为什么我建议在复杂但是性能关键的表上所有查询都加上 force index
最近,又遇到了慢 SQL,简单的看了下,又是因为 MySQL 本身优化器还有查询计划估计不准的问题。SQL 如下:
select * from t_pay_recordWHERE((user_id = 'user_id1'AND is_del = 0))ORDER BYid DESCLIMIT 20
这个 SQL 执行了 20 分钟才有结果。但是我们换一个 user_id,执行就很快。从线上业务表现来看,大部分用户的表现都正常。我们又用一个数据分布与这个用户相似的用户去查,还是比较快。
我们先来 EXPLAIN 下这个原始 SQL,结果是:
+----+-------------+--------------+------------+-------+-----------------------------------------------------------------------------------------+---------+---------+------+-------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+--------------+------------+-------+-----------------------------------------------------------------------------------------+---------+---------+------+-------+----------+-------------+| 1 | SIMPLE | t_pay_record | NULL | index | idx_user_id,idx_user_status_pay,idx_user_id_trade_code_status_amount_create_time_is_del | PRIMARY | 8 | NULL | 22593 | 0.01 | Using where |+----+-------------+--------------+------------+-------+-----------------------------------------------------------------------------------------+---------+---------+------+-------+----------+-------------+
然后我们换一些分布差不多的用户但是响应时间正常的用户,EXPLAIN 结果有的是:
+----+-------------+--------------+------------+-------+-----------------------------------------------------------------------------------------+---------------------------------------------------------+---------+------+-------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+--------------+------------+-------+-----------------------------------------------------------------------------------------+---------------------------------------------------------+---------+------+-------+----------+-------------+| 1 | SIMPLE | t_pay_record | NULL | index | idx_user_id,idx_user_status_pay,idx_user_id_trade_code_status_amount_create_time_is_del | idx_user_id_trade_code_status_amount_create_time_is_del | 195 | NULL | 107561| 10.00| Using where |+----+-------------+--------------+------------+-------+-----------------------------------------------------------------------------------------+---------------------------------------------------------+---------+------+-------+----------+-------------+
有的是:
+----+-------------+--------------+------------+-------+-----------------------------------------------------------------------------------------+-------------+---------+------+-------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+--------------+------------+-------+-----------------------------------------------------------------------------------------+-------------+---------+------+-------+----------+-------------+| 1 | SIMPLE | t_pay_record | NULL | index | idx_user_id,idx_user_status_pay,idx_user_id_trade_code_status_amount_create_time_is_del | idx_user_id | 195 | NULL | 87514| 10.00| Using where |+----+-------------+--------------+------------+-------+-----------------------------------------------------------------------------------------+-------------+---------+------+-------+----------+-------------+
其实根据这个表现就可以推断出,是走错索引了。为啥会用错索引呢?这个是因为多方面的原因导致的,本篇文章将针对这个 SQL 来分析下这个多方面的原因,并给出最后的解决办法。
对于 MySQL 慢 SQL 的分析
在之前的文章,我提到过 SQL 调优一般通过下面三个工具:
- EXPLAIN:这个是比较浅显的分析,并不会真正执行 SQL,分析出来的可能不够准确详细。但是能发现一些关键问题。
- PROFILING: 通过
set profiling = 1开启的 SQL 执行采样。可以分析 SQL 执行分为哪些阶段,并且每阶段的耗时如何。需要执行并且执行成功 SQL,并且分析出来的阶段不够详细,一般只能通过某些阶段是否存在如何避免这些阶段的出现进行优化(例如避免内存排序的出现等等)。 - OPTIMIZER TRACE:详细展示优化器的每一步,需要执行并且执行成功 SQL。MySQL 的优化器由于考虑的因素太多,迭代太多,配置相当复杂,默认的配置在大部分情况没问题,但是在某些特殊情况会有问题,需要我们进行人为干预。
这里再说一下在不同的 MySQL 版本, EXPLAIN 和 OPTIMIZER TRACE 结果可能不同,这是 MySQL 本身设计上的不足导致的,EXPLAIN 更贴近最后的执行结果,OPTIMIZER TRACE 相当于在每一步埋点采集,在 MySQL 不断迭代开发的时候,难免会有疏漏
对于上面这个 SQL,我们其实 EXPLAIN 就能知道它的原因是走错索引了。但是不能直观的看出来为啥会走错索引,需要通过 OPTIMIZER TRACE 进行进一步定位。但是在进一步定位之前,我想先说一下 MySQL 的 InnoDB 查询优化器数据配置。
MySQL InnoDB 查询优化器数据配置(MySQL InnoDB Optimizer Statistics)
官网文档地址:https://dev.mysql.com/doc/refman/8.0/en/innodb-persistent-stats.html
为了优化用户的 SQL 查询,MySQL 会对所有 SQL 查询进行 SQL 解析、改写和查询计划优化。针对 InnoDB 引擎,制定查询计划的时候要分析:
- 全表扫描消耗是多大
- 走索引可以走哪些索引?会考虑 where 条件,以及 order 条件,通过里面的条件找有这些条件的索引
- 每个索引的查询消耗是多大
- 选出消耗最小的那个查询计划并执行
每个索引查询消耗,需要通过 InnoDB 查询优化器数据。这个数据是通过采集表以及索引数据得出的,并且并不是全量采集,而是抽样采集。与以下配置相关:
innodb_stats_persistent全局变量控制全局默认的数据是否持久化,默认为 ON 即持久化,我们一般不会能接受在内存中保存,这样万一数据库重启,表就要重新分析,这样减慢启动时间。控制单个表的配置是STATS_PERSISTENT(在CREATE TABLE以及ALTER TABLE中使用)。innodb_stats_auto_recalc全局变量全局默认是否自动更新,默认为 ON 即在表中有 10% 以上的行更新后触发后台异步更新采集数据,。控制单个表的配置是STATS_AUTO_RECALC(在CREATE TABLE以及ALTER TABLE中使用)。innodb_stats_persistent_sample_pages全局变量控制全局默认的采集页的数量,默认为 20. 即每次更新,随机采集表以及表中的每个索引的 20 页数据,用于估算每个索引的查询消耗是多大以及全表扫描消耗是多大,控制单个表的配置是STATS_SAMPLE_PAGES(在CREATE TABLE以及ALTER TABLE中使用)。
执行时间最慢的 SQL 原因定位
通过之前的 EXPLAIN 的结果,我们知道最后的查询用的索引是 PRIMARY 主键索引,这样的话整个 SQL 的执行过程就是:通过主键倒序遍历表中的每一条数据,直到筛选出 20 条。通过执行耗时我们知道,这个遍历了很多数据才凑满 20 条,效率极其低下。为啥会这样呢?
通过 SQL 语句我们知道,在前面提到的第二步中,考虑的索引包括 where 条件中的 user_id,is_del 相关的索引(通过 EXPLAIN 我们知道有这些索引:idx_user_id,idx_user_status_pay,idx_user_id_trade_code_status_amount_create_time_is_del),以及 order by 条件中的 id 索引,也就是主键索引。假设本次随机采集中采集的页数据是这个样子的:
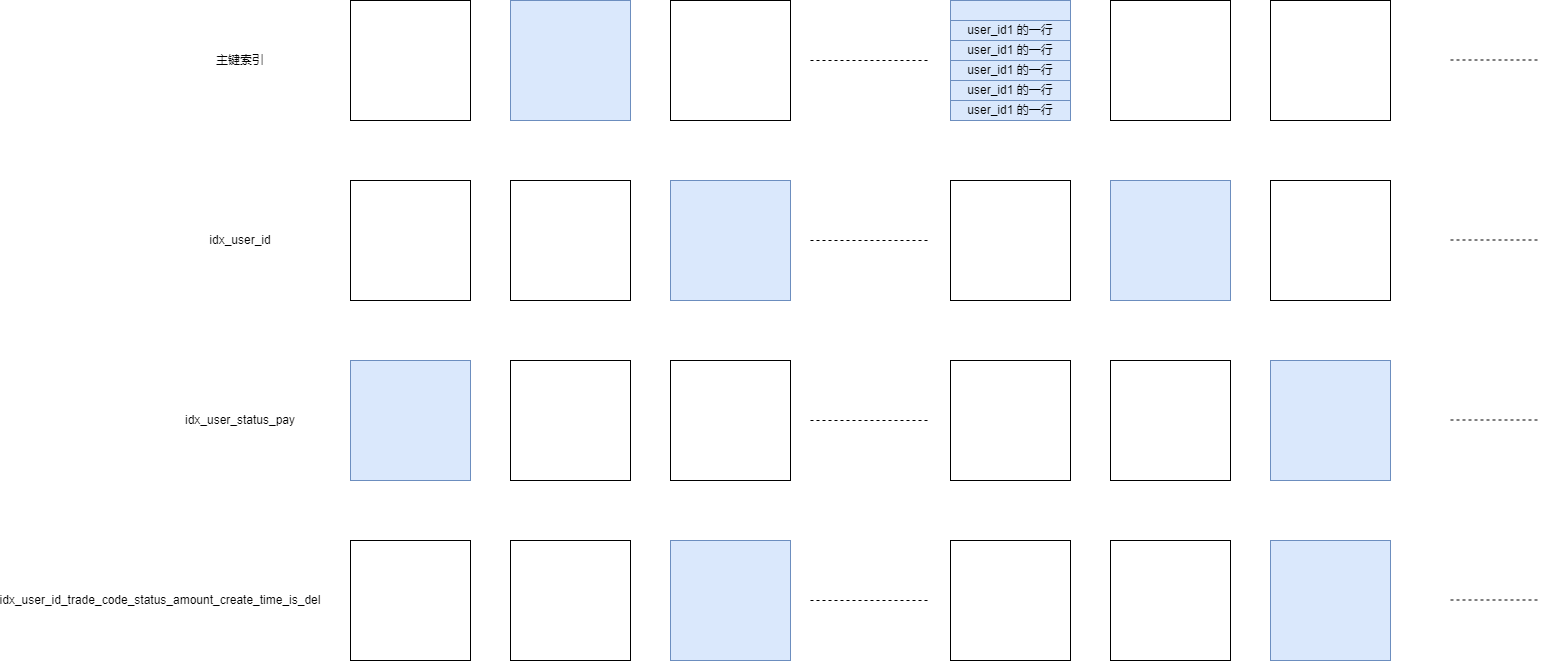
图中蓝色的代表抽样到的页,同一个表内每个索引都会抽样默认 20 页。假设本次采集的结果就是图中所示,其他索引采集的比较均衡,通过其他索引判断用户都要扫描几万行的结果。但是主键采集的最后一页,正好末尾全是这个用户的记录。由于语句最后有 limit 20,如果末尾正好有 20 条记录(并且都符合 where 条件),那么就会认为按照主键倒着找 20 条记录就可以了。这样就会造成优化器认为走主键扫描消耗最少。但是实际上并不是这样,因为这是采样的,没准后面有很多很多不是这个用户的记录,对大表尤其如此。
如果我们把 limit 去掉,EXPLAIN 就会发现索引走对了,因为不限制 limit,主键索引就要全部扫描一遍,消耗怎么也不可能比 user_id 相关的索引低了。
执行时间正常的 SQL 为啥 user_id 不同也会走分析出走不同索引的原因
同样的,由于所有索引的优化器数据是随机采样的,随着表的不断变大以及索引的不断膨胀,还有就是可能加更复杂的索引,这样会加剧使用不同参数分析索引消耗的差异性(这里就是使用不同的 user_id)。
这也引出了一个新的可能大家也会遇到的问题,我在原有索引的基础上,加了一个复合索引(举个例子就是原来只有 idx_user_id,后来加了 idx_user_status_pay),那么原来的只按照 user_id 去查数据的 SQL,有的可能会使用
idx_user_id,有的可能会使用 idx_user_status_pay,使用 idx_user_status_pay 大概率比使用 idx_user_id, 慢。所以,添加新的复合索引,可能会导致原来的不是这个复合索引要优化的 SQL 的其他业务 SQL 变慢,所以需要慎重添加
这种设计,在数据量不断增大表越变越复杂的时候,会带来哪些问题
- 由于统计数据不是实时更新,而是更新的行数超过一定比例才会开始更新。并且统计数据不是全量统计,是抽样统计。所以在表的数据量很大的时候,这个统计数据很难非常准确。
- 由于统计数据本来就不够准确,表设计如果也比较复杂,存储的数据类型比较多,字段也很多,并且最关键的是有各种复合索引,索引也越来越复杂,这样更加加剧了这个统计数据的不准确性。
- 顺便说一下:MySQL 表数据量不能很大,需要做好水平拆分,同时字段不能太多,所以需要做好垂直拆分。并且索引不能随便加,想加多少加多少,也有以上说的这两个原因,这样会加剧统计数据的不准确性,导致用错索引。
- 手动 Analyze Table,会在表上加读锁,会阻塞表上的更新以及事务。所以不能在这种在线业务关键表上面使用。可以考虑在业务低峰的时候,定时 Analyze 业务关键 Table
- 依靠表本身自动刷新数据机制,参数比较难以调整(主要是
STATS_SAMPLE_PAGES这个参数,STATS_PERSISTENT我们一般不会改,我们不会能接受在内存中保存,这样万一数据库重启,表就要重新分析,这样减慢启动时间,STATS_AUTO_RECALC我们也不会关闭,这样会导致优化器分析的越来越不准确),很难预测出到底调整到什么数值最合适。并且业务的增长,用户的行为导致的数据的倾斜,也是很难预测的。通过 Alter Table 修改某个表的STATS_SAMPLE_PAGES的时候,会导致和 Analyze 这个 Table 一样的效果,会在表上加读锁,会阻塞表上的更新以及事务。所以不能在这种在线业务关键表上面使用。所以最好一开始就能估计出大表的量级,但是这个很难。
结论和建议
综上所述,我建议线上对于数据量比较大的表,最好能提前通过分库分表控制每个表的数据量,但是业务增长与产品需求都是不断在迭代并且变复杂的。很难保证不会出现大并且索引比较复杂的表。这种情况下需要我们,在适当调高 STATS_SAMPLE_PAGES 的前提下,对于一些用户触发的关键查询 SQL,使用 force index 引导它走正确的索引,这样就不会出现本文中说的因为 MySQL 优化器表采集数据的不准确导致的某些用户 id 查询走错索引的情况。
微信搜索“我的编程喵”关注公众号,加作者微信,每日一刷,轻松提升技术,斩获各种offer:
我会经常发一些很好的各种框架的官方社区的新闻视频资料并加上个人翻译字幕到如下地址(也包括上面的公众号),欢迎关注:

为什么我建议在复杂但是性能关键的表上所有查询都加上 force index的更多相关文章
- 高性能mysql 第六章查询性能优化 总结(上)查询的执行过程
6 查询性能优化 6.1为什么查询会变慢 这里说明了的查询执行周期,从客户端到服务器端,服务器端解析,优化器生成执行计划,执行(可以细分,大体过程可以通过show profile查看),从服务器端返 ...
- MySQL数据库性能优化:表、索引、SQL等
一.MySQL 数据库性能优化之SQL优化 注:这篇文章是以 MySQL 为背景,很多内容同时适用于其他关系型数据库,需要有一些索引知识为基础 优化目标 减少 IO 次数IO永远是数据库最容易瓶颈的地 ...
- 0709MySQL 数据库性能优化之表结构优化
转自http://isky000.com/database/mysql-perfornamce-tuning-schema MySQL 数据库性能优化之缓存参数优化 MySQL数据库性能优化之硬件瓶颈 ...
- SQL Server查询性能优化——堆表、碎片与索引(一)
SQL Server在堆表中查询数据时,是不知道到底有多少数据行符合你所指定的查找条件,它将根据指定的查询条件把数据表的全部数据都查找 一遍.如果有可采用的索引,SQL Server只需要在索引层级查 ...
- SQL Server查询性能优化——堆表、碎片与索引(二)
本文是对 SQL Server查询性能优化——堆表.碎片与索引(一)的一些总结. 第一:先对 SQL Server查询性能优化——堆表.碎片与索引(一)中的例一的SET STATISTICS IO之 ...
- MYSQl 全表扫描以及查询性能
MYSQl 全表扫描以及查询性能 -- 本文章仅用于学习,记录 一. Mysql在一些情况下全表检索比索引查询更快: 1.表格数据很少,使用全表检索会比使用索引检索更快.一般当表格总数据小于10行并且 ...
- zabbix nagios 类nagios 之 不以性能为前提的开发和监控都是瞎扯淡
从最初的nagios到现在强大的zabbix 3.0,我想说,不以性能为前提的开发和监控都是瞎扯淡? 首先我对这两款监控软件的认识: zabbix,很多企业都在用,给人的感觉是很炫,不过我个人觉得虽然 ...
- Oracle Update 语句语法与性能分析 - 多表关联
Oracle Update 语句语法与性能分析 - 多表关联 为了方便起见,建立了以下简单模型,和构造了部分测试数据: 在某个业务受理子系统BSS中, SQL 代码 --客户资料表 create ...
- SQL中使用WITH AS提高性能,使用公用表表达式(CTE)简化嵌套SQL
一.WITH AS的含义 WITH AS短语,也叫做子查询部分(subquery factoring),可以让你做很多事情,定义一个SQL片断,该SQL片断会被整个SQL语句所用到.有的时候, ...
随机推荐
- 记一次线上SpringCloud-Feign请求服务超时异常排查
由于近期线上单量暴涨,第三方反馈部分工单业务存在查询处理失败现象,经排查是当前系统通过FeignClient调用下游系统出现部分超时失败(异常代码贴在下方). Caused by: feign.Ret ...
- Centos下安装Maven私服Nexus
dockers安装Nexus,指定访问路径(默认为/:在使用Nginx做反向代理时,最好指定访问路径),并在容器外持久化数据,避免Nexus容器升级后数据丢失. 安装并启动 docker run -d ...
- Flowable实战(八)BPMN2.0 任务
任务是流程中最重要的组成部分.Flowable提供了多种任务类型,以满足实际需求. 常用任务类型有: 用户任务 Java Service任务 脚本任务 业务规则任务 执行监听器 任务监听器 多 ...
- JUC之线程池基础
线程池 定义和方法 线程池的工作时控制运行的线程数量,处理过程中将任务放入队列,然后在线程创建后启动这些任务,如果线程数量超过了最大数量,超出数量的线程排队等候,等待其他线程执行完成,再从队列中取出任 ...
- RHCSA 第七天
1.创建文件,并赋予权限611(两种方式,一种guoa,一种nnn) 2.创建目录,并赋予权限755(两种方式,一种guoa,一种nnn) 3.创建文件,并将文件的属主和属组修改其他用户 4.设置su ...
- java日志打印使用指南
一.简介 日志打印是java代码开发中不可缺少的重要一步. 日志可以排查问题,可以搜集数据 二.常用日志框架 比较常用的日志框架就是logback, 一些老项目会使用log4j,他们用的都是slf4j ...
- 【刷题-LeetCode】236. Lowest Common Ancestor of a Binary Tree
Lowest Common Ancestor of a Binary Tree Given a binary tree, find the lowest common ancestor (LCA) o ...
- Cesium1.70-介绍CesiumOSM建筑新特性
Cesium中文网:http://cesiumcn.org/ | 国内快速访问:http://cesium.coinidea.com/ 我们很高兴宣布Cesium OSM建筑,一个覆盖整个世界的3D建 ...
- [WAF攻防]从WAF攻防角度重看sql注入
从WAF攻防角度重看sql注入 攻防都是在对抗中逐步提升的,所以如果想攻,且攻得明白,就必须对防有深刻的了解 sql注入的大体流程 Fuzz测试找到注入点 对注入点进行过滤检测,及WAF绕过 构建pa ...
- update(修改,DML语句) 和 delete(删除数据,DML语句)
7.7.修改update(DML) 语法格式: update 表名 set 字段名1=值1,字段名2=值2,字段名3=值3....where 条件; 注意:没有条件限制会导致所有数据全部更新 upda ...