饮冰三年-人工智能-Python-17Python基础之模块与包
一、模块(module)
1.1 啥是模块
简单理解一个.py文件就称之为一个模块。
有的功能开发者自己无法完成,需要借助已经实现的函数\类来完成这些功能。例如:和操作系统打交道的类或者是随机数函数等系统内置模块。
有的功能其他开发者已经完成,我们无需重复造轮子,只需借用他们的功能。例如:django框架或者scrapy框架等第三方模块。
有的功能开发者已经自主完成,需要重复使用,可以通过模块避免代码重复。这种称为自定义模块。
1.2 模块种类
# 内置模块
# 安装python解释器的时候跟着装上的那些方法
# 第三方模块/扩展模块
# 没在安装python解释器的时候安装的那些功能
# 自定义模块
# 你写的功能如果是一个通用的功能,那你就把它当做一个模块
模块的种类
1.3 模块的优点
分类管理方法
节省内存
- 提供更多的功能,避免重复造轮子
1.4 如何使用模块
# import cul #第一种写法
from pkage11.cul import add #第二种写法
if __name__=='__main__':
print(add())
# import 语句的搜索路径
# ['', '/usr/lib/python3.4', '/usr/lib/python3.4/plat-x86_64-linux-gnu','/usr/lib/python3.4/lib-dynload', '/usr/local/lib/python3.4/dist-packages', '/usr/lib/python3/dist-packages']
# 区别:
# 无论1还是2,首先通过sys.path找到cul.py,然后执行cul脚本(全部执行),
# 区别是1会将cul这个变量名加载到名字空间,而2只会将add这个变量名加载进来。
常用的两种导入方法
1.5 模块运行的原理
首先,我们要知道py文件运行的两种方式:
- 以脚本的形式运行。如:直接pycharm运行 cmd运行
- 以模块的方式运行。如:import my_module
name = "张三" def sayHi():
print("Hi,I'm %s" % name) sayHi()
自定义一个模块my_module
import my_module
通过test模块来调用
被调用处只导入了一个my_module模块,控制台有 # Hi,I'm 张三 输出。
其次,我们要了解其调用过程 1:找到my_module模块;2:开辟命名空间;3:执行这个模块
结论一:一旦引入模块,该模块就会执行。
PS:同一模块即使import多次,也只是执行1次
问题一:sayHi() 在测试或调试的时候使用,不希望在被调用处运行。
name = "张三" def sayHi():
print("Hi,I'm %s" % name) if __name__ == '__main__':
sayHi()
调用处,不执行模块内部内容
import my_module
from my_module import name, sayHi print(name)
sayHi()
print("---------------------")
name = "李四"
print(name)
sayHi()
print("---------------------")
#强行修改,被导入模块的值
my_module.name = "王五"
print(name)
sayHi()
print("---------------------")
#强行刷新 当前模块的值
from my_module import name
print(name)
sayHi() '''
张三
Hi,I'm 张三
---------------------
李四
Hi,I'm 张三
---------------------
李四
Hi,I'm 王五
---------------------
王五
Hi,I'm 王五 '''
test调用
结论二:如果本文件中和导入的模块中的变量名相同,调用最后一次加载内存中的值。如name的变化。
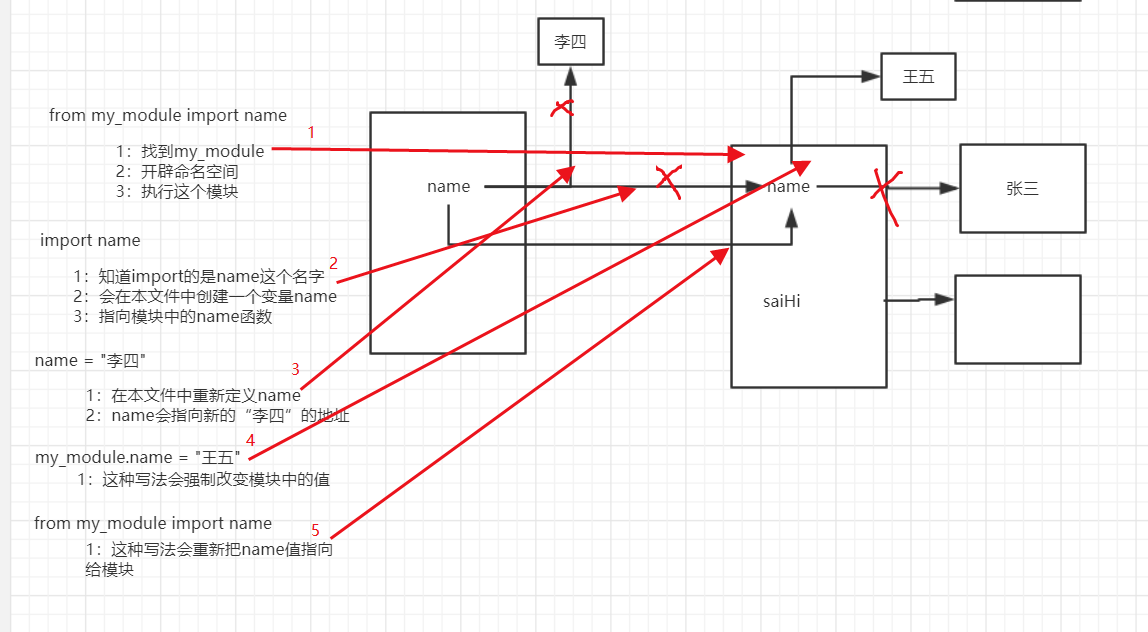
结论三:强烈不建议调用处使用和被调用同名的变量(可以通过as别名的方式避免),不建议强行修改被调用模块中的变量值或方法内容
from my_module import *:默认是导入该模块下的所有内容
但是如果在my_module中 通过 __all__=["name"]。那么import * 也就只包含name一项内容了。
1.6 __main__与__name__
import sys
print(__name__) #__main__
print(sys.modules[__name__]) # <module '__main__' from 'D:/Code/Home_ORM/App01/my_module.py'>
my_module
import my_module
''' 输出结果
my_module
<module 'my_module' from 'D:\\Code\\Home_ORM\\App01\\my_module.py'>
'''
test调用
结论一: 1.6.1 __name__的变与不变 (变的是位置:如果是在当前其值为__main__,不变的是初心:路径不变)
__main__是当前文件执行地址
import sys
print(sys.modules["__main__"]) # <module '__main__' from 'D:/Code/Home_ORM/App01/my_module.py'>
my_module
import my_module
''' 输出结果
<module '__main__' from 'D:/Code/Home_ORM/App01/tests.py'>
'''
test调用
结论二:__main__:是当前直接执行文件所在的地址
import sys print(sys.modules["__main__"]) # <module '__main__' from 'D:/Code/Home_ORM/App01/my_module.py'> def funa():print("aaa") # getattr(sys.modules['__main__'],"funa")() # __main__在被调用处运行,有可能会由于没有导入funa而导致报错 getattr(sys.modules[__name__],"funa")()
my_module
结论三:__main__:使用反射自己模块中的内容的时候都要使用__name__。不能用'__main__'。注意__name__不需要加'',而'__main__'需要
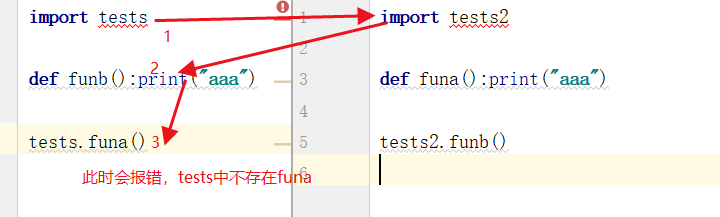
结论四:不要出现循环引用
总结:
- '__main__':当前直接执行文件所在的地址
- if __name__=='__main__': #主要作用是测试当前模块,不被被调用处运行。
- 在编写py文件的时候,所有不在函数和类中封装的内容都应该写在, if __name__ == '__main__':下面
- 使用反射自己模块中的内容的时候都要使用__name__。不能用__main__。 # import sys # getattr(sys.modules[__name__],变量名)
二、包
当提供的功能比较复杂,一个py文件无法完成的时候,我们把结合了一组py文件,提供了一组复杂功能的py集合称为包。下面有__init__.py文件。
1 直接导入模块
import 包.包.模块
包.包.模块.变量
from 包.包 import 模块 # 推荐
模块.变量
2 导入包 读框架源码的时候,封装好让别人使用
如要希望导入包之后 模块能够正常的使用 那么需要自己去完成init文件的开发
包中模块的 绝对导入
包中模块的 相对导入
使用了相对导入的模块只能被当做模块执行
不能被当做脚本执行
三、常用模块
3.1 时间模块
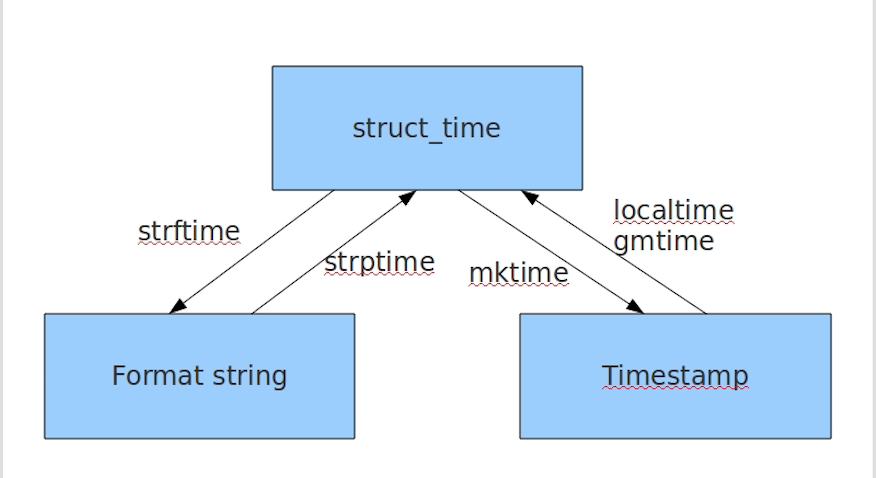
import time
#毫秒值--开始
print(time.time())
#输出结果 1538533474.3565
#毫秒值--结束 #结构化时间--开始
print(time.localtime())
#输出结果 time.struct_time(tm_year=2018, tm_mon=10, tm_mday=3, tm_hour=11, tm_min=5, tm_sec=21, tm_wday=2, tm_yday=276, tm_isdst=0)
print(time.gmtime())
#输出结果 time.struct_time(tm_year=2018, tm_mon=10, tm_mday=3, tm_hour=3, tm_min=8, tm_sec=19, tm_wday=2, tm_yday=276, tm_isdst=0)
#结构化时间--结束 #结构化时间==》毫秒值--开始
print(time.mktime(time.localtime()))
#结构化时间==》毫秒值--结束 #结构化时间==》格式化时间--开始
print(time.strftime('%Y-%m-%d %X',time.localtime()))
#结构化时间==》格式化时间--结束 #格式化时间==》结构化时间-开始
print(time.strptime('2018-10-03 11:18:37','%Y-%m-%d %X'))
#格式化时间==》结构化时间-结束 #固定格式的时间-开始
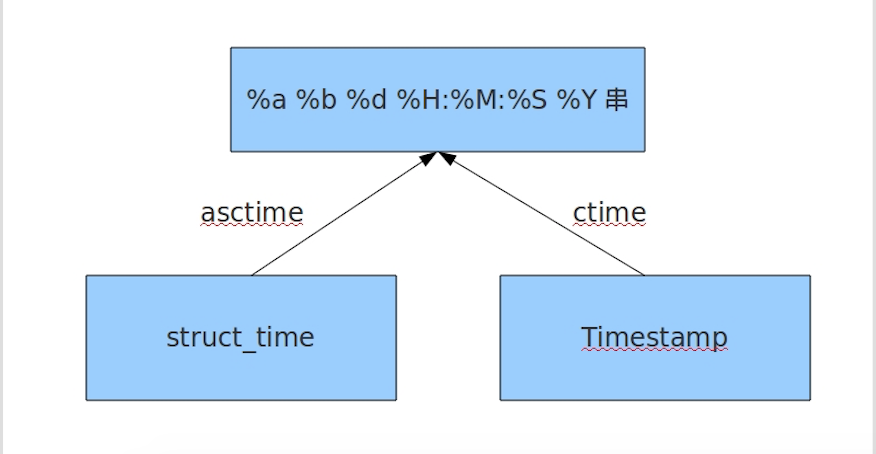
print(time.asctime())
print(time.ctime())
#固定格式的时间-结束
time
import datetime
print(datetime.datetime.now())
datetime
判断一个时间是否是10分钟之内
import time
help_alarm_entity = HelpAlarmHistory.objects.filter(sms_code="").first() # type:HelpAlarmHistory
# 获取数据表中的时间字段,并转成秒
d1 = time.mktime(help_alarm_entity.process_time.timetuple())
# 获取当前时间转成秒
d2 = time.mktime(time.localtime())
# 人生,应该做减法
d = d2 - d1 - 600
if d > 0:
print("超过10分钟")
else:
print("10分钟之内")
print('相差的秒数:{}'.format(d))
计算时间差
3.2 随机函数
import random
ret = random.random()
print(ret)
ret1 = random.randint(1,3) #[1,3]
print(ret1)
ret1 = random.randrange(1,3) #[1,3)
print(ret1)
ret1 = random.choice([1,3,5]) #从1,3,5中获取数据
print(ret1)
ret1 = random.sample([1,3,5],2) #从1,3,5中获取2个数据
print(ret1)
ret1=[1,3,5]
random.shuffle(ret1) #重新洗牌
print(ret1)
randomTest
def v_code():
ret=""
for i in range(5):
num= random.randint(0,9)
alf=chr(random.randint(65,122))
s=str(random.choice([num,alf]))
ret+=s
return ret
print(v_code())
生成验证码
3.3 OS
import os os.getcwd() # 获取当前工作目录,即当前python脚本工作的目录路径
print(os.getcwd()) # D:\Code\venv1
# 改变当前脚本工作目录;相当于shell下cd
os.chdir("..")
print(os.getcwd())
# os.curdir 返回当前目录: ('.')
print(os.curdir)
# os.pardir 获取当前目录的父目录字符串名:('..')
print(os.pardir)
# os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.makedirs('dirname1/dirname2')
# os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.removedirs('dirname1/dirname2')
# os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.mkdir('dirname')
# os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.listdir('dirname')
# os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.rmdir('dirname')
# os.remove() 删除一个文件
# os.rename("oldname","newname") 重命名文件/目录
os.mkdir('dirname')
os.rename('dirname','newname')
os.rmdir('newname')
# os.stat('path/filename') 获取文件/目录信息
os.mkdir('dirname')
print(os.stat('D:\Code\dirname'))
os.rmdir('dirname')
# os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
# os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
# os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
# os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
# os.system("bash command") 运行shell命令,直接显示
# os.environ 获取系统环境变量
print(os.environ)
# os.path.abspath(path) 返回path规范化的绝对路径
print(os.path.abspath('dirname'))
# os.path.split(path) 将path分割成目录和文件名二元组返回
print(os.path.split('D:\Code\dirname'))
# os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
print(os.path.dirname('D:\Code\dirname') )
# os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
print(os.path.basename('dirname') )
os.mkdir('dirname')
# os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
print(os.path.exists('D:\Code\dirname') )
# os.path.isabs(path) 如果path是绝对路径,返回True
print(os.path.exists('D:\Code\dirname') )
# os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
print(os.path.isfile('D:\Code\dirname') )
# os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
print(os.path.isdir('D:\Code') )
os.rmdir('dirname')
# os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
s="D:\Code"
n="dirname"
print(os.path.join(s,n) )
os.mkdir('dirname')
# os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
print(os.path.getatime('D:\Code\dirname') )
# os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
print(os.path.getmtime('D:\Code\dirname') )
os.rmdir('dirname')
os
3.4 Json
# ----------------------------序列化
import json dic = {'name': 'alvin', 'age': 23, 'sex': 'male'}
print(type(dic)) # <class 'dict'>
j = json.dumps(dic)
print(type(j)) # <class 'str'>
print(j) #{"name": "alvin", "age": 23, "sex": "male"} 把单引号修改成了双引号 data=json.loads(j)
print(data)
#{'name': 'alvin', 'age': 23, 'sex': 'male'}
json
3.5 pickle
##----------------------------序列化
import pickle dic={'name':'alvin','age':23,'sex':'male'} print(type(dic))#<class 'dict'> j=pickle.dumps(dic)
print(type(j))#<class 'bytes'> f=open('序列化对象_pickle','wb')#注意是w是写入str,wb是写入bytes,j是'bytes'
f.write(j) #-------------------等价于pickle.dump(dic,f) f.close()
#-------------------------反序列化
import pickle
f=open('序列化对象_pickle','rb') data=pickle.loads(f.read())# 等价于data=pickle.load(f) print(data['age'])
pickle
3.6 shelve
import shelve f=shelve.open(r'shelve2') #目的:将一个字典放入到文本中,二进制,是二进制啊
f["stu1_info"]={'name':'ajax','age':''}
f["school_info"]={'name':'北大青鸟','city':'beijing'}
f.close()
f=shelve.open(r'shelve2')
print(f.get('stu1_info')['age']) #会生成3个文件
# shelve2.bak
# shelve2.dat
# shelve2.dir
shelve
3.7 xml
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year updated="yes">2013</year>
<gdppc>141100</gdppc>
<neighbor direction="E" name="Austria" />
<neighbor direction="W" name="Switzerland" />
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year updated="yes">2016</year>
<gdppc>59900</gdppc>
<neighbor direction="N" name="Malaysia" />
</country>
<country name="China">
<rank updated="yes" />
<year>2018</year><gdppc />
<neighbor />
</country>
</data>
htmlContent.html
#操作xml
import xml.etree.ElementTree as ET
# 1加载xml数据
tree = ET.parse("htmlContent.html")
# 2获取根节点
root = tree.getroot();
print(root.tag) #data
#3 查询
#3.1 遍历xml文档
for child in root:
print(child.tag,child.attrib) #country {'name': 'Liechtenstein'}
for i in child:
print(i.tag,i.attrib,i.text)
#3.2 只遍历year 节点
for node in root.iter('year'):
print(node.tag,node.attrib,node.text)
#4 修改
for node in root.iter('year'):
new_year = int(node.text)+1
node.text=str(new_year)
node.set("updated","yes")
tree.write("htmlContent.html")
#5 删除
for node in root.findall('country'):
rank = int(node.find("rank").text)
if rank > 50:
root.remove(node)
tree.write("htmlContent.html")
#6 添加节点
country = ET.SubElement(root,"country",attrib={"name":"China"})
rank = ET.SubElement(country,"rank",attrib={"updated":"yes"})
year=ET.SubElement(country,"year")
gdppc=ET.SubElement(country,"gdppc")
neighbor=ET.SubElement(country,"neighbor")
year.text=""
tree.write("htmlContent.html")
#7 新建文件
new_xml = ET.Element("nameList")
name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"})
age = ET.SubElement(name,"age",attrib={"enecked":"no"})
sex=ET.SubElement(name,"sex")
age.text=''
st=ET.ElementTree(new_xml)
st.write("test.xml",encoding="utf-8",xml_declaration=True)
htmltest.py
3.8 re正则匹配
import re
#1 元字符 . ^ $ * + ? ( ) [] {} \ |
#1.1 通配符.表示任意字符
ret=re.findall('a..in','helloalvin')
print(ret)#['alvin']
#1.2 ^ 表示以。。。开头
ret=re.findall('^a...n','alvinhelloawwwn')
print(ret)#['alvin']
#1.3 \$ 表示以。。。结尾
ret=re.findall('a...n$','alvinhelloawwwn')
print(ret)#['awwwn']
#1.4 * 表示#贪婪匹配[0,+∞]
ret = re.findall('abc*', 'abcccc')
print(ret) # ['abcccc']
#1.5 +表示#贪婪匹配[1,+∞]
ret = re.findall('abc+', 'abccc')
print(ret) # ['abccc']
#1.6 +表示贪婪匹配[0,1]
ret = re.findall('abc?', 'abccc')
print(ret) # ['abc']
# 注意:前面的*,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
#1.7 ?还可以表示取消贪婪模式
ret=re.findall('abc+?','abccc')
print(ret)#['abc']
#1.8 {}表示贪婪匹配可以指定次数
ret=re.findall('abc{1,4}','abccc')
print(ret)#['abccc'] 贪婪匹配
#1.9 []表示自定义字符集
ret = re.findall('[a-z]', 'acd')
print(ret) # ['a', 'c', 'd']
ret = re.findall('[.*+]', 'a.cd+')
print(ret) # ['.', '+']
#1.10 在字符集里有功能的符号: - ^ \
#- 表示范围
ret = re.findall('[1-9]', '45dha3')
print(ret) # ['4', '5', '3']
#^ 表示取反
ret = re.findall('[^ab]', '45bdha3')
print(ret) # ['4', '5', 'd', 'h', '3']
#\ 表示转义
ret = re.findall('[\d]', '45bdha3')
print(ret) # ['4', '5', '3'] # 1.11 元字符之转义符\
# 反斜杠后边跟元字符去除特殊功能,比如\.
# 反斜杠后边跟普通字符实现特殊功能,比如\d
# \d 匹配任何十进制数;它相当于类 [0-9]。
# \D 匹配任何非数字字符;它相当于类 [^0-9]。
# \s 匹配任何空白字符;它相当于类 [ \t\n\r\f\v]。
# \S 匹配任何非空白字符;它相当于类 [^ \t\n\r\f\v]。
# \w 匹配任何字母数字字符;它相当于类 [a-zA-Z0-9_]。
# \W 匹配任何非字母数字字符;它相当于类 [^a-zA-Z0-9_]
# \b 匹配一个特殊字符边界,比如空格 ,&,#等
ret=re.findall('I\b','I am LIST')
print(ret)#[]
ret=re.findall(r'I\b','I am LIST')
print(ret)#['I'] # -----------------------------eg1:
ret = re.findall('c\\\\l', 'abc\le')
print(ret) # ['c\\l']
ret = re.findall(r'c\\l', 'abc\le')
print(ret) # ['c\\l'] # -----------------------------eg2:
# 之所以选择\b是因为\b在ASCII表中是有意义的
m = re.findall('\bblow', 'blow')
print(m)
m = re.findall(r'\bblow', 'blow')
print(m)
# 1.12元字符之分组()
m=re.findall('(ad)+','adadad')
print(m) # 输出结果['ad'],()中有优先级,只匹配输出第一个
ret=re.search('(?P<id>\d{2})/(?P<name>\w{3})','23/com')
print(ret.group('id'))
# 输出结果 23 # 1.13元字符之|
ret = re.search('(ab)|\d',"ababababcdabc123123")
print(ret.group())# 输出结果 ab #2 re模块下的常用方法
#2.1 findall方法 返回所有满足匹配条件的结果,放到列表中
print(re.findall('a','apple append')) #['a', 'a']
#2.2 search方法
# 只找到第一个匹配的结果,然后返回一个包含匹配信息的对象
# 该对象可以通过调用group()方法得到匹配的字符串,如果没有匹配到,返回None
print(re.search('a','apple append').group()) #a
#2.3 match方法
# 与search方法类似,但是只匹配首字母开头
print(re.match('a','isapple append')) #None #2.4 split方法
print(re.split('[ap]','isaple append')) #['is', '', 'le ', '', '', 'end']
#先按照a分割 'is' 'pple' '' 'ppend'
#再按照p分割 'is' '' 'le' '' '' 'end' #2.5 sub方法 替换 把数字替换成*保密
ret = re.sub('\d+','*','我的年龄是18岁')
print(ret) #我的年龄是*岁
#现在只隐藏年龄中的第一位置的数
ret = re.sub('\d','*','我的年龄是18岁',1)
print(ret) #我的年龄是*8岁 #2.5 compile方法
obj=re.compile('\d{2}') #可以多次使用
ret = obj.search("abc123def45ghi6789")
print(ret.group()) # #2.6 finditer方法
ret = re.finditer('\d','ds3sy4784a')
print(ret) #<callable_iterator object at 0x000000000257F198>
print(next(ret).group()) # #2.7 findall会优先把匹配结果组里内容返回
ret = re.findall('www.(baidu|yangke).com','www.baidu.com')
print(ret) #['baidu']
# 如果想取消优先级,需要添加?:
ret = re.findall('www.(?:baidu|yangke).com','www.baidu.com')
print(ret) #['www.baidu.com']
#2.8 补充
print(re.findall("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>"))
print(re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>"))
print(re.search(r"<(\w+)>\w+</\1>","<h1>hello</h1>"))
# 2.9 练习
#匹配出所有的整数
ret=re.findall(r"-?\d+\.\d*|(-?\d+)","1-2*(60+(-40.35/5)-(-4*3))")
ret.remove("")
print(ret) #['1', '-2', '60', '5', '-4', '3']
#匹配出最里层的()
ret=re.findall("\([^()]+\)","1-2*(60+(-40.35/5)-(-4*3))")
print(ret) #['(-40.35/5)', '(-4*3)']
re
3.9 logging
import logging #基础设置
logging.basicConfig(
level=logging.DEBUG, #设置级别
filename="loggger.log", #保存文件名
filemode="w", #设置读写方式
format="%(asctime)s %(filename)s [%(lineno)d]" #时间格式 和 行号 )
logging.debug('debug message')
logging.info('info message')
logging.warning('warning message')
logging.error('error message')
logging.critical('critical message') '''
2018-10-05 10:40:01,092 logTest.py [11]
2018-10-05 10:40:01,092 logTest.py [12]
2018-10-05 10:40:01,092 logTest.py [13]
2018-10-05 10:40:01,092 logTest.py [14]
2018-10-05 10:40:01,092 logTest.py [15]
'''
import logging
#1 创建对象logger
logger = logging.getLogger()
#1.1 创建文件对象和屏幕对象
fm = logging.FileHandler("logInfo.log")
sm = logging.StreamHandler()
#1.2 创建信息格式
ff = logging.Formatter("%(asctime)s,%(message)s")
#2.1 把格式添加到fm和sm上
fm.setFormatter(ff)
sm.setFormatter(ff)
#3.1 把fm和sm添加到logger上
logger.addHandler(fm)
logger.addHandler(sm)
#4设置打印级别
logger.setLevel("DEBUG")
#被调用处
logger.debug('logger debug message')
logger.info('logger info message')
logger.warning('logger warning message')
logger.error('logger error message')
logger.critical('logger critical message')
3.10 configparser
import configparser
#创建文档
config = configparser.ConfigParser() #创建文档
#默认文档,比较特殊。1创建以后其他版块默认拥有DEFULT的属性值
# 方式一,直接赋值
config["DEFULT"]={
"ServerAliveInterval" : "",
"Compression" : "yes",
"CompressionLevel" : ""
}
config["DEFULT"]["ForwardX11"]="yes"
# 方式二,创建一个空字典,然后给空字典赋值
config["bitbucket.org"]={}
config["bitbucket.org"]["user"]="hg"
# 方式三,创建一个空字典,然后给空字典赋值给变量,然后通过变量赋值
config["topsecret.server.com"]={}
topsecret=config["topsecret.server.com"]
topsecret["Port"] = ""
topsecret["ForwardX11"] = "no"
#最后统一写文件
with open("configparserContent1.ini","w") as f:
config.write(f) import configparser
#创建对象
config = configparser.ConfigParser()
#加载内容
config.read("configparserContent1.ini")
# 查
# 1.1 查看所有的key值
print(config.sections()) #['DEFULT', 'bitbucket.org', 'topsecret.server.com']
#1.2 判断某个key值是否存在
print("abc" in config) #False
# 1.3 查看某个key值中的具体内容
print(config["topsecret.server.com"]["ForwardX11"]) #no
#1.4 遍历
print("-----")
for key in config["topsecret.server.com"]:
print(key)
#1.5 查找一个根节点的key值
print(config.options('bitbucket.org')) #['user']
#1.6 查找一个根节点的键值对
print(config.items('bitbucket.org')) #[('user', 'hg')]
#1.7 查找某一个具体指
print(config.get('bitbucket.org','user')) #hg #2 删除
#2.1 删除节点下的某个键值对
config.remove_option('bitbucket.org','user')
print(config.options('bitbucket.org')) #[]
#2.2 删除某个节点
config.remove_section("bitbucket.org")
print(config.sections()) #['DEFULT', 'topsecret.server.com'] #3 添加
#3.1 添加某个节点
config.add_section("Aaron")
#4 修改
config.set("Aaron","age","")
config.write(open("configparserContent1.ini","w"))
configparser
3.11 hashlib
import hashlib m=hashlib.md5()
m.update("admin".encode("utf-8"))
print(m.hexdigest()) #21232f297a57a5a743894a0e4a801fc3
m.update("root".encode("utf-8")) #注意,其实这里是对“adminroot”加密
print(m.hexdigest()) #4b3626865dc6d5cfe1c60b855e68634a # 为了防止撞库,我们需要对加密方式进行强化
hash = hashlib.sha256('abcd'.encode('utf8'))
hash.update('Aaron'.encode('utf8'))
print (hash.hexdigest())#c8d25a6e22ce56ec653978bc31f6006f2f3a2850cc01cfa9f509d49264705aab
hashlibTest
饮冰三年-人工智能-Python-17Python基础之模块与包的更多相关文章
- Python 入门基础13 --模块与包
本节内容: 一.模块及使用 1.模块及使用 2.起别名.from导入 3.自执行与模块 二.包的使用 2.1 包中模块的使用:import 2.2 包的嵌套 2.3 包中模块的使用:from ...i ...
- 饮冰三年-人工智能-Python-21 Python数据库MySql
一:下载与安装 1:下载地址:https://dev.mysql.com/downloads/mysql/ 2:安装MySql 打开下载文件解压到指定文件目录.(我这里解压目录为D:\MySql\my ...
- 饮冰三年-人工智能-Python-10之C#与Python的对比
1:注释 C# 中 单行注释:// 多行注释:/**/ python 中 单行注释:# 多行注释:“““内容””” 2:字符串 C#中 "" 用双引号如("我是字符串&q ...
- 饮冰三年-人工智能-Python-22 Python初识Django
1:一个简单的web框架 # 导包 from wsgiref.simple_server import make_server #自定义个处理函数 def application(environ,st ...
- 饮冰三年-人工智能-Python-20 Python线程、进程、线程
进程:最小的数据单元 线程:最小的执行单元 一: 1:线程1 import threading #线程 import time def Music(): print("Listen Musi ...
- 饮冰三年-人工智能-Python-19 Python网络编程
Socket:套接字.作用:我们只需要安照socket的规定去编程,就不需要深入理解tcp/udp协议也可以实现 1:TCP协议 1.1 客户端服务端循环收发消息 # 1:引入stock模块(导包) ...
- 饮冰三年-人工智能-Python-16Python基础之迭代器、生成器、装饰器
一:迭代器: 最大的特点:节省内存 1.1 迭代器协议 a:对象必须提供一个next方法, b:执行方法要么返回迭代中的下一项,要么抛弃一个Stopiteration异常, c:只能向后不能向前. 1 ...
- 饮冰三年-人工智能-Python-14Python基础之变量与函数
1:函数:函数是逻辑结构化和过程化的一种编程方法.函数即变量 #参数组:**字典 *列表 def test(x,*args): print(args); print(args[0]); print(& ...
- 饮冰三年-人工智能-Python-13Python基础之运算符与数据类型
1:算数运算符 + - * / ** % // 2: 成员运算符 in not in name = """张三""" if "张& ...
随机推荐
- 【Convex Optimization (by Boyd) 学习笔记】Chapter 1 - Mathematical Optimization
以下笔记参考自Boyd老师的教材[Convex Optimization]. I. Mathematical Optimization 1.1 定义 数学优化问题(Mathematical Optim ...
- 编程基础 - 0x00008 的0x代表什么?
总结: 二进制:0dXXXX 八进制:0XXXX 十六进制:0xXXXX ------------------------------- 1- 十六进制 以“0x”开始的数据表示16进制,计算机中每位 ...
- 【转】Python 面向对象(初级篇)
[转]Python 面向对象(初级篇) 51CTO同步发布地址:http://3060674.blog.51cto.com/3050674/1689163 概述 面向过程:根据业务逻辑从上到下写垒代码 ...
- python骚操作之...
python中的Ellipsis对象.写作:- 中文解释:省略 该对象bool测试是为真 用途: 1.用来省略代码,作用类似于pass的一种替代方案. from collections.abc imp ...
- 谈谈asp,php,jsp的优缺点
谈谈asp,php,jsp的优缺点 http://hi.baidu.com/lhyboy/item/f95bac264c38830d72863e41 asp.php.asp.net.jsp等主流网 ...
- boost 文件系统
第 9 章 文件系统 目录 9.1 概述 9.2 路径 9.3 文件与目录 9.4 文件流 9.5 练习 该书采用 Creative Commons License 授权 9.1. 概述 库 Boo ...
- mysql数据库基于linux的安装步骤及数据库操作
一.数据库安装 Ubuntu上安装MySQL非常简单只需要几条命令就可以完成. sudo apt-get install mysql-server sudo apt-get isntall mysql ...
- jqueryui插件slider的简单使用
<!DOCTYPE html> <html> <head> <title>slider</title> <meta charset=& ...
- python操作mysql数据库增删改查的dbutils实例
python操作mysql数据库增删改查的dbutils实例 # 数据库配置文件 # cat gconf.py #encoding=utf-8 import json # json里面的字典不能用单引 ...
- gcc/g++基本命令
gcc & g++现在是gnu中最主要和最流行的c & c++编译器 .g++是c++的命令,以.cpp为主,对于c语言后缀名一般为.c.这时候命令换做gcc即可.其实是无关紧要的.其 ...