代码详解:TensorFlow Core带你探索深度神经网络“黑匣子”
来源商业新知网,原标题:代码详解:TensorFlow Core带你探索深度神经网络“黑匣子”
想学TensorFlow?先从低阶API开始吧~某种程度而言,它能够帮助我们更好地理解Tensorflow,更加灵活地控制训练过程。本文演示了如何使用低阶TensorFlow Core 搭建卷积神经网络(ConvNet)模型,并演示了使用TensorFlow编写自定义代码的方法。
对很多开发人员来说,神经网络就像一个“黑匣子”, 而TensorFlow Core的应用,则将我们带上了对深度神经网络后台“黑幕”的探索进程。
本文将MNIST手写数字数据集加载到数据迭代器,使用图和会话,搭建新的卷积神经网络体系结构,使用不同选项训练模型,作出预测,保存训练模型。同时,也会提供完整的代码以及Keras中的等效模型,以便使用Keras的用户进行直接比较,加深了解,同时高阶API在搭建神经网络方面的强大功能也能得到展示。

MNIST数据集
MNIST是一组28x28大小的手写数字的灰度图像,其中训练集有60000张图像,测试集有10000张图像。
首先,加载并处理MNIST图像。
预计训练模型输入形状为[batch_size, height, width, channels]([批量大小,高度,宽度,通道])。由于灰度图是单通道图像,它们的形状为 [60000,28,28],因此需要添加通道维度,使得形状为 [60000,28,28,1]。而且图像的数据类型是uint8(像素值范围为0-255),因此需要将其除以255,才能缩放到0-1之间的范围。这样第一张图像就可显示为一个样例。
attn_layer = AttentionLayer(name='attention_layer')([encoder_out,decoder_out])
import tensorflow as tf
import numpy as np
mnist = tf.keras.datasets.mnist
(train_images, train_labels),(test_images, test_labels) = mnist.load_data()
# Normalize and reshape images to [28,28,1]
train_images = np.expand_dims(train_images.astype(np.float32) / 255.0, axis=3)
test_images = np.expand_dims(test_images.astype(np.float32) / 255.0, axis=3)
# View a sample image
import matplotlib.pyplot as plt
plt.figure(dpi=100)
plt.imshow(np.squeeze(train_images[0]), cmap='gray')
plt.title('Number: {}'.format(train_labels[0]))
plt.show()
由于标签是整数值(例如0、1、2),即分类值,需要转换成one-hot编码(例如[1,0,0], [0,1,0], [0,0,1])用于训练。将Keras的to_categorical编码器转换标签,也可以选择用Scikit-learn的OneHotEncoder 编码器。
如下所示,测试集标签不用转化成one-hot编码。
from keras.utils import to_categorical
train_labels = to_categorical(train_labels)
图和会话
用TensorFlow创建模型分为两个步骤:创建一个图;在会话中执行图。
图概述了计算数据流。这种数据流图决定在张量(多维数据阵列)上执行操作的时间和方式。图形可以在会话内部或外部创建,但只能在会话内部使用。只有在会话中才能初始化张量,执行操作,训练模型。
数据迭代器
为了演示数据流图和会话,创建数据集迭代器。由于MNIST图像和真值标签是Numpy数组的切片,因此可以通过将数组传递到tf.data.dataset.from_tensor_slices方法中来创建数据集。然后为数据集创建迭代器。我们希望它在每次运行时返回一个 batch_size(批量大小)图像数量和标签数量,如果不确定训练次数,则返回重复。
batch_size = 128
dataset = tf.data.Dataset.from_tensor_slices((train_images, train_labels))
iterator = dataset.repeat().batch(batch_size).make_initializable_iterator()
data_batch = iterator.get_next(
现在我们定义了一个数据流图,为了获得一批新图像和新标签,我们在会话中运行data_batch。
但是还未完成。虽然数据流图创建好了,但图像还没有被完全传递进来。为此,迭代器需要在会话中初始化。
sess = tf.Session()
sess.run(iterator.initializer)
现在有一个会话正在运行,只需运行data_batch就可以检索第一批图像。图像的形状为[batch_size, height, width, channels],标签的形状为[batch_size, classes]。可以通过以下方式检查:
batch_images, batch_labels = sess.run(data_batch)
print('Images shape: {}'.format(batch_images.shape))
print('Labels shape: {}'.format(batch_labels.shape)
Images shape: (128, 28, 28, 1)
Labels shape: (128, 10)
通过两次运行data_batch来显示前两批中的第一个图像。
# Get the first batch of images and display first image
batch_images, batch_labels = sess.run(data_batch)
plt.subplot(1, 2, 1)
plt.imshow(np.squeeze(batch_images)[0], cmap='gray')
# Get a second batch of images and display first image
batch_images, batch_labels = sess.run(data_batch)
plt.subplot(1, 2, 2)
plt.imshow(np.squeeze(batch_images)[0], cmap='gray')
plt.show()
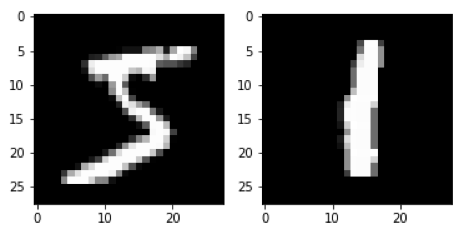
在第一批中,第一个图像是5。 在第二批中,第一个图像是1。
然后可以通过sess.close()关闭会话。 但是,请记住,当会话关闭时,信息将丢失。 例如,如 果如下图所示关闭并重新启动会话,那么数据迭代器将从头开始启动。(注意,迭代器需要在每个会话中初始化。)
# New session
sess = tf.Session()
sess.run(iterator.initializer)
# Get the first batch of images and display first image
batch_images, batch_labels = sess.run(data_batch)
plt.subplot(1, 2, 1)
plt.imshow(np.squeeze(batch_images)[0], cmap='gray')
# Close and restart session
sess.close()
sess = tf.Session()
sess.run(iterator.initializer)
# Get a second batch of images and display first image
batch_images, batch_labels = sess.run(data_batch)
plt.subplot(1, 2, 2)
plt.imshow(np.squeeze(batch_images)[0], cmap='gray')
plt.show()
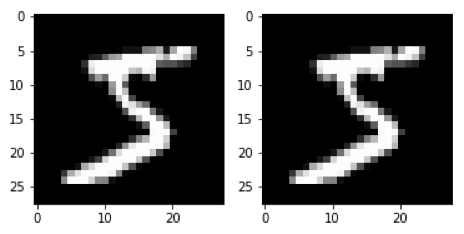
因为会话已关闭,并且创建了新会话,所以数据迭代器开始重新启动,并再次显示相同的图像。
使用with语句
会话也可以通过“with”语句启动和自动关闭。在“with”块的末尾,会话将按指示关闭。
with tf.Session() as sess:
sess.run(iterator.initializer)
for _ in range(2):
batch_images, batch_labels = sess.run(data_batch)
img = np.squeeze(batch_images)[0]
plt.imshow(img, cmap='gray')
plt.show()
# sess is closed
卷积神经网络模型
下面将演示如何使用TensorFlow构建下图所示的基本卷积神经网络模型:
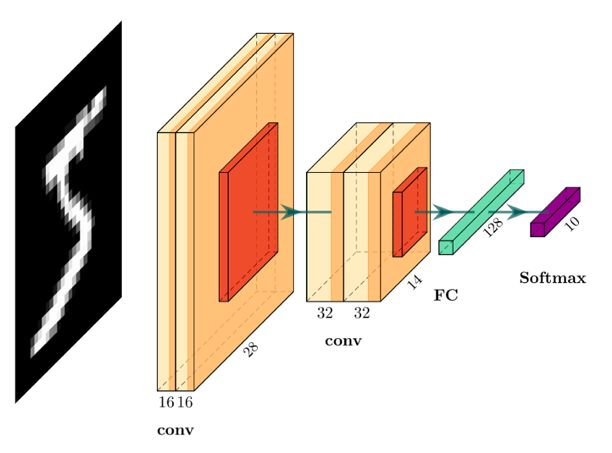
该体系结构有四个卷积层。前两层有16个过滤器,后两层有32个过滤器,所有过滤器的尺寸为3x3。四个卷积层中都添加了偏差和relu激活函数。最后两层是完全连接(密集)的层。
权值和偏差
卷积神经网络中的初始权重需要对称破缺的随机值,以便网络能够学习。xavier_initializer设定项“旨在保持所有层中梯度比例大致相同”,通常用于初始化模型的权重。通过使用带有tf.get_variable的初始值设定项来创建层的权重。每个卷积层都有形状为[filter_height, filter_width, in_channels, out_channels]的滤波器。由于致密层是完全连接的,并且没有3x3大小的滤波器,因此它们的形状为[in_channels, out_channels]。同时,还创建了偏差,每个偏差的大小与相应层的out_channels 的大小相同,并用零初始化。
创建weights(权值)和biases(参数) 字典,以便组织和简化。
weights = {
# Convolution Layers
'c1': tf.get_variable('W1', shape=(3,3,1,16),
initializer=tf.contrib.layers.xavier_initializer()),
'c2': tf.get_variable('W2', shape=(3,3,16,16),
initializer=tf.contrib.layers.xavier_initializer()),
'c3': tf.get_variable('W3', shape=(3,3,16,32),
initializer=tf.contrib.layers.xavier_initializer()),
'c4': tf.get_variable('W4', shape=(3,3,32,32),
initializer=tf.contrib.layers.xavier_initializer()),
# Dense Layers
'd1': tf.get_variable('W5', shape=(7*7*32,128),
initializer=tf.contrib.layers.xavier_initializer()),
'out': tf.get_variable('W6', shape=(128,n_classes),
initializer=tf.contrib.layers.xavier_initializer()),
}
biases = {
# Convolution Layers
'c1': tf.get_variable('B1', shape=(16), initializer=tf.zeros_initializer()),
'c2': tf.get_variable('B2', shape=(16), initializer=tf.zeros_initializer()),
'c3': tf.get_variable('B3', shape=(32), initializer=tf.zeros_initializer()),
'c4': tf.get_variable('B4', shape=(32), initializer=tf.zeros_initializer()),
# Dense Layers
'd1': tf.get_variable('B5', shape=(128), initializer=tf.zeros_initializer()),
'out': tf.get_variable('B6', shape=(n_classes), initializer=tf.zeros_initializer()),
}
因为MNIST图像是灰度的,所以第一层的in_channels为1。输出层需要将out_channels 设为10,因为有10个类。其他层中的滤波器数量可以根据性能或速度进行调整,但是in_channels中的每一个滤波器都需要与前一层的out_channels 相同。在下面创建卷积神经网络时,将解释第一个致密层采用7*7*32大小的原因。
卷积层
TensorFlow有一个tf.nn.conv2d函数,可用于将张量与权重卷积。为了简化卷积层,创建一个函数,它接受输入数据x 并应用一个具有权重W的二维卷积,添加一个偏差b,使用relu函数激活。
#Define 2D convolutional function
def conv2d(x, W, b, strides=1):
x = tf.nn.conv2d(x, W, strides=[1,1,1,1], padding='SAME')
x = tf.nn.bias_add(x, b)
return tf.nn.relu(x )
模型图
另一个函数可用于绘制模型图。这将把MNIST图像作为data(数据),并使用不同层中的权重和偏差。
如体系结构所示,在第二层和第四层卷积层之后,层的高度和宽度都会减小。池化操作将滑动一个窗口,只使用区域内的单个最大值。通过使用2x2窗口(ksize=[1,2,2,1])和跨距2(strides=[1,2,2,1]),尺寸将减少一半。这有助于减少模型大小,同时保留最重要的功能。对于输入的奇数尺寸,输出形状由除以2后的上限确定(例如7/2=4)。
在第四卷积层之后,张量需要在完全连接层之前进行整形,使其变平。完全连接层的权重不是用于二维卷积,而是仅用于矩阵乘法,因此不使用conv2d 函数。
在最后两层之间添加一个脱落层样本,帮助减少过度拟合,其中权值下降的概率为0.2。脱落层只能在训练期间使用,因此如果模型用于预测,则应包含training 标记以绕过该层。如果在预测过程中包含了脱落层,那么模型的输出将不一致,并且由于随机下降的权重而具有较低的准确性。
def conv_net(data, weights, biases, training=False):
# Convolution layers
conv1 = conv2d(data, weights['c1'], biases['c1']) # [28,28,16]
conv2 = conv2d(conv1, weights['c2'], biases['c2']) # [28,28,16]
pool1 = tf.nn.max_pool(conv2, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME')
# [14,14,16]
conv3 = conv2d(pool1, weights['c3'], biases['c3']) # [14,14,32]
conv4 = conv2d(conv3, weights['c4'], biases['c4']) # [14,14,32]
pool2 = tf.nn.max_pool(conv4, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME')
# [7,7,32]
# Flatten
flat = tf.reshape(pool2, [-1, weights['d1'].get_shape().as_list()[0]])
# [7*7*32] = [1568]
# Fully connected layer
fc1 = tf.add(tf.matmul(flat, weights['d1']), biases['d1']) # [128]
fc1 = tf.nn.relu(fc1) # [128]
# Dropout
if training:
fc1 = tf.nn.dropout(fc1, rate=0.2)
# Output
out = tf.add(tf.matmul(fc1, weights['out']), biases['out']) # [10]
return out
不同层的形状在代码注释中给出。从28x28图像开始,两个最大池层将大小缩小了两倍,因此其宽度和高度减小到(28/2)/2=7大小。在用于密集层之前,需要对权重进行扁平化和重塑。由于在第四个卷积层中有32个滤波器,因此扁平层的第一个形状尺寸为7x7x32(这就是为什么使用它来获得weights['d1']的形状)。
构建卷积神经网络图
接下来构建用于模型训练的数据流图。
一个重要的概念是使用占位符,因此首先使用它们创建卷积神经网络。不过,还会展示如何在没有占位符的情况下制作模型。
占位符
我们需要确定如何将来自数据迭代器的数据输入到模型图中。为此,可以制作一个占位符,指示将一些形状为[batch_size, height, width, channels] 的张量输入conv_net函数。将height (高度)和width (宽度)设置为28,将channels (通道)设置为1,并通过将其设置为None(无),将批次大小保留为变量。
现在可以使用带有weights (权重)和biases (偏差)字典的Xtrain 占位符作为conv_net函数的输入来获取logits输出。
Xtrain = tf.placeholder(tf.float32, shape=(None, 28, 28, 1))
logits = conv_net(Xtrain, weights, biases)
此步骤将允许我们通过将一个或多个图像输入Xtrain 占位符来训练模型。
损失
该模型基于一组10个互斥类对图像进行分类。在训练过程中,通过使用softmax将logits转换为图像属于每个类的相对概率,然后通过softmax的交叉熵计算损失。
这些都可以用TensorFlow的softmax交叉熵一步完成。测量一批图像的损失,可以使用tf.reduce_mean 获取批处理的平均损失。
我们可以再次为图使用ytrain占位符,该图将用于提供MNIST标签。回想一下标签经过了one-hot编码,批处理中的每个图像都有一个标签,所以形状应该是[batch_size, n_classes]。
ytrain = tf.placeholder(tf.float32, shape=(None, n_classes))
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=logits,
labels=ytrain))
优化器
该损失用于通过网络对损失进行反向传播来更新模型权重和偏差。学习率用于缩小更新,从而防止权重在优化值周围分散或跳跃。
Adam优化器是由具有动量的Adagrad和RMSProp结合而成,并已证明可以与卷积神经网络一起良好运行。这里我使用学习率为1e-4的Adam优化器。然后计算梯度,并通过运行最小化方法更新权重。
optimizer = tf.train.AdamOptimizer(1e-4)
train_op = optimizer.minimize(loss)
现在train_op是训练模型的关键,因为它能运行optimizer.minimize。为了训练模型,只需将图像输入到图中,然后运行train_op 即可根据损失更新权重。
训练模型
准确性
使用测试图像来测量训练期间的准确性。对于每个图像,执行模型推理,并使用具有最大logit值的类作为预测。准确性就是正确预测的分数。我们需要使用整数值而不是one-hot编码来比较预测与标签,因此需要使用argmax(这就是test_labels未转换为one-hot编码的原因,否则必须将其转换回标签)。
准确性可使用TensorFlow的准确性运算符测量,该运算符有两个输出。第一个输出是不更新度量的准确性,第二个输出是我们将使用的输出,它用更新度量返回准确性。
test_predictions = tf.nn.softmax(conv_net(test_images, weights, biases))
acc,acc_op = tf.metrics.accuracy(predictions=tf.argmax(test_predictions,1),
labels=tests_labels )
初始化变量
需要初始化局部变量(临时变量,如准确性中的total 和count 度量)和全局变量(如模型权重和偏差),以便在会话中使用。
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
输入图像
回想一下,对于每一批,都会创建一组需要输入到占位符Xtrain 和ytrain中新的图像和真值。如上图所示,可以从data_batch(数据批次)中获得batch_images (批次图像)和batch_labels (批次标签)。然后,通过创建一个以占位符为键,数据为值的字典,将它们输入占位符,然后在sess.run()中运行train_op 时将字典传递到feed_dict 参数。
batch_images, batch_labels = sess.run(data_batch)
feed_dict = {Xtrain: batch_images, ytrain: batch_labels}
sess.run(train_op, feed_dict=feed_dict)
训练会话
通过在会话中调用 train_op,图中的所有步骤都将按上述方式运行。我们将使用tqdm 查看每次训练期间训练的进程。在每次训练之后,测量并打印出准确性。
from tqdm import tqdm
nepochs = 5
sess = tf.Session()
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
sess.run(iterator.initializer)
for epoch in range(nepochs):
for step in tqdm(range(int(len(train_images)/batch_size))):
# Batched data
batch_images, batch_labels = sess.run(data_batch)
# Train model
feed_dict = {Xtrain: batch_images, ytrain: batch_labels}
sess.run(train_op, feed_dict=feed_dict)
# Test model
accuracy = sess.run(acc_op)
print('nEpoch {} Accuracy: {}'.format(epoch+1, accuracy))

该模型将继续用给定的训练次数进行训练。经过5次训练,该模型的准确性约为0.97。
无占位符训练
上面的样例演示了在图像中输入的占位符,但是可以将conv_net和batch_labels 中的batch_images直接使用在tf.nn.softmax_cross_entropy_with_logits_v2的labels 参数中,使该图更加简洁。然后可以训练模型,便不必向图中输入任何张量,如下所示:
batch_images, batch_labels = iterator.get_next()
logits = conv_net(batch_images, weights, biases, training=True)
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=logits,
labels=batch_labels))
train_op = optimizer.minimize(loss)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
sess.run(iterator.initializer)
for epoch in range(nepochs):
for step in tqdm(range(int(len(train_images)/batch_size)))
sess.run(train_op)
accuracy = sess.run(acc_op)
print('nEpoch {} Accuracy: {}'.format(epoch+1, accuracy))
访问其它节点
可以通过在会话中单独或在列表中调用图中的不同节点来访问它们。如果运行节点列表,则会给出输出列表。例如,假设希望在训练期间看到每个图像批的损失,这可以通过在会话中运行train_op列表中的loss来完成。在这里,将使用tqdm打印每次训练期间每个批次的损失。
for epoch in range(nepochs):
prog_bar = tqdm(range(int(len(train_images)/batch_size)))
for step in prog_bar:
_,cost = sess.run([train_op,loss])
prog_bar.set_description("cost: {}".format(cost))
accuracy = sess.run(acc_op)
print('nEpoch {} Accuracy: {}'.format(epoch+1, accuracy ))

预测
测试预测
使用测试准确性中的test_predictions (测试_预测)来对性能进行可视化,这些性能用于对样例图像进行分类。在这里,显示前25个测试图像,并使用整数预测作为标题。
onehot_predictions = sess.run(test_predictions)
predictions = np.argmax(np.squeeze(onehot_predictions), axis=1)
f, axarr = plt.subplots(5, 5, figsize=(25,25))
for idx in range(25):
axarr[int(idx/5), idx%5].imshow(np.squeeze(test_images[idx]), cmap='gray')
axarr[int(idx/5), idx%5].set_title(str(predictions[idx]),fontsize=50 )

预测新图像批次
如果要预测一组新图像,只需在会话中对一批图像运行 conv_net函数即可进行预测。例如,以下内容可用于获取测试集中前25个图像的预测:
predictions = sess.run(tf.argmax(conv_net(test_images[:25], weights, biases), axis=1))
然后可以像上面一样将predictions (预测)用于显示图像。
预测单一图像
回想一下,模型期望输入具有形状[batch_size, height, width, channels]。这意味着,如果对单个图像进行预测,则需要扩展图像的维度,使第一个维度(batch_size)成为一个单一维度。这里预测了测试集中的第1000个图像。
img = test_images[1000]
print(img.shape) # [28, 28, 1]
img = np.expand_dims(img, 0)
print(img.shape) # [1, 28, 28, 1]
prediction = sess.run(tf.argmax(conv_net(img, weights, biases), axis=1))
plt.imshow(np.squeeze(img), cmap='gray')
plt.title(np.squeeze(prediction), fontsize=40)

预测概率
预测的归一化概率分布可以使用softmax,按conv_net 模型中的logits来计算。
idx = 1000
img = np.expand_dims(test_images[idx], 0)
plt.imshow(np.squeeze(img), cmap='gray')
# Predict value
prediction = conv_net(img, weights, biases)
probabilities = tf.nn.softmax(prediction)
probs = sess.run(probabilities)
probs = np.squeeze(probs)
# Plot probabilities
plt.figure(dpi=150)
plt.bar(range(10), probs)
for i in range(10):
plt.text(i-0.3, probs[i]+0.05, s='{:.2f}'.format(probs[i]), size=10)
plt.ylim([0,1.1])
plt.xticks(range(10))
plt.ylabel('Probability')
plt.xlabel('Predicted Number')
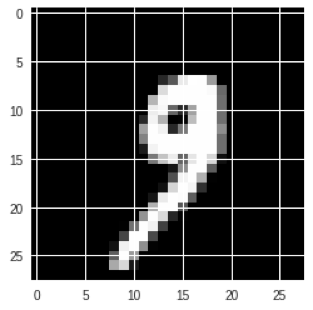
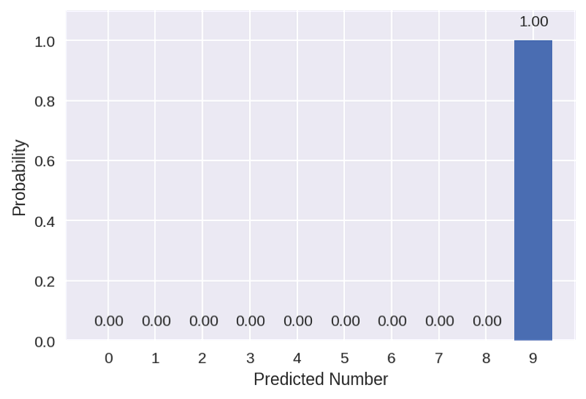
该模型预测该数字为9的概率很高。
有些数字对模型来说并不是那么容易预测。例如,这里是测试集中的另一个图像(idx=3062)。

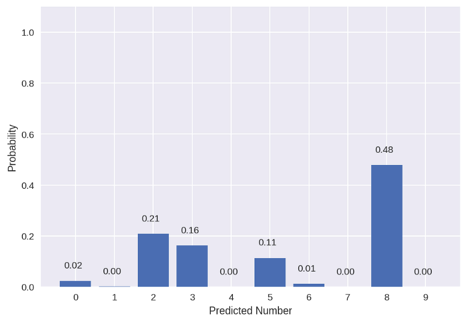
虽然模型的确预测8是最有可能的类,但它的概率只有0.48,而且其它几个数字的概率增加了。
以下是一个错误的预测样例(idx=259):

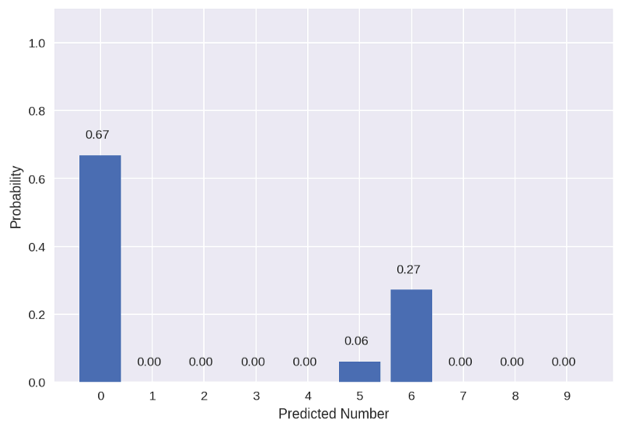
该模型错误地预测了0,而数字6只是可能性为第二的预测。
保存模型
如前所述,只要会话仍然打开,就可以进行预测。如果会话关闭,经过训练的权重和偏差将丢失。使用tf.train.Saver可以将会话和模型图以及经过训练的权重和偏差保存为检查点。
saver = tf.train.Saver()
saver.save(sess, './model.ckpt')
完整的代码样例
结合上面的信息,下面是一个脚本样例,用于创建、训练和保存卷积神经网络并显示对手写数字样本的预测。
import tensorflow as tf
import numpy as np
from tqdm import tqdm
from keras.datasets import mnist
from keras.utils import to_categorical
import matplotlib.pyplot as plt
# MNIST Dataset
(train_images, train_labels),(test_images, test_labels) = mnist.load_data()
train_images = np.expand_dims(train_images.astype(np.float32) / 255.0, axis=3)
test_images = np.expand_dims(test_images.astype(np.float32) / 255.0, axis=3)
train_labels = to_categorical(train_labels)
# Training parameters
batch_size = 128
n_epochs = 5
n_classes = 10
learning_rate = 1e-4
# 2D Convolutional Function
def conv2d(x, W, b, strides=1):
x = tf.nn.conv2d(x, W, strides=[1,1,1,1], padding='SAME')
x = tf.nn.bias_add(x, b)
return tf.nn.relu(x)
# Define Weights and Biases
weights = {
# Convolution Layers
'c1': tf.get_variable('W1', shape=(3,3,1,16),
initializer=tf.contrib.layers.xavier_initializer()),
'c2': tf.get_variable('W2', shape=(3,3,16,16),
initializer=tf.contrib.layers.xavier_initializer()),
'c3': tf.get_variable('W3', shape=(3,3,16,32),
initializer=tf.contrib.layers.xavier_initializer()),
'c4': tf.get_variable('W4', shape=(3,3,32,32),
initializer=tf.contrib.layers.xavier_initializer()),
# Dense Layers
'd1': tf.get_variable('W5', shape=(7*7*32,128),
initializer=tf.contrib.layers.xavier_initializer()),
'out': tf.get_variable('W6', shape=(128,n_classes),
initializer=tf.contrib.layers.xavier_initializer()),
}
biases = {
# Convolution Layers
'c1': tf.get_variable('B1', shape=(16), initializer=tf.zeros_initializer()),
'c2': tf.get_variable('B2', shape=(16), initializer=tf.zeros_initializer()),
'c3': tf.get_variable('B3', shape=(32), initializer=tf.zeros_initializer()),
'c4': tf.get_variable('B4', shape=(32), initializer=tf.zeros_initializer()),
# Dense Layers
'd1': tf.get_variable('B5', shape=(128), initializer=tf.zeros_initializer()),
'out': tf.get_variable('B6', shape=(n_classes), initializer=tf.zeros_initializer()),
}
# Model Function
def conv_net(data, weights, biases, training=False):
# Convolution layers
conv1 = conv2d(data, weights['c1'], biases['c1']) # [28,28,16]
conv2 = conv2d(conv1, weights['c2'], biases['c2']) # [28,28,16]
pool1 = tf.nn.max_pool(conv2, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME')
# [14,14,16]
conv3 = conv2d(pool1, weights['c3'], biases['c3']) # [14,14,32]
conv4 = conv2d(conv3, weights['c4'], biases['c4']) # [14,14,32]
pool2 = tf.nn.max_pool(conv4, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME')
# [7,7,32]
# Flatten
flat = tf.reshape(pool2, [-1, weights['d1'].get_shape().as_list()[0]])
# [7*7*32] = [1568]
# Fully connected layer
fc1 = tf.add(tf.matmul(flat, weights['d1']), biases['d1']) # [128]
fc1 = tf.nn.relu(fc1) # [128]
# Dropout
if training:
fc1 = tf.nn.dropout(fc1, rate=0.2)
# Output
out = tf.add(tf.matmul(fc1, weights['out']), biases['out']) # [10]
return out
# Dataflow Graph
dataset = tf.data.Dataset.from_tensor_slices((train_images,train_labels)).repeat().batch(batch_size)
iterator = dataset.make_initializable_iterator()
batch_images, batch_labels = iterator.get_next()
logits = conv_net(batch_images, weights, biases, training=True)
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=logits, labels=batch_labels))
optimizer = tf.train.AdamOptimizer(learning_rate)
train_op = optimizer.minimize(loss)
test_predictions = tf.nn.softmax(conv_net(test_images, weights, biases))
acc,acc_op = tf.metrics.accuracy(predictions=tf.argmax(test_predictions,1), labels=test_labels)
# Run Session
with tf.Session() as sess:
# Initialize Variables
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
sess.run(iterator.initializer)
# Train the Model
for epoch in range(n_epochs):
prog_bar = tqdm(range(int(len(train_images)/batch_size)))
for step in prog_bar:
_,cost = sess.run([train_op,loss])
prog_bar.set_description("cost: {:.3f}".format(cost))
accuracy = sess.run(acc_op)
print('nEpoch {} Accuracy: {:.3f}'.format(epoch+1, accuracy))
# Show Sample Predictions
predictions = sess.run(tf.argmax(conv_net(test_images[:25], weights, biases), axis=1))
f, axarr = plt.subplots(5, 5, figsize=(25,25))
for idx in range(25):
axarr[int(idx/5), idx%5].imshow(np.squeeze(test_images[idx]), cmap='gray')
axarr[int(idx/5), idx%5].set_title(str(predictions[idx]),fontsize=50)
# Save Model
saver = tf.train.Saver()
saver.save(sess, './model.ckpt')
Keras的等效模型
Keras是一种高阶API,可以通过使用其顺序模型API(功能API也是对更复杂的神经网络的一种选择)大大简化上述代码。
请注意,不需要使用会话。此外,模型权重和偏差不需要在模型外部定义。它们是在添加层时创建的,而且它们的形状是自动计算的。
from keras.models import Sequential, Model
from keras.layers import Dense, Activation, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D, Input
from keras.optimizers import Adam
from keras.datasets import mnist
from keras.utils import to_categorical
import numpy as np
# MNIST Dataset
(train_images, train_labels),(test_images, test_labels) = mnist.load_data()
train_images = np.expand_dims(train_images.astype(np.float32) / 255.0, axis=3)
test_images = np.expand_dims(test_images.astype(np.float32) / 255.0, axis=3)
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
# Training parameters
batch_size = 128
n_epochs = 5
n_classes = 10
# Create the model
model = Sequential()
# Convolution Layers
model.add(Conv2D(16, 3, activation='relu', input_shape=(28, 28, 1), padding='same'))
model.add(Conv2D(16, 3, activation='relu', padding='same'))
model.add(MaxPooling2D(pool_size=2, padding='same'))
model.add(Conv2D(32, 3, activation='relu', padding='same'))
model.add(Conv2D(32, 3, activation='relu', padding='same'))
model.add(MaxPooling2D(pool_size=2, padding='same'))
# Dense Layers
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(n_classes, activation='softmax'))
# Optimizer
optimizer = Adam(lr=1e-4)
# Compile
model.compile(loss='categorical_crossentropy',
optimizer=optimizer,
metrics=['categorical_accuracy'])
# Train model
model.fit(train_images,
train_labels,
epochs=n_epochs,
batch_size=batch_size,
validation_data=(test_images, test_labels)
)
# Show Sample Predictions
predictions = model.predict(test_images[:25])
predictions = np.argmax(predictions, axis=1)
f, axarr = plt.subplots(5, 5, figsize=(25,25))
for idx in range(25):
axarr[int(idx/5), idx%5].imshow(np.squeeze(test_images[idx]), cmap='gray')
axarr[int(idx/5), idx%5].set_title(str(predictions[idx]),fontsize=50)
# Save Model
model.save_weights("model.h5")
总结
TensorFlow图创建了计算数据流用于训练模型,而且这些会话用于实际训练中。本文展示了创建图和在训练对话中运行图时使用的不同步骤和选项。当大致了解了如何创建图并在会话中使用时,开发自定义神经网络和使用TensorFlow Core来满足特定需求就会变得更容易。
显而易见,keras更为简洁,并且该API有利于测试新的神经网络。然而,对于新的人工智能开发人员来说,许多步骤可能是“黑匣子”,而本教程可以帮助展示其后台发生的事情。

编译组:陈枫、黄琎
相关链接:
https://towardsdatascience.com/guide-to-coding-a-custom-convolutional-neural-network-in-tensorflow-bec694e36ad3
代码详解:TensorFlow Core带你探索深度神经网络“黑匣子”的更多相关文章
- 十图详解tensorflow数据读取机制(附代码)转知乎
十图详解tensorflow数据读取机制(附代码) - 何之源的文章 - 知乎 https://zhuanlan.zhihu.com/p/27238630
- Kaggle网站流量预测任务第一名解决方案:从模型到代码详解时序预测
Kaggle网站流量预测任务第一名解决方案:从模型到代码详解时序预测 2017年12月13日 17:39:11 机器之心V 阅读数:5931 近日,Artur Suilin 等人发布了 Kaggl ...
- JAVA类与类之间的全部关系简述+代码详解
本文转自: https://blog.csdn.net/wq6ylg08/article/details/81092056类和类之间关系包括了 is a,has a, use a三种关系(1)is a ...
- 基础 | batchnorm原理及代码详解
https://blog.csdn.net/qq_25737169/article/details/79048516 https://www.cnblogs.com/bonelee/p/8528722 ...
- DeepLearning tutorial(3)MLP多层感知机原理简介+代码详解
本文介绍多层感知机算法,特别是详细解读其代码实现,基于python theano,代码来自:Multilayer Perceptron,如果你想详细了解多层感知机算法,可以参考:UFLDL教程,或者参 ...
- springboot扫描自定义的servlet和filter代码详解_java - JAVA
文章来源:嗨学网 敏而好学论坛www.piaodoo.com 欢迎大家相互学习 这几天使用spring boot编写公司一个应用,在编写了一个filter,用于指定编码的filter,如下: /** ...
- ARM Cortex-M底层技术(2)—启动代码详解
杂谈 工作了一天,脑袋比较乱.一直想把底层的知识写成一个系列,希望可以坚持下去.为什么要写底层的东西呢?首先,工作用到了这部分内容,最近和内部Flash打交道比较多,自然而然会接触到一些底层的东西:第 ...
- 详解Net Core Web Api项目与在NginX下发布
前言 本文将介绍Net Core的一些基础知识和如何NginX下发布Net Core的WebApi项目. 测试环境 操作系统:windows 10 开发工具:visual studio 2019 框架 ...
- BM算法 Boyer-Moore高质量实现代码详解与算法详解
Boyer-Moore高质量实现代码详解与算法详解 鉴于我见到对算法本身分析非常透彻的文章以及实现的非常精巧的文章,所以就转载了,本文的贡献在于将两者结合起来,方便大家了解代码实现! 算法详解转自:h ...
随机推荐
- 蓝桥杯省赛 牌型种数java
小明被劫持到X赌城,被迫与其他3人玩牌. 一副扑克牌(去掉大小王牌,共52张),均匀发给4个人,每个人13张.这时,小明脑子里突然冒出一个问题:如果不考虑花色,只考虑点数,也不考虑自己得到的牌的先后顺 ...
- 新建git仓库并与github同步
windows系统,GitExtentions. 如果在一个空目录克隆一个github仓库: 1. 在一个空目录下,点击右键,点击Clone 2. 设置: 3. 点击加载SSH密钥.参看 GitExt ...
- 【CentOS】设置定时执行任务
1.Crond服务启动状态确认 service crond status crond (pid ) を実行中... 2.追加新的执行任务 crontab -e #Ansible: dnsmasq fo ...
- js中Array的map()函数,其中的回调函数还能这么用
<!DOCTYPE html><html><head><meta charset="utf-8"><title>菜鸟教程 ...
- 知识点:Mysql 数据库索引优化实战(4)
知识点:Mysql 索引原理完全手册(1) 知识点:Mysql 索引原理完全手册(2) 知识点:Mysql 索引优化实战(3) 知识点:Mysql 数据库索引优化实战(4) 一:插入订单 业务逻辑:插 ...
- linux杂记
find [path] -name fileName find /home/audio/mrcp-asr/audio -type f -newermt '2019-04-23 00:00' ! -ne ...
- 配置samba的流程
1.关闭防火墙和selinuxservice iptables stopsetenforce 02.配置本地yummount /dev/cdrom /mediacd /etc/yum.repos.dc ...
- 入门Spring ioc
简单的来记录一下自己的SSM框架入门--------IOC篇段 ioc(控制反转 -将对象的创建的权利从类型本身来创建,来交给spring工厂来创建)的配置. <bean>:是可以指spr ...
- c#经典三层框架中的SqlHelper帮助类
using System; using System.Collections.Generic; using System.Configuration; using System.Data; using ...
- matlab-双摆仿真
在物理学和数学中,在动力系统领域,双摆是一个摆锤,另一个摆锤连接在其末端,是一个简单的物理系统,具有丰富的动态特性,对初始条件具有很强的敏感性.双摆的运动由一组耦合的常微分方程控制并且是混沌的. 由于 ...