HiveServer2的负载均衡高可用与ActicePassive高可用浅析
负载均衡的高可用
最近在工作中遇到了hiveserver2需要部署高可用的场景,去网上搜索了解过后,用了绝大多数人推荐的共同方法:
| Property_name | Property_value | Description |
|---|---|---|
| hive.server2.support.dynamic.service.discovery | true(默认false) | 使hiveserver2服务可被动态发现 |
| hive.server2.zookeeper.namespace | hiveserver2(默认值) | hiveserver2实例在zk中注册的znode名 |
| hive.zookeeper.client.port | 2181(默认值) | zk端口 |
| hive.zookeeper.quorum | zk1:2181,zk2:2181,zk3:2181(默认空) | zk集群连接方式 |
当如上配置后,启动的hiveserver2实例都会注册到zk的/hiveserver2节点下,如下所示
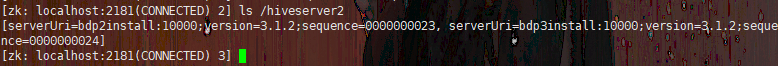
get一下其中一个实例,就会发现它包含了这个hs2的uri、端口号等连接配置,如下所示

此时用客户端(如beeline)连接hs2时,url需使用
jdbc:hive2://zk1:2181,zk2:2181,zk3:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2
此时zk会随机从多个实例中随机拿一个实例供连接使用,过程在代码中体现如下:
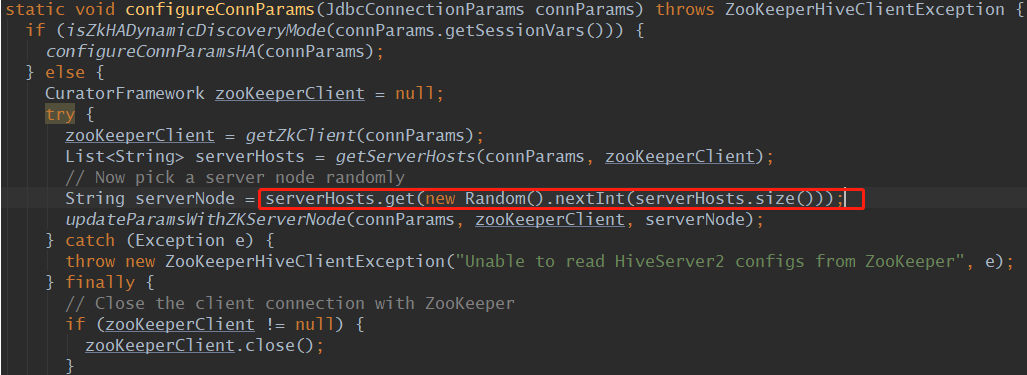
先去指定的znode(/hiveserver2)下拿到所有实例,再通过Random随机拿其中一个去连接;也正因为这个随机的过程,此种方式的hs2高可用一定程度上实现了hiveserver2的负载均衡。
问题
但这种方式的高可用在使用中存在一个问题,即当你同时开启了鉴权的服务(如ranger),hs2在启动时不仅会注册hs2的实例,还会注册一个leader节点,如下所示

从图中可以看出,leader节点下有两个子节点,而每个子节点实际没有任何内容,因为这个leader节点在此处没有用处。
但因为leader节点的存在,使上面讲的随机拿的过程中就可能会拿到这个leader节点,而该节点实际不是有效的hs2实例,故此时连接会报错“Unable to read HiveServer2 configs from ZooKeeper”.
那么Leader节点为什么会产生呢?我们看下源码里对应的部分

而目前还没有发现leader节点的具体作用,只会在从zk拿实例时徒增报错。
为了解决此问题,我重新编译了hive-jdbc的源码,在从zk拿实例的过程中过滤掉了leader节点。
能解决此问题的,还有另一种方式,即配置ActivePassiveHA。
ActivePassiveHA
探究源码过程中,发现hive还提供了另一种高可用方案,即ActivePassiveHA,开启需如下配置:
| Property_name | Property_value | Description |
|---|---|---|
| hive.server2.support.dynamic.service.discovery | true(默认false) | 使hiveserver2服务可被动态发现 |
| hive.server2.active.passive.ha.enable | true(默认false) | ActivePassiveHA启用 |
| hive.server2.active.passive.ha.registry.namespace | hs2ActivePassiveHA(默认值) | hiveserver2实例及leader在zk中注册的znode名 |
| hive.zookeeper.quorum | zk1:2181,zk2:2181,zk3:2181(默认空) | zk集群连接方式 |
| hive.zookeeper.client.port | 2181(默认值) | zk端口 |
当如上配置后,启动的hiveserver2实例都会注册到zk的/hs2ActivePassiveHA节点下,如下所示

由图可见,其本质还是和上面类似的注册实例的过程相似,但注册的实例统一放在了instances下面,且注册时信息更详细;而单独产生的_LEADER节点则将两个实例中的registry.unique.id拿出单独放置。(hs2ActivePassiveHA后的unsecure或secure是根据是否开启身份验证或鉴权后自动添加的)
而ActivePassiveHA和上述高可用方案最大的区别,就是通过_LEADER节点分配可连接实例中的"leader"和"worker",当leader没有挂掉的时候,所有通过zk连接到hs2的连接都会指向leader节点,而不会连接到其他节点,与上述高可用方案的随机方式有一定区别。
此时,连接的url需使用
jdbc:hive2://zk1:2181,zk2:2181,zk3:2181/;serviceDiscoveryMode=zooKeeperHA;zooKeeperNamespace=hs2ActivePassiveHA
这种高可用方案同时解决了另一个问题:java.lang.NoClassDefFoundError: org/apache/tez/dag/api/TezConfiguration,如下所示
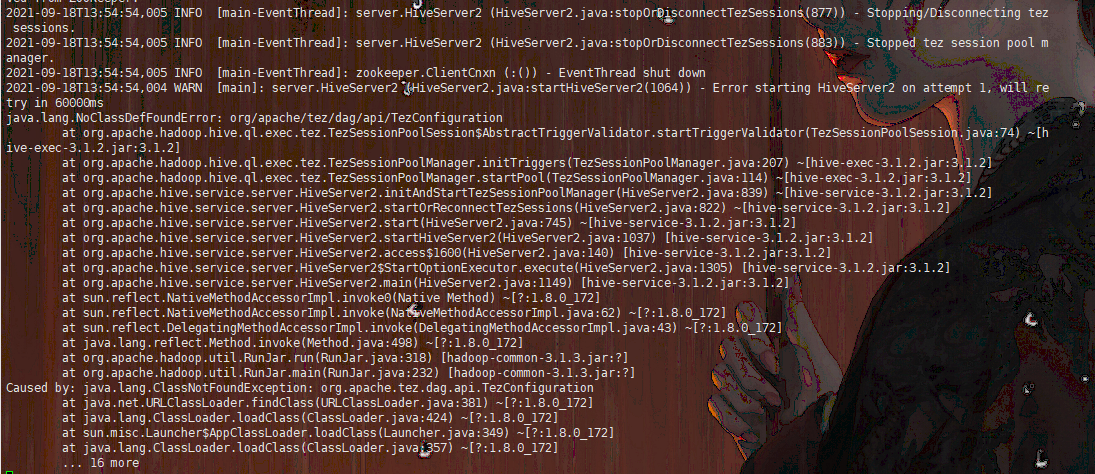
这问题出现在hs2启动过程中,因为对hive3来说mr引擎已经是过时的,所以无论你的hive执行引擎选的是什么,都会在启动hs2时自动启动一个TezSession,但如果你在hive-env.sh中没有配置tez包的位置,这里就会报ClassNotFound,并且强制等待60s后重试,重试后不管成功还是失败都会继续向下执行,不影响正常启动,但拖慢了hs2启动的时间。本来十几秒就能解决的事非要等待一分多钟才行。
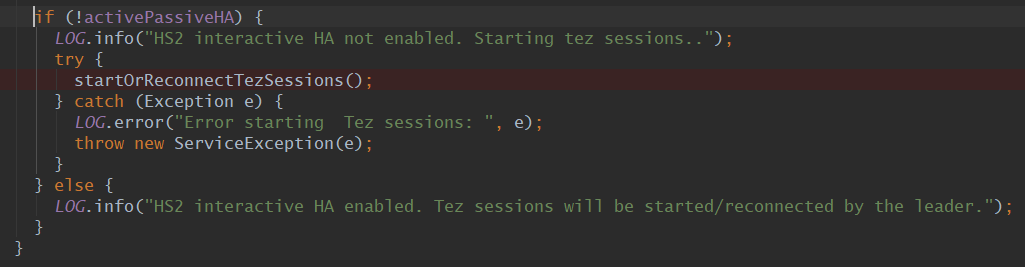
但当开启了ActicePassiveHA后,这个启动TezSession的过程就会变成此处暂不启动,后续由leader自行启动,代码如下:
问题
此种高可用方案在hive官网和网络上的帖子中几乎没有被提及,是在hs2启动时跟源码发现的,目前发现存在一些问题:
- 此种方式的高可用在leader节点没有挂掉的情况下会始终连接leader节点,只有在leader不可用时才会自动切换,类似hadoop的Actice/Standby方案,但这样只能做到故障切换,没有做到负载均衡(这种方式在代码中是否有另外一套负载均衡的机制还有待探究)
- url中serviceDiscoveryMode=zooKeeperHA的连接方式不被一些鉴权服务所支持(如ranger)
以上就是我在探究hiveserver2高可用的过程当积累的一些心得,在此记录一下,希望对大家有所帮助。如内容有错误敬请补充或指正
HiveServer2的负载均衡高可用与ActicePassive高可用浅析的更多相关文章
- 浅谈web应用的负载均衡、集群、高可用(HA)解决方案(转)
1.熟悉几个组件 1.1.apache —— 它是Apache软件基金会的一个开放源代码的跨平台的网页服务器,属于老牌的web服务器了,支持基于Ip或者域名的虚拟主机,支持代理服务器,支持安 ...
- keepalived+LVS 实现双机热备、负载均衡、失效转移 高性能 高可用 高伸缩性 服务器集群
本章笔者亲自动手,使用LVS技术实现实现一个可以支持庞大访问量.高可用性.高伸缩性的服务器集群 在读本章之前,可能有不少读者尚未使用该技术,或者部分读者使用Nginx实现应用层的负载均衡.这里大家都可 ...
- nginx实现请求的负载均衡 + keepalived实现nginx的高可用
前言 使用集群是网站解决高并发.海量数据问题的常用手段.当一台服务器的处理能力.存储空间不足时,不要企图去换更强大的服务器,对大型网站而言,不管多么强大的服务器,都满足不了网站持续增长的业务需求.这种 ...
- 浅谈web应用的负载均衡、集群、高可用(HA)解决方案
http://aokunsang.iteye.com/blog/2053719 声明:以下仅为个人的一些总结和随写,如有不对之处,还请看到的网友指出,以免误导. (详细的配置方案请google,这 ...
- web应用的负载均衡、集群、高可用(HA)解决方案
看看别人的文章: 1.熟悉几个组件 1.1.apache —— 它是Apache软件基金会的一个开放源代码的跨平台的网页服务器,属于老牌的web服务器了,支持基于Ip或者域名的虚拟主机,支持代 ...
- Nginx配置upstream实现负载均衡及keepalived实现nginx高可用
(原文链接:http://www.studyshare.cn/blog-front//blog/details/1159/0 ) 一.准备工作 1.准备两个项目,发布到不同的服务器上,此处使用2个虚拟 ...
- Nginx实现负载均衡 + Keepalived实现Nginx的高可用
前言 使用集群是大中型网站解决高并发.海量数据问题的常用手段.当一台服务器的处理能力.存储空间不足时,不要企图去换更强大的服务器,对大型网站而言,不管多么强大的服务器,都满足不了网站持续增长的业务需求 ...
- 配置LVS + Keepalived高可用负载均衡集群之图文教程
负载均衡系统可以选用LVS方案,而为避免Director Server单点故障引起系统崩溃,我们可以选用LVS+Keepalived组合保证高可用性. 重点:每个节点时间都同步哈! C++代码 [r ...
- Net分布式系统之三:Keepalived+LVS+Nginx负载均衡之高可用
上一篇写了nginx负载均衡,此篇实现高可用(HA).系统整体设计是采用Nginx做负载均衡,若出现Nginx单机故障,则导致整个系统无法正常运行.针对系统架构设计的高可用要求,我们需要解决Nginx ...
随机推荐
- 刷了无数大厂Android研发岗面试题,其实考的无非是这 3 点能力
前言 发现一个有趣的现象,似乎程序员们对面试题总是抱有热情,多看几道面试题,自己的面试能力就可以提高一点. 作为一个研发工程师,看过很多公司的面试题,也参与过很多公司的面试,发现大厂的面试题更加具有代 ...
- IntelliJ IDEA 中为Maven 配置阿里云镜像源
idea中查看位置,应该都是一样的这个位置 在此位置下新建一个.xml文件 内容如下: <?xml version="1.0" encoding="UTF-8&qu ...
- HDFS中NameNode工作机制
引言 NameNode: 存储元数据 管理整个HDFS集群 DataNode: 存储数据的block SecondaryNameNode: 辅助HDFS完成一些事情 NameNode和Secondar ...
- MapReduce框架-Join的使用
引言 首先先明白在关系型数据库中Join的用法. Join在MapReduce中的用法也是用于两个文件之间的连接. 使用MR程序解决两张表的join问题,有两种解决方案 à MR程序的join应用 1 ...
- flink clickhouse-jdbc和flink-connector 写入数据到clickhouse因为jar包冲突导致的60 seconds.Please check if the requested resources are available in the YARN cluster和Could not resolve ResourceManager address akka报错血案
一.问题现象,使用flink on yarn 模式,写入数据到clickhouse,但是在yarn 集群充足的情况下一直报:Deployment took more than 60 seconds. ...
- [NumPy]文件的保存和加载
如果想看.ipynb文件,那就借一步说话!
- Solution of Cobertura Exception "touchJump" when Unit Test
During unit test I encounter a "java.lang.NoSuchMethodError: net.sourceforge.cobertura.coverage ...
- Http协议中的CharacterEncoding、Content-Encoding和Transfer-Encoding
https://www.cnblogs.com/jinzhiming/p/5765672.html https://www.jianshu.com/p/e918a65b617f https://www ...
- Redis雪崩和Redis穿透
Redis雪崩:查询时Redis没有数据 本来先从Redis里面查某个数据 但是Redis中这个数据刚好被删除了,还没来得及更新 一瞬间很多请求直接进入了Mysql进行查询 而mysql承受不了太大压 ...
- shell 获取当前路径 和 2>&1 &的作用
#!/bin/bash current_path=$(cd $(dirname "${BASH_SOURCE[0]}") && pwd) nohup $curren ...