10: java数据结构和算法: 构建哈夫曼树, 获取哈夫曼编码, 使用哈夫曼编码原理对文件压缩和解压
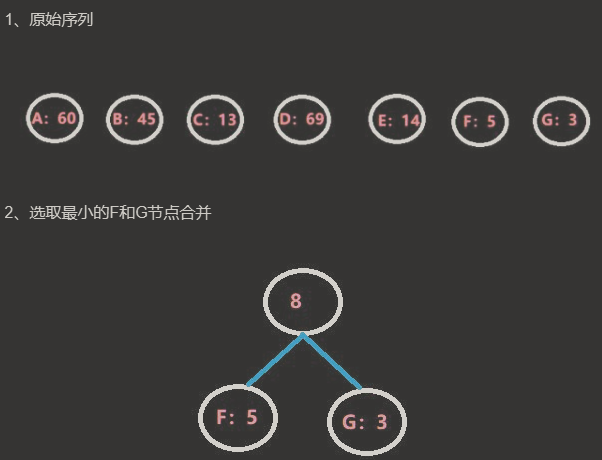

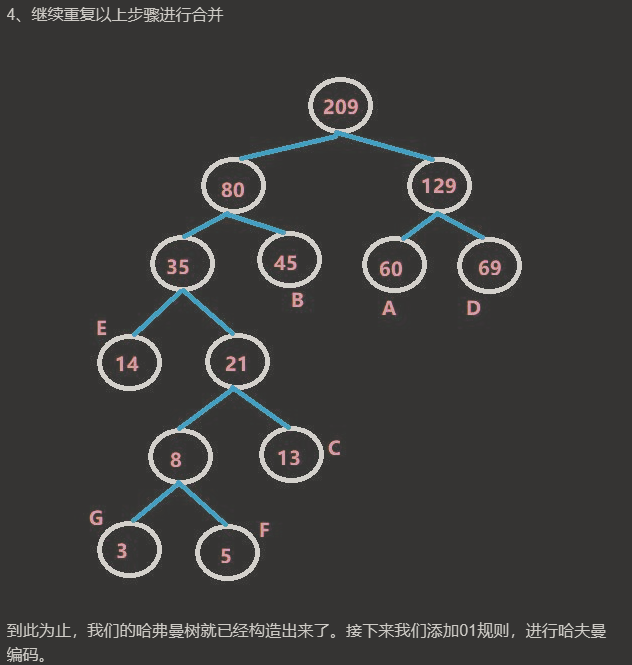
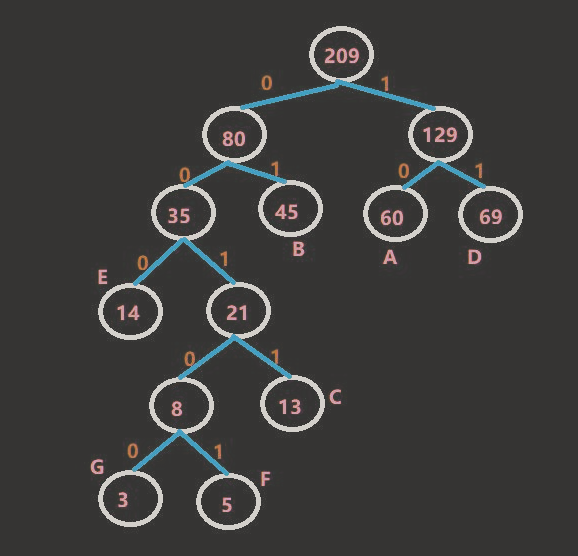
最终结果哈夫曼树,如图所示:
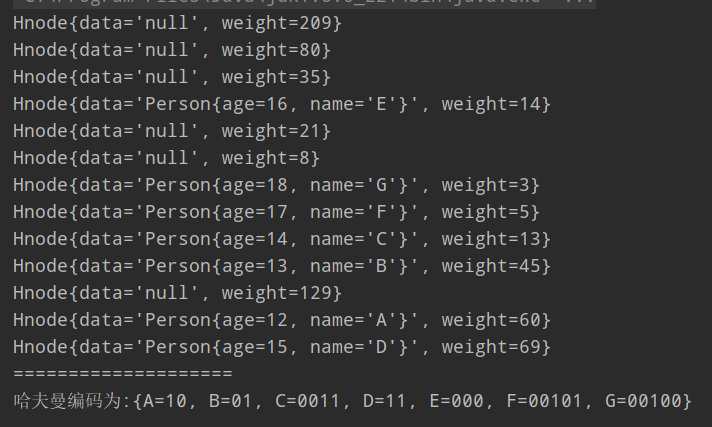
直接上代码:
public class HuffmanCode {
public static void main(String[] args) {
//获取哈夫曼树并显示
Hnode root = createHuffmanTree(createNodes());
root.beforePrint();
System.out.println("====================");
//从哈夫曼树中读取 哈夫曼编码
getHuffmanCode(root);
//从huffmanCodes 中读取哈夫曼编码:A:10, B:01, C:0011,D:11,E:000,F:00100,G:00101
System.out.println("哈夫曼编码为:"+huffmanCodes);
}
//创建一个 Hnode节点的集合
public static List<Hnode> createNodes(){
List<Hnode> nodes = new ArrayList<Hnode>();
nodes.add(new Hnode(new Person(12,"A"),60));
nodes.add(new Hnode(new Person(13,"B"),45));
nodes.add(new Hnode(new Person(14,"C"),13));
nodes.add(new Hnode(new Person(15,"D"),69));
nodes.add(new Hnode(new Person(16,"E"),14));
nodes.add(new Hnode(new Person(17,"F"),5));
nodes.add(new Hnode(new Person(18,"G"),3));
return nodes;
}
//根据list 创建哈夫曼树
public static Hnode createHuffmanTree(List<Hnode> nodes){
while(nodes.size() > 1){
//先对 nodes进行从小到大排序, 根据权重值进行从小到大排序
Collections.sort(nodes, new Comparator<Hnode>() {
public int compare(Hnode o1, Hnode o2) {
return o1.weight - o2.weight;
}
});
//取出前二个最小的元素,构建一个父节点只有权重 没有数据的二叉树
Hnode leftNode = nodes.get(0);
Hnode rightNode = nodes.get(1);
Hnode parent = new Hnode(null, leftNode.weight + rightNode.weight);
parent.leftNode = leftNode;
parent.rightNode = rightNode;
//将原来nodes中已经处理的前二个最小元素删除调,并将parent节点存入nodes中
nodes.remove(leftNode);
nodes.remove(rightNode);
nodes.add(parent);
}
//循环结束时候,nodes中只有一个节点了,且该节点就是哈夫曼树的根节点
return nodes.get(0);
}
static StringBuilder stringBuilder = new StringBuilder();
static Map<String,String> huffmanCodes = new HashMap<String, String>();
//从哈夫曼树中读取 哈夫曼编码: A:10, B:01, C:0011,D:11,E:000,F:00100,G:00101
public static void getHuffmanCode(Hnode root){
if (root == null) {
return ;
}
getCode(root.leftNode,"0",stringBuilder);
getCode(root.rightNode,"1",stringBuilder);
}
private static void getCode(Hnode node, String code, StringBuilder builder) {
StringBuilder builder1 = new StringBuilder(builder);
builder1.append(code);
if (node != null) {
if (node.person == null) {
//如果数据为不null,说明是子节点
//左递归处理
getCode(node.leftNode,"0",builder1);
//右递归处理
getCode(node.rightNode,"1",builder1);
}else{
//如果数据为null,说明是叶子节点
huffmanCodes.put(node.person.name,builder1.toString());
}
}
}
}
//先建节点
class Hnode{
Person person;//数据
int weight;//权重
Hnode leftNode;
Hnode rightNode;
public Hnode(Person person, int weight) {
this.person = person;
this.weight = weight;
}
@Override
public String toString() {
return "Hnode{" +
"data='" + person + '\'' +
", weight=" + weight +
'}';
}
//前序遍历
public void beforePrint(){
System.out.println(this);
if (this.leftNode != null) {
this.leftNode.beforePrint();
}
if (this.rightNode != null) {
this.rightNode.beforePrint();
}
}
}
class Person {
int age;
String name;
public Person(int age, String name) {
this.age = age;
this.name = name;
}
@Override
public String toString() {
return "Person{" +
"age=" + age +
", name='" + name + '\'' +
'}';
}
}
结果如下:
压缩原理:
1: 被压缩文件通过输入流,转化为原始字节数组, 遍历统计每个字节出现的次数,并转化为map, key:字节,value:该字节的次数
2: map 转化为list,根据list创建 哈夫曼树,并获取到对应的哈夫曼编码
3: 将哈夫曼编码转化字节数组,通过输出流,写入到目标文件中,同时将哈夫曼编码也写入到目标文件中(目的:是为了解码使用)
解压缩原理:
1: 通过输入流从被解压缩文件中,读取到哈夫曼编码,和 哈夫曼编码转化字节数组,
2: 解码 得到原始字节数组, 并将数组写出到目标文件中
10: java数据结构和算法: 构建哈夫曼树, 获取哈夫曼编码, 使用哈夫曼编码原理对文件压缩和解压的更多相关文章
- Java数据结构和算法(七)B+ 树
Java数据结构和算法(七)B+ 树 数据结构与算法目录(https://www.cnblogs.com/binarylei/p/10115867.html) 我们都知道二叉查找树的查找的时间复杂度是 ...
- java 文件压缩和解压(ZipInputStream, ZipOutputStream)
最近在看java se 的IO 部分 , 看到 java 的文件的压缩和解压比较有意思,主要用到了两个IO流-ZipInputStream, ZipOutputStream,不仅可以对文件进行压缩,还 ...
- java文件压缩和解压
功能实现. package com.test; import java.io.File; import java.io.BufferedOutputStream; import java.io.Buf ...
- Java数据结构和算法(四)赫夫曼树
Java数据结构和算法(四)赫夫曼树 数据结构与算法目录(https://www.cnblogs.com/binarylei/p/10115867.html) 赫夫曼树又称为最优二叉树,赫夫曼树的一个 ...
- Java数据结构和算法 - 二叉树
前言 数据结构可划分为线性结构.树型结构和图型结构三大类.前面几篇讨论了数组.栈和队列.链表都是线性结构.树型结构中每个结点只允许有一个直接前驱结点,但允许有一个以上直接后驱结点.树型结构有树和二叉树 ...
- 【Java数据结构学习笔记之二】Java数据结构与算法之栈(Stack)实现
本篇是java数据结构与算法的第2篇,从本篇开始我们将来了解栈的设计与实现,以下是本篇的相关知识点: 栈的抽象数据类型 顺序栈的设计与实现 链式栈的设计与实现 栈的应用 栈的抽象数据类型 栈是 ...
- Java数据结构和算法(九)——高级排序
春晚好看吗?不存在的!!! 在Java数据结构和算法(三)——冒泡.选择.插入排序算法中我们介绍了三种简单的排序算法,它们的时间复杂度大O表示法都是O(N2),如果数据量少,我们还能忍受,但是数据量大 ...
- java数据结构与算法之栈(Stack)设计与实现
本篇是java数据结构与算法的第4篇,从本篇开始我们将来了解栈的设计与实现,以下是本篇的相关知识点: 栈的抽象数据类型 顺序栈的设计与实现 链式栈的设计与实现 栈的应用 栈的抽象数据类型 栈是一种用于 ...
- Java数据结构和算法 - 高级排序
希尔排序 Q: 什么是希尔排序? A: 希尔排序因计算机科学家Donald L.Shell而得名,他在1959年发现了希尔排序算法. A: 希尔排序基于插入排序,但是增加了一个新的特性,大大地提高了插 ...
随机推荐
- 基于frida框架Hook native中的函数(1)
作者:H01mes撰写的这篇关于frida框架hook native函数的文章很不错,值得推荐和学习,也感谢原作者. 0x01 前言 关于android的hook以前一直用的xposed来hook j ...
- Day009 面向对象和方法回顾
面向过程&面向对象 面向过程思想 步骤清晰简单,第一步做什么,第二步做什么..... 面象过程适合处理一些较为简单的问题 面向对象思想 物以类聚,分类的思维模式,思考问题首先会解决问题需要哪些 ...
- web scraper
参考:https://sspai.com/u/skychx/updates https://www.jianshu.com/p/76cad8e963b5 :nth-of-type(-n+100) 元素 ...
- java基础——循环结构
循环结构 while 循环 只要表达式成立,循环就一直持续 我们大多数情况会让循环停下来,我们需要一个让表达式失效的方式,来结束循环 public static void main(String ...
- 使用基于centos7 dbus问题总结
Authorization not available. Check if polkit Authorization not available. Check if polkit service is ...
- [Linux] 完全卸载mysql
参考 https://www.jianshu.com/p/ef58fb333cd6
- SecureCRT自动保存日志设置
SecureCRT自动保存日志设置原创杭州_燕十三 最后发布于2017-03-26 22:00:08 阅读数 24731 收藏展开 嵌入式开发经常由于无法debug而只能使用串口打印日志的方式调试代码 ...
- Spark 集群安装部署
安装准备 Spark 集群和 Hadoop 类似,也是采用主从架构,Spark 中的主服务器进程就叫 Master(standalone 模式),从服务器进程叫 Worker Spark 集群规划如下 ...
- Linux进阶之Linux破解密码、yum源配置、防火墙设置及源码包安装
一.老师语录: 所有要求笔试的公司都是垃圾公司 笔试(是考所有的涉及到的点) 要有自己的卖点.专长(给自己个标签)(至少一个) 生产环境中,尽量使用mv(mv到一个没用的目录下),少使用rm 二.防火 ...
- 自己封装的mysql应用类示例
from pymysql import *class my_mysql_mud(object): def __init__(self,host,port,db,user,passwd,charset= ...