Apriori算法的原理与python 实现。
前言:这是一个老故事, 但每次看总是能从中想到点什么.在一家超市里,有一个有趣的现象:尿布和啤酒赫然摆在一起出售。但是这个奇怪的举措却使尿布和啤酒的销量双双增加了。这不是一个笑话,而是发生在美国沃尔玛连锁店超市的真实案例,并一直为商家所津津乐道。原来,美国的妇女们经常会嘱咐她们的丈夫下班以后要为孩子买尿布。而丈夫在买完尿布之后又要顺手买回自己爱喝的啤酒,因此啤酒和尿布在一起购买的机会还是很多的。 是什么让沃尔玛发现了尿布和啤酒之间的关系呢?正是商家通过对超市一年多原始交易数字进行详细的分析,才发现了这对神奇的组合。 无独有偶。美国密执安州有一家名为"阿汉"的小餐馆有个异常奇特的做法:经常光顾该餐馆的顾客, 只要愿意,便可报上自己的常住地址,在客户登记簿上注册,开一个"户头",以后顾客每次到这里来就餐,餐馆都会如实地在其户头上记下用餐款额。每年的9月30日,餐馆便会按客户登记簿上的记载算出每位顾客从上年9月30日以来在餐馆的消费总额,然后再按餐馆纯利10%的比例算出每位顾客应得的利润分发给顾客,这样,餐馆自然就常常门庭若市。阿汉餐馆给顾客分红的方法虽然损失了一部分纯利,但却使顾客感到自己与餐馆的利润息息相关,自己也是餐馆的一员。这样一来,餐馆密切了与消费者的关系,吸引了许多回头客。 这种让食客成为"股东"的做法其实也是一种"组合"式的生意之道,不同的是前者是明显的"物质组合",而后者是隐蔽的"人员组合",两者都是以消费者心甘情愿地付出而给老板带来了滚滚利润,何乐而不为呢?
上面的例子我们不讨论他的经营之道,我们来挖掘其中用到的技术思想。
一:关联分析
我们一般去网点或者店里购物,一般都会有这样的购物清单吧。
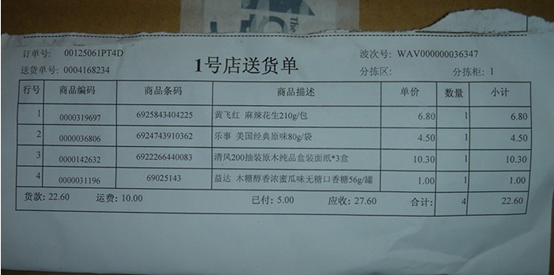
有的人说,这种有什么用?那再来看看这个:
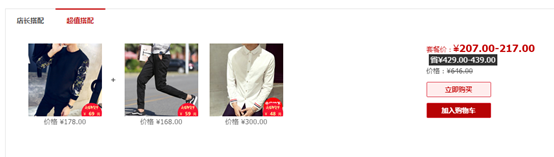
这是我随便找的一家网店的超值搭配。你会说这有什么联系吗?
假如,我是这个店长,我分析了我店里的历史数据,看见衣服1和裤子2被同一个顾客购买的可能性很大。那我是不是可以在我的店里搭配这两个套餐,同时也可以在给点击衣服1的人推荐我的裤子2,说不定,这个人看上了裤子2,又感觉与衣服1搭配还挺合适的,那么就会把这两件都买下来,商家在这次的购物行为中就赚了一笔。
那可能,你会问,小的数据集我可能很快就分析出来了,假如我的店很大,有很多物品。类似于天猫超市那样的,我怎样才能找到他们的关联项呢?不会让我穷尽所有操作吧。那么下面我们来介绍Apriori帮助店长解决这个繁琐的问题。
二 :Apriori算法
先介绍两个概念:
支持度:用于表示给定数据集的频繁程度。公式: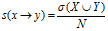 分子为X与Y同
分子为X与Y同
时出现的概率,N为整个数据的个数。
置信度:Y在包含X的事物中出现的频繁程度。公式: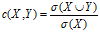
项集:一个购物篮中任意的商品组合就是一个项集(包括单独的一个,但是项集不能出现重复的商品)
频繁项集:出现的项集大于一个人为设置的阀值,我们称之为频繁项集。
三:算法过程
先通过偏离数据库得到一个项集(也就是一个商品),然后计算他的支持度,如果小于某一个阀值则删除,大于则保留,然后组合求2两个项的项集的支持度。低于阀值则去掉,高于阀值则保留。用上面的用以上步骤重复处理新得到的频繁项集合, 直到没有频繁项集合产生。其中候选项集产生的过程被分为连接与剪技两个部分。 采用这种方式, 使得所有的频繁项集既不会遗漏又不会重复。 为提高频繁项集逐层产生的效率, Apriori算法利用了两个重要的性质用于压缩搜索空间。
性质 1 k维数据项目集 X是频繁项目集的必要条件是它的所有 k-1维子集均是频繁项目集。
性质 2 若 k维项目集 X中有 (k-1)维子集不是频繁项集, 则 X不是频繁项集
四:算法的python实现
本算法和数据来自机器学习实战。
'''
Created on Mar 24, 2011
Ch 11 code
@author: Peter
'''
from numpy import *
def loadDataSet():
return [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
def createC1(dataSet):
C1 = []
for transaction in dataSet:
for item in transaction:
if not [item] in C1:
C1.append([item])
C1.sort()
return map(frozenset, C1)#use frozen set so we
#can use it as a key in a dict
def scanD(D, Ck, minSupport):
ssCnt = {}
for tid in D:
for can in Ck:
if can.issubset(tid):
if not ssCnt.has_key(can): ssCnt[can]=1
else: ssCnt[can] += 1
numItems = float(len(D))
retList = []
supportData = {}
for key in ssCnt:
support = ssCnt[key]/numItems
if support >= minSupport:
retList.insert(0,key)
supportData[key] = support
return retList, supportData
def aprioriGen(Lk, k): #creates Ck
retList = []
lenLk = len(Lk)
for i in range(lenLk):
for j in range(i+1, lenLk):
L1 = list(Lk[i])[:k-2]; L2 = list(Lk[j])[:k-2]
L1.sort(); L2.sort()
if L1==L2: #if first k-2 elements are equal
retList.append(Lk[i] | Lk[j]) #set union
return retList
def apriori(dataSet, minSupport = 0.5):
C1 = createC1(dataSet)
D = map(set, dataSet)
L1, supportData = scanD(D, C1, minSupport)
L = [L1]
k = 2
while (len(L[k-2]) > 0):
Ck = aprioriGen(L[k-2], k)
Lk, supK = scanD(D, Ck, minSupport)#scan DB to get Lk
supportData.update(supK)
L.append(Lk)
k += 1
return L, supportData
def generateRules(L, supportData, minConf=0.7): #supportData is a dict coming from scanD
bigRuleList = []
for i in range(1, len(L)):#only get the sets with two or more items
for freqSet in L[i]:
H1 = [frozenset([item]) for item in freqSet]
if (i > 1):
rulesFromConseq(freqSet, H1, supportData, bigRuleList, minConf)
else:
calcConf(freqSet, H1, supportData, bigRuleList, minConf)
return bigRuleList
def calcConf(freqSet, H, supportData, brl, minConf=0.7):
prunedH = [] #create new list to return
for conseq in H:
conf = supportData[freqSet]/supportData[freqSet-conseq] #calc confidence
if conf >= minConf:
print freqSet-conseq,'-->',conseq,'conf:',conf
brl.append((freqSet-conseq, conseq, conf))
prunedH.append(conseq)
return prunedH
def rulesFromConseq(freqSet, H, supportData, brl, minConf=0.7):
m = len(H[0])
if (len(freqSet) > (m + 1)): #try further merging
Hmp1 = aprioriGen(H, m+1)#create Hm+1 new candidates
Hmp1 = calcConf(freqSet, Hmp1, supportData, brl, minConf)
if (len(Hmp1) > 1): #need at least two sets to merge
rulesFromConseq(freqSet, Hmp1, supportData, brl, minConf)
def pntRules(ruleList, itemMeaning):
for ruleTup in ruleList:
for item in ruleTup[0]:
print itemMeaning[item]
print " -------->"
for item in ruleTup[1]:
print itemMeaning[item]
print "confidence: %f" % ruleTup[2]
print #print a blank line
因为Apriori算法比较简单,也没什么好说的,有时会要结合具体硬件进行改进,也可以通过数据的存储形式进行改变。
在这里说一下,那个阿汉餐馆为每个人开个账户我们是不是可以根据他的消费习惯,给他推荐一些相似的餐品。这就用到我们的推荐算法了,哈哈。
Apriori算法的原理与python 实现。的更多相关文章
- 模拟退火算法SA原理及python、java、php、c++语言代码实现TSP旅行商问题,智能优化算法,随机寻优算法,全局最短路径
模拟退火算法SA原理及python.java.php.c++语言代码实现TSP旅行商问题,智能优化算法,随机寻优算法,全局最短路径 模拟退火算法(Simulated Annealing,SA)最早的思 ...
- Apriori算法思想和其python实现
第十一章 使用Apriori算法进行关联分析 一.导语 "啤酒和尿布"问题属于经典的关联分析.在零售业,医药业等我们经常需要是要关联分析.我们之所以要使用关联分析,其目的是为了从大 ...
- BP算法从原理到python实现
BP算法从原理到实践 反向传播算法Backpropagation的python实现 觉得有用的话,欢迎一起讨论相互学习~Follow Me 博主接触深度学习已经一段时间,近期在与别人进行讨论时,发现自 ...
- 神经网络中 BP 算法的原理与 Python 实现源码解析
最近这段时间系统性的学习了 BP 算法后写下了这篇学习笔记,因为能力有限,若有明显错误,还请指正. 什么是梯度下降和链式求导法则 假设我们有一个函数 J(w),如下图所示. 梯度下降示意图 现在,我们 ...
- 机器学习——使用Apriori算法进行关联分析
从大规模的数据集中寻找隐含关系被称作为关联分析(association analysis)或者关联规则学习(association rule learning). Apriori算法 优点:易编码实现 ...
- 嫌弃Apriori算法太慢?使用FP-growth算法让你的数据挖掘快到飞起
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第20篇文章,我们来看看FP-growth算法. 这个算法挺冷门的,至少比Apriori算法冷门.很多数据挖掘的教材还会 ...
- 【机器学习】Apriori算法——原理及代码实现(Python版)
Apriopri算法 Apriori算法在数据挖掘中应用较为广泛,常用来挖掘属性与结果之间的相关程度.对于这种寻找数据内部关联关系的做法,我们称之为:关联分析或者关联规则学习.而Apriori算法就是 ...
- Apriori算法介绍(Python实现)
导读: 随着大数据概念的火热,啤酒与尿布的故事广为人知.我们如何发现买啤酒的人往往也会买尿布这一规律?数据挖掘中的用于挖掘频繁项集和关联规则的Apriori算法可以告诉我们.本文首先对Apriori算 ...
- Python两步实现关联规则Apriori算法,参考机器学习实战,包括频繁项集的构建以及关联规则的挖掘
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
随机推荐
- oracle rman catalog备份和恢复
1.丢失控制文件 启动数据库至nomount状态:restore controlfile from autobackup/restore controlfile from '+data/ba ...
- 数据可视化案例 | 如何打造数据中心APP产品
意识到数据探索带来的无尽信息,越来越多的企业开始建立自有的数据分析平台,打造数据化产品,实现数据可视化. 在零售商超行业,沃尔玛"啤酒与尿布"的故事已不再是传奇.无论是大数据还是小 ...
- Android Studio多渠道打包
本文所讲述的多渠道打包是基于友盟统计实施的. 多渠道打包的步骤: 1.在AndroidManifest.xml里设置动态渠道变量 <meta-data android:name="UM ...
- IOS开发基础知识--碎片49
1:iOS项目配置文件info.plist文件解析 Localization native development region本地化 Executable file可执行文件路径 Bundle id ...
- Android Volley
1.volley简单的介绍: Volley是一个HTTP库,使Android应用程序变得更加容易,最重要的是,网络 得更快. Vollry 提供以下好处: 1.自动调度的网络请求. 2.多个并发的网络 ...
- Mac 开发者常用的工具
转载:http://www.oschina.net/news/53946/mac-dev-tools 在写 Mac 程序员的十个武器之前,我决定先讲一个故事,关于 Mac 和爱情的.(你们不是问 Ma ...
- JSON金额解析BUG的解决过程
[原创申明:文章为原创,欢迎非盈利性转载,但转载必须注明来源] 这是在我们开发的一个支付系统中暴露的一个BUG,问题本身比较简单,有意思的是解决问题的过程.将过程分享出来,希望能够对大家有所帮助. 一 ...
- JavaScript 函数
JavaScript 函数 介绍:函数是由事件驱动的或者当它被调用时执行的可重复使用的代码块.嗯,就像Java中封装的方法一样. 将脚本编写为函数,就可以避免页面载入时执行该脚本. 函数包含着一些代码 ...
- Java开发代码性能优化总结
代码优化,可能说起来一些人觉得没用.可是我觉得应该平时开发过程中,就尽量要求自己,养成良好习惯,一个个小的优化点,积攒起来绝对是有大幅度效率提升的.好了,将平时看到用到总结的分享给大家. 代码优化的目 ...
- Android 强制设置横屏或竖屏 设置全屏
(转自:http://blog.csdn.net/yuejingjiahong/article/details/6636981) 强制横屏: @Override protected void onRe ...