <pid> ,即使我们编写脚本,还是显得有些粗鲁。
这样的应用停止方式,在停止的那一霎那,应用中正在处理的业务逻辑会被中断,导致产生业务异常情形。
这种情况如何避免,本文介绍的优雅停机,将完美解决该问题。
什么叫优雅停机?
简单说就是在对应用进程发送停止指令之后,能保证正在执行的业务操作不受影响。应用接收到停止指令之后的步骤应该是,停止接收访问请求,等待已经接收到的请求处理完成,并能成功返回,这时才真正停止应用。
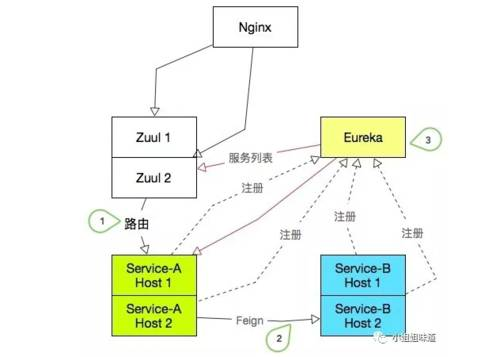
- Spring Cloud 微服务到注册中心的注册操作是通过 Rest 接口调用的。
- 它不能像 ZooKeeper 那样,有问题节点反馈及时生效。
- 也不能像 Redis 那么快的去轮询,太耗费资源。
如下图:
优雅的三个要求:
1) ServiceA 下线一台实例后,Zuul 网关的调用不能失败;
2) ServiceB 下线一台实例后,ServiceA 的 Feign 调用不能失败;
3) 其中一个微服务上线或下线,Eureka 及其它微服务能够快速感知;
说白了就一件事,怎样尽量缩短服务下线后 Zuul 和其他被依赖服务的发现时间,并在这段时间内保证请求不失败。
解决时间问题
影响因素

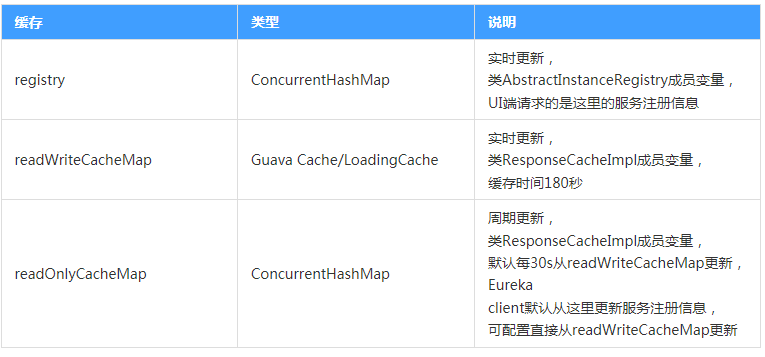
三级缓存
缓存相关配置
| 配置 | 默认 | 说明 |
|---|---|---|
| eureka.server.useReadOnlyResponseCache | true | Client从readOnlyCacheMap更新数据,false则跳过readOnlyCacheMap直接从readWriteCacheMap更新 |
| eureka.server.responsecCacheUpdateIntervalMs | 30000 | readWriteCacheMap更新至readOnlyCacheMap周期,默认30s |
| eureka.server.evictionIntervalTimerInMs | 60000 | 清理未续约节点(evict)周期,默认60s |
| eureka.instance.leaseExpirationDurationInSeconds | 90 | 清理未续约节点超时时间,默认90s |
关键类
| 类名 | 说明 |
|---|---|
| com.netflix.eureka.registry.AbstractInstanceRegistry | 保存服务注册信息,持有registry和responseCache成员变量 |
| com.netflix.eureka.registry.ResponseCacheImpl | 持有readWriteCacheMap和readOnlyCacheMap成员变量 |
1) Eureka 的两层缓存问题 (待确认)
Eureka Server 默认有两个缓存,一个是 ReadWriteMap 读写缓存,另一个是 ReadOnlyMap 只读缓存。
Eureka
Server
存在三个变量:(registry、readWriteCacheMap、readOnlyCacheMap)保存服务注册信息,默认情况下定时任务每
30s 将 readWriteCacheMap 同步至 readOnlyCacheMap,每 60s 清理超过 90s
未续约的节点,Eureka Client 每 30s 从 readOnlyCacheMap 更新服务注册信息,而 UI 则从 registry
更新服务注册信息。
有服务提供者注册、注销服务或者维持心跳时,会修改 ReadWriteMap。
当有服务调用者查询服务实例列表时,默认会从 ReadOnlyMap 读取(这个在原生 Eureka 可以配置,SpringCloud Eureka 中不能配置,一定会启用 ReadOnlyMap 读取),
这样可以减少 ReadWriteMap 读写锁的争用,增大吞吐量。
EurekaServer 定时把数据从 ReadWriteMap 更新到 ReadOnlyMap 中。
Eureka注册中心收到注销请求后,会先将信息更新到读写缓存中。
注册中心有个定时任务会定时(默认值是30s)将读写缓存中的数据同步到只读缓存中。
shouldUseReadOnlyResponseCache 读取的是 eureka.server.use-read-only-response-cache 参数
responseCacheUpdateIntervalMs 读取的是 eureka.server.response-cache-update-interval-ms 参数
responseCacheAutoExpirationInSeconds 读取的是 eureka.server.response-cache-update-interval-ms 参数
eureka server对rest api提供了多级缓存,第一层是readOnlyCacheMap,然后是readWriteCacheMap,最后如果readWriteCacheMap读取不到,然后就从registry进行读取。其中readOnlyCacheMap会定时从readWriteCacheMap更新数据,而readWriteCacheMap有自己的过期时间,过期后自动从loader加载新数据。
2) 心跳时间
服务提供者注册服务后,会定时心跳。这个根据服务提供者的 Eureka 配置中的服务刷新时间决定。还有个配置是服务过期时间,这个配置在服务提供者配置但是在 EurekaServer 使用了,但是默认配置 EurekaServer 不会启用这个字段。需要配置好 EurekaServer 的扫描失效时间,才会启用 EurekaServer 的主动失效机制。在这个机制启用下:每个服务提供者会发送自己服务过期时间上去,EurekaServer 会定时检查每个服务过期时间和上次心跳时间,如果在过期时间内没有收到过任何一次心跳,同时没有处于保护模式下,则会将这个实例从 ReadWriteMap 中去掉。
3) 调用者服务从 Eureka 拉列表的轮训间隔
由于eureka注册中心没有通知的功能,只能由节点自己发起刷新请求,所以修改状态后,需要等到相关节点下一次刷新后才会生效。
节点刷新是通过定时任务实现的,源码在com.netflix.discovery.DiscoveryClient中,并且任务是在构造方法中初始化的,还不能自己手动触发。
CloudEurekaClient中有一个刷新的方法,发布一个心跳事件,但这个方法是protected,没法通过实例调用,并且依赖于心跳事件。
应用节点默认刷新事件是60秒一次,时间也不算太长,所以动态停用节点后再60秒内生效,应该是在能接受的范围吧,并且这个时间还能配置。
4) Ribbon 缓存
Ribbon 去请求其它微服务时的“负载均衡”列表,有缓存时间,过期后才会更新。
解决方式
1) 禁用 Eureka 的 ReadOnlyMap 缓存 (Eureka 端)
eureka.server.use-read-only-response-cache: false
2) 启用主动失效,并且每次主动失效检测间隔为 3s (Eureka 端)
eureka.server.eviction-interval-timer-in-ms: 3000
像 eureka.server.responseCacheUpdateInvervalMs和 eureka.server.responseCacheAutoExpirationInSeconds在启用了主动失效后其实没什么用了。默认的 180s 真够把人给急疯的。
3) 调整服务过期时间 (服务提供方)
eureka.instance.lease-expiration-duration-in-seconds: 15
超过这个时间没有接收到心跳 Eureka Server 就会将这个实例剔除。
注意:Eureka Server 一定要设置 eureka.server.eviction-interval-timer-in-ms ,否则这个配置无效,这个配置一般为服务刷新时间配置的三倍。默认 90s!
4) 服务刷新时间配置,每隔这个时间会主动心跳一次 (服务提供方)
eureka.instance.lease-renewal-interval-in-seconds: 5
服务心跳间隔时间, 默认 30s。
5) 拉服务列表时间间隔 (客户端)
eureka.client.registryFetchIntervalSeconds: 5
客户端去 Eureka 注册表拉取服务列表的时间间隔设置,默认 30s。
6) ribbon 刷新时间 (客户端)
ribbon.ServerListRefreshInterval: 5000
注意 ribbon 也有缓存,ribbon 中此参数可以用来调整刷新server list的时间间隔,默认 30s
这些超时时间相互影响,三个地方都需要配置,一不小心就会出现服务不下线,服务不上线的囧境。不得不说 SpringCloud 的这套默认参数很复杂,一定要小心谨慎地修改。
重试机制
那么一台服务器下线,最长的不可用(指请求会落到下线的服务器上,请求失败)的时间是多少呢?
赶的巧的话,这个基本时间就是 eureka.client.registryFetchIntervalSeconds+ribbon.ServerListRefreshInterval, 大约是 8秒的时间。如果算上服务端主动失效的时间,这个时间会增加到 11秒。
如果你只有两个实例,极端情况下服务上线的发现时间也需要 11 秒,那就是 22 秒的时间。
理想情况下,在这 11 秒之间,请求是失败的。假如你的 QPS 是 1000,部署了四个节点,那么在 11 秒中失败的请求数量会是 1000 / 4 * 11 = 2750,这是不可接受的。所以我们要引入重试机制。
SpringCloud 引入重试还是比较简单的。但不是配置一下就可以的,既然用了重试,那么就还需要控制超时。可以按照以下的步骤:
1) 引入 pom (千万别忘了哦)
org.springframework.retryspring-retry
2) 加入配置
ribbon.OkToRetryOnAllOperations:true # (是否所有操作都重试,若false则仅get请求重试)
ribbon.MaxAutoRetriesNextServer:3 # (重试负载均衡其他实例最大重试次数,不含首次实例)
ribbon.MaxAutoRetries:1 # (同一实例最大重试次数,不含首次调用)
ribbon.ReadTimeout:30000
ribbon.ConnectTimeout:3000
ribbon.retryableStatusCodes:404,500,503 # (那些状态进行重试)
spring.cloud.loadbalancer.retry.enable:true # (重试开关)
3) 发布系统
OK, 机制已经解释清楚,但是实践起来还是很繁杂的,让人焦躁。比如有一个服务有两个实例,我要一台一台的去发布,在发布第二台之前,起码要等上 11 秒。如果手速太快,那就是灾难。所以一个配套的发布系统是必要的。
首先可以通过 rest 请求去请求 Eureka,主动去隔离一台实例,多了这一步,可以减少至少 3 秒服务不可用的时间(还是比较划算的)。
然后通过打包工具打包,推包。依次上线替换。
附录 —— Spring Boot 项目优雅停止
默认的 Spring Boot 项目收到 kill 发来的 SIGTERM 信号后,会中断所有正在进行的请求,这样有些粗鲁。
Spring Boot 优雅停止参考:https://github.com/erdanielli/spring-boot-graceful-shutdown/tree/master/src/main/java/com/github/erdanielli/boot/shutdown
package com.sudheera.playground.spring.testgracefullshutdown.config; import java.util.concurrent.Executor;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit; import org.apache.catalina.connector.Connector;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory; import org.springframework.boot.web.embedded.tomcat.TomcatConnectorCustomizer;
import org.springframework.context.ApplicationListener;
import org.springframework.context.event.ContextClosedEvent;
import org.springframework.stereotype.Component; /**
* Custom Tomcat protocol handler's executor service shutdown listner implementation to avoid spring application context
* to shutdown before shutting down the tomcat server threads. This bean will do following when the application context
* closed event occurred.
*
* 1. Pausing connector to stop accepting new connections
* 2. Invoke shutdown of the ThreadPoolExecutor used in the Tomcat protocol handler
* 3. Await until ThreadPoolExecutor is completely shutdown
*
* Read : https://github.com/spring-projects/spring-boot/issues/4657 for more information regarding the issue, this
* implementation is based on `wilkinsona`s proposed solution in the issue thread
*/
@Component
public class TomcatGracefulShutdownListener implements TomcatConnectorCustomizer, ApplicationListener<ContextClosedEvent> { private static final Logger log = LoggerFactory.getLogger(TomcatGracefulShutdownListener.class);
private static final int AWAIT_SECONDS = 100; private volatile Connector connector; @Override
public void customize(Connector connector) {
this.connector = connector;
} @Override
public void onApplicationEvent(ContextClosedEvent event) {
connector.pause();
Executor executor = connector.getProtocolHandler().getExecutor();
if (executor == null) {
return;
} if (!(executor instanceof ThreadPoolExecutor)) {
log.warn("{} is not an instance of ThreadPoolExecutor class, Can't ensure graceful shutdown..!!", executor.getClass());
return;
} ThreadPoolExecutor threadPoolExecutor = (ThreadPoolExecutor) executor;
log.info("Shutting down Tomcat thread pool executor. Active thread count : {}", threadPoolExecutor.getActiveCount());
threadPoolExecutor.shutdown();
try {
if (threadPoolExecutor.awaitTermination(AWAIT_SECONDS, TimeUnit.SECONDS)) {
log.info("Tomcat shutdown gracefully.!");
return;
} threadPoolExecutor.shutdownNow();
if (!threadPoolExecutor.awaitTermination(AWAIT_SECONDS, TimeUnit.SECONDS)) {
log.warn("Tomcat thread pool executor did not terminate. Active thread count : {}", threadPoolExecutor.getActiveCount());
} } catch (InterruptedException ex) {
log.error("Got interrupted while waiting for graceful shutdown", ex);
Thread.currentThread().interrupt();
}
}
}
Spring Boot 项目优雅停止
当我们流量请求到此接口执行业务逻辑的时候,若服务端此时执行关机 (kill),spring boot 默认情况会直接关闭容器(tomcat 等),导致此业务逻辑执行失败。在一些业务场景下:会出现数据不一致的情况,事务逻辑不会回滚。
首先来介绍下什么是优雅地停止,简而言之,就是对应用进程发送停止指令之后,能保证正在执行的业务操作不受影响,可以继续完成已有请求的处理,但是停止接受新请求。
在 Spring Boot 2.3 中增加了新特性优雅停止,目前 Spring Boot 内置的四个嵌入式 Web 服务器(Jetty、Reactor Netty、Tomcat 和 Undertow)以及反应式和基于 Servlet 的 Web 应用程序都支持优雅停止。
下面,我们先用新版本尝试下:
Spring Boot 2.3 优雅停止
首先创建一个 Spring Boot 的 Web 项目,版本选择 2.3.0.RELEASE,Spring Boot 2.3.0.RELEASE 版本内置的 Tomcat 为 9.0.35。
然后需要在 application.yml 中添加一些配置来启用优雅停止的功能:
# 开启优雅停止 Web 容器,默认为 IMMEDIATE:立即停止
server:
shutdown: graceful # 最大等待时间
spring:
lifecycle:
timeout-per-shutdown-phase: 30s
其中,平滑关闭内置的 Web 容器(以 Tomcat 为例)的入口代码在 org.springframework.boot.web.embedded.tomcat 的 GracefulShutdown 里,大概逻辑就是先停止外部的所有新请求,然后再处理关闭前收到的请求,有兴趣的可以自己去看下。
内嵌的 Tomcat 容器平滑关闭的配置已经完成了,那么如何优雅关闭 Spring 容器了,就需要 Actuator 来实现 Spring 容器的关闭了。
然后加入 actuator 依赖,依赖如下所示:
org.springframework.boot
spring-boot-starter-actuator
然后接着再添加一些配置来暴露 actuator 的 shutdown 接口:
# 暴露 shutdown 接口
management:
endpoint:
shutdown:
enabled: true
endpoints:
web:
exposure:
include: shutdown
其中通过 Actuator 关闭 Spring 容器的入口代码在 org.springframework.boot.actuate.context 包下 ShutdownEndpoint 类中,主要的就是执行 doClose() 方法关闭并销毁 applicationContext,有兴趣的可以自己去看下。
配置搞定后,然后在 controller 包下创建一个 WorkController 类,并有一个 work 方法,用来模拟复杂业务耗时处理流程,具体代码如下:
@RestController
public class WorkController { @GetMapping("/work")
public String work() throws InterruptedException {
// 模拟复杂业务耗时处理流程
Thread.sleep(10 * 1000L);
return "success";
}
}
然后,我们启动项目,先用 Postman 请求 http://localhost:8080/work 处理业务:
然后在这个时候,调用 http://localhost:8080/actuator/shutdown 就可以执行优雅地停止,返回结果如下:
{
"message": "Shutting down, bye..."
}
如果在这个时候,发起新的请求 http://localhost:8080/work, 会没有反应
再回头看第一个请求,返回了结果:success。
其中有几条服务日志如下:
2020-05-20 23:05:15.163 INFO 102724 --- [ Thread-253] o.s.b.w.e.tomcat.GracefulShutdown : Commencing graceful shutdown. Waiting for active requests to complete
2020-05-20 23:05:15.287 INFO 102724 --- [tomcat-shutdown] o.s.b.w.e.tomcat.GracefulShutdown : Graceful shutdown complete
2020-05-20 23:05:15.295 INFO 102724 --- [ Thread-253] o.s.s.concurrent.ThreadPoolTaskExecutor : Shutting down ExecutorService 'applicationTaskExecutor'
从日志中也可以看出来,当调用 shutdown 接口的时候,会先等待请求处理完毕后再优雅地停止。
到此为止,Spring Boot 2.3 的优雅关闭就讲解完了,是不是很简单呢?如果是在之前不支持优雅关闭的版本如何去做呢?
不同 web 容器优雅停机行为区别
容器停机行为取决于具体的 web 容器行为
| web 容器名称 | 行为说明 |
|---|---|
| tomcat 9.0.33+ | 停止接收请求,客户端新请求等待超时。 |
| Reactor Netty | 停止接收请求,客户端新请求等待超时。 |
| Undertow | 停止接收请求,客户端新请求直接返回 503。 |
Spring Boot 旧版本优雅停止
在这里介绍 GitHub 上 issue 里 Spring Boot 开发者提供的一种方案:
选取的 Spring Boot 版本为 2.2.6.RELEASE,首先要实现 TomcatConnectorCustomizer 接口,该接口是自定义 Connector 的回调接口:
@FunctionalInterface
public interface TomcatConnectorCustomizer { void customize(Connector connector);
}
除了定制 Connector 的行为,还要实现 ApplicationListener 接口,因为要监听 Spring 容器的关闭事件,即当前的 ApplicationContext 执行 close() 方法,这样我们就可以在请求处理完毕后进行 Tomcat 线程池的关闭,具体的实现代码如下:
@Bean
public GracefulShutdown gracefulShutdown() {
return new GracefulShutdown();
} private static class GracefulShutdown implements TomcatConnectorCustomizer, ApplicationListener {
private static final Logger log = LoggerFactory.getLogger(GracefulShutdown.class); private volatile Connector connector; @Override
public void customize(Connector connector) {
this.connector = connector;
} @Override
public void onApplicationEvent(ContextClosedEvent event) {
this.connector.pause();
Executor executor = this.connector.getProtocolHandler().getExecutor();
if (executor instanceof ThreadPoolExecutor) {
try {
ThreadPoolExecutor threadPoolExecutor = (ThreadPoolExecutor) executor;
threadPoolExecutor.shutdown();
if (!threadPoolExecutor.awaitTermination(30, TimeUnit.SECONDS)) {
log.warn("Tomcat thread pool did not shut down gracefully within 30 seconds. Proceeding with forceful shutdown");
}
} catch (InterruptedException ex) {
Thread.currentThread().interrupt();
}
}
}
}
有了定制的 Connector 回调,还需要在启动过程中添加到内嵌的 Tomcat 容器中,然后等待监听到关闭指令时执行,addConnectorCustomizers 方法可以把定制的 Connector 行为添加到内嵌的 Tomcat 中,具体代码如下:
@Bean
public ConfigurableServletWebServerFactory tomcatCustomizer() {
TomcatServletWebServerFactory factory = new TomcatServletWebServerFactory();
factory.addConnectorCustomizers(gracefulShutdown());
return factory;
}
到此为止,内置的 Tomcat 容器平滑关闭的操作就完成了,Spring 容器优雅停止上面已经说过了,再次就不再赘述了。
通过测试,同样可以达到上面那样优雅停止的效果。
总结
本文主要讲解了 Spring Boot 2.3 版本和旧版本的优雅停止,避免强制停止导致正在处理的业务逻辑会被中断,进而导致产生业务异常的情形。
另外使用 Actuator 的同时要注意安全问题,比如可以通过引入 security 依赖,打开安全限制并进行身份验证,设置单独的 Actuator 管理端口并配置只对内网开放等。
本文的完整代码在 https://github.com/wupeixuan/SpringBoot-Learn 的 graceful-shutdown 目录下。
最好的关系就是互相成就,大家的在看、转发、留言三连就是我创作的最大动力。
参考
https://github.com/spring-projects/spring-boot/issues/4657
https://github.com/wupeixuan/SpringBoot-Learn
Hystrix 熔断器
雪崩效应
雪崩效应是一种因服务提供者的不可用,导致服务调用者的不可用,并将不可用逐渐放大的过程。
当一切正常时,请求流如下所示:

当有后端系统有问题时,它会阻止所有用户请求:

随着流量的增大,单个后端依赖性变得有问题,这可能导致所有服务器上的所有资源在几秒钟内变得饱和。
应用程序中可能会导致网络请求通过网络或客户端库传播的每个点都是潜在故障的根源。
比故障更糟糕的是,这些应用程序还会导致服务之间的等待时间增加,而且会进一步影响到备份队列,线程和其他系统资源,从而导致整个系统出现更多级联故障。
当通过第三方客户端执行网络访问时,这些问题会更加严重。“第三方”是一个隐藏了实施细节的“黑匣子”,可以随时更改,并且每个客户端库的网络或资源配置都不相同,并且通常难以监视和监控。
熔断
如果某个目标服务调用慢或者有大量超时,此时,熔断该服务的调用,对于后续调用请求,不在继续调用目标服务,直接返回,快速释放资源。如果目标服务情况好转则恢复调用。
熔断器是位于线程池之前的组件。用户请求某一服务之后,Hystrix会先经过熔断器,此时如果熔断器的状态是打开(跳起),则说明已经熔断,这时将直接进行降级处理,不会继续将请求发到线程池。熔断器相当于在线程池之前的一层屏障。每个熔断器默认维护10个bucket
,每秒创建一个bucket ,每个blucket记录成功,失败,超时,拒绝的次数。当有新的bucket被创建时,最旧的bucket会被抛弃。
熔断器的状态机:
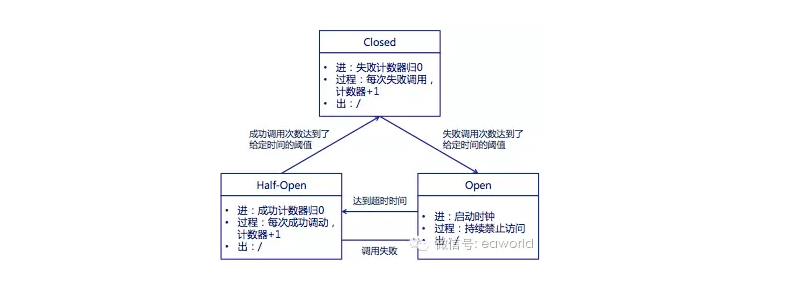
- Closed:熔断器
关闭状态,调用失败次数积累,到了阈值(或一定比例)则启动熔断机制; - Open:熔断器
打开状态,此时对下游的调用都内部直接返回错误,不走网络,但设计了一个时钟选项,默认的时钟达到了一定时间(这个时间一般设置成平均故障处理时间,也就是MTTR),到了这个时间,进入半熔断状态; - Half-Open:
半熔断状态,允许定量的服务请求,如果调用都成功(或一定比例)则认为恢复了,关闭熔断器,否则认为还没好,又回到熔断器打开状态;
Hystrix的工作原理:
- 防止任何单个依赖项耗尽所有容器(例如Tomcat)用户线程。
- 减少负载并快速失败,而不是排队。
- 在可行的情况下提供备用方法,以保护用户免受故障的影响。
- 使用隔离技术(例如隔板,泳道和断路器模式)来限制任何一种依赖关系的影响。
- 通过近实时指标,监控和警报优化故障发现时间
- 通过在 Hystrix 的大多数方面中以低延迟传播配置更改来优化恢复时间,并支持动态属性更改,这使您可以通过低延迟反馈回路进行实时操作修改。
- 防止整个依赖项客户端执行失败,而不仅仅是网络流量失败。
流程
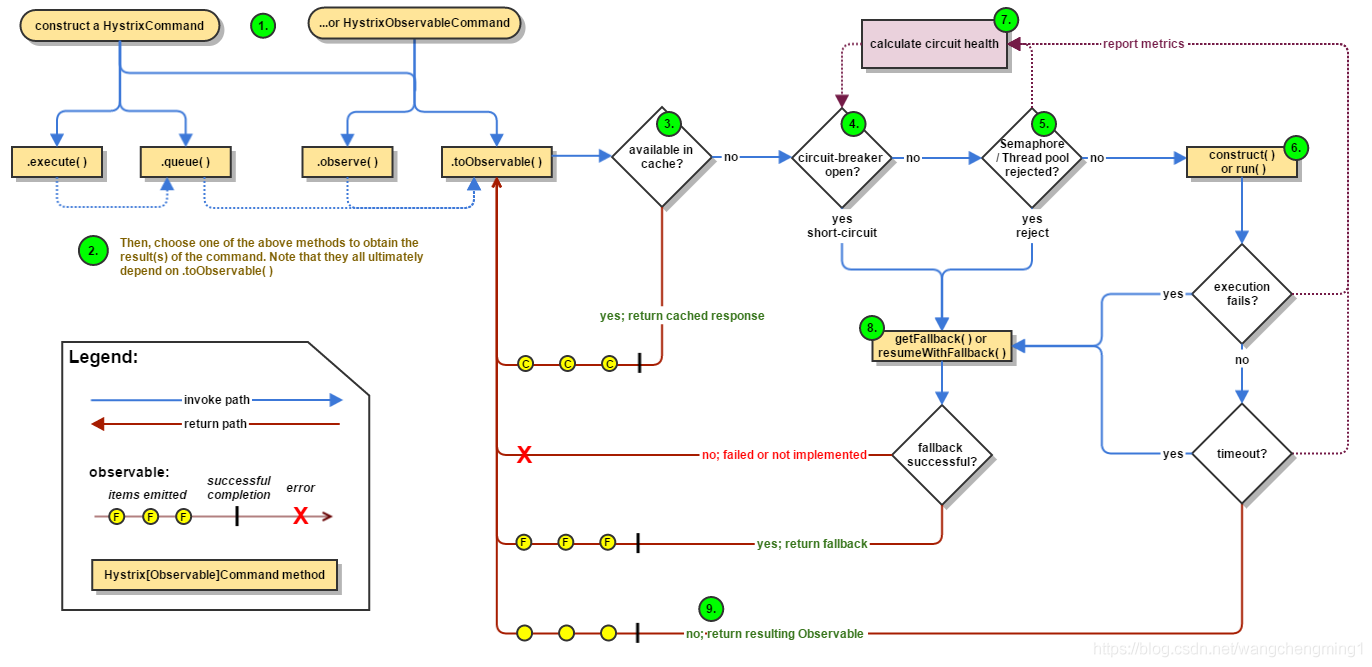
Fallback 回退
- 执行超时
- 执行过程抛出异常
- 断路器打开状态
- 线程池拒绝(池满后的拒绝策略)
- 信号量拒绝(信号量耗完)
电路打开和闭合的精确方式
- 如果电路上的音量达到某个阈值(HystrixCommandProperties.circuitBreakerRequestVolumeThreshold())…
- 并且错误百分比超过阈值误差百分比(HystrixCommandProperties.circuitBreakerErrorThresholdPercentage())…
- 然后,断路器从转换CLOSED为OPEN。
- 当它断开时,它会使针对该断路器的所有请求短路。
- 经过一段时间(HystrixCommandProperties.circuitBreakerSleepWindowInMilliseconds())后,下一个单个请求被允许通过(这是HALF-OPEN状态)。如果请求失败,则断路器将OPEN在睡眠窗口持续时间内返回到该状态。如果请求成功,断路器将切换到,CLOSED并且1.中的逻辑将再次接管。
配置参数
| 参数 | 作用 | 备注 |
|---|---|---|
| circuitBreaker.errorThresholdPercentage | 失败率达到多少百分比后熔断 | 默认值:50, |
| 主要根据依赖重要性进行调整 | ||
| circuitBreaker.forceClosed | 是否强制关闭熔断 | 如果是强依赖,应该设置为true |
| circuitBreaker.requestVolumeThreshold | 熔断触发的最小个数/10s | 默认值:20 |
| circuitBreaker.sleepWindowInMilliseconds | 熔断多少毫秒后去尝试请求 | 默认值:5000 |
| commandKey | 使用自定义命令名称(可以配置文件中针对此名称进行配置) | 默认值:当前执行方法名 |
| coreSize | 线程池coreSize | 默认值:10 |
| execution.isolation.semaphore.maxConcurrentRequests | 信号量最大并发度 | SEMAPHORE模式有效,默认值:10 |
| execution.isolation.strategy | 隔离策略,有THREAD和SEMAPHORE | 默认使用THREAD模式,以下几种可以使用SEMAPHORE模式: |
| 只想控制并发度 | ||
| 外部的方法已经做了线程隔离 | ||
| 调用的是本地方法或者可靠度非常高、耗时特别小的方法(如medis) | ||
| execution.isolation.thread.interruptOnTimeout | 是否打开超时线程中断 | THREAD模式有效 |
| execution.isolation.thread.timeoutInMilliseconds | 超时时间 | 默认值:1000 毫秒 |
| 在THREAD模式下,达到超时时间,可以中断 | ||
| 在SEMAPHORE模式下,会等待执行完成后,再去判断是否超时 | ||
| execution.timeout.enabled | 是否打开超时 | |
| fallback.isolation.semaphore.maxConcurrentRequests | fallback最大并发度 | 默认值:10 |
| groupKey | 表示所属的group,一个group共用线程池 | 默认值:getClass().getSimpleName(); |
| maxQueueSize | 请求等待队列 | 默认值:-1 |
| 如果使用正数,队列将从SynchronizeQueue改为LinkedBlockingQueue | ||
| hystrix.command.default.metrics.rollingStats.timeInMilliseconds | 设置统计的时间窗口值的,毫秒值 | circuit break 的打开会根据1个rolling window的统计来计算。若rolling window被设为10000毫秒,则rolling window会被分成n个buckets,每个bucket包含success,failure,timeout,rejection的次数的统计信息。默认10000 |
| hystrix.command.default.metrics.rollingStats.numBuckets | 设置一个rolling window被划分的数量 | |
| hystrix.command.default.metrics.healthSnapshot.intervalInMilliseconds | 记录health 快照(用来统计成功和错误绿)的间隔 | 默认500ms |
当您使用Hystrix封装每个基础依赖项时,如上图所示的体系结构将更改为类似于下图。每个依赖项都是相互隔离的,受到延迟时发生饱和的资源的限制,并包含回退逻辑,该逻辑决定了在依赖项中发生任何类型的故障时做出什么响应:


ribbon:
ReadTimeout: 30000
ConnectTimeout: 30000
feign:
hystrix:
# feign熔断器开关
enabled: true hystrix:
command:
default:
execution:
isolation:
thread:
#断路器的超时时间ms,默认1000
timeoutInMilliseconds: 30000
circuitBreaker:
#当在配置时间窗口内达到此数量的失败后,进行短路
requestVolumeThreshold: 20
#出错百分比阈值,当达到此阈值后,开始短路。默认50%)
errorThresholdPercentage: 50%
#短路多久以后开始尝试是否恢复,默认5s)-单位ms
sleepWindowInMilliseconds: 500
hystrix.command.default和hystrix.threadpool.default中的default为默认CommandKey Command Properties
Execution相关的属性的配置:
hystrix.command.default.execution.isolation.strategy 隔离策略,默认是Thread, 可选Thread|Semaphore hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds 命令执行超时时间,默认1000ms hystrix.command.default.execution.timeout.enabled 执行是否启用超时,默认启用true
hystrix.command.default.execution.isolation.thread.interruptOnTimeout 发生超时是是否中断,默认true
hystrix.command.default.execution.isolation.semaphore.maxConcurrentRequests 最大并发请求数,默认10,该参数当使用ExecutionIsolationStrategy.SEMAPHORE策略时才有效。如果达到最大并发请求数,请求会被拒绝。理论上选择semaphore size的原则和选择thread size一致,但选用semaphore时每次执行的单元要比较小且执行速度快(ms级别),否则的话应该用thread。
semaphore应该占整个容器(tomcat)的线程池的一小部分。
Fallback相关的属性
这些参数可以应用于Hystrix的THREAD和SEMAPHORE策略 hystrix.command.default.fallback.isolation.semaphore.maxConcurrentRequests 如果并发数达到该设置值,请求会被拒绝和抛出异常并且fallback不会被调用。默认10
hystrix.command.default.fallback.enabled 当执行失败或者请求被拒绝,是否会尝试调用hystrixCommand.getFallback() 。默认true
Circuit Breaker相关的属性
hystrix.command.default.circuitBreaker.enabled 用来跟踪circuit的健康性,如果未达标则让request短路。默认true
hystrix.command.default.circuitBreaker.requestVolumeThreshold 一个rolling window内最小的请求数。如果设为20,那么当一个rolling window的时间内(比如说1个rolling window是10秒)收到19个请求,即使19个请求都失败,也不会触发circuit break。默认20
hystrix.command.default.circuitBreaker.sleepWindowInMilliseconds 触发短路的时间值,当该值设为5000时,则当触发circuit break后的5000毫秒内都会拒绝request,也就是5000毫秒后才会关闭circuit。默认5000
hystrix.command.default.circuitBreaker.errorThresholdPercentage错误比率阀值,如果错误率>=该值,circuit会被打开,并短路所有请求触发fallback。默认50
hystrix.command.default.circuitBreaker.forceOpen 强制打开熔断器,如果打开这个开关,那么拒绝所有request,默认false
hystrix.command.default.circuitBreaker.forceClosed 强制关闭熔断器 如果这个开关打开,circuit将一直关闭且忽略circuitBreaker.errorThresholdPercentage
Metrics相关参数
hystrix.command.default.metrics.rollingStats.timeInMilliseconds 设置统计的时间窗口值的,毫秒值,circuit break 的打开会根据1个rolling window的统计来计算。若rolling window被设为10000毫秒,则rolling window会被分成n个buckets,每个bucket包含success,failure,timeout,rejection的次数的统计信息。默认10000
hystrix.command.default.metrics.rollingStats.numBuckets 设置一个rolling window被划分的数量,若numBuckets=10,rolling window=10000,那么一个bucket的时间即1秒。必须符合rolling window % numberBuckets == 0。默认10
hystrix.command.default.metrics.rollingPercentile.enabled 执行时是否enable指标的计算和跟踪,默认true
hystrix.command.default.metrics.rollingPercentile.timeInMilliseconds 设置rolling percentile window的时间,默认60000
hystrix.command.default.metrics.rollingPercentile.numBuckets 设置rolling percentile window的numberBuckets。逻辑同上。默认6
hystrix.command.default.metrics.rollingPercentile.bucketSize 如果bucket size=100,window=10s,若这10s里有500次执行,只有最后100次执行会被统计到bucket里去。增加该值会增加内存开销以及排序的开销。默认100
hystrix.command.default.metrics.healthSnapshot.intervalInMilliseconds 记录health 快照(用来统计成功和错误绿)的间隔,默认500ms
Request Context 相关参数
hystrix.command.default.requestCache.enabled 默认true,需要重载getCacheKey(),返回null时不缓存
hystrix.command.default.requestLog.enabled 记录日志到HystrixRequestLog,默认true Collapser Properties 相关参数
hystrix.collapser.default.maxRequestsInBatch 单次批处理的最大请求数,达到该数量触发批处理,默认Integer.MAX_VALUE
hystrix.collapser.default.timerDelayInMilliseconds 触发批处理的延迟,也可以为创建批处理的时间+该值,默认10
hystrix.collapser.default.requestCache.enabled 是否对HystrixCollapser.execute() and HystrixCollapser.queue()的cache,默认true ThreadPool 相关参数
线程数默认值10适用于大部分情况(有时可以设置得更小),如果需要设置得更大,那有个基本得公式可以follow:
requests per second at peak when healthy × 99th percentile latency in seconds + some breathing room
每秒最大支撑的请求数 (99%平均响应时间 + 缓存值)
比如:每秒能处理1000个请求,99%的请求响应时间是60ms,那么公式是:
1000 (0.060+0.012) 基本得原则时保持线程池尽可能小,他主要是为了释放压力,防止资源被阻塞。
当一切都是正常的时候,线程池一般仅会有1到2个线程激活来提供服务 hystrix.threadpool.default.coreSize 并发执行的最大线程数,默认10
hystrix.threadpool.default.maxQueueSize BlockingQueue的最大队列数,当设为-1,会使用SynchronousQueue,值为正时使用LinkedBlcokingQueue。该设置只会在初始化时有效,之后不能修改threadpool的queue size,除非reinitialising thread executor。默认-1。
hystrix.threadpool.default.queueSizeRejectionThreshold 即使maxQueueSize没有达到,达到queueSizeRejectionThreshold该值后,请求也会被拒绝。因为maxQueueSize不能被动态修改,这个参数将允许我们动态设置该值。if maxQueueSize == -1,该字段将不起作用
hystrix.threadpool.default.keepAliveTimeMinutes 如果corePoolSize和maxPoolSize设成一样(默认实现)该设置无效。如果通过plugin(https://github.com/Netflix/Hystrix/wiki/Plugins)使用自定义实现,该设置才有用,默认1.
hystrix.threadpool.default.metrics.rollingStats.timeInMilliseconds 线程池统计指标的时间,默认10000
hystrix.threadpool.default.metrics.rollingStats.numBuckets 将rolling window划分为n个buckets,默认10
springcloud优雅停止上下线与熔断的更多相关文章
- SpringBoot系列: 如何优雅停止服务
============================背景============================在系统生命周期中, 免不了要做升级部署, 对于关键服务, 我们应该能做到不停服务完成 ...
- apache2 重启、停止、优雅重启、优雅停止
停止或者重新启动Apache有两种发送信号的方法 第一种方法: 直接使用linux的kill命令向运行中的进程发送信号.你也许你会注意到你的系统里运行着很多httpd进程.但你不应该直接对它们中的任何 ...
- 从零开始实现lmax-Disruptor队列(六)Disruptor 解决伪共享、消费者优雅停止实现原理解析
MyDisruptor V6版本介绍 在v5版本的MyDisruptor实现DSL风格的API后.按照计划,v6版本的MyDisruptor作为最后一个版本,需要对MyDisruptor进行最终的一些 ...
- 基于Nginx dyups模块的站点动态上下线并实现简单服务治理
简介 今天主要讨论一下,对于分布式服务,站点如何平滑的上下线问题. 分布式服务 在分布式服务下,我们会用nginx做负载均衡, 业务站点访问某服务站点的时候, 统一走nginx, 然后nginx根据一 ...
- 学习笔记:Zookeeper 应用案例(上下线动态感知)
1.Zookeeper 应用案例(上下线动态感知) 8.1 案例1--服务器上下线动态感知 8.1.1 需求描述 某分布式系统中,主节点可以有多台,可以动态上下线 任意一台客户端都能实时感知到主节点服 ...
- SSM项目使用GoEasy 获取客户端上下线实时状态变化及在线客户列表
一.背景 上篇SSM项目使用GoEasy 实现web消息推送服务是GoEasy的一个用途,今天我们来看GoEasy的第二个用途:订阅客户端上下线实时状态变化.获取当前在线客户数量和在线客户列表.截止我 ...
- SpringCloud 在Feign上使用Hystrix(断路由)
SpringCloud 在Feign上使用Hystrix(断路由) 第一步:由于Feign的起步依赖中已经引入了Hystrix的依赖,所以只需要开启Hystrix的功能,在properties文件中 ...
- 【zookeeper】4、利用zookeeper,借助观察模式,判断服务器的上下线
首先什么是观察者模式,可以看看我之前的设计模式的文章 https://www.cnblogs.com/cutter-point/p/5249780.html 确定一下,要有观察者,要有被观察者,然后要 ...
- Spring Cloud Feign 在调用接口类上,配置熔断 fallback后,输出异常
Spring Cloud Feign 在调用接口类上,配置熔断 fallback后,出现请求异常时,会进入熔断处理,但是不会抛出异常信息. 经过以下配置,可以抛出异常: 将原有ErrorEncoder ...
随机推荐
- Linux档案权限篇(一)
查看档案的属性"ls-al". 即列出所有的档案的详细权限与属性(包括隐藏文件) 权限 第一个字符代表档案的类型: d:代表是目录 -:代表是文件 l:代表是连接文件(相当于win ...
- win10家庭版 不能远程登录 windows 10 mstsc不可用
Windows10家庭版的用户,因为系统中没有组策略编辑器,需要修改注册表来实现. 注册表路径:HKLM\Software\Microsoft\Windows\CurrentVersion\Polic ...
- Linux python 虚拟环境管理
直接复制的内容: 原著:https://www.cnblogs.com/q767498226/p/11099884.html 报错解决:https://blog.csdn.net/weixin_467 ...
- Qt中的ui文件转换为py文件
将pyuic5 -o demo.py demo.ui写入ui-py.bat文件(自定义文件),将ui文件与ui-py.bat文件放在同一文件夹,双击.bat文件即可生成.py文件
- 定要过python二级 选择题第5套
1. 2.. 3. https://zhidao.baidu.com/question/1952133724016713828.html 4. 5. 6. 7. 8. 9. 10. 11.
- 鸿蒙内核源码分析(编译过程篇) | 简单案例窥视GCC编译全过程 | 百篇博客分析OpenHarmony源码| v57.01
百篇博客系列篇.本篇为: v57.xx 鸿蒙内核源码分析(编译过程篇) | 简单案例窥视编译全过程 | 51.c.h.o 编译构建相关篇为: v50.xx 鸿蒙内核源码分析(编译环境篇) | 编译鸿蒙 ...
- 鸿蒙内核源码分析(编译环境篇) | 编译鸿蒙看这篇或许真的够了 | 百篇博客分析OpenHarmony源码 | v50.06
百篇博客系列篇.本篇为: v50.xx 鸿蒙内核源码分析(编译环境篇) | 编译鸿蒙防掉坑指南 | 51.c.h.o 编译构建相关篇为: v50.xx 鸿蒙内核源码分析(编译环境篇) | 编译鸿蒙防掉 ...
- P4643-[国家集训队]阿狸和桃子的游戏【结论】
正题 题目链接:https://www.luogu.com.cn/problem/P4643 题目大意 给出\(n\)个点\(m\)条边的无向图,两个人轮流选择一个未被选择的点加入点集. 然后每个人的 ...
- Jenkins持续集成与部署
一.Jenkins简介 在阅读此文章之前,你需要对Linux.Docker.Git有一定的了解和使用,如果还未学习,请阅读我前面发布的相关文章进行学习. 1.概念了解:CI/CD模型 CI全名Cont ...
- 实验2:Open vSwitch虚拟交换机实践
作业链接:实验2:Open vSwitch虚拟交换机实践 一.实验目的 能够对Open vSwitch进行基本操作: 能够通过命令行终端使用OVS命令操作Open vSwitch交换机,管理流表: 能 ...