Hive之同比环比的计算
Hive系列文章
- Hive表的基本操作
- Hive中的集合数据类型
- Hive动态分区详解
- hive中orc格式表的数据导入
- Java通过jdbc连接hive
- 通过HiveServer2访问Hive
- SpringBoot连接Hive实现自助取数
- hive关联hbase表
- Hive udf 使用方法
- Hive基于UDF进行文本分词
- Hive窗口函数row number的用法
- 数据仓库之拉链表
关注公众号:
大数据技术派,回复:资料,领取1024G资料。
同比环比的计算
测试数据
1,2020-04-20,4202,2020-04-04,8003,2020-03-28,5004,2020-03-13,1005,2020-02-27,3006,2020-01-07,4507,2019-04-07,8008,2019-03-15,12009,2019-02-17,20010,2019-02-07,60011,2019-01-13,300
CREATE TABLE ods_saleorder (order_id int ,order_time date ,order_num int)ROW FORMAT DELIMITEDFIELDS TERMINATED BY ',';LOAD DATA LOCAL INPATH '/Users/liuwenqiang/workspace/hive/saleorder.txt' OVERWRITE INTO TABLE ods.ods_saleorder;
销售量的月年占比
关联实现
selecta.m_num,a.cmonth,b.y_num,b.cyear,round( m_num / y_num, 2 ) AS ratiofrom(selectsum(order_num) as m_num,DATE_FORMAT(order_time,'yyyy-MM') as cmonthfromods_saleordergroup byDATE_FORMAT(order_time,'yyyy-MM')) ainner join(selectsum(order_num) as y_num,DATE_FORMAT(order_time,'yyyy') as cyearfromods_saleordergroup byDATE_FORMAT(order_time,'yyyy')) bonsubstring(a.cmonth,1,4)=b.cyear;
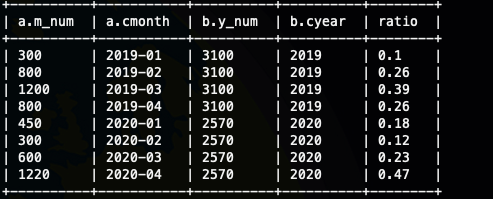
窗口实现
SELECTorder_month,num,total,round( num / total, 2 ) AS ratioFROM(selectsubstr(order_time, 1, 7) as order_month,sum(order_num) over (partition by substr(order_time, 1, 7)) as num,sum(order_num) over (partition by substr( order_time, 1, 4 ) ) total,row_number() over (partition by substr(order_time, 1, 7)) as rkfrom ods_saleorder) tempwhere rk = 1;
同比环比
与上年度数据对比称"同比",与上月数据对比称"环比"。
相关公式如下:
同比增长率计算公式(当年值-上年值)/上年值x100%环比增长率计算公式(当月值-上月值)/上月值x100%
lead lag 的实现
这里我们就用环比做个例子,同比类似
selectnow_month,now_num,last_num,round( (now_num-last_num) / last_num, 2 ) as ratioFROM(selectnow_month,now_num,lag( t1.now_num, 1) over (order by t1.now_month ) as last_numfrom(selectsubstr(order_time, 1, 7) as now_month,sum(order_num) as now_numfrom ods_saleordergroup bysubstr(order_time, 1, 7)) t1) t2;
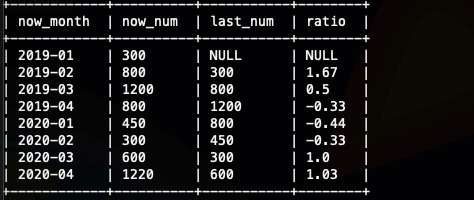
我们看到有null 值,这里我们可以使用,lag的默认值做一次优化
selectnow_month,now_num,last_num,-- 分母是0的话返回值是nullnvl(round( (now_num-last_num) / last_num, 2 ),0)as ratioFROM(selectnow_month,now_num,lag( t1.now_num, 1,0) over (order by t1.now_month ) as last_numfrom(selectsubstr(order_time, 1, 7) as now_month,sum(order_num) as now_numfrom ods_saleordergroup bysubstr(order_time, 1, 7)) t1) t2;
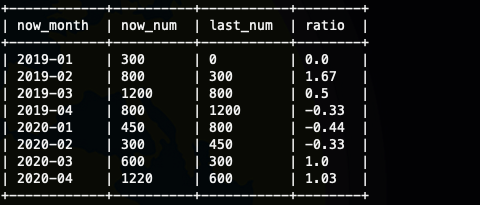
其实到这里我们就处理完了,但是这样真的对吗,我们看到'2020-01' 的last_num 是800 也就是'2019-04',其实到这里我们就明白了,我们的数据是不连续的,所以我们这样计算是不行的,如果每个月都齐全,都有数据lag(num,12)就可以。
那就只能做自关联了,这样的话我们可以对时间做精准的限制
自关联的实现
with a as (selectnow_month,now_num,substr(date(concat(now_month,'-','01')) - INTERVAL '1' month, 1, 7) as last_monthfrom(selectsubstr(order_time, 1, 7) as now_month,sum(order_num) as now_numfrom ods_saleordergroup bysubstr(order_time, 1, 7)) tmp)selecta1.now_month,a1.now_num,a1.last_month,a2.now_num,nvl(round( (a1.now_num-a2.now_num) / a2.now_num, 2 ),0) as ratiofroma a1inner joina a2ona1.last_month=a2.now_month;
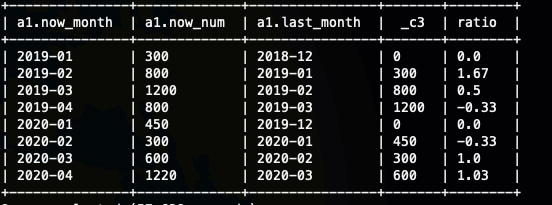
这里的时间计算INTERVAL 你也可以换成其他函数
with a as (selectnow_month,now_num,substr(add_months(concat(now_month,'-','01'),-1), 1, 7) as last_monthfrom(selectsubstr(order_time, 1, 7) as now_month,sum(order_num) as now_numfrom ods_saleordergroup bysubstr(order_time, 1, 7)) tmp)selecta1.now_month,a1.now_num,a1.last_month,nvl(a2.now_num,0),nvl(round( (a1.now_num-a2.now_num) / a2.now_num, 2 ),0) as ratiofroma a1left joina a2ona1.last_month=a2.now_month;
猜你喜欢
Hive之同比环比的计算的更多相关文章
- 再谈Cognos利用FM模型来做同比环比
很早之前已经讲过 <Cognos利用DMR模型开发同比环比>这篇文章里说的是不利用过滤器,而是采用 except (lastPeriods (-9000,[订单数据分析].[日期维度].[ ...
- cognos report同比环比以及默认为当前月分析
现在的需求是按月份分析不同时期的余额数据,.(报表工具:cognos report:建模工具:FM) ------------------------------------------------- ...
- MySQL统计同比环比SQL
大体思路: MySQL没有类似oracle方便的统计函数,只能靠自己去硬计算:通过时间字段直接增加年份.月份,然后通过left join关联时间字段去计算环比.同比公式即可 原始表结构: 求同比SQL ...
- Oracle分析函数/排名函数/位移函数/同比环比
分析函数 作用:分析函数可以在数据中进行分组,然后计算基于组的某种统计值,并且每一组的每一行都可以返回一个统计值.统计函数:MAX(字段名).MIN(字段名).AVG(字段名).SUM(字段名).CO ...
- 【hive】关于用户留存率的计算
首先用户留存率一般是面向新增用户的概念,是指某一天注册后的几天还是否活跃,是以每天为单位进行计算的.一般收到的需求都是一个时间段内的新增用户的几天留存 (1)找到这个时间段内的新增用户(也可能含有地区 ...
- 数据可视化之DAX篇(十二)掌握时间智能函数,同比环比各种比,轻松搞定!
https://zhuanlan.zhihu.com/p/55841964 时间可以说是数据分析中最常用的独立变量,工作中也常常会遇到对时间数据的对比分析.假设要计算上年同期的销量,在PowerBI中 ...
- MDX 占比同比环比
http://blog.csdn.net/hero_hegang/article/details/9072889
- 实现同比、环比计算的N种姿势
在做数据分析时,我们会经常听到同比.环比同比的概念.各个企业和组织在发布统计数据时,通常喜欢用同比.环比来和之前的历史数据进行比较,用来说明数据的变化情况.例如,统计局公布2022年1月份CPI同比增 ...
- 同比 VS 环比
同比(YoY=year on year):与历史同时期比较,例如2014年7月份与2013年7月份相比,叫同比 环比(MoM=month on month):是本期统计数据与上期比较,例如2014年7 ...
随机推荐
- Python之路 - Day4 - Python基础4 (新版)
本节内容 迭代器&生成器 装饰器 Json & pickle 数据序列化 软件目录结构规范 作业:ATM项目开发 1.列表生成式,迭代器&生成器 列表生成式 孩子,我现在有个需 ...
- SpringMVC 解析(一)概览
Spring MVC是Spring提供的构建Web应用程序的框架,该框架遵循了Servlet规范,负责接收并处理Servelt容器传递的请求,并将响应写回Response.Spring MVC以Dis ...
- js复制标题和链接
问题 常常在写博客和作业时候,需要附上参考链接. 希望可以一键得到标题和链接. 解决方案 普通元素 可以使用findid然后复制 但是标题无法使用 <!DOCTYPE html> < ...
- Natasha 4.0 探索之路系列(一) 概况
Natasha 简介 Natasha 是一个基于 Roslyn 的动态编译类库, 它以极简的 API 完成了动态编译的大部分功能, 使用它可以在程序运行时编译出新的程序集. Natasha 允许开发人 ...
- Natasha 4.0 探索之路系列(二) "域"与插件
域与ALC 在 Natasha 发布之后有不少小伙伴跑过来问域相关的问题, 能不能兼容 AppDomain, 如何使用 AppDomain, 为什么 CoreAPI 阉割了 AppDomain 等一系 ...
- tarjan全家桶
tarjan 全家桶 关于tarjan 它太强了 CCCOrz dfs树&low dfs树:在图上做不重复经过同一点的dfs,经过的边与点形成一棵树.于是图上所有点都被这棵树包含,一部分边被包 ...
- gin框架的热加载方法
gin是用于实时重新加载Go Web应用程序的简单命令行实用程序.只需gin在您的应用程序目录中运行,您的网络应用程序将 gin作为代理提供.gin检测到更改后,将自动重新编译您的代码.您的应用在下次 ...
- gin中使用路由组
package main import ( "github.com/gin-gonic/gin" ) func main() { router := gin.Default() / ...
- 安装python3.6,设为默认,yum不能用
安装python3.6 1.安装依赖包 yum -y install wget sqlite-devel xz gcc automake zlib-devel openssl-devel epel-r ...
- Java高级语法之反射
Java高级语法之反射 什么是反射 java.lang包提供java语言程序设计的基础类,在lang包下存在一个子包:reflect,与反射相关的APIs均在此处: 官方对reflect包的介绍如下: ...