神经网络中的偏置项b到底是什么?
原文地址:https://blog.csdn.net/Uwr44UOuQcNsUQb60zk2/article/details/81074408
前言
很多人不明白为什么要在神经网络、逻辑回归中要在样本X的最前面加一个1,使得 X=[x1,x2,…,xn] 变成 X=[1,x1,x2,…,xn] 。因此可能会犯各种错误,比如漏了这个1,或者错误的将这个1加到W·X的结果上,导致模型出各种bug甚至无法收敛。究其原因,还是没有理解这个偏置项的作用啦。
在文章《逻辑回归》和《从逻辑回归到神经网络》中,小夕为了集中论点,往往忽略掉模型的偏置项b,但是并不代表在实际工程和严谨理论中也可以忽略掉啊,恰恰相反,这个灰常重要的。
在文章《从逻辑回归到神经网络》中,小夕为大家讲解了,一个传统的神经网络就可以看成多个逻辑回归模型的输出作为另一个逻辑回归模型的输入的“组合模型”。因此,讨论神经网络中的偏置项b的作用,就近似等价于讨论逻辑回归模型中的偏置项b的作用。
所以,我们为了减小思维量,不妨从逻辑回归模型的偏置项说起,实际上就是复习一下中学数学啦。
基础回顾
我们知道,逻辑回归模型本质上就是用 y=WX+b 这个函数画决策面,其中W就是模型参数,也就是函数的斜率(回顾一下初中数学的 y=ax+b ),而b,就是函数的截距。一维情况下,令W=[1], b=2。则y=WX+b如下(一条截距为2,斜率为1的直线):
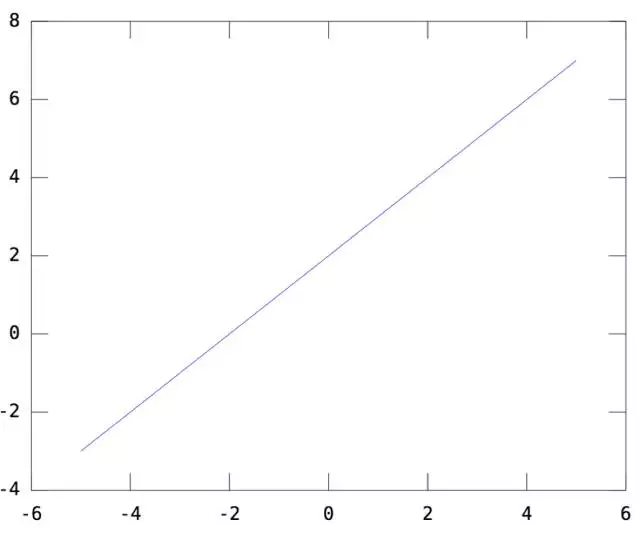
二维情况下,令W=[1 1],b=2,则y=WX+b如下(一个截距为2,斜率为[1 1]的平面)
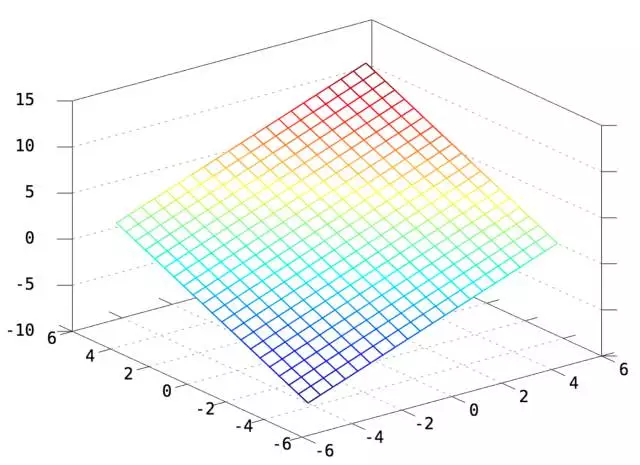
显然,y=WX+b这个函数,就是2维/3维/更高维空间的直线/平面/超平面。因此逻辑回归当然是线性分类器啦。因此如果没有这个偏置项b,那么我们就只能在空间里画过原点的直线/平面/超平面。这时对于绝大部分情况,比如下图,要求决策面过原点的话简直是灾难。
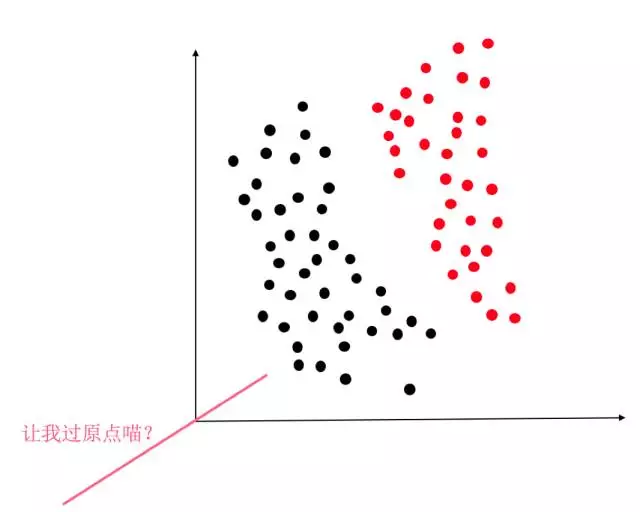
因此,对于逻辑回归来说,必须要加上这个偏置项b,才能保证我们的分类器可以在空间的任何位置画决策面(虽然必须画的直直的,不能弯,嘤…)。
神经网络的偏置项
同样的道理,对于多个逻辑回归组成的神经网络,更要加上偏置项b了。但是想一想,如果隐层有3个节点,那就相当于有3个逻辑回归分类器啊。这三个分类器各画各的决策面,那一般情况下它们的偏置项b也会各不相同的呀。比如下面这个复杂的决策边界就可能是由三个隐层节点的神经网络画出来的:
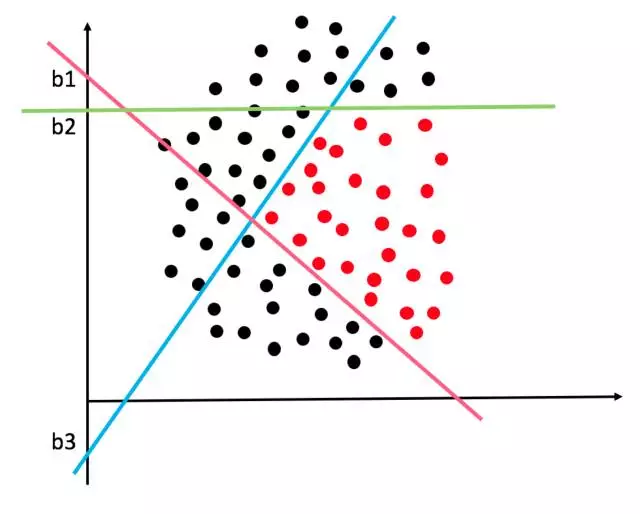
那如何机智的为三个分类器(隐节点)分配不同的b呢?或者说如果让模型在训练的过程中,动态的调整三个分类器的b以画出各自最佳的决策面呢?
那就是先在X的前面加个1,作为偏置项的基底,(此时X就从n维向量变成了n+1维向量,即变成 [1, x1,x2…] ),然后,让每个分类器去训练自己的偏置项权重,所以每个分类器的权重就也变成了n+1维,即[w0,w1,…],其中,w0就是偏置项的权重,所以1*w0就是本分类器的偏置/截距啦。这样,就让截距b这个看似与斜率W不同的参数,都统一到了一个框架下,使得模型在训练的过程中不断调整参数w0,从而达到调整b的目的。
所以,如果你在写神经网络的代码的时候,要是把偏置项给漏掉了,那么神经网络很有可能变得很差,收敛很慢而且精度差,甚至可能陷入“僵死”状态无法收敛。因此,除非你有非常确定的理由去掉偏置项b,否则不要看它小,就丢掉它哦。
神经网络中的偏置项b到底是什么?的更多相关文章
- [转载]神经网络偏置项(bias)的设置及作用
[转载]神经网络偏置项(bias)的设置及作用 原文来自:https://www.cnblogs.com/shuaishuaidefeizhu/p/6832541.html 1.什么是bias? 偏置 ...
- 浅谈神经网络中的bias
1.什么是bias? 偏置单元(bias unit),在有些资料里也称为偏置项(bias term)或者截距项(intercept term),它其实就是函数的截距,与线性方程 y=wx+b 中的 b ...
- 神经网络损失函数中的正则化项L1和L2
神经网络中损失函数后一般会加一个额外的正则项L1或L2,也成为L1范数和L2范数.正则项可以看做是损失函数的惩罚项,用来对损失函数中的系数做一些限制. 正则化描述: L1正则化是指权值向量w中各个元素 ...
- 循环神经网络中BFTT的公式推导
一.变量定义 此文是我学习BFTT算法的笔记,参考了雷明<机器学习与应用>中的BFTT算法推导,将该本书若干个推导串联起来,下列所有公式都是结合书和资料,手动在PPT上码的,很费时间,但是 ...
- 第二节,神经网络中反向传播四个基本公式证明——BackPropagation
假设一个三层的神经网络结构图如下: 对于一个单独的训练样本x其二次代价函数可以写成: C = 1/2|| y - aL||2 = 1/2∑j(yj - ajL)2 ajL=σ(zjL) zjl = ∑ ...
- 神经网络中 BP 算法的原理与 Python 实现源码解析
最近这段时间系统性的学习了 BP 算法后写下了这篇学习笔记,因为能力有限,若有明显错误,还请指正. 什么是梯度下降和链式求导法则 假设我们有一个函数 J(w),如下图所示. 梯度下降示意图 现在,我们 ...
- 一文弄懂神经网络中的反向传播法——BackPropagation【转】
本文转载自:https://www.cnblogs.com/charlotte77/p/5629865.html 一文弄懂神经网络中的反向传播法——BackPropagation 最近在看深度学习 ...
- 在神经网络中weight decay
weight decay(权值衰减)的最终目的是防止过拟合.在损失函数中,weight decay是放在正则项(regularization)前面的一个系数,正则项一般指示模型的复杂度,所以weigh ...
- 神经网络中的反向传播法--bp【转载】
from: 作者:Charlotte77 出处:http://www.cnblogs.com/charlotte77/ 一文弄懂神经网络中的反向传播法——BackPropagation 最近在看深度学 ...
随机推荐
- HTML第一耍 标题 段落 字体等标签
1.HTML标题的使用 <!doctype html> <html> <head> <title>文本标签演示</title> </h ...
- 队列 Queue 与 生产者消费模型
队列:先进先出 # from multiprocessing import Queue # Q = Queue(4) # Q.put('a') # Q.put('b') # Q.put('b') # ...
- css3实现单行文本溢出显示省略号
文本超出一定宽度让其隐藏,以省略号替代 width:200px; white-space:nowrap; text-overflow:ellipsis; overflow:hidden; 如下图
- Java时间转换的一个特性
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm"); Date codedat ...
- C# web IIS服务器 DateTime 带中文解决
C# Web应用在某些电脑IIS上部署运行,读取当前时间带有中文,比如2018-5-1 星期一 上午 12:00:00,虽然使用Format转换可以解决,但代码量较大难免遗漏,会引发问题,为了解决该问 ...
- 调用waitpid的SIGCHLD信号处理函数
#include <stdio.h> #include <sys/wait.h> void sig_chld(int signo) { pid_t pid; int stat; ...
- man termios(FreeBSD 12.0)
TERMIOS() FreeBSD Kernel Interfaces Manual TERMIOS() NAME termios - general terminal line discipline ...
- HTML 实例学习(基础)
1.HTML <html> 标签 注意:对于中文网页需要使用 <meta charset="utf-8"> 声明编码,否则会出现乱码.有些浏览器会设置 GB ...
- Spring Data 起步
[Maven 坐标]G A V ……………………………………………………………………………………………………………………………………………… [JDBC] Connection 连接数据库 State ...
- sql 左右连接 on 之后的and 和where的区别