SpringCloud微服务实战——搭建企业级开发框架(三十三):整合Skywalking实现链路追踪
Skywalking是由国内开源爱好者吴晟(原OneAPM工程师)开源并提交到Apache孵化器的产品,它同时吸收了Zipkin/Pinpoint/CAT的设计思路,支持非侵入式埋点。是一款基于分布式跟踪的应用程序性能监控系统。另外社区还发展出了一个叫OpenTracing的组织,旨在推进调用链监控的一些规范和标准工作。
1、下载Skywalking,下载地址:https://skywalking.apache.org/downloads/#download-the-latest-versions ,根据需求选择发布的版本,这里我们选择最新发布版v8.4.0 for H2/MySQL/TiDB/InfluxDB/ElasticSearch 7
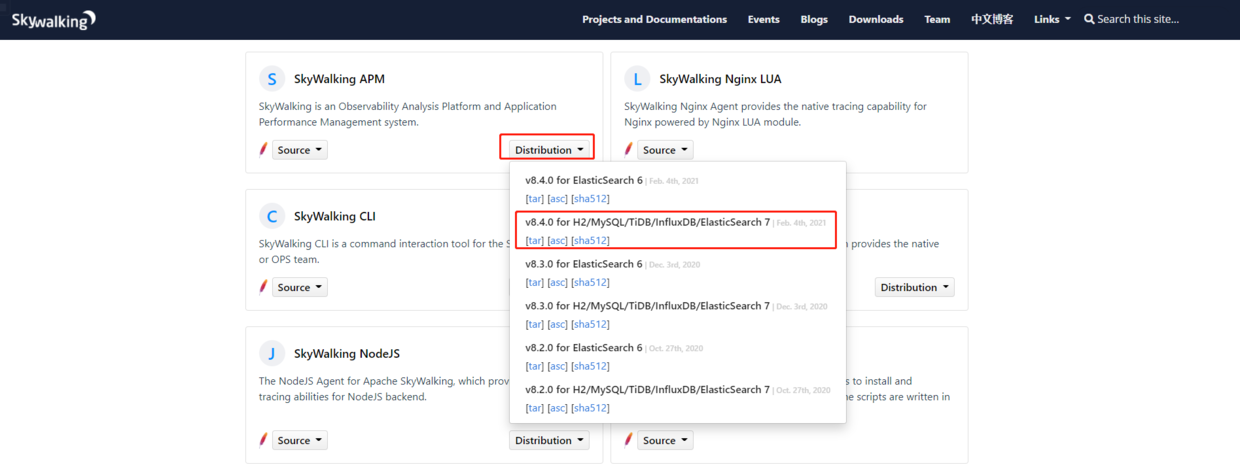
2、下载Elasticsearch,下载地址:https://www.elastic.co/cn/downloads/elasticsearch ,因为上面我们选择下载的Skywalking用到的是ElasticSearch 7,所以这里下载Elasticsearch 7.12.0
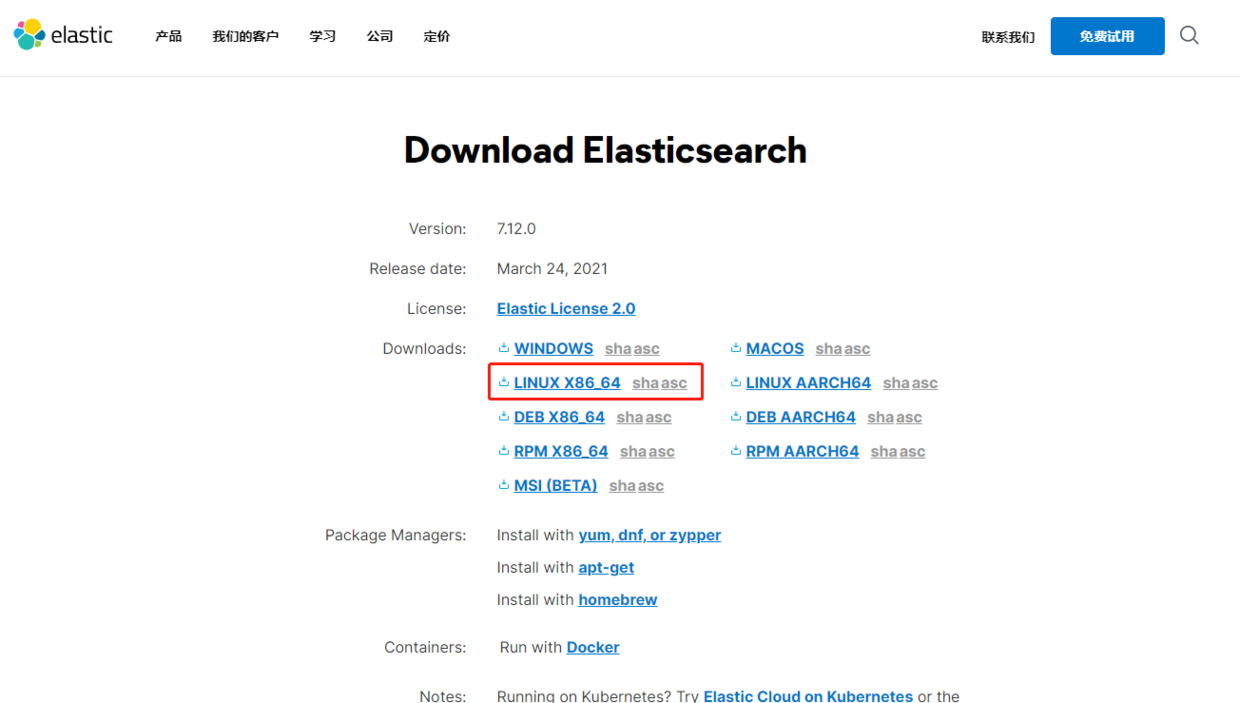
3、将下载后的apache-skywalking-apm-es7-8.4.0.tar.gz和elasticsearch-7.12.0-linux-x86_64.tar.gz上传到Linux服务器并分别解压
tar -zxvf apache-skywalking-apm-es7-8.4.0.tar.gztar -zxvf elasticsearch-7.12.0-linux-x86_64.tar.gz
4、修改/elasticsearch-7.12.0/config下的elasticsearch.yml
# 修改clusteri.name: CollectorDBClusternode.name: CollectorDBCluster-1# 这里设置为实际的ip地址network.host: 127.0.0.1http.port: 9200cluster.initial_master_nodes: ["CollectorDBCluster-1"]
5、为了系统安全考虑,Elasticsearch默认不能使用root用户启动,这里新建一个es用户用于启动Elasticsearch
#创建es用户组及es用户groupadd esuseradd es -g es# 修改登录用户的密码,这里设置为Skywalkingpasswd es#将elasticsearch-7.12.0文件夹权限赋予es用户chown -R es:es elasticsearch-7.12.0#切换到es用户su es#进入到elasticsearch-7.12.0/bin目录,执行启动命令, 后面-d为后台启动./elasticsearch -d
6、访问http://127.0.0.1:9200即可查看elasticsearch是否启动成功
{"name" : "CollectorDBCluster-1","cluster_name" : "CollectorDBCluster","cluster_uuid" : "J2LyQWfdTeeBN0dcdWpgqw","version" : {"number" : "7.12.0","build_flavor" : "default","build_type" : "tar","build_hash" : "78722783c38caa25a70982b5b042074cde5d3b3a","build_date" : "2021-03-18T06:17:15.410153305Z","build_snapshot" : false,"lucene_version" : "8.8.0","minimum_wire_compatibility_version" : "6.8.0","minimum_index_compatibility_version" : "6.0.0-beta1"},"tagline" : "You Know, for Search"}
7、修改apache-skywalking-apm-bin-es7\config\application.yml
storage:# 默认存储是h2,这里改为elasticsearch7selector: ${SW_STORAGE:elasticsearch7}elasticsearch7:nameSpace: ${SW_NAMESPACE:"CollectorDBCluster"}#这里localhost改为elasticsearch7的安装地址clusterNodes: ${SW_STORAGE_ES_CLUSTER_NODES:127.0.0.1:9200}
8、切换到apache-skywalking-apm-bin-es7\bin目录,并执行启动命令
./startup.sh
9、访问http://127.0.0.1:8080/查看是否启动成功
10、Skywalking搭建好之后,我们这里说明在开发环境中,把agent通过IDEA配置到每个微服务中,配置-Dskywalking.agent.service_name为微服务的名称
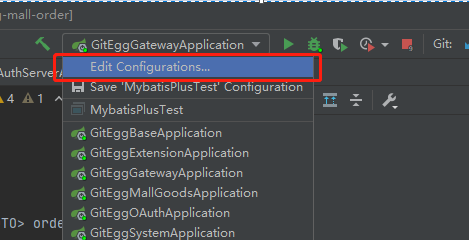
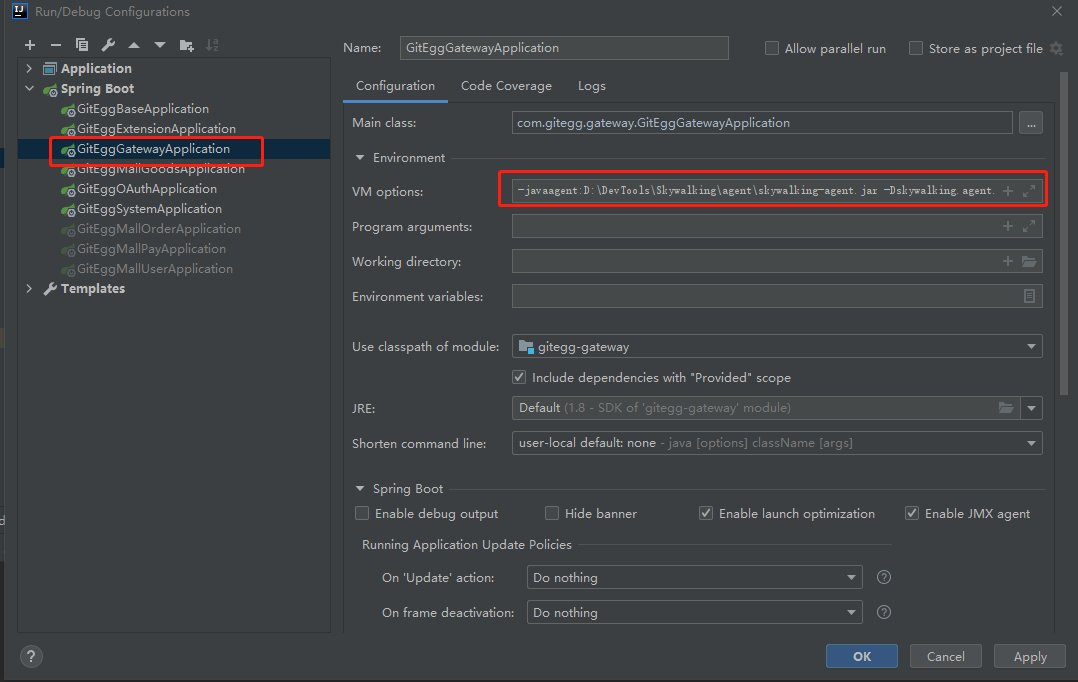
-javaagent:D:\DevTools\Skywalking\agent\skywalking-agent.jar -Dskywalking.agent.service_name=gitegg-gateway -Dskywalking.collector.backend_service=127.0.0.1:11800
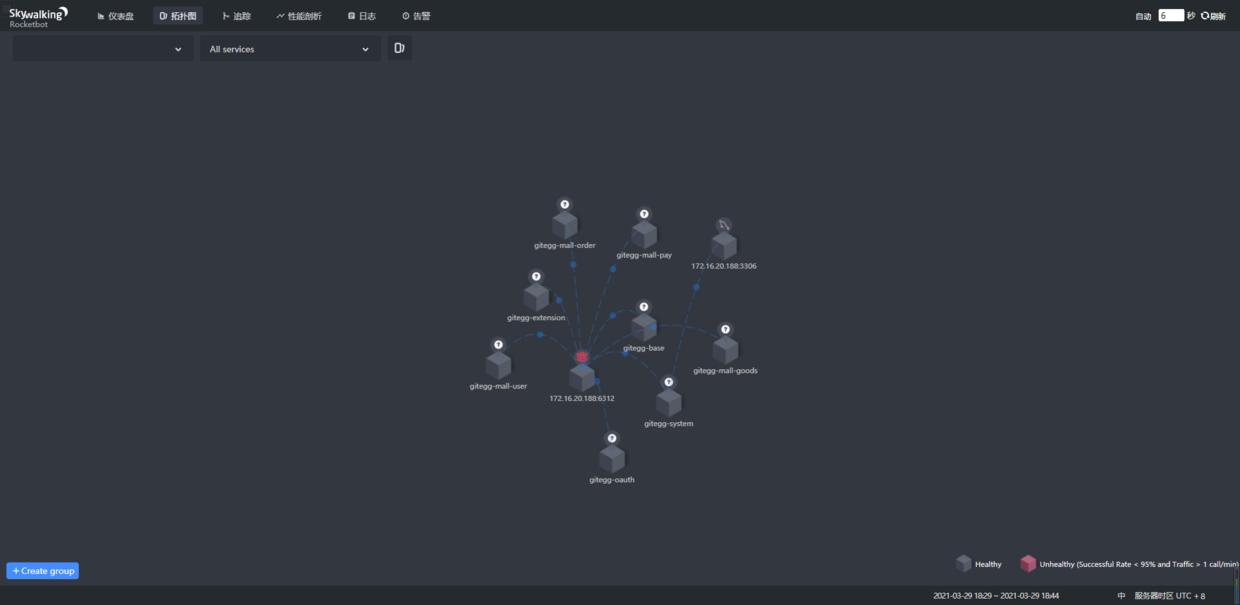
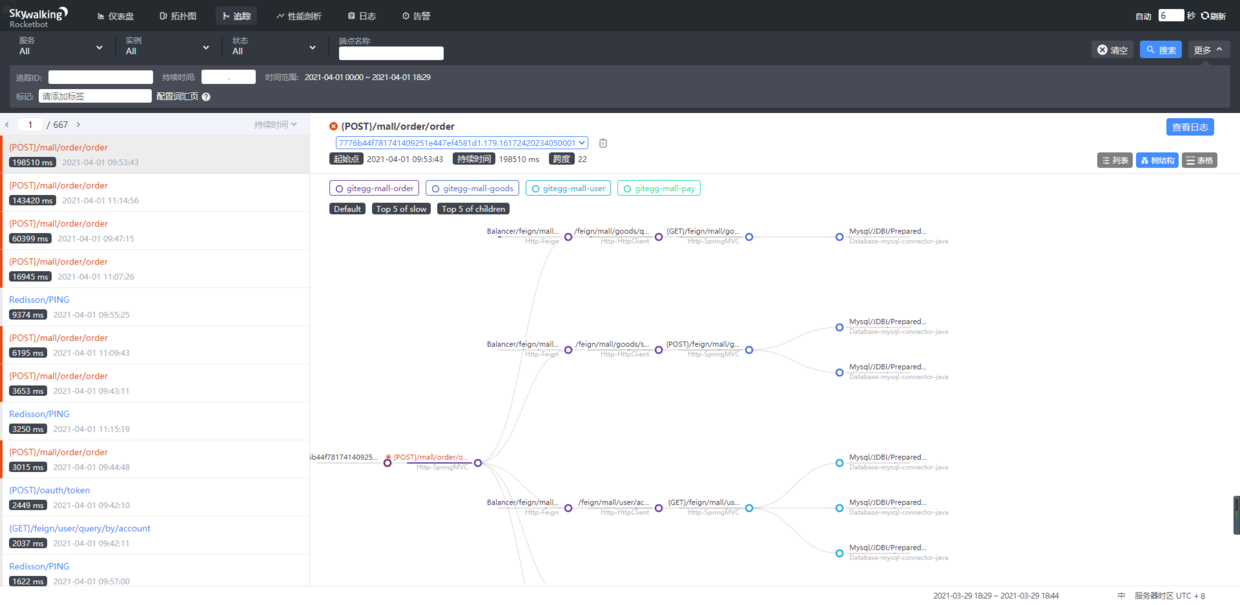
11、配置好之后启动微服务,打开http://127.0.0.1:8080 ,点击拓扑图可以看到整个微服务的关系
源码地址:
Gitee: https://gitee.com/wmz1930/GitEgg
GitHub: https://github.com/wmz1930/GitEgg
SpringCloud微服务实战——搭建企业级开发框架(三十三):整合Skywalking实现链路追踪的更多相关文章
- SpringCloud微服务实战——搭建企业级开发框架(十三):OpenFeign+Ribbon实现高可用重试机制
Spring Cloud OpenFeign 默认是使用Ribbon实现负载均衡和重试机制的,虽然Feign有自己的重试机制,但该功能在Spring Cloud OpenFeign基本用不上,除非 ...
- SpringCloud微服务实战——搭建企业级开发框架(三十七):微服务日志系统设计与实现
针对业务开发人员通常面对的业务需求,我们将日志分为操作(请求)日志和系统运行日志,操作(请求)日志可以让管理员或者运营人员方便简单的在系统界面中查询追踪用户具体做了哪些操作,便于分析统计用户行为: ...
- SpringCloud微服务实战——搭建企业级开发框架(三十八):搭建ELK日志采集与分析系统
一套好的日志分析系统可以详细记录系统的运行情况,方便我们定位分析系统性能瓶颈.查找定位系统问题.上一篇说明了日志的多种业务场景以及日志记录的实现方式,那么日志记录下来,相关人员就需要对日志数据进行 ...
- SpringCloud微服务实战——搭建企业级开发框架(三十四):SpringCloud + Docker + k8s实现微服务集群打包部署-Maven打包配置
SpringCloud微服务包含多个SpringBoot可运行的应用程序,在单应用程序下,版本发布时的打包部署还相对简单,当有多个应用程序的微服务发布部署时,原先的单应用程序部署方式就会显得复杂且 ...
- SpringCloud微服务实战——搭建企业级开发框架(三十六):使用Spring Cloud Stream实现可灵活配置消息中间件的功能
在以往消息队列的使用中,我们通常使用集成消息中间件开源包来实现对应功能,而消息中间件的实现又有多种,比如目前比较主流的ActiveMQ.RocketMQ.RabbitMQ.Kafka,Stream ...
- SpringCloud微服务实战——搭建企业级开发框架(三十五):SpringCloud + Docker + k8s实现微服务集群打包部署-集群环境部署
一.集群环境规划配置 生产环境不要使用一主多从,要使用多主多从.这里使用三台主机进行测试一台Master(172.16.20.111),两台Node(172.16.20.112和172.16.20.1 ...
- SpringCloud微服务实战——搭建企业级开发框架(三十一):自定义MybatisPlus代码生成器实现前后端代码自动生成
理想的情况下,代码生成可以节省很多重复且没有技术含量的工作量,并且代码生成可以按照统一的代码规范和格式来生成代码,给日常的代码开发提供很大的帮助.但是,代码生成也有其局限性,当牵涉到复杂的业务逻辑 ...
- SpringCloud微服务实战——搭建企业级开发框架(三十二):代码生成器使用配置说明
一.新建数据源配置 因考虑到多数据源问题,代码生成器作为一个通用的模块,后续可能会为其他工程生成代码,所以,这里不直接读取系统工程配置的数据源,而是让用户自己维护. 参数说明 数据源名称:用于查找区分 ...
- SpringCloud微服务实战——搭建企业级开发框架(三十):整合EasyExcel实现数据表格导入导出功能
批量上传数据导入.数据统计分析导出,已经基本是系统必不可缺的一项功能,这里从性能和易用性方面考虑,集成EasyExcel.EasyExcel是一个基于Java的简单.省内存的读写Excel的开源项 ...
随机推荐
- python实现轮廓发现
目录: (一)轮廓发现的介绍 (二)代码实现 (1)使用直接使用阈值方法threshold方法获取二值化图像来选择轮廓 (2)使用canny边缘检测获取二值化图像 (一)轮廓发现的介绍与API的介绍 ...
- [luogu3706]硬币游戏
(可以参考洛谷4548,推导过程较为省略) 定义$g_{i}$表示随机$i$次后未出现给定字符串的概率,$f_{k,i}$表示随机$i$次后恰好出现$s_{k}$(指第$k$个字符串)的概率,设两者的 ...
- [luogu5666]树的重心
考虑枚举一个点k,求其为重心的方案数暴力的做法是,将其作为根搜索,设最大子树大小为s1,次大为s2,对割掉的子树分类讨论:1.在子树中,分两种情况(都可以用线段树合并来做) (1)从s1中切掉一棵大小 ...
- 【PS】证件照转换背景色
证件照转换背景色 2019-07-14 12:18:49 by冲冲 1. 需求 自由切换证件照的背景颜色(白底.蓝底.红底...) 2. 步骤 ① 双击 图层锁 解锁,弹出的"新建图层0 ...
- 解决ip和域名都能够ping通但是启动nginx无法访问网页的问题
解决思路 最近双11逛西部数码的官网看看有没有什么服务器优惠的时候,发现了可以申请一个一块钱用一整年的SSL证书,立马心动下单了,想想俺也可以用https装装X了哈哈 不过在部署完证书,并调整ngin ...
- Codeforces 436E - Cardboard Box(贪心/反悔贪心/数据结构)
题面传送门 题意: 有 \(n\) 个关卡,第 \(i\) 个关卡玩到 \(1\) 颗星需要花 \(a_i\) 的时间,玩到 \(2\) 颗星需要 \(b_i\) 的时间.(\(a_i<b_i\ ...
- perl FileHandle 模块使用
打开多个文件时必备啊 1 use FileHandle; 2 3 my (%index,%fh); 4 # 创建句柄,这里利用gzip 压缩下 5 foreach my $k(keys %index) ...
- Linux—linux 查看一个文件有多少M
ls -l --block-size=M #就把目录下的所有文件按M单位呈现
- 44-Count and Say
Count and Say My Submissions QuestionEditorial Solution Total Accepted: 79863 Total Submissions: 275 ...
- 05 Windows安装python3.6.4+pycharm环境
windows安装python3.6.4环境 使用微信扫码关注微信公众号,并回复:"Python工具包",免费获取下载链接! 一.卸载python环境 卸载以下软件: 二.安装py ...