【Spark】【RDD】从HDFS创建RDD
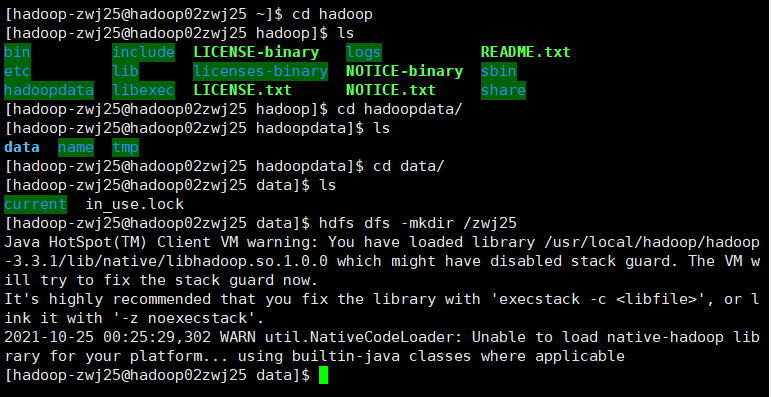
1.在HDFS根目录下创建目录(姓名学号)
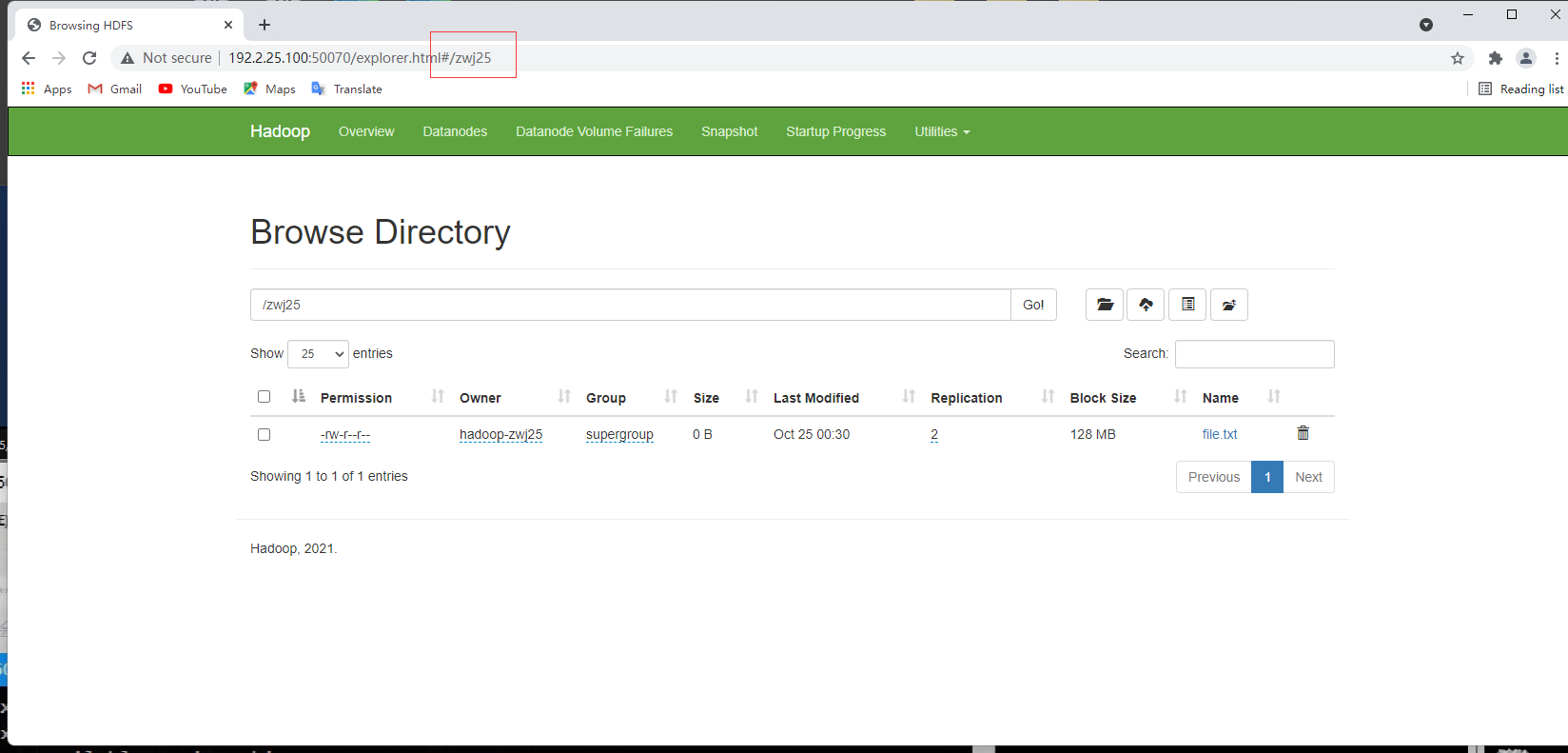
hdfs dfs -mkdir /zwj25
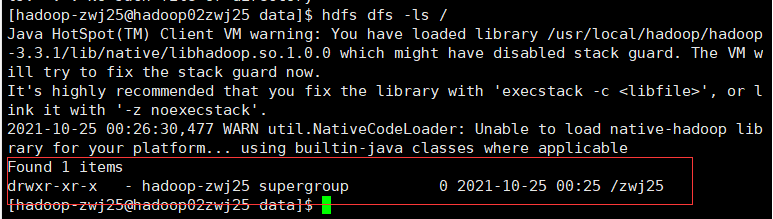
hdfs dfs -ls /
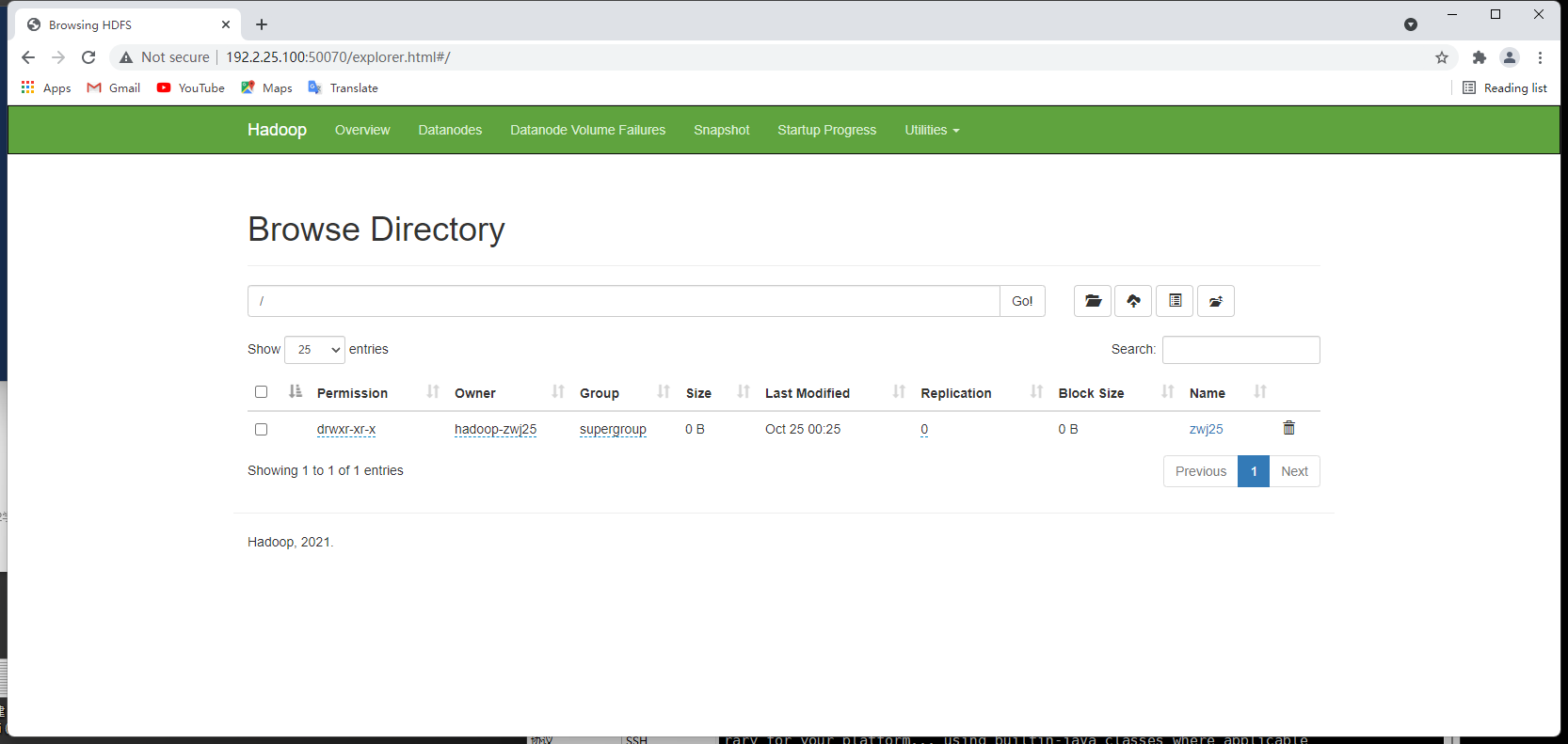
访问 http://[IP]:50070
2.上传本地文件到HDFS
hdfs dfs -put file.txt /zwj25
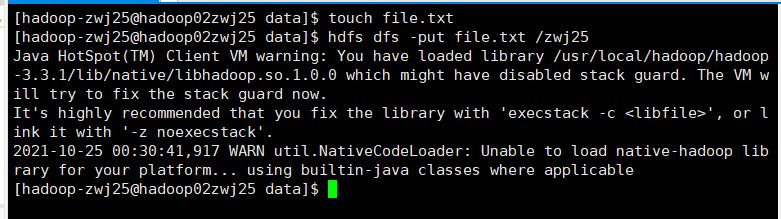
3.进入spark4-shell
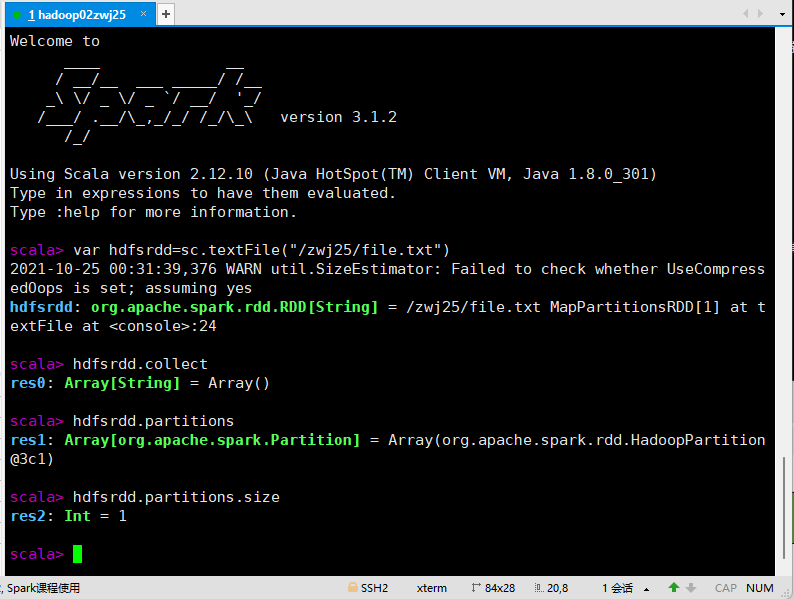
var hdfsrdd=sc.textFile("/zwj25/file.txt")
hdfsrdd.collect
hdfsrdd.partitions
hdfsrdd.partitions.size
sc.defaultMinPartitions=min(sc.defaultParallelism,2)
rdd分区数=max(hdfs文件的block数目,sc.defaultMinPartitions)
【Spark】【RDD】从HDFS创建RDD的更多相关文章
- Spark RDD概念学习系列之RDD的创建(六)
RDD的创建 两种方式来创建RDD: 1)由一个已经存在的Scala集合创建 2)由外部存储系统的数据集创建,包括本地文件系统,还有所有Hadoop支持的数据集,比如HDFS.Cassandra.H ...
- 5、创建RDD(集合、本地文件、HDFS文件)
一.创建RDD 1.创建RDD 进行Spark核心编程时,首先要做的第一件事,就是创建一个初始的RDD.该RDD中,通常就代表和包含了Spark应用程序的输入源数据.然后在创建了初始的RDD之后,才可 ...
- Spark练习之创建RDD(集合、本地文件),RDD持久化及RDD持久化策略
Spark练习之创建RDD(集合.本地文件) 一.创建RDD 二.并行化集合创建RDD 2.1 Java并行创建RDD--计算1-10的累加和 2.2 Scala并行创建RDD--计算1-10的累加和 ...
- Learning Spark中文版--第三章--RDD编程(1)
本章介绍了Spark用于数据处理的核心抽象概念,具有弹性的分布式数据集(RDD).一个RDD仅仅是一个分布式的元素集合.在Spark中,所有工作都表示为创建新的RDDs.转换现有的RDD,或者调 ...
- 【Spark】【RDD】初次学习RDD 笔记 汇总
RDD Author:萌狼蓝天 [哔哩哔哩]萌狼蓝天 [博客]https://mllt.cc [博客园]萌狼蓝天 - 博客园 [微信公众号]mllt9920 [学习交流QQ群]238948804 目录 ...
- Spark核心编程---创建RDD
创建RDD: 1:使用程序中的集合创建RDD,主要用于进行测试,可以在实际部署到集群运行之前,自己使用集合构造测试数据,来测试后面的spark应用流程. 2:使用本地文件创建RDD,主要用于临时性地处 ...
- Spark核心RDD、什么是RDD、RDD的属性、创建RDD、RDD的依赖以及缓存、
1:什么是Spark的RDD??? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行 ...
- 02、创建RDD(集合、本地文件、HDFS文件)
Spark Core提供了三种创建RDD的方式,包括:使用程序中的集合创建RDD:使用本地文件创建RDD:使用HDFS文件创建RDD. 1.并行化集合 如果要通过并行化集合来创建RDD,需要针对程序中 ...
- Hive数据分析——Spark是一种基于rdd(弹性数据集)的内存分布式并行处理框架,比于Hadoop将大量的中间结果写入HDFS,Spark避免了中间结果的持久化
转自:http://blog.csdn.net/wh_springer/article/details/51842496 近十年来,随着Hadoop生态系统的不断完善,Hadoop早已成为大数据事实上 ...
随机推荐
- [年薪60W分水岭]基于Netty手写Apache Dubbo(带注册中心和注解)
阅读这篇文章之前,建议先阅读和这篇文章关联的内容. 1. 详细剖析分布式微服务架构下网络通信的底层实现原理(图解) 2. (年薪60W的技巧)工作了5年,你真的理解Netty以及为什么要用吗?(深度干 ...
- 【Microsoft Azure 的1024种玩法】二.基于Azure云平台的安全攻防靶场系统构建
简介 本篇文章将基于在Microsoft Azure云平台上使用Pikachu去构建安全攻防靶场,Pikachu使用世界上最好的语言PHP进行开发,数据库使用的是mysql,因此运行Pikachu需要 ...
- [bzoj1735]泥泞的牧场
考虑木板一定都尽量长,对于每一个污泥,最多只有两种木板会覆盖它(横着和竖的),将这两块木板连边,意味着每一条边两端端点中一定有一个点要被选,即最小点覆盖=最大匹配数. 1 #include<bi ...
- [nowcoder5669E]Eliminate++
枚举$a_{i}$并判断是否可行,有以下结论:若$a_{i}$可以留下来,一定存在一种合法方案使得$a_{i}$仅参与最后若干次合并,且第一次参与合并前左右都不超过2个数 证明:将大于$a_{i}$的 ...
- 【Mysql】深入理解 MVCC 多版本并发控制
MVCC MVCC(Multi-Version Concurrency Control),即多版本并发控制.是 innodb 实现事务并发与回滚的重要功能.锁机制可以控制并发操作,但是其系统开销较大, ...
- 【NOIP 2018】摆渡车
前情提要 是的 我终于回来补坑了 一年了哇 你这个鸽子王 斜率优化版本 今天在复习斜率优化的时候才想起来这个题 定义就不设了 大家想看可以看上面那个原版 怎么斜率优化呢? 我们考虑\(i\)点是当前的 ...
- LOJ #2769 -「ROI 2017 Day 1」前往大都会(单调栈维护斜率优化)
LOJ 题面传送门 orz 斜率优化-- 模拟赛时被这题送走了,所以来写篇题解( 首先这个最短路的求法是 trivial 的,直接一遍 dijkstra 即可( 重点在于怎样求第二问.注意到这个第二问 ...
- 洛谷 P3688 - [ZJOI2017]树状数组(二维线段树+标记永久化)
题面传送门 首先学过树状数组的应该都知道,将树状数组方向写反等价于前缀和 \(\to\) 后缀和,因此题目中伪代码的区间求和实质上是 \(sum[l-1...n]-sum[r...n]=sum[l-1 ...
- 端口TCP——简介
cmd命令:telnet 如果需要搭建外网可访问的网站,可以顺便勾选HTTP,HTTPS端口:
- linux命令行快速统计文件(压缩文件)的行数
统计(文件|压缩文件)的行数 zcat file.gz | sed -n '$=' #迅速.直接打印出多少行.-n 取消 ...