Chapter 15 Outcome Regression and Propensity Scores
这一章讲一种新的方法: propensity scores.
15.1 Outcome regression
在满足条件可交换性下,
\]
之前的模型都是对等式左端进行建模, 倘若我们对等式右端进行建模呢?
\]
15.2 Propensity scores
在IP weighting 和 g-estimation的使用过程中, 我们需要估计条件概率\(\mathrm{Pr}[A=1|L]\), 记为\(\pi (L)\).
\(\pi (L)\) 就是所谓的propensity scores, 其反应了特定\(L\)的一种倾向.
首先我们要证明,
\]
不妨假设\(\pi(L) = s \Leftrightarrow L \in \{l_i\}\), 则
\mathrm{Pr}[Y^a|\pi(L)=s]
&= \mathrm{Pr} [Y^a|L \in \{l_i\}] \\
&= \frac{\sum_i\mathrm{Pr}[Y^a,L=l_i]}{\sum_i \mathrm{Pr} [L=l_i]}\\
&= \frac{\sum_i\mathrm{Pr}[Y|A=a, L=l_i]\mathrm{Pr}[L=l_i]}{\sum_i \mathrm{Pr} [L=l_i]}\\
&= \frac{\mathrm{Pr}[A=a|L=l] \cdot \sum_i\mathrm{Pr}[Y|A=a, L=l_i]\mathrm{Pr}[L=l_i]}{\mathrm{Pr}[A=a|L=l]\sum_i \mathrm{Pr} [L=l_i]}\\
&= \frac{\cdot \sum_i\mathrm{Pr}[Y|A=a, L=l_i]\mathrm{Pr}[A=a, L=l_i]}{\sum_i \mathrm{Pr} [A=a, L=l_i]}\\
&= \frac{\cdot \sum_i\mathrm{Pr}[Y, A=a, L=l_i]}{\sum_i \mathrm{Pr} [A=a, L=l_i]}\\
&= \frac{\cdot \mathrm{Pr}[Y, A=a, \pi(L)=s]}{\mathrm{Pr} [A=a, \pi(L)]}\\
&= \mathrm{Pr} [Y|A=a, \pi(L)=s].
\end{array}
\]
注意: \(\pi(l_i) = \pi(l_j) = \pi(l) = s\).
注意到, 上面有很重要的一步, 我们上下同时乘以\(\mathrm{Pr}[A=a|L=l]\), 实际上只有当\(A \in \{0, 1\}\)的时候才能成立, 因为二元, 加之\(\pi(L)=s\), 所以
\]
也就是说当\(A\)不是二元的时候, 上面的推导就是错误的了.
怪不得书上说, propensity scores这个方法是很难推广的非二元treatments的情况的.
15.3 Propensity stratification and standardization
此时, 我们可以把\(\pi(L)\)看成一个新的中间变量\(L\)(confounder?), 如下图:
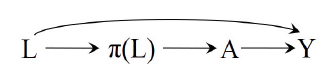
要知道, 原来的\(L\)可能是一个高维向量, 现在压缩为一维, 这意味着我们的可以将
\]
假设地更加精简.
估计或许更加牢靠(直接无参数模型?).
但是需要指出是, 不同个体的\(\pi(L)\)往往都是不同的, 这就导致我们想要估计
\]
几乎是不可能的.
一种比较好的做法是, 分成一段段区间, 考虑
\]
比如书上推荐的10分位.
当然这种做法会在一定程度上破化条件可交换性, 但是可以认为如果区间取得比较合适, 结果应该是比较合理的.
另外需要指出的, 我们往往会陷入一个误区, 觉得\(\pi(L)\), 即条件概率\(\mathrm{Pr}[A=1|L]\)的估计越准确越好, 实际上不是.
我们需要保证的仅仅是满足条件可交换性, 实际上准确度无关紧要.
有些时候过分追求准确度会适得其反, 因为这时我们往往会引入很多的变量, 导致我们的条件可交换性被大大破坏了.
所以不要仅仅当成是回归问题来看.
15.4 Propensity matching
看就是就是matching的翻版, 不过我matching也没搞懂哦.
15.5 Propensity models, structural models, predictive models
就主要是15.3里讲过的.
Fine Point
Nuisance parameters
Effect modification and the propensity score
Technical Point
Balancing scores and prognostic scores
Chapter 15 Outcome Regression and Propensity Scores的更多相关文章
- 零元学Expression Blend 4 - Chapter 15 用实例了解互动控制项「Button」I
原文:零元学Expression Blend 4 - Chapter 15 用实例了解互动控制项「Button」I 本章将教大家如何更改Button的预设Template,以及如何在Button内设置 ...
- Propensity Scores
目录 基本的概念 重要的结果 应用 Propensity Score Matching Stratification on the Propensity Score Inverse Probabili ...
- Thinking in Java from Chapter 15
From Thinking in Java 4th Edition. 泛型实现了:参数化类型的概念,使代码可以应用于多种类型.“泛型”这个术语的意思是:“适用于许多许多的类型”. 如果你了解其他语言( ...
- Think Python - Chapter 15 - Classes and objects
15.1 User-defined typesWe have used many of Python’s built-in types; now we are going to define a ne ...
- 《C++ Primer》 chapter 15 TextQuery
<C++ Primer>中第15章为了讲解面向对象编程,举了一个例子:设计一个小程序,能够处理查询给定word在文件中所在行的任务,并且能够处理“非”查询,“或”查询,“与”查询.例如执行 ...
- 【C++ Primer 5th】Chapter 15
摘要: 1. 面向对象程序设计的核心思想是数据抽象.继承和动态绑定.数据抽象将类的接口和实现分离:继承定义相似的类型并对齐相似关系建模:动态绑定,在一定程度上忽略相似类型的区别,而以统一的方式使用它们 ...
- 《算法导论》— Chapter 15 动态规划
序 算法导论一书的第四部分-高级设计和分析技术从本章开始讨论,主要分析高效算法的三种重要技术:动态规划.贪心算法以及平摊分析三种. 首先,本章讨论动态规划,它是通过组合子问题的解而解决整个问题的,通常 ...
- MySQL Crash Course #07# Chapter 15. 关系数据库. INNER JOIN. VS. nested subquery
索引 理解相关表. foreign key JOIN 与保持参照完整性 关于JOIN 的一些建议,子查询 VS. 联表查询 我发现MySQL 的官方文档里是有教程的. SQL Tutorial - W ...
- Chapter 6 — Improving ASP.NET Performance
https://msdn.microsoft.com/en-us/library/ff647787.aspx Retired Content This content is outdated and ...
随机推荐
- 日常Java 2021/11/4
ServerSocket类的方法服务器应用程序通过使用java.net.ServerSocket类以获取一个端口,并且侦听客户端请求. 构造方法: public ServerSocket(int po ...
- 带你全面了解 OAuth2.0
最开始接触 OAuth2.0 的时候,经常将它和 SSO单点登录搞混.后来因为工作需要,在项目中实现了一套SSO,通过对SSO的逐渐了解,也把它和OAuth2.0区分开了.所以当时自己也整理了一篇文章 ...
- Angular @Input讲解及用法
1.什么是@input @input的作用是定义模块输入,是用来让父级组件向子组件传递内容. 2.@input用法 首先在子组件中将需要传递给父组件的变量用@input()修饰 需要在子组件ts文件i ...
- ORACLE 查询sql和存储性能思路
1.确定session id 如果是存储过程,在程序开头设置客户端标识.并根据标识获取session id. DBMS_SESSION.set_identifier('XXX'); select * ...
- 【C/C++】算法入门:排序/算法笔记
(设排序从小到大) 冒泡排序 这个大家都会,从第一个开始往后俩俩交换,然后第二个,最后到最后一个,复杂度n^2 选择排序 思路和冒泡差不多,比如要得到从小到大的排序,就是从第一个开始,i取1~n,每次 ...
- Boss直聘App上“天使投资、VC、PE” 与“A轮、B轮、C轮融资”的关系
我们经常看到朋友圈里某某公司获得了某轮融资,所谓的A轮B轮究竟是个什么概念呢?今天就跟小伙伴们分享一下A.B.C.D轮融资与天使投资.VC.PE的关系. 天使投资(AI):天使投资所投的是一些非常早期 ...
- Linux入侵 反弹shell
目录 一.简介 二.命令 三.NetCat 一.简介 黑入服务器很少会是通过账号密码的方式进入,因为这很难破解密码和很多服务器都做了限制白名单. 大多是通过上传脚本文件,然后执行脚本开启一个端口,通过 ...
- thinkPHP跨数据库访问/数据库切换
在项目的开发中会遇到访问多个数据库的问题这里讲的是:访问同一地址下的多个数据库 第一步:在配置文件中配置你要连接的其他的数据库 例如:我现在默认的数据库是back 现在我要设置第二个数据库travel ...
- Mac 下安装Phonegap开发环境
Mac 下安装Phonegap开发环境 2014.09.11 星期四 评论 0 条 阅读 5,613 次 作者:野草 标签:phonegap ios mac 什么是Phonegap呢?Phon ...
- 小迪安全 Web安全 基础入门 - 第一天 - 操作系统&名词&文件下载&反弹SHELL&防火墙绕过
一.专业名词 1.POC:(Proof of Concept),即概念验证.漏洞报告中的POC是一段说明或一个攻击的样例使读者能够确认这个漏洞是真实存在的. 2.EXP:exploit,即漏洞利用.对 ...