docker容器使用loki收集日志
docker-compose安装loki套件(loki+promtail+grafana)
loki进行日志聚合处理 类似elk中的es
promtail是日志收集,类似elk中的logstash filebeat等,如果是只收集docker容器的日志则可以用loki的docker plugin替代
grafana是日志显示,类似elk中的kibana,可以通过各种标签和表达式过滤显示日志
docker-compose.yml内容如下
version: "3" networks:
loki: services:
loki:
image: grafana/loki
restart: always
environment:
- TZ=Asia/Shanghai
- LANG=zh_CN.UTF-8
ports:
- 3100:3100
networks:
- loki promtail:
image: grafana/promtail
restart: always
environment:
- TZ=Asia/Shanghai
- LANG=zh_CN.UTF-8
networks:
- loki grafana:
image: grafana/grafana:master
restart: always
environment:
- TZ=Asia/Shanghai
- LANG=zh_CN.UTF-8
ports:
- 3000:3000
networks:
- loki
如果只用docker plugin来收集日志则可以把promtail部分删除,已经有grafana的也可以直接复用
安装loki的docker plugin
命令行运行
docker plugin install grafana/loki-docker-driver:latest --alias loki --grant-all-permissions
当有新版本时, 更新plugins
docker plugin disable loki --force
docker plugin upgrade loki grafana/loki-docker-driver:latest --grant-all-permissions
docker plugin enable loki
systemctl restart docker
对于loki的docker plugin有两种使用方式。
- 配置daemon.json,收集此后创建的所有容器的日志(注意,是配置daemon.json后重启docker服务后创建的容器才会把日志输出到loki)。
- 新建容器时指定logging类型为loki,这样只有指定了logging的容器才会输出到loki
全局收集配置
编辑daemon.json。linux下默认路径是/etc/docker/daemon.json (需要sudo), windows则默认是%userprofile%\.docker\daemon.json
{
"log-driver": "loki",
"log-opts": {
"loki-url": "http://YOUR_IP:3100/loki/api/v1/push",
"max-size": "50m",
"max-file": "10",
"loki-pipeline-stages": "- multiline:\n firstline: '^\[\d{2}:\d{2}:\d{2} \w{4}\]'\n"
},
"registry-mirrors": ["https://registry.docker-cn.com"]
}
记得把YOUR_IP换成loki所在主机的IP,一般都是本机的局域网地址,如果loki映射的端口换了记得这里也需要换。镜像仓库地址也可以换成自己云服务的。
其中max-size表示日志文件最大大小,max-file表示最多10个日志文件,都是对单个容器来说的, multiline是配置多行识别(默认最多128行),转为单行, firstline表示单条日志的首行正则表达式
我的是 [03:00:32 INFO] 开头这种格式,所以对应正则是^\[\d{2}:\d{2}:\d{2} \w{4}\] 按照你自己的日志开头编写对应正则替换即可
然后重启docker服务。
sudo systemctl restart docker
在此之后创建的容器默认都会把日志发送到loki。
如果不全局配置,而只想特定的容器进行日志收集,则根据启动容器的方式,有两种配置方法。
docker run配置日志输出到loki
通过docker run启动容器,可以通过--log-driver来指定为loki。示例如下
docker run --rm --name=grafana --log-driver=loki --log-opt loki-url="http://YOUR_IP:3100/loki/api/v1/push" --log-opt max-size=50m --log-opt max-file=10 grafana/grafana
--log-driver=loki指定日志驱动器为loki
--log-opt loki-url则指定了loki的url
--log-opt max-size日志最大大小
--log-opt max-file日志文件最大数量
docker-compose 配置日志输出到loki
docker-compose 小于3.4可以对需要日志输出的配置添加配置如下
logging:
driver: loki
options:
loki-url: "http://YOUR_IP:3100/loki/api/v1/push"
max-size: "50m"
max-file: "10"
loki-pipeline-stages: |
- multiline:
firstline: '^\[\d{2}:\d{2}:\d{2} \w{4}\]'
注意:max-size和max-file这里需要加引号 multiline已经在上文解释过了就不再赘述了
对于3.4极其以上版本可以通过定义模板来减少代码量
version: "3.4" x-logging:
&loki-logging
driver: loki
options:
loki-url: "http://YOUR_IP:3100/loki/api/v1/push"
max-size: "50m"
max-file: "10"
loki-pipeline-stages: |
- multiline:
firstline: '^\[\d{2}:\d{2}:\d{2} \w{4}\]'
services:
host:
container_name: grafana
image: grafana/grafana
environment:
- TZ=Asia/Shanghai
- LANG=zh_CN.UTF-8
logging: *loki-logging
&loki-logging表示定义模板
*loki-logging表示引用模板。对于多个服务就只需要对应加上一行 logging: *loki-logging 即可。相比之前的版本可谓是大大简化了
Grafana显示和过滤日志
一开始安装的时候将grafana映射到了宿主机的3000端口,所以地址就为 http://YOUR_IP:3000
grafana默认用户名密码是admin和admin
第一次进入需要修改admin的密码
添加loki数据源
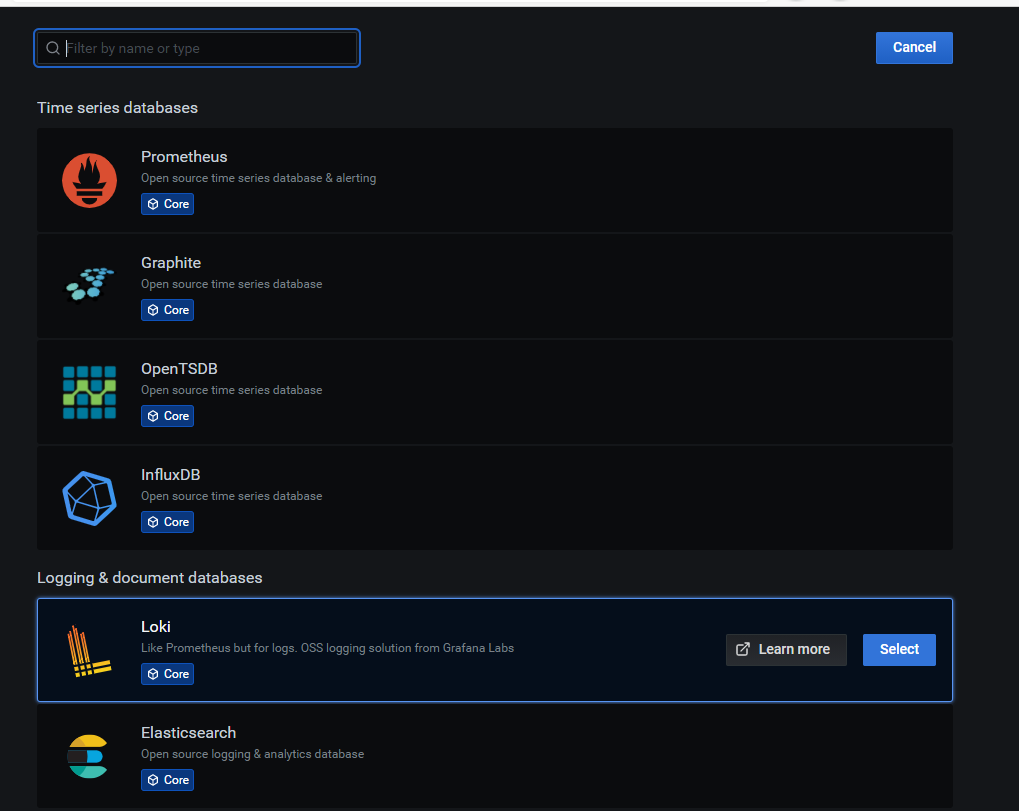
选择loki。
因为一开始安装grafana和loki是在一个docker-compose里,所以默认在同一个子网下,因此可以url可以直接写http://loki:3100。如果grafana和loki是分开的,则需要改为填loki所在的宿主机ip
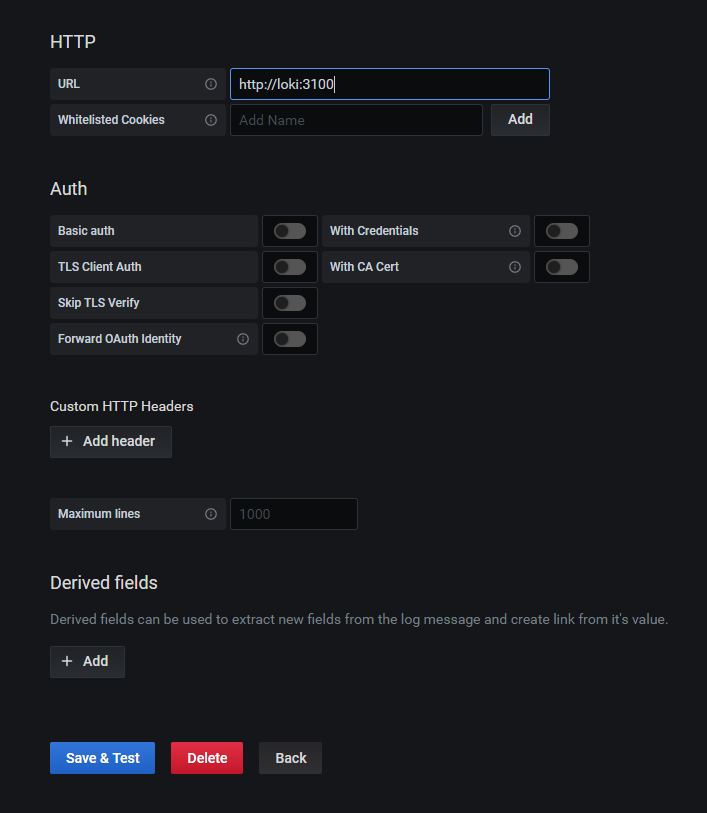
点击 保存和测试 。会提示链接成功。
查看过滤日志
左侧菜单栏选择探索
label里有对应选项可以选择。 compose_project就是docker-compose的项目名 compose_service就是其中的服务名 container_name就是容器名。这几个基本就够我们定位到具体的某个容器了。
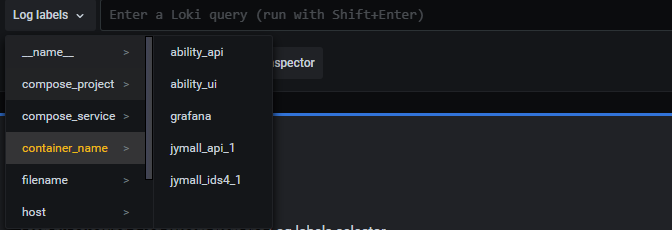
关键字查询 |~ "keyword" 文档链接: LogQL文档
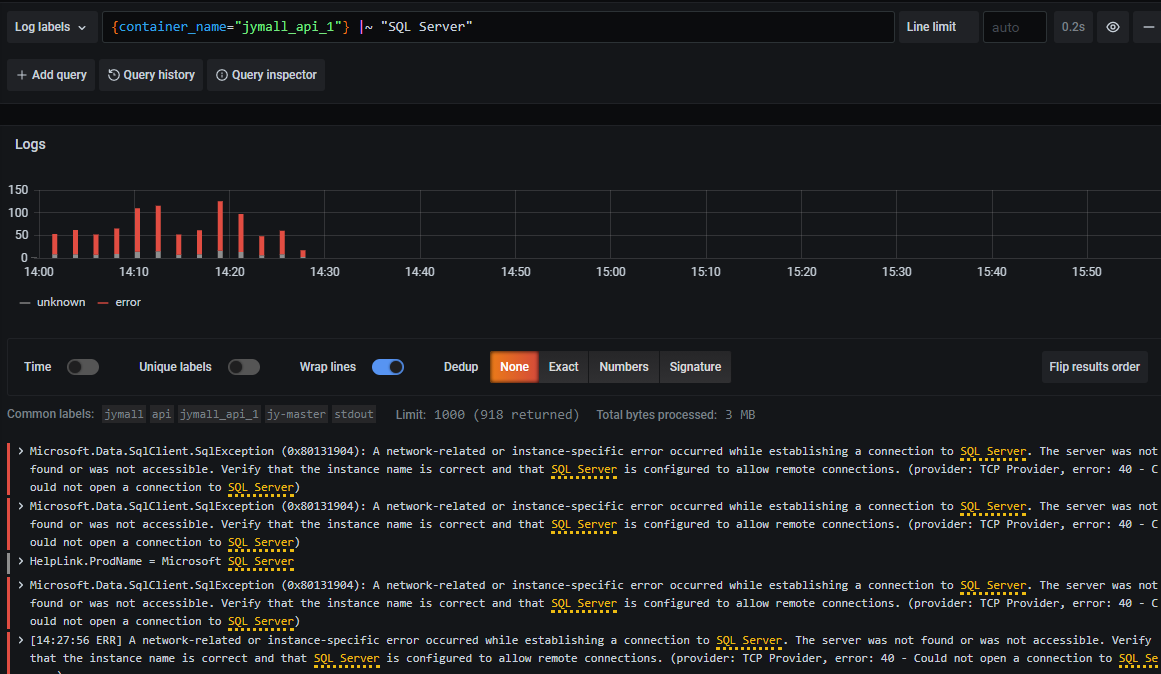
然后是时间段选择
注意:Serilog默认日志格式是 "[{Timestamp:HH:mm:ss} {Level:u3}] {Message:lj}{NewLine}{Exception}" 其中日志等级是3位,loki识别不到,最好是4位,所以需要把Level:u3改为u4
后续应该是loki增加缓存以优化查询速度和集群配置(k8s)
docker容器使用loki收集日志的更多相关文章
- Docker 容器、镜像、日志相关操作
一. 容器操作 新建并启动 命令:docker run 查看容器 命令:docker ps 查看终止状态的容器 命令:docker ps -a 启动已终止容器 命令:docker start 终止容器 ...
- docker容器日志管理(清理)
原文:docker容器日志管理(清理) 前言 在使用docker容器时候,其日志的管理是我们不得不考虑的事情.因为docker容器的日志文件会占据大量的磁盘空间.下面介绍的就是对docker容器日志的 ...
- 万能日志数据收集器 Fluentd - 每天5分钟玩转 Docker 容器技术(91)
前面的 ELK 中我们是用 Filebeat 收集 Docker 容器的日志,利用的是 Docker 默认的 logging driver json-file,本节我们将使用 fluentd 来收集容 ...
- docker容器日志收集方案汇总评价总结
docker日志收集方案有太多,下面截图罗列docker官方给的日志收集方案(详细请转docker官方文档).很多方案都不适合我们下面的系列文章没有说. 经过以下5篇博客的叙述简单说下docker容器 ...
- docker容器日志收集方案(方案N,其他中间件传输方案)
由于docker虚拟化的特殊性导致日志收集方案的多样性和复杂性下面接收几个可能的方案 这个方案各大公司都在用只不过传输方式大同小异 中间件使用kafka是肯定的,kafka的积压与吞吐能力相当强悍 ...
- docker容器日志收集方案(方案一 filebeat+本地日志收集)
filebeat不用多说就是扫描本地磁盘日志文件,读取文件内容然后远程传输. docker容器日志默认记录方式为 json-file 就是将日志以json格式记录在磁盘上 格式如下: { " ...
- elk-filebeat收集docker容器日志
目录 使用docker搭建elk filebeat安装与配置 docker容器设置 参考文章 首发地址 使用docker搭建elk 1.使用docker-compose文件构建elk.文件如下: ve ...
- Flume+Kafka收集Docker容器内分布式日志应用实践
1 背景和问题 随着云计算.PaaS平台的普及,虚拟化.容器化等技术的应用,例如Docker等技术,越来越多的服务会部署在云端.通常,我们需要需要获取日志,来进行监控.分析.预测.统计等工作,但是云端 ...
- ELK:收集Docker容器日志
简介 之前写过一篇博客 ELK:日志收集分析平台,介绍了在Centos7系统上部署配置使用ELK的方法,随着容器化时代的到来,容器化部署成为一种很方便的部署方式,收集容器日志也成为刚需.本篇文档从 容 ...
随机推荐
- 001.AD域控简介及使用
一 AD概述 1.1 AD简介 域(Domain)是Windows网络中独立运行的单位,域之间相互访问则需要建立信任关系. 当一个域与其他域建立了信任关系后,2个域之间不但可以按需要相互进行管理,还可 ...
- Swift-技巧(六)设置按钮状态并更改
摘要 按钮是一个宝藏控件,可以在设置的时候就对不同的状态添加图片.文本,甚至更改背景.在不同的展示场景中更改到不同的状态显示就好.恰恰是如何更改状态着实让我懵了一阵,所以记录一下过程.如果没有兴趣了解 ...
- 七、Hadoop3.3.1 HA 高可用集群QJM (基于Zookeeper,NameNode高可用+Yarn高可用)
目录 前文 Hadoop3.3.1 HA 高可用集群的搭建 QJM 的 NameNode HA Hadoop HA模式搭建(高可用) 1.集群规划 2.Zookeeper集群搭建: 3.修改Hadoo ...
- springboot上传文件异常解决方案
配置文件加入: #配置文件传输 spring.servlet.multipart.enabled =true spring.servlet.multipart.file-size-threshold ...
- Spring Cloud Gateway过滤器精确控制异常返回(实战,控制http返回码和message字段)
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 前文<Spring Cloud Gat ...
- 三个 AGC D(AGC037D、AGC043D、AGC050D)
大概就 lxr 讲了 4 个 AGC 的 D,有一个以前做过了不算,另外三个都会做罢( 为了避免开三个博客就把它们合并到一起了 AGC 037 D lxr:难度顺序排列大概是 037<043&l ...
- Linux中gz文件操作遇到的一些技巧和坑
目录 不解压情况下获取gz超大文件的前/后几行? Perl读入gz文件操作? 不能直接通过wc -l 来统计gz文件的行数 前提是gz文件超大,如上百G,肯定不能直接解压来做. 不解压情况下获取gz超 ...
- KVM原理
虚拟化是云计算的基础.简单的说,虚拟化使得在一台物理的服务器上可以跑多台虚拟机,虚拟机共享物理机的 CPU.内存.IO 硬件资源,但逻辑上虚拟机之间是相互隔离的.物理机我们一般称为宿主机(Host), ...
- arm三大编译器的不同选择编译
ARM 系列目前支持三大主流的工具链,即ARM RealView (armcc), IAR EWARM (iccarm), and GNU Compiler Collection (gcc). ...
- 宏GENERATED_BODY做了什么?
Version:4.26.2 UE4 C++工程名:MyProject \ 一般语境下,我们说c++源码的编译大体分为:预处理.编译.链接; cppreference-translation_phas ...