Flask中本地栈的使用

4种上下文变量
承接上一篇内容。当一个请求到来时,除了request被封装成全局变量之外,还有三个变量也是同样被封装成全局变量,那就是current_app、g、session。上面4个变量之所以能够使用,是因为程序上下文生效了。
上下文这个概念非常常见,比如在进程切换时时会保存当前进程的上下文,恢复活动进程的上下文。我见过对上下文对通透的解释就是说所谓上下文就是运行环境,恢复上下文就是恢复运行环境。
在Flask中有两种上下文:程序上下文和请求上下文。当一个请求到来时,Flask会激活这两种上下文,其中request就是在请求上下文中获取。
| 变量名 | 上下文 | 说明 |
|---|---|---|
| current_app | 应用上下文 | 当前激活程序的程序实例 |
| g | 应用上下文 | 处理请求时用作临时存储的对象。每次请求都会重设这个变量 |
| request | 请求上下文 | 请求对象,封装了客户端发出的HTTP请求中的内容 |
| session | 请求上下文 | 用户会话,用于存储请求之间需要“记住”的字典 |
上下文在请求中的生命周期
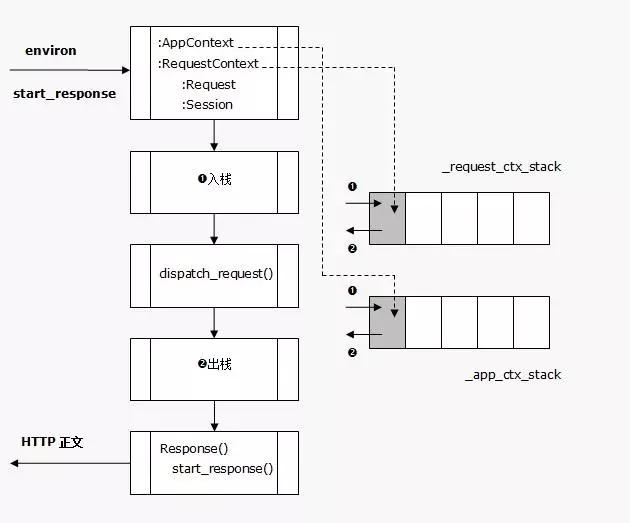
Flask在分发请求之前将程序上下文(AppContext)压入应用本地栈中,将请求上下文(RequestContext)压入请求本地栈中。请求处理完成后再将两个上下文分别出栈。
程序上下文被入栈后,就可以在视图函数中使用current_app和g变量;类似的,请求上下文被推送后,就可以使用request和session变量。
具体来说:请求上下文保存在_request_ctx_stack,程序上下文保存在 _app_ctx_stack。当一个请求到来时,请求上下文对象RequestContext,程序上下文对象AppContext都会相应入栈。
Flask经典错误
如果我们没有激活程序上下文或请求上下文就使用这些变量会导致一个Flask的经典错误。
RuntimeError: Working outside of application context.
比如:
from flask import Flask, current_app
app = Flask(__name__)
print(current_app.name)
在上面的示例中打印current_app的名字,但是并没有在视图函数中,也就是说没有请求到来。那么这一段程序就会报错:
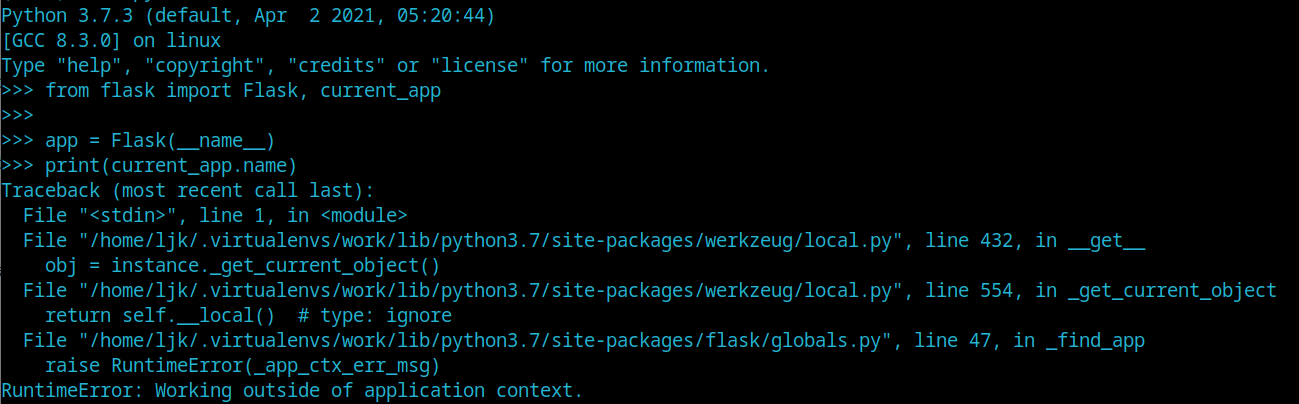
这就是因为current_app必须是要在请求到来时,请求上下文和程序上下文都激活之后才能使用。上面一段代码没有请求到来,所以current_app不能使用。
手动压栈程序上下文
为了能够在没有请求到来也能使用Flask项目的配置,文件等,可以手动将程序上下文入栈。
from flask import Flask, current_app
app = Flask(__name__)
with app.app_context():
print(current_app)
print(current_app.config) # 打印flask项目的配置
<Flask 'manual_push'>
<Config {'ENV': 'production', 'DEBUG': False, 'TESTING': False, 'PROPAGATE_EXCEPTIONS': None, 'PRESERVE_CONTEXT_ON_EXCEPTION': None, 'SECRET_KEY': None, 'PERMANENT_SESSION_LIFETIME': datetime.timedelta(days=31), 'USE_X_SENDFILE': False, 'SERVER_NAME': None, 'APPLICATION_ROOT': '/', 'SESSION_COOKIE_NAME': 'session', 'SESSION_COOKIE_DOMAIN': None, 'SESSION_COOKIE_PATH': None, 'SESSION_COOKIE_HTTPONLY': True, 'SESSION_COOKIE_SECURE': False, 'SESSION_COOKIE_SAMESITE': None, 'SESSION_REFRESH_EACH_REQUEST': True, 'MAX_CONTENT_LENGTH': None, 'SEND_FILE_MAX_AGE_DEFAULT': None, 'TRAP_BAD_REQUEST_ERRORS': None, 'TRAP_HTTP_EXCEPTIONS': False, 'EXPLAIN_TEMPLATE_LOADING': False, 'PREFERRED_URL_SCHEME': 'http', 'JSON_AS_ASCII': True, 'JSON_SORT_KEYS': True, 'JSONIFY_PRETTYPRINT_REGULAR': False, 'JSONIFY_MIMETYPE': 'application/json', 'TEMPLATES_AUTO_RELOAD': None, 'MAX_COOKIE_SIZE': 4093}>
请求上下文和程序上下文为什么要分开
在flask0.1中请求上下文和程序上下文是在同一个栈中保存,为什么后面分离开来?
是为了非 web 应用的场合。所谓非web应用场合就是没有请求到来时,也需要使用程序上下文的场景,典型代表就是flask shell。在处理一些数据库导入,脚本等场景时没有网络请求到来,也就没有请求上下文和程序上下文。所以current_app不可使用,如配置信息、orm数据库等都不可使用。为了能够在没有请求到来的场景下使用程序上下文,所以将程序上下文和请求上下文分开,然后使用手动入栈程序上下文的方式来方便的使用flask提供的功能。也就是上面分析的手动入栈。
为什么用栈来保存上下文对象
学到这里时我其实有一个疑问,为什么请求上下文对象和程序上下文对象要用本地栈来保存呢?用本地线程不可以吗?
网上给出的解释是flask通过中间件同时处理两个app的程序,两个app的请求会同时存在,用本地栈能够让各自请求找到自己的数据。但是根据flask的服务端模型,同一时间,一个线程只处理一个请求,根本不会有多个请求同时被处理的情况,用本地线程也可以保存上下文,那么到底什么原因让flask用本地栈这种数据结构呢?
Flask 处理模型
首先说明flask的服务处理模型
flask 有两种启动模式,分别是单线程和多线程。单线程启动就是请求只在一个线程中处理,当上一个请求没有返回,下一个请求需要等待;多线程请求中每一个请求到来不会被阻塞,会有多个线程提供处理。默认是多线程
单进程
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world(num):
return f"Hello world!"
if __name__ == '__main__':
app.run()
多进程
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world(num):
return f"Hello world!"
if __name__ == '__main__':
app.run(processes=True)
但是不管是多进程启动还是单进程启动,同一个线程同一个时刻只会处理一个请求, 又因为本地线程技术(上一篇有介绍本地线程技术Flask中请求数据的优雅传递)也就是说同一个时刻只有一个request对象,那么为什么flask保存request对象时使用的是本地栈而不是本地线程呢?
这个问题的答案是:当程序上下文手动入栈时,可以入栈多个程序上下文。这样会同时存在多个程序上下文,为了获取正确的程序上下文,需要使用栈这种先进后出的结构。
如果没有明白原因没关系,可以从下面的程序中找到解释。
import time
from flask import Flask, current_app
app1 = Flask('app01')
app2 = Flask('app02')
def do_something():
print("app1 压栈------------------------------------")
with app1.app_context():
time.sleep(5)
print("app2 压栈------------------------------------")
with app2.app_context():
pass # current_app是程序上下文,上一个栈顶元素是app1,当app2被推入时获取的是app2
print("app2 is 出栈-------------------------------------")
# 当app2出栈之后,栈顶元素又变成app1,而这时获取到的又是栈顶元素
do_something()
同时在Flask中程序上下文入栈之后打印了调试信息

当app1入栈后,_app_ctx_stack中只有一个元素,就是app1,这时访问current_app就是app1;
当app2入栈后,_app_ctx_stack中有两个元素,且栈顶是app2。这时访问current_app就是app2;
当app2出栈后,_app_ctx_stack中剩余一个元素,就是app1,这时再访问current_app就是app1。
正是通过这种栈数据结构,让处理函数都是获取自己程序上下文中的current_app。
小结
程序上下文和请求上下文都是保存在本地栈中,因为手动入栈时存在多个上下文环境嵌套,所以需要栈这样的数据结构保持最新的上下文在最先获得。
Flask中本地栈的使用的更多相关文章
- Flask中的ThreadLocal本地线程,上下文管理
先说一下和flask没有关系的: 我们都知道线程是由进程创建出来的,CPU实际执行的也是线程,那么线程其实是没有自己独有的内存空间的,所有的线程共享进程的资源和空间,共享就会有冲突,对于多线程对同一块 ...
- Flask中请求数据的优雅传递
当一个请求到来时,浏览器会携带很多信息发送发送服务端.在Django中,每一个处理函数都要传入一个request的参数,该参数携带所有请求的信息,也就是服务端程序封装的environ(不明白该参数可以 ...
- Flask中全局变量的实现
我们都知道在Flask中g,request,session和request是作为全局对象来提供信息的,既然是全局的又如何保持线程安全呢,接下来我们就看看flask是如何做到这点的.在源码中的ctx.p ...
- Python框架学习之Flask中的视图及路由
在前面一讲中我们学习如何创建一个简单的Flask项目,并做了一些简单的分析.接下来在这一节中就主要来讲讲Flask中最核心的内容之一:Werkzeug工具箱.Werkzeug是一个遵循WSGI协议的P ...
- Python直接改变实例化对象的列表属性的值 导致在flask中接口多次请求报错
错误原理实例如下: class One(): list = [1, 2, 3] @classmethod def get_copy_list(cls): # copy一份list,这样对list的改变 ...
- 深入flask中的request
缘起 在使用flask的时候一直比较纳闷request是什么原理,他是如何保证多线程情况下对不同请求参数的隔离的. 准备知识 在讲request之前首先需要先理解一下werkzeug.local中的几 ...
- flask中的蓝图与红图
内容: 1.flask中的蓝图 2.flask子域名实现 3.flask中的红图 1.flask中的蓝图 一个大型项目中视图比较多,如果仅仅是写在app.py中不方便管理,蓝图就可以做到分功能分目录结 ...
- Flask(2)- 装饰器的坑及解决办法、flask中的路由/实例化配置/对象配置/蓝图/特殊装饰器(中间件、重定义错误页面)
一.装饰器的坑以及解决方法 1.使用装饰器装饰两个视图函数,代码如下 from flask import Flask, redirect, render_template, request, sess ...
- flask中cookie和session介绍
flask中cookie和session介绍 一.cookie: 在网站中,http请求是无状态的.也就是说即使第一次和服务器连接后并且登录成功后,第二次请求服务器依然不能知道当前请求是哪个用户.co ...
随机推荐
- 软件开发架构与网络之OSI七层协议(五层)
本期内容概要 python回顾 软件开发架构 网络理论前瞻 osi七层协议(五层) 以太网协议 IP协议 port协议 交换机 路由器 局域网 广域网 TCP协议 三次握手 四次挥手 UDP协议 内容 ...
- 读《疯狂Java讲义》笔记总结二
1.变量分类图 2.通过实例访问静态变量(类变量) 3.静态导入 4.构造器 5.创建对象内存过程
- leetcode 83. 删除排序链表中的重复元素 及 82. 删除排序链表中的重复元素 II
83. 删除排序链表中的重复元素 问题描述 给定一个排序链表,删除所有重复的元素,使得每个元素只出现一次. 示例 1: 输入: 1->1->2 输出: 1->2 示例 2: 输入: ...
- (2)用Micropython将ESP32数据上云
之前我们尝试过直接把LED点亮并且闪烁. 今天尝试一下将LED的开关状态上云,并可以通过云来进行数据下发. 数据要上云,首先开发板要联网. 首先我们会用 Python的network 库, 在netw ...
- CesiumJS新增官方TypeScript类型定义
Cesium中文网:http://cesiumcn.org/ | 国内快速访问:http://cesium.coinidea.com/ 在当前的1.70版本中,CesiumJS现在附带了正式的Type ...
- vue学习4-class和sytle绑定
#### Class绑定: 1. 通过数组的方式来实现: 2. 通过对象的方式来实现: 通过对象: 通过数组,通过数组是把多个style样式对象添加进去:
- VUE3 之 Non-Props 属性
1. 概述 墨菲定律告诉我们:人总是容易犯错误的,无论科技发展到什么程度,无论是什么身份的人,错误总是会在不经意间发生.因此我们最好在做重要的事情时,尽量去预估所有可能发生的错误,并思考错误发生后的补 ...
- listen()和accept()
1.listen()队列剖析 作用:监听端口,TCP连接中的服务器端角色 调用格式:int listen(int sockfd, int backlog); 第一个参数:创建的sockfd, 好好理解 ...
- gin中如何记录日志和错误日志
package main import ( "github.com/gin-gonic/gin" "io" "os" ) func main ...
- Servlet-斜杠在web中不同意义
Servlet-斜杠在web中不同意义 在web中 / 斜杠是一种绝对路径 / 斜杠 如果被浏览器解析,得到的地址是:http://ip/port/ / 斜杠 如果被服务器解析,得到的地址是:http ...