论文解读SDCN《Structural Deep Clustering Network》
前言
- 考虑自身信息采用 基础的 Autoencoder ,考虑结构信息采用 GCN。
1.介绍
在现实中,将结构信息集成到深度聚类中通常需要解决以下两个问题。
1、在深度聚类中应该考虑哪些结构性信息?
- 结构信息表明了数据样本之间潜在的相似性。不仅需要考虑低阶信息还需要考虑高阶信息。
2、结构信息与深度聚类之间的关系是什么?
- 深度聚类的基本组成部分是深度神经网络(DNN),例如 Autoencoder。Autoencoder 由多层结构组成,每一层都会捕获不同的潜在信息。在数据之间也有各种类型的结构信息。如何优雅地将数据的结构与自动编码器的结构结合起来则是另一个问题。
为获取结构信息,首先构造一个 KNN 图,它能够揭示数据的底层结构。为从 KNN 图中获取低阶和高阶的结构信息,提出了一个由多个图卷积层组成的 GCN 模块来学习 GCN 特定的表示。为了将结构信息引入到深度聚类中,引入了一个 AutoEncoder 模块来从原始数据中学习 AutoEncoder 特定的表示,并提出了一个 delivery operator 来将其与 GCN 特定的表示相结合。我们从理论上证明了 delivery operator 能够更好地辅助自动编码器与 GCN 之间的集成。特别地,我们证明了 GCN 为由 Autoencoder 学习的表示提供了一个近似的二阶图正则化,并且由自编码器学习的表示可以缓解GCN中的过平滑问题。
最后,由于自动编码器和GCN模块都将输出表示,我们提出了一个双自监督模块来统一引导这两个模块。通过双自监督模块,可以对整个模型进行端到端聚类任务训练。
综上所述,本文主要贡献如下:
- 提出了一种新的结构深度聚类网络(SDCN)来进行深度聚类。所提出的SDCN有效地结合了自编码器和GCN的优势与一个新的传递操作符和一个双自监督模块。据我们所知,这是第一次将结构性信息明确地应用到深度聚类中。
- 对 SDCN 进行了理论分析,并证明了 GCN 为 DNN 表示提供了一个近似的二阶图正则化,并且在 SDCN 中学习到的数据表示相当于具有不同阶结构信息的表示的和。通过我们的理论分析,可以有效地缓解 SDCN 中 GCN 模块的过平滑问题。
- 在6个真实数据集上的大量实验表明,SDCN 与先进技术相比的优越性。具体来说,SDCN 与最佳基线方法相比取得了显著的改进(NMI17%,ARI28%)。
2.网络架构
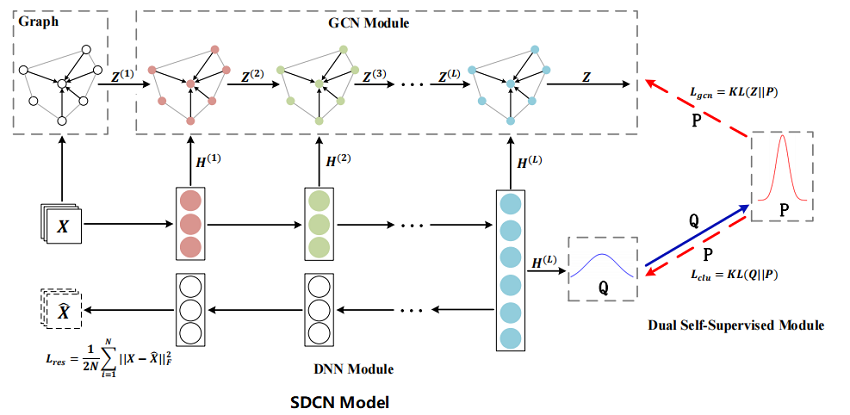
The blue solid line represents that target distribution P is calculated by the distribution Q and the two red dotted lines represent the dual self-supervised mechanism. The target distribution P to guide the update of the DNN module and the GCN module at the same time.
3.模型详解
在本节中,将介绍 SDCN,其整体框架如 Figure 1 所示。首先基于原始数据构建一个KNN图。然后,将原始数据和 KNN 图分别输入到自动编码器和GCN中。并将每一层的自动编码器与相应的 GCN 层连接起来,这样就可以通过 delivery operator 将自动编码器特定的表示集成到 GCN 的表示中。同时,我们提出了一种双重自监督机制来监督自动编码器和 GCN 的训练进程。本文将在下面详细描述我们提出的模型。
3.1 KNN Graph
假设我们有原始数据 $\mathrm{X} \in \mathbb{R}^{N \times d} $,其中每一行 $\mathbf{x}_{i}$ 代表 $i-th$ 样本,$N$ 是样本数,$d$ 是维度。 对于每个样本,我们首先找到它的 $top-K$ 相似邻居并设置边以将其与其邻居连接。 有很多方法可以计算样本的相似度矩阵 $S \in \mathbb{R}^{N} \times N$。
这里列出在构建 KNN 图时使用的两种相似度计算的流行方法:
- Heat Kernel. 样本 $i$ 和 $j$ 之间的相似度计算如下:
$ \mathrm{S}_{i j}=e^{-\frac{\left\|\mathrm{x}_{i}-\mathrm{x}_{j}\right\|^{2}}{t}}\quad \quad(1)$
其中, $t$ 为热传导方程中的时间参数。对于连续的数据,如:图像。
- Dot-product. 样本 $i$ 和样本 $j$ 之间的相似性的计算方法为:
$\mathrm{S}_{i j}=\mathbf{x}_{j}^{T} \mathbf{x}_{i} \quad \quad (2)$
对于离散数据,如: bag-of-words,使用点积相似性,使相似性只与相同 word 的数量相关。
在计算相似度矩阵 $S$ 后,选择每个样本的前 $k$ 个相似度点作为其邻居,构造一个无向的 $k$ 近邻图,从非图数据中得到邻接矩阵 $A$。
tips:代码中 $k =10$,但是仔细看生成的邻接矩阵可以发现部分点甚至出现了11个最近临。
3.2 DNN模块
在本文中,使用基本的自动编码器来学习原始数据的表示,以适应不同类型的数据特征。假设在自动编码器中存在 $L$ 个层,并且 $ℓ$ 表示层数。
在 Encoder 部分 $H(ℓ)$ 中,第 $ℓ$ 层学习到的表示如下:
$\mathbf{H}^{(\ell)}=\phi\left(\mathbf{W}_{e}^{(\ell)} \mathbf{H}^{(\ell-1)}+\mathbf{b}_{e}^{(\ell)}\right)$
其中 $\phi$ 是激活函数,本文取 $Relu$。 $\mathbf{W}_{e}^{(\ell)}$ 和 $\mathbf {b}_{e}^{(\ell)}$ 分别是 Encoder 中 $\ell$ 层的权重矩阵和偏差。 此外,我们将 $\mathbf{H}^{(0)}$ 表示为 raw data : $\mathbf{X}$ 。
Encoder 部分后面是 Decoder 部分:
$\mathbf{H}^{(\ell)}=\phi\left(\mathbf{W}_{d}^{(\ell)} \mathbf{H}^{(\ell-1)}+\mathbf{b}_{d}^{(\ell)}\right) \quad \quad (4)$
其中 $\mathbf{W}_{d}^{(\ell)}$ 和 $\mathbf{b}_{d}^{(\ell)}$ 是分别位于解码器第 $\ell$ 层的权重矩阵和偏差 。
解码器部分的输出是对原始数据 $\hat{\mathbf{X}}=\mathbf{H}^{(L)}$ 的重构,从而得到以下目标函数:
$\mathcal{L}_{r e s}=\frac{1}{2 N} \sum \limits _{i=1}^{N}\left\|\mathbf{x}_{i}-\hat{\mathbf{x}}_{i}\right\|_{2}^{2}=\frac{1}{2 N}\|\mathbf{X}-\hat{\mathbf{X}}\|_{F}^{2}\quad \quad (5)$
3.3 GCN Module
自编码器能够从数据本身中学习有用的表示,例如 $\mathrm{H}^{(1)}$ , $\mathrm{H}^{(2)}$ , $\cdots$ , $\mathrm{H}^{(L)}$ ,但忽略了样本之间的关系。 在本节中,将介绍如何使用 GCN 模块来传播 DNN 模块生成的这些表示。 一旦将 DNN 模块学习到的所有表示都集成到 GCN 中,那么 GCN 可学习表示将能够适应两种不同类型的信息,即数据本身和数据之间的关系。
$\mathrm{GCN}$ 的 $\ell$ 层,权重矩阵 $\mathbf{W}$ ,学习到的表示$\mathrm{Z}^{(\ell)}$ 可以通过以下卷积运算得到:
$\mathrm{Z}^{(\ell)}=\phi\left(\widetilde{\mathrm{D}}^{-\frac{1}{2}} \widetilde{\mathrm{A}} \widetilde{\mathrm{D}}^{-\frac{1}{2}} \mathbf{Z}^{(\ell-1)} \mathbf{W}^{(\ell-1)}\right) \quad \quad (6)$
其中 $\widetilde{\mathbf{A}}=\mathbf{A}+\mathbf{I}$ 和 $\widetilde{\mathbf{D}}_{ii}=\sum_{j} \widetilde{\mathbf {A}}_{\mathbf{ij}}$ , $\mathbf{I}$ 是每个节点中自循环的相邻矩阵 $A$ 的单位对角矩阵。 从方程 (6) 可以看出,表示 $Z^{(\ell-1)}$ 将通过归一化邻接矩阵 $\widetilde{\mathbf{D}}^{-\frac{1}{2}} \widetilde{\mathbf {A}} \widetilde{\mathbf{D}}^{-\frac{1}{2}}$ 以获得新的表示 $Z^{(\ell)}$ 。
考虑到自编码器 $\mathbf{H}^{(\ell-1)}$ 学习到的表示能够重构数据本身并包含不同的有价值信息,我们将这两种表示结合起来 $\mathbf{Z}^{( \ell-1)}$ 和 $\mathbf{H}^{(\ell-1)}$ 一起得到更完整和强大的表示如下:
$\widetilde{\mathbf{Z}}^{(\ell-1)}=(1-\epsilon) \mathbf{Z}^{(\ell-1)}+\epsilon \mathbf{H}^{(\ell-1)} \quad \quad (7)$
其中 $ϵ$ 是一个平衡系数,在这里我们统一地将其设为 $0.5$ 。这样,我们一层地将自动编码器和 GCN 连接起来。
然后使用 $\widetilde{\mathbf{Z}}^{(\ell-1)}$ 作为 $\mathrm{GCN}$ 中 $l $ 层的输入来生成表示 $Z^{ (\ell)} $:
$\mathbf{Z}^{(\ell)}=\phi\left(\widetilde{\mathbf{D}}^{-\frac{1}{2}} \widetilde{\mathbf{A}} \widetilde{\mathbf{D}}^{-\frac{1}{2}} \widetilde{\mathbf{Z}}^{(\ell-1)} \mathbf{W}^{(\ell-1)}\right) \quad \quad (8)$
由于每个 DNN 层学习的表示不同,为了尽可能多地保留信息,我们将从每个 DNN 层学习到的表示转移到相应的 GCN 层进行信息传播,如图 1 所示。delivery operator 在整个模型中工作 $L$ 次。 我们将在 3.5 节中从理论上分析这种 delivery operator 的优势。
注意,第一层GCN的输入是原始数据 $X$:
$\mathrm{Z}^{(1)}=\phi\left(\widetilde{\mathbf{D}}^{-\frac{1}{2}} \widetilde{\mathrm{A}} \widetilde{\mathbf{D}}^{-\frac{1}{2}} \mathbf{X} \mathbf{W}^{(1)}\right) \quad \quad (9)$
GCN模块的最后一层是具有 softmax 功能的多分类层:
$Z=\operatorname{softmax}\left(\widetilde{\mathbf{D}}^{-\frac{1}{2}} \widetilde{\mathbf{A}} \widetilde{\mathbf{D}}^{-\frac{1}{2}} \mathbf{Z}^{(L)} \mathbf{W}^{(L)}\right) \quad \quad (10)$
结果 $z_{i j} \in Z$ 表示概率样本 $i$ 属于聚类中心 $j$ ,我们可以将 $Z$ 视为概率分布。
3.4 双自监督模块
现已在神经网络架构中将自动编码器与 GCN 连接起来。然而,它们并不是为 deep clustering 而设计的。自动编码器主要用于数据表示学习,这是一种无监督的学习场景,而传统的 GCN 是在半监督的学习场景中。它们两者都不能直接应用于聚类问题。
在此,我们提出了一个双自监督模块,它将自编码器和 GCN 模块统一在一个统一的框架内,有效地对这两个模块进行端到端训练以进行聚类。
对于第 $i$ 个样本和第 $j$ 个簇,我们使用 Student’s t-distribution 来度量数据表示 $h_i$ 和簇中心向量 $µ_j$ 之间的相似性:
${\large q_{i j}=\frac{\left(1+\left\|\mathbf{h}_{i}-\boldsymbol{\mu}_{j}\right\|^{2} / v\right)^{-\frac{v+1}{2}}}{\sum_{j^{\prime}}\left(1+\left\|\mathbf{h}_{i}-\boldsymbol{\mu}_{j^{\prime}}\right\|^{2} / v\right)^{-\frac{v+1}{2}}}} \quad \quad (11)$
其中 $\mathbf{h}_{i}$ 是 $\mathbf{H}^{(L)}$ 的第 $i$ 行, $\boldsymbol{\mu}_{j}$ 初始化为 $K -means$ 在预训练自动编码器学习的表征上,$v$ 是 Student’s t-distribution 的自由度。 $q_{i j}$ 可以认为是将样本 $i$ 分配给集群 $j$ 的概率,即软分配。 我们将 $Q=\left[q_{i j}\right]$ 视为所有样本的分配分布,并让 $v=1$ 用于所有实验。
在获得聚类结果分布 $Q$ 后,我们的目标是通过从高置信度分配中学习来优化数据表示。具体来说,我们希望使数据表示更接近集群中心,从而提高集群的凝聚力。因此,我们计算一个目标分布 $P$ 如下:
${\large p_{i j}=\frac{q_{i j}^{2} / f_{j}}{\sum_{j^{\prime}} q_{i j^{\prime}}^{2} / f_{j^{\prime}}}} \quad \quad (12)$
其中 $f_{j}=\sum_{i} q_{i j}$ 是软聚类频率。在目标分布 $P$ 中,对 $Q$ 中的每个分配进行平方和归一化,以便分配具有更高的置信度,采用 KL 散度来比较两类概率:
$\mathcal{L}_{c l u}=K L(P \| Q)=\sum \limits _{i} \sum\limits _{j} p_{i j} \log \frac{p_{i j}}{q_{i j}} \quad \quad (13)$
通过最小化 $Q$ 和 $P$ 分布之间的 $KL$ 散度损失。
目标分布 $P$ 可以帮助DNN模块学习更好的聚类任务表示,即使数据表示更接近聚类中心。这被认为是一个自监督机制,因为目标分布 $P$ 是由分布 $Q$ 计算出来的,而 $P$ 分布依次监督分布 $Q$ 的更新。
另一个自监督模块在:对于 GCN 模块的训练,GCN 模块也会出现提供一个聚类分配分布 $Z$ 。因此,可以使用分配 $P$ 来监督分配 $Z$ 如下:
$\mathcal{L}_{g c n}=K L(P \| Z)=\sum \limits_{i} \sum \limits _{j} p_{i j} \log \frac{p_{i j}}{z_{i j}}\quad \quad (14)$
该目标函数有两个优点:
- 与传统多分类损失函数相比,KL 散度以更 “gentle” 的方式更新整个模型,以防止数据表示受到严重干扰;
- GCN 和 DNN 模块统一在同一优化目标中,使其结果在训练过程中趋于一致。由于 DNN 模块和 GCN 模块的目标是近似目标分布P,这两个模块之间有很强的联系,我们称之为双重自监督机制。
通过这种机制,SDCN可以直接将聚类目标和分类目标这两个不同的目标集中在一个损失函数中。因此,我们提出的SDCN的总体损失函数是:
$\mathcal{L}=\mathcal{L}_{\text {res }}+\alpha \mathcal{L}_{\text {clu }}+\beta \mathcal{L}_{g c n}\quad \quad (15)$
其中,$α>0$(实验取0.1) 是平衡原始数据的聚类优化和局部结构保存的超参数,$β>0$ (实验取0.01) 是控制GCN模块对嵌入空间的干扰的系数。
训练直到最大时期,SDCN 将得到一个稳定的结果。然后就可为样本设置标签。我们选择分布 $Z$ 中的软分配作为最终的聚类结果。因为 GCN 学习到的表示包含了两种不同类型的信息。分配给样本 $i$ 的标签是:
$r_{i}=\underset{j}{arg\ max} \ z_{i j}\quad \quad (16)$
其中 $z_{ij}$ 是用方程 (10) 计算出来的。
算法流程:

3.5 Theory Analysis
在本节中,我们将分析 SDCN 如何将结构信息引入自动编码器。在此之前,我们给出了 Graph regularization 和 Second-order graph regularization 的定义。
Definition 1. Graph regularization [2]. Given a weighted graph $G$, the objective of graph regularization is to minimize the following equation:
$\sum \limits _{i j} \frac{1}{2}\left\|\mathbf{h}_{i}-\mathbf{h}_{j}\right\|_{2}^{2} w_{i j}$
Definition 2. Second-order similarity. We assume that $\mathrm{A}$ is the adjacency matrix of graph $\mathcal{G}$ and $\mathrm{a}_{i}$ is the $i -th$ column of $A$. The second-order similarity between node $i$ and node $j$ is
$s_{i j}=\frac{\mathbf{a}_{i}^{T} \mathbf{a}_{j}}{\left\|\mathbf{a}_{i}\right\|\left\|\mathbf{a}_{j}\right\|}=\frac{\mathbf{a}_{i}^{T} \mathbf{a}_{j}}{\sqrt{d_{i}} \sqrt{d_{j}}}=\frac{C}{\sqrt{d_{i}} \sqrt{d_{j}}}$
其中 $C$ 为节点 $i$ 和节点 $j$ 之间的共同邻居的个数,$d_i$ 为节点 $i$ 的度。
其中 $s_{ij}$ 是二阶相似度。
与 Definition 1 相比,Definition 3 施加了一个高阶约束,即如果两个节点有许多共同的邻居,它们的表示也应该更相似。
4 实验
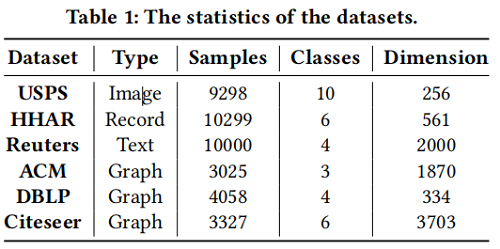
4.1 Datasets
4.2 Baselines
Methods
- K-means : A classical clustering method based on the raw data.
- AE : It is a two-stage deep clustering algorithm which performs K-means on the representations learned by autoencoder.
- DEC : It is a deep clustering method which designs a clustering objective to guide the learning of the data representations.
- IDEC : This method adds a reconstruction loss to DEC, so as to learn better representation.
- GAE & VGAE: It is an unsupervised graph embedding method using GCN to learn data representations.
- DAEGC: It uses an attention network to learn the node representations and employs a clustering loss to supervise the process of graph clustering.
- $SDCN_{Q}$ : The variant of SDCN with distribution Q.
- $SDCN$: The proposed method.
Metrics
- Accuracy(ACC)
- Normalized Mutual Information (NMI)
- Average Rand Index (ARI)
- macro F1-score (F1)
Parameter Setting.
if you want to know more ,please see the Code.
4.3对聚类结果的分析
Table 2 shows the clustering results on six datasets.
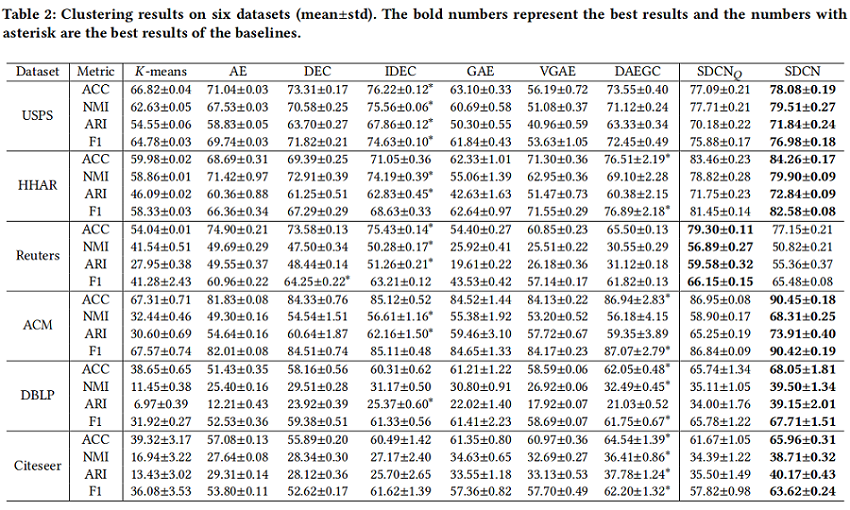
- For each metric, SDCN and $SDCN_Q$ achieves a signicant improvement of 6% on ACC, 17% on NMI and 28% on ARI averagely.
- SDCN generally achieves better cluster results than $SDCN_Q$ .because SDCN uses the representations containing the structural information learned by GCN, while $SDCN_Q$ mainly uses the representations learned by the autoencoder. However, in Reuters, the result of $SDCN_Q$ is much better than SDCN. Because in the KNN graph of Reuters, many different classes of nodes are connected together, which contains much wrong structural information.
- Clustering results of autoencoder based methods (AE, DEC, IDEC) are generally better than those of GCN-based methods (GAE, VAGE, DAEGC) on the data with KNN graph, while GCN-based methods usually perform better on the data with graph structure.
- Comparing the results of AE with DEC and the results of GAE with DAEGC, we can nd that the clustering loss function, dened in Eq. 13, plays an important role in improving the deep clustering performance. Because IDEC and DAEGC can be seen as the combination of the clustering loss with AE and GAE, respectively.
4.4 Analysis of Variants
我们将我们的模型与两种变体进行了比较,以验证GCN在学习结构信息方面的能力和 delivery operator 的生态能力。特别地,我们研究以下变体:
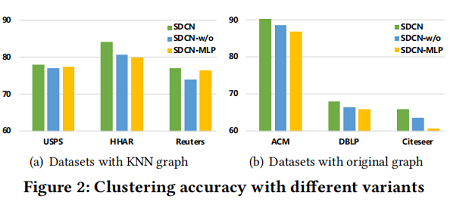
- SDCN-w/o: This variant is SDCN without delivery operator, which is used to validate the effectiveness of our proposed delivery operator.
- SDCN-MLP: This variant is SDCN replacing the GCN module with the same number of layers of multilayer perceptron (MLP), which is used to validate the advantages of GCN in learning structural information.
From Figure 2, we have the following observations:
- In Figure 2(a), 我们可以证明,SDCN-MLP的聚类精度在 Reuters 上优于 SDCN-w/o,并且在USPS和HHAR中也取得了类似的结果。这说明在KNN图中,如果没有 delivery operator ,GCN学习结构信息的能力受到严重限制。其原因是多层GCN会产生严重的 over-smoothing 问题,导致聚类结果的减少。另一方面,SDCN比SDCN-MLP要好。这证明了 delivery operator 可以帮助GCN缓解 over-smoothing 问题,并学习更好的数据表示。
- In Figure 2(b), 在三个包含原始图的数据集中,SDCN-w/o的聚类精度都优于SDCN-MLP。这说明GCN具有利用结构信息学习数据表示的强大能力。此外,SDCN在三个数据集中的性能都优于SDCN-w/o。这证明了在SDCN-w/o中仍然存在过平滑问题,但良好的图结构仍然使SDCN-w/o取得了不错的聚类结果。
- 比较 Figure 2(a) 和 Figure 2(b) 中的结果。与SDCN-w/o和SDCN-MLP的数据集相比,SDCN无论使用哪种类型的数据集,我们都可以取得了最好的性能。这证明了 delivery operator 和GCN在提高集群质量方面都发挥着重要的作用。
4.5 Analysis of Different Propagation Layers
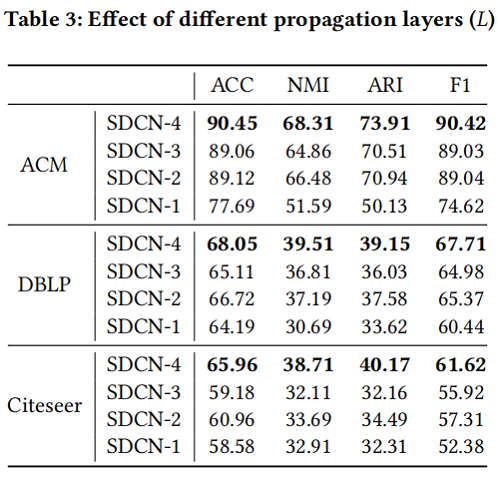
我们选择具有原始图的数据集来验证聚类上传播层数的数量,因为它们具有自然结构信息。
分析如下:
- 增加SDCN的深度可以大大提高聚类性能。这是由于自动编码器中每一层学习到的表示都是不同的,为了尽可能多地保留信息,我们需要将从自动编码器学习到的所有表示放到相应的GCN层中。
- 有一个有趣的现象是,SDCN-3在所有数据集中的性能都不如SDCN-2好。
4.6 Analysis of balance coeffcient ϵ
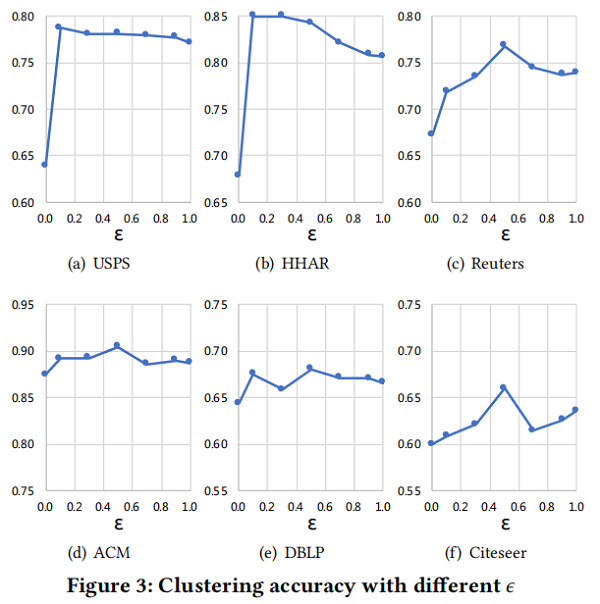
$ϵ=0.0$ 表示GCN模块中的表示不包含来自自动编码器的表示,而 $ϵ=1.0$ 表示GCN只使用DNN学习到的表示 $H^{(L)}$。
- 使用参数 $ϵ=0.5$ 在四个数据集( Reuters、ACM、DBLP、Citeseer)上的聚类精度达到最佳性能。
- 在所有数据集中,使用参数 $ϵ=0.0$的聚类精度表现最差。(over-smoothing)
- 另一个有趣的观察结果是,参数为 $ϵ=1.0$ 的SDCN仍然具有更高的聚类精度。
4.7 K-sensitivity Analysis
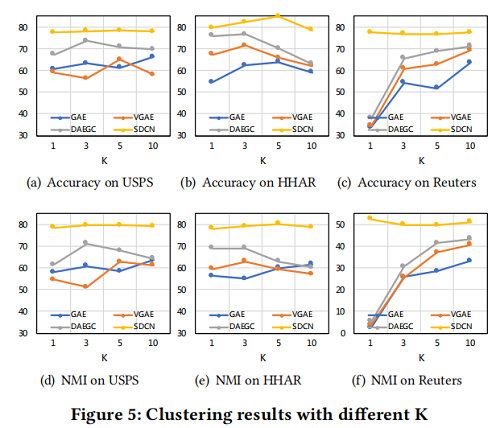
- From Figure 5, we can find that with $K={1, 3, 5, 10}$, our proposed SDCN is much better than GAE, VGAE and DAEGC.
- these four methods can achieve good performance when K = 3 or K = 5, but in the case of K = 1 and K = 10, the performance will drop signicantly.
4.8 Analysis of Training Process
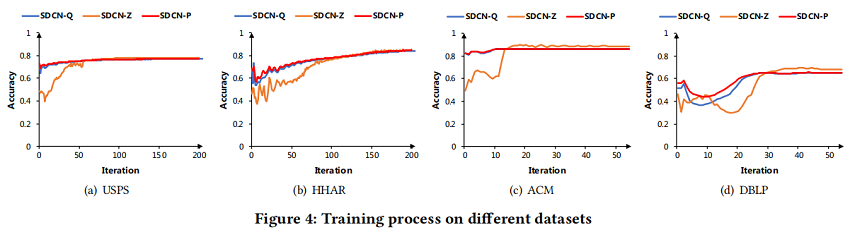
- In Figure 4, the red line SDCN-P, the blue line SDCN-Q and the orange line SDCN-Z represent the accuracy of the target distribution P, distribution Q and distribution Z, respectively.
- 在大多数情况下,SDCN-P 的精度都高于 SDCN-Q,这说明目标分布P能够指导整个模型的更新。
- 从一开始,三种分布的精度结果均在不同的范围内下降。因为由自动编码器和GCN学习到的信息是不同的。
- 然后,SDCN-Q和SDCN-Z的精度快速提高到一个高水平,因为目标分布SDCN-P缓解了两个模块之间的冲突,使它们的结果趋于一致。
5 结论
在本文中,我们首次尝试将结构信息集成到深度聚类中。我们提出了一种新的结构性深度聚类网络,由DNN模块、GCN模块和双自监督模块组成。我们的模型能够有效地将自 autoencoder-spectic representation 与 GCN-spectic representation 结合起来。通过理论分析,证明了交付操作员的强度。我们表明,我们提出的模型在各种开放数据集中始终优于最先进的深度聚类方法。
论文解读SDCN《Structural Deep Clustering Network》的更多相关文章
- [论文阅读笔记] Structural Deep Network Embedding
[论文阅读笔记] Structural Deep Network Embedding 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问题 现有的表示学习方法大多采用浅层模型,这可能不能 ...
- 论文解读《Bilinear Graph Neural Network with Neighbor Interactions》
论文信息 论文标题:Bilinear Graph Neural Network with Neighbor Interactions论文作者:Hongmin Zhu, Fuli Feng, Xiang ...
- 论文解读《Learning Deep CNN Denoiser Prior for Image Restoration》
CVPR2017的一篇论文 Learning Deep CNN Denoiser Prior for Image Restoration: 一般的,image restoration(IR)任务旨在从 ...
- 论文解读(DFCN)《Deep Fusion Clustering Network》
Paper information Titile:Deep Fusion Clustering Network Authors:Wenxuan Tu, Sihang Zhou, Xinwang Liu ...
- 基于图嵌入的高斯混合变分自编码器的深度聚类(Deep Clustering by Gaussian Mixture Variational Autoencoders with Graph Embedding, DGG)
基于图嵌入的高斯混合变分自编码器的深度聚类 Deep Clustering by Gaussian Mixture Variational Autoencoders with Graph Embedd ...
- 论文解读(SDNE)《Structural Deep Network Embedding》
论文题目:<Structural Deep Network Embedding>发表时间: KDD 2016 论文作者: Aditya Grover;Aditya Grover; Ju ...
- 论文解读(DCN)《Towards K-means-friendly Spaces: Simultaneous Deep Learning and Clustering》
论文信息 论文标题:Towards K-means-friendly Spaces: Simultaneous Deep Learning and Clustering论文作者:Bo Yang, Xi ...
- 论文解读(IDEC)《Improved Deep Embedded Clustering with Local Structure Preservation》
Paper Information Title:<Improved Deep Embedded Clustering with Local Structure Preservation>A ...
- Deep Unfolding Network for Image Super-Resolution 论文解读
Introduction 超分是一个在 low level CV 领域中经典的病态问题,比如增强图像视觉质量.改善其他 high level 视觉任务的表现.Zhang Kai 老师这篇文章在我看到的 ...
随机推荐
- CF1156F Card Bag
题目传送门. 题意简述:有 \(n\) 张卡牌,每张卡牌有数字 \(a_1,a_2,\cdots,a_n\).现在随机抽取卡牌,不放回,设本次抽到的卡牌为 \(x\),上次抽到的卡牌为 \(y\),若 ...
- zabbix监控php状态
环境介绍: php /usr/loca/php nignx /usr/loca/nginx 配置文件都是放在extra中 修改php-fpm的配置文件启动状态页面 pm.status_path = ...
- 49-Reverse Linked List II
Reverse Linked List II My Submissions QuestionEditorial Solution Total Accepted: 70579 Total Submiss ...
- Go语言缺陷
我为什么放弃Go语言 目录(?)[+] 我为什么放弃Go语言 有好几次,当我想起来的时候,总是会问自己:我为什么要放弃Go语言?这个决定是正确的吗?是明智和理性的吗?其实我一直在认真思考这个问题. 开 ...
- c#图标、显示图表、图形、json echarts实例 数据封装【c#】
page: <%@ Control Language="C#" AutoEventWireup="true" CodeFile="Viewxxx ...
- 学习java 7.13
学习内容: 一个汉字存储:如果是GBK编码,占用2个字节:如果是UTF-8编码,占用3个字节 汉字在存储的时候,无论选择哪种编码存储,第一个字节都是负数 字符流=字节流+编码表 采用何种规则编码,就要 ...
- Java实现读取文件
目录 Java实现读取文件 1.按字节读取文件内容 使用场景 2.按字符读取文件内容 使用场景 3.按行读取文件内容 使用场景 4.随机读取文件内容 使用场景 Java实现读取文件 1.按字节读取文件 ...
- [php代码审计] Typecho 1.1 -反序列化Cookie数据进行前台Getshell
环境搭建 源码下载:https://github.com/typecho/typecho/archive/v1.1-15.5.12-beta.zip 下载后部署到web根目录,然后进行安装即可,其中注 ...
- MBean代码例子
public class ServerImpl { public final long startTime; public ServerImpl() { startTime = System.curr ...
- 关于ssh-keygen 生成的key以“BEGIN OPENSSH PRIVATE KEY”开头
现在使用命令 ssh-keygen -t rsa 生成ssh,默认是以新的格式生成,id_rsa的第一行变成了"BEGIN OPENSSH PRIVATE KEY" 而不在是&q ...