[平台建设] Spark任务的诊断调优
背景
平台目前大多数任务都是Spark任务,用户在提交Spark作业的时候都要进行的一步动作就是配置spark executor 个数、每个executor 的core 个数以及 executor 的内存大小等,这项配置目前基本靠用户个人经验,在这个过程中,有的用户就会设置非常不合理,比如配置的内存非常大,实际上任务运行时所占用的内存极少. 基于此,希望能有工具来针对任务进行分析,帮助用户来监控和调优任务,并给出一些建议,使任务更加有效率,同时减少乱配资源影响其他用户任务运行的情况。
Dr. Elephant介绍
通过调研,发现一个开源项目 Dr. Elephant 基本与想要达成目标一致。
DR.Elephant 介绍:
Dr. Elephant is a job and flow-level performance monitoring and tuning tool for Apache Hadoop and Apache Spark
Dr功能介绍:
https://github.com/linkedin/dr-elephant/wiki/User-Guide
接下来就是需要了解下Dr的架构, 因为我们有些定制化的需求,所以需要了解下架构,以及阅读源码进行相关改造适配。
Dr. Elephant 的系统架构如下图。主要包括三个部分:
数据采集:数据源为 Job History
诊断和建议:内置诊断系统
存储和展示:MySQL 和 WebUI
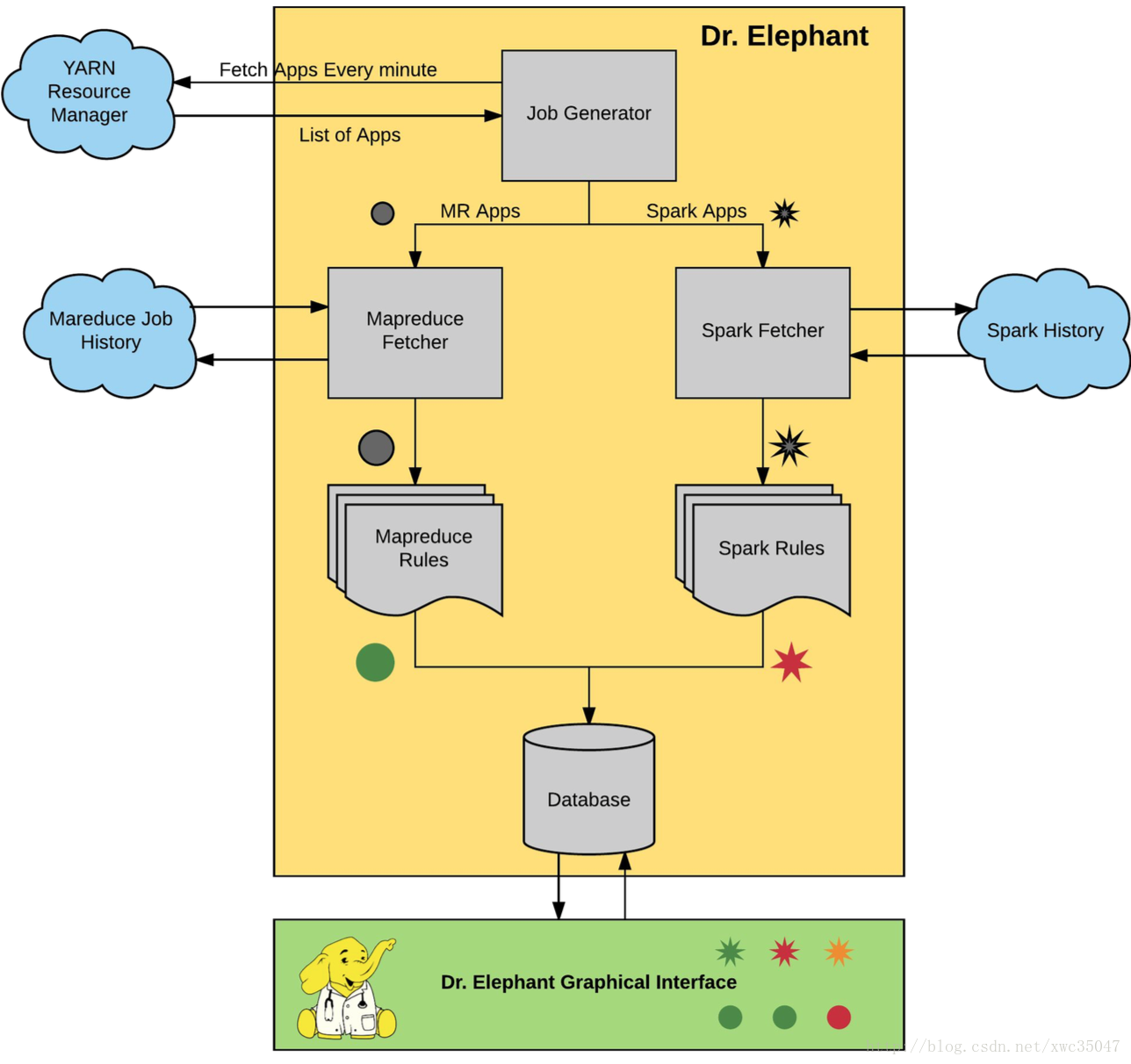
Dr.Elephant定期从Hadoop平台的YARN资源管理中心获取近期所有的任务,这些任务既包含成功的任务,也包含那些失败的任务。每个任务的元数据,例如任务计数器、配置信息以及运行信息都可以从Hadoop平台的历史任务服务端获取到。一旦获取到了任务的元数据,Dr.Elephant就基于这些元数据运行启发式算法,然后会产生一份该启发式算法对该任务性能的诊断报告。根据每个任务的执行情况,这份报告会为该任务标记一个待优化的严重性级别。严重性级别一共分为五级,报告会对该任务产生一个级别的定位,并通过级别来表明该任务中存在的性能问题的严重程度。
启发式算法具体要做的事情就是:
- 获取数据
- 量化计算打分
- 将分值与不同诊断等级阈值进行比较
- 给出诊断等级
源码解析与改造
首先我们要知道Dr整体的运行流程是怎么样的?
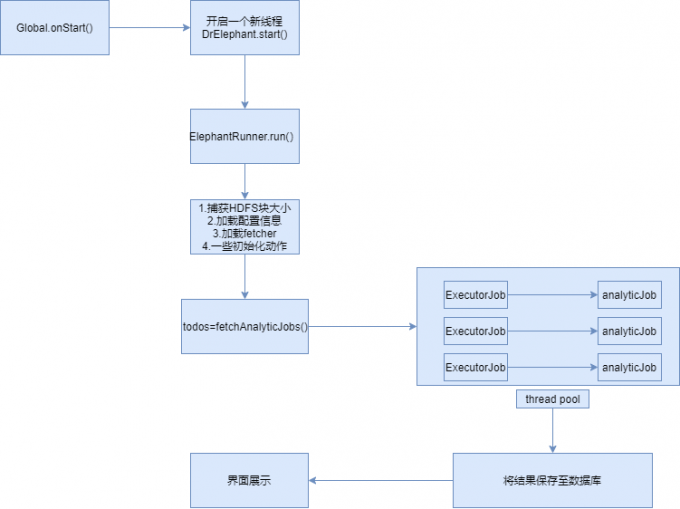
因为我们只需要关注Spark任务,下面主要介绍下Spark指标如何采集?
上面我们已经知道Dr执行的大致流程, 我们只采集spark任务, 所以不用太多额外的代码和抽象.
只需要关键的几个步骤改造即可:
1.首先还是通过yarn api 获取执行的job, 我们只需要对ExecutorJob直接使用org.apache.spark.deploy.history.SparkFSFetcher#fetchData方法, 获取eventlog, 并对eventlog进行重放解析
将解析后的数据,获取相关需要的信息,直接写入mysql库
因为涉及连接hdfs,yarn 等服务,将hdfs-site.xml,core-site.xml等文件放置配置目录下
最终将程序改造成一个main方法直接运行的常驻进程运行
采集后的主要信息:
- 采集stage相关指标信息
- 采集app任务配置、executor个数、核数等,执行开始时间、结束时间、耗时等
改造后整体流程如下:
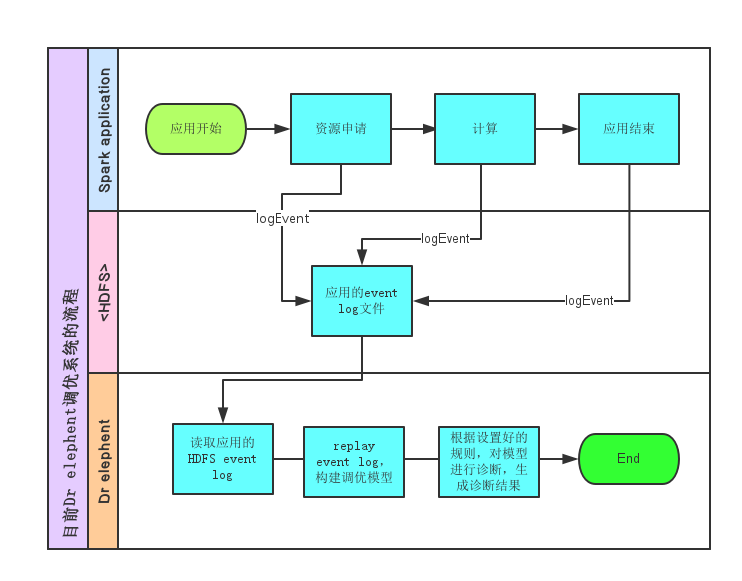
规则平台进行配置, 有了采集数据, 根据规则对相关指标定级, 并以不同颜色区分展示,并给出相关诊断意见.
总结
本文主要根据平台用户平常提交的spark任务思考,调研引入Dr. Elephant, 通过阅读Dr 相关源码, 明白Dr 执行整体流程并对代码进行改造,适配我们的需求.最终转变为平台产品来对用户的Spark任务进行诊断并给出相关调优建议.
参考
https://github.com/linkedin/dr-elephant
https://blog.csdn.net/qq475781638/article/details/90247623
[平台建设] Spark任务的诊断调优的更多相关文章
- 【原创 Hadoop&Spark 动手实践 8】Spark 应用经验、调优与动手实践
[原创 Hadoop&Spark 动手实践 7]Spark 应用经验.调优与动手实践 目标: 1. 了解Spark 应用经验与调优的理论与方法,如果遇到Spark调优的事情,有理论思考框架. ...
- Spark面试题(八)——Spark的Shuffle配置调优
Spark系列面试题 Spark面试题(一) Spark面试题(二) Spark面试题(三) Spark面试题(四) Spark面试题(五)--数据倾斜调优 Spark面试题(六)--Spark资源调 ...
- 【Spark】Sparkstreaming-性能调优
Sparkstreaming-性能调优 Spark Master at spark://node-01:7077 sparkstreaming 线程 数量_百度搜索 streaming中partiti ...
- Spark 常用参数及调优
spark streaming 调优的几个角度: 高效地利用集群资源减少批数据的处理时间 设置正确的批容量(size),使数据的处理速度能够赶上数据的接收速度 内存调优 Spark SQL 可以通过调 ...
- spark submit参数及调优
park submit参数介绍 你可以通过spark-submit --help或者spark-shell --help来查看这些参数. 使用格式: ./bin/spark-submit \ ...
- 013 Spark中的资源调优
1.平常的资源使用情况 2.官网 3.资源参数调优 cores memory JVM 4.具体参数 可以在--conf参数中给定资源配置相关信息(配置的一般是JVM的一些垃圾回收机制) --drive ...
- 【Spark】Spark-性能调优-系列文章
Spark-性能调优-系列文章 Spark Master at spark://node-01:7077 scala java8_百度搜索 (1 封私信)如何评价Linkedin决定逐渐减少Scala ...
- Spark(十)Spark之数据倾斜调优
一 调优概述 有的时候,我们可能会遇到大数据计算中一个最棘手的问题——数据倾斜,此时Spark作业的性能会比期望差很多.数据倾斜调优,就是使用各种技术方案解决不同类型的数据倾斜问题,以保证Spark作 ...
- spark submit参数及调优(转载)
spark submit参数介绍 你可以通过spark-submit --help或者spark-shell --help来查看这些参数. 使用格式: ./bin/spark-submit \ -- ...
随机推荐
- Docker学习(三)——Docker镜像使用
Docker镜像使用 当运行容器时,使用的镜像如果在本地中不存在,docker就会自动从docker镜像仓库中下载,默认是从Docker Hub公共镜像源下载. 1.镜像使用 (1)列 ...
- Multiple Inheritance in C++
Multiple Inheritance is a feature of C++ where a class can inherit from more than one classes. The c ...
- POST/GET请求中RequestBody和RequestParam的应用场景
POST请求时 @RequestBody --> JSON字符串部分 @RequestParam --> 请求参数部分 application/json格局图 图一.png form- ...
- System.exit(-1)和return 的区别
对于只有一个单一方法的类或者系统来说是一样的,但是对于含有多个类和方法,且调用关系比较复杂时就不一样了. System.exit(-1)是指所有程序(方法,类等)停止,系统停止运行. return只是 ...
- 【Linux】【Services】【Configuration】puppet
1. 简介 1.1. 官方网站:https://docs.puppet.com/ 1.2. puppet是IT基础设施自动化管理工具,他的整个生命周期包括:provisioning,configura ...
- 【Linux卷管理】LVM创建与管理
安装LVM 首先确定系统中是否安装了lvm工具: [root@jetsen ~]# rpm -qa|grep lvm system-config-lvm-1.1.5-1.0.el5 lvm2-2.02 ...
- 使用jquery完成抽奖图片滚动的效果
<!DOCTYPE html><html><head> <meta charset="UTF-8"> <title>jq ...
- pipeline post指令
目录 一.介绍 二.参数说明 三.使用实例 一.介绍 post步骤包含的是在整个pipeline或阶段完成后一些附加的步骤.post步骤是可选的,所以并不包含在声明式pipeline最简结构中,但这并 ...
- Excel如何使用vlookup
一.vlookup的语法 VLOOKUP (lookup_value, table_array, col_index_num, [range_lookup]) ①Lookup_value为需要在数据表 ...
- git 基本命令及idea集成使用
目录 git基本命令使用 设置签名 gitHub 服务配置秘钥 上传代码 更新代码 分支管理 bat脚本更新 idea集成git git基本命令使用 设置签名 签名和秘钥大多数是一起设置的,设置后一般 ...