ElasticSearch6.5.0 【安装IK分词器】
不得不夸奖一下ES的周边资源,比如这个IK分词器,紧跟ES的版本,卢本伟牛逼!另外ES更新太快了吧,几乎不到半个月一个小版本就发布了!!目前已经发了6.5.2,估计我还没怎么玩就到7.0了。
下载
分词器:GitHub
点击release,下载对应的版本,他这个跟ES是一一对应的。
安装
他这个安装非常容易!业界良心啊!!
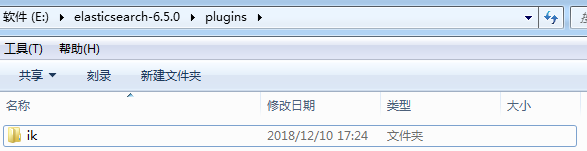
第一步:在elasticsearch-6.5.0主目录下的plugins目录新建一个ik文件夹
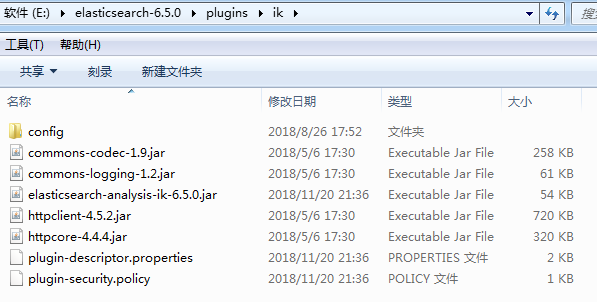
第二步:把从GitHub下载下来的压缩包解压到这个文件夹
启动
进入ES主目录
[E:\elasticsearch-6.5.]$ .\bin\elasticsearch.bat
准备数据
依赖:
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.11.1</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.11.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.25</version>
</dependency> <dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>6.5.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>6.5.0</version>
</dependency>
连接:
package com.demo.dao; import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient; /**
* Java高级REST客户机在Java低级REST客户机之上工作。它的主要目标是公开特定于API的方法,这些方法接受请求对象作为参数并返回响应对象
* 可以同步或异步调用每个API。同步方法返回一个响应对象,而异步方法(其名称以async后缀结尾)需要一个侦听器参数
* 一旦接收到响应或错误,侦听器参数(在低层客户机管理的线程池上)将被通知。
* Java高级REST客户机依赖于Elasticsearch核心项目。它接受与TransportClient相同的请求参数,并返回相同的响应对象。
* Java高级REST客户机需要Java 1.8
* 客户机版本与开发客户机的Elasticsearch版本相同
* 6.0客户端能够与任意6.X节点通信,6.1客户端能够与6.1、6.2和任意6.X通信
*/
public class RestClientFactory { private RestClientFactory(){} private static class Inner{
private static final RestClientFactory instance = new RestClientFactory();
} public static RestClientFactory getInstance(){
return Inner.instance;
} public RestHighLevelClient getClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
//new HttpHost("localhost", 9201, "http"),
new HttpHost("localhost", , "http")
)
);
return client;
} }
代码:
/**
* 创建索引
* @return
* @throws IOException
*/
public static RestHighLevelClient createIndexForIk() throws IOException {
RestHighLevelClient client = RestClientFactory.getInstance().getClient();
CreateIndexRequest request = new CreateIndexRequest("test_ik_index");
request.settings(Settings.builder()
.put("index.number_of_shards", 1)
.put("index.number_of_replicas", 1))
// 设置mapping
.mapping("social", "content1","type=text", "content2", "type=text,analyzer=ik_smart","content3", "type=text,analyzer=ik_max_word")
// 创建超时
.timeout(TimeValue.timeValueMinutes(2))
// 连接到主节点超时时间
.masterNodeTimeout(TimeValue.timeValueMinutes(1));
CreateIndexResponse indexResponse = client.indices().create(request, RequestOptions.DEFAULT);
boolean acknowledged = indexResponse.isAcknowledged();
boolean shardsAcknowledged = indexResponse.isShardsAcknowledged();
System.out.println(acknowledged + "," + shardsAcknowledged);
return client;
} /**
* 准备数据
* @return
* @throws IOException
*/
public static RestHighLevelClient bulkAddForIk() throws IOException {
RestHighLevelClient client = RestClientFactory.getInstance().getClient();
BulkRequest request = new BulkRequest();
request.add(new IndexRequest("test_ik_index", "social", "1")
.source(XContentType.JSON,"content1", "富强、民主、文明、和谐,自由、平等、公正、法治,爱国、敬业、诚信、友善",
"content2", "“富强、民主、文明、和谐”,是我国社会主义现代化国家的建设目标,也是从价值目标层面对社会主义核心价值观基本理念的凝练,在社会主义核心价值观中居于最高层次,对其他层次的价值理念具有统领作用",
"content3", "富强、民主、文明、和谐,自由、平等、公正、法治,爱国、敬业、诚信、友善"));
request.add(new IndexRequest("test_ik_index", "social", "2")
.source(XContentType.JSON,"content1", "以热爱祖国为荣,以危害祖国为耻",
"content2", "1978年12月,党的十一届三中全会重新恢复和确立了实事求是的思想路线,坚持把马克思主义与改革开放和我国社会主义建设伟大实践相结合,科学继承了***思想,创立了邓小平理论、“三个代表”重要思想、科学发展观等马克思主义中国化最新成果,马克思主义在意识形态领域的指导地位不断巩固",
"content3", "“自由、平等、公正、法治”,是对美好社会的生动表述,也是从社会层面对社会主义核心价值观基本理念的凝练"));
request.add(new IndexRequest("test_ik_index", "social", "3")
.source(XContentType.JSON,"content1", "以服务人民为荣,以背离人民为耻",
"content2", "新中国的建立,确立了以社会主义基本政治制度、基本经济制度的确立和以马克思主义为指导思想的社会主义意识形态,为社会主义核心价值体系建设奠定了政治前提、物质基础和文化条件",
"content3", "“爱国、敬业、诚信、友善”,是公民基本道德规范,是从个人行为层面对社会主义核心价值观基本理念的凝练"));
BulkResponse bulk = client.bulk(request, RequestOptions.DEFAULT);
System.out.println("Status:" + bulk.status().name() + ",hasFailures:" + bulk.hasFailures());
MultiGetRequest multiGetRequest = new MultiGetRequest()
.add(new MultiGetRequest.Item("test_ik_index", "social", "1"))
.add(new MultiGetRequest.Item("test_ik_index", "social", "2"))
.add(new MultiGetRequest.Item("test_ik_index", "social", "3"));
MultiGetResponse response = client.mget(multiGetRequest, RequestOptions.DEFAULT);
MultiGetItemResponse[] itemResponses = response.getResponses();
for(MultiGetItemResponse r : itemResponses){
System.out.println(r.getResponse().getSourceAsString());
}
return client;
}
执行
public static void main(String[] args) throws IOException, ExecutionException, InterruptedException {
createIndexForIk().close();
bulkAddForIk().close();
}
我有三个字段:content1--用的默认分词器;content2:用的ik_smart;content3:用的ik_max_word
测试(在Kibana控制台里)
第一个查询:(可见默认的没有正确分词,看highlight字段)
GET /test_ik_index/_search
{
"query" : {
"match": { "content1": "中国" }
},
"highlight" : {
"pre_tags" : ["<tag1>"],
"post_tags" : ["</tag1>"],
"fields" : {
"content1": {}
}
}
} -------------------------------
{
"took" : ,
"timed_out" : false,
"_shards" : {
"total" : ,
"successful" : ,
"skipped" : ,
"failed" :
},
"hits" : {
"total" : ,
"max_score" : 0.68320733,
"hits" : [
{
"_index" : "test_ik_index",
"_type" : "social",
"_id" : "",
"_score" : 0.68320733,
"_source" : {
"content1" : "以热爱祖国为荣,以危害祖国为耻",
"content2" : "1978年12月,党的十一届三中全会重新恢复和确立了实事求是的思想路线,坚持把马克思主义与改革开放和我国社会主义建设伟大实践相结合,科学继承了***思想,创立了邓小平理论、“三个代表”重要思想、科学发展观等马克思主义中国化最新成果,马克思主义在意识形态领域的指导地位不断巩固",
"content3" : "“自由、平等、公正、法治”,是对美好社会的生动表述,也是从社会层面对社会主义核心价值观基本理念的凝练"
},
"highlight" : {
"content1" : [
"以热爱祖<tag1>国</tag1>为荣,以危害祖<tag1>国</tag1>为耻"
]
}
},
{
"_index" : "test_ik_index",
"_type" : "social",
"_id" : "",
"_score" : 0.40610588,
"_source" : {
"content1" : "富强、民主、文明、和谐,自由、平等、公正、法治,爱国、敬业、诚信、友善",
"content2" : "“富强、民主、文明、和谐”,是我国社会主义现代化国家的建设目标,也是从价值目标层面对社会主义核心价值观基本理念的凝练,在社会主义核心价值观中居于最高层次,对其他层次的价值理念具有统领作用",
"content3" : "富强、民主、文明、和谐,自由、平等、公正、法治,爱国、敬业、诚信、友善"
},
"highlight" : {
"content1" : [
"富强、民主、文明、和谐,自由、平等、公正、法治,爱<tag1>国</tag1>、敬业、诚信、友善"
]
}
}
]
}
}
第二个:(ok)
GET /test_ik_index/_search
{
"query" : {
"match": { "content2": "马克思主义" }
},
"highlight" : {
"pre_tags" : ["<tag1>"],
"post_tags" : ["</tag1>"],
"fields" : {
"content2": {}
}
}
} -------------------------------
{
"took" : ,
"timed_out" : false,
"_shards" : {
"total" : ,
"successful" : ,
"skipped" : ,
"failed" :
},
"hits" : {
"total" : ,
"max_score" : 0.71390307,
"hits" : [
{
"_index" : "test_ik_index",
"_type" : "social",
"_id" : "",
"_score" : 0.71390307,
"_source" : {
"content1" : "以热爱祖国为荣,以危害祖国为耻",
"content2" : "1978年12月,党的十一届三中全会重新恢复和确立了实事求是的思想路线,坚持把马克思主义与改革开放和我国社会主义建设伟大实践相结合,科学继承了***思想,创立了邓小平理论、“三个代表”重要思想、科学发展观等马克思主义中国化最新成果,马克思主义在意识形态领域的指导地位不断巩固",
"content3" : "“自由、平等、公正、法治”,是对美好社会的生动表述,也是从社会层面对社会主义核心价值观基本理念的凝练"
},
"highlight" : {
"content2" : [
"1978年12月,党的十一届三中全会重新恢复和确立了实事求是的思想路线,坚持把<tag1>马克思主义</tag1>与改革开放和我国社会主义建设伟大实践相结合,科学继承了***思想,创立了邓小平理论、“三个代表”重要思想、科学发展观等<tag1>马克思主义</tag1>中国化最新成果",
",<tag1>马克思主义</tag1>在意识形态领域的指导地位不断巩固"
]
}
},
{
"_index" : "test_ik_index",
"_type" : "social",
"_id" : "",
"_score" : 0.50678647,
"_source" : {
"content1" : "以服务人民为荣,以背离人民为耻",
"content2" : "新中国的建立,确立了以社会主义基本政治制度、基本经济制度的确立和以马克思主义为指导思想的社会主义意识形态,为社会主义核心价值体系建设奠定了政治前提、物质基础和文化条件",
"content3" : "“爱国、敬业、诚信、友善”,是公民基本道德规范,是从个人行为层面对社会主义核心价值观基本理念的凝练"
},
"highlight" : {
"content2" : [
"新中国的建立,确立了以社会主义基本政治制度、基本经济制度的确立和以<tag1>马克思主义</tag1>为指导思想的社会主义意识形态,为社会主义核心价值体系建设奠定了政治前提、物质基础和文化条件"
]
}
}
]
}
}
第三个:(ok)
GET /test_ik_index/_search
{
"query" : {
"match": { "content3": "富强" }
},
"highlight" : {
"pre_tags" : ["<tag1>"],
"post_tags" : ["</tag1>"],
"fields" : {
"content3" : {}
}
}
} -----------------------------------
{
"took" : ,
"timed_out" : false,
"_shards" : {
"total" : ,
"successful" : ,
"skipped" : ,
"failed" :
},
"hits" : {
"total" : ,
"max_score" : 1.2146692,
"hits" : [
{
"_index" : "test_ik_index",
"_type" : "social",
"_id" : "",
"_score" : 1.2146692,
"_source" : {
"content1" : "富强、民主、文明、和谐,自由、平等、公正、法治,爱国、敬业、诚信、友善",
"content2" : "“富强、民主、文明、和谐”,是我国社会主义现代化国家的建设目标,也是从价值目标层面对社会主义核心价值观基本理念的凝练,在社会主义核心价值观中居于最高层次,对其他层次的价值理念具有统领作用",
"content3" : "富强、民主、文明、和谐,自由、平等、公正、法治,爱国、敬业、诚信、友善"
},
"highlight" : {
"content3" : [
"<tag1>富强</tag1>、民主、文明、和谐,自由、平等、公正、法治,爱国、敬业、诚信、友善"
]
}
}
]
}
}
你也可以单独验证分词器
GET test_ik_index/_analyze
{
"analyzer": "ik_max_word",
"text": "中央高度重视培育和践行社会主义核心价值观"
} -----------------------
{
"tokens" : [
{
"token" : "中央",
"start_offset" : ,
"end_offset" : ,
"type" : "CN_WORD",
"position" :
},
{
"token" : "高度重视",
"start_offset" : ,
"end_offset" : ,
"type" : "CN_WORD",
"position" :
},
{
"token" : "高度",
"start_offset" : ,
"end_offset" : ,
"type" : "CN_WORD",
"position" :
},
{
"token" : "重视",
"start_offset" : ,
"end_offset" : ,
"type" : "CN_WORD",
"position" :
},
{
"token" : "培育",
"start_offset" : ,
"end_offset" : ,
"type" : "CN_WORD",
"position" :
},
{
"token" : "和",
"start_offset" : ,
"end_offset" : ,
"type" : "CN_CHAR",
"position" :
},
{
"token" : "践行",
"start_offset" : ,
"end_offset" : ,
"type" : "CN_WORD",
"position" :
},
{
"token" : "行社",
"start_offset" : ,
"end_offset" : ,
"type" : "CN_WORD",
"position" :
},
{
"token" : "社会主义",
"start_offset" : ,
"end_offset" : ,
"type" : "CN_WORD",
"position" :
},
{
"token" : "社会",
"start_offset" : ,
"end_offset" : ,
"type" : "CN_WORD",
"position" :
},
{
"token" : "主义",
"start_offset" : ,
"end_offset" : ,
"type" : "CN_WORD",
"position" :
},
{
"token" : "核心",
"start_offset" : ,
"end_offset" : ,
"type" : "CN_WORD",
"position" :
},
{
"token" : "价值观",
"start_offset" : ,
"end_offset" : ,
"type" : "CN_WORD",
"position" :
},
{
"token" : "价值",
"start_offset" : ,
"end_offset" : ,
"type" : "CN_WORD",
"position" :
},
{
"token" : "观",
"start_offset" : ,
"end_offset" : ,
"type" : "CN_CHAR",
"position" :
}
]
}
还可以通过Java API
public static RestHighLevelClient analyze() throws IOException {
RestHighLevelClient client = RestClientFactory.getInstance().getClient();
AnalyzeRequest request = new AnalyzeRequest();
request.text("高通指控苹果侵犯其两项专利", "高通再次将苹果告上法庭,起诉苹果拖欠专利费 70 亿美元");
request.analyzer("ik_smart");
AnalyzeResponse response = client.indices().analyze(request, RequestOptions.DEFAULT);
List<AnalyzeResponse.AnalyzeToken> tokens = response.getTokens();
for(AnalyzeResponse.AnalyzeToken t : tokens){
int endOffset = t.getEndOffset();
int position = t.getPosition();
int positionLength = t.getPositionLength();
int startOffset = t.getStartOffset();
String term = t.getTerm();
String type = t.getType();
System.out.println("Start:" + startOffset + ",End:" + endOffset + ",Position:" + position + ",Length:" + positionLength +
",Term:" + term + ",Type:" + type);
}
return client;
}
结果:
Start:,End:,Position:,Length:,Term:高,Type:CN_CHAR
Start:,End:,Position:,Length:,Term:通,Type:CN_CHAR
Start:,End:,Position:,Length:,Term:指控,Type:CN_WORD
Start:,End:,Position:,Length:,Term:苹果,Type:CN_WORD
Start:,End:,Position:,Length:,Term:侵犯,Type:CN_WORD
Start:,End:,Position:,Length:,Term:其,Type:CN_CHAR
Start:,End:,Position:,Length:,Term:两项,Type:CN_WORD
Start:,End:,Position:,Length:,Term:专利,Type:CN_WORD
Start:,End:,Position:,Length:,Term:高,Type:CN_CHAR
Start:,End:,Position:,Length:,Term:通,Type:CN_CHAR
Start:,End:,Position:,Length:,Term:再次,Type:CN_WORD
Start:,End:,Position:,Length:,Term:将,Type:CN_CHAR
Start:,End:,Position:,Length:,Term:苹果,Type:CN_WORD
Start:,End:,Position:,Length:,Term:告,Type:CN_CHAR
Start:,End:,Position:,Length:,Term:上,Type:CN_CHAR
Start:,End:,Position:,Length:,Term:法庭,Type:CN_WORD
Start:,End:,Position:,Length:,Term:起诉,Type:CN_WORD
Start:,End:,Position:,Length:,Term:苹果,Type:CN_WORD
Start:,End:,Position:,Length:,Term:拖欠,Type:CN_WORD
Start:,End:,Position:,Length:,Term:专利费,Type:CN_WORD
Start:,End:,Position:,Length:,Term:,Type:ARABIC
Start:,End:,Position:,Length:,Term:亿,Type:TYPE_CNUM
Start:,End:,Position:,Length:,Term:美元,Type:CN_WORD
到此为止,分词器安装完毕
小插曲:文本有***不让发布。。。。

ElasticSearch6.5.0 【安装IK分词器】的更多相关文章
- Linux下,非Docker启动Elasticsearch 6.3.0,安装ik分词器插件,以及使用Kibana测试Elasticsearch,
Linux下,非Docker启动Elasticsearch 6.3.0 查看java版本,需要1.8版本 java -version yum -y install java 创建用户,因为elasti ...
- Linux使用Docker启动Elasticsearch并配合Kibana使用,安装ik分词器
注意事项 这里我的Linux虚拟机的IP地址是192.168.1.3 Docker运行Elasticsearch容器之后不会立即有反应,要等一会,等待容器内部启动Elasticsearch,才可以访问 ...
- 如何开发自己的搜索帝国之安装ik分词器
Elasticsearch默认提供的分词器,会把每个汉字分开,而不是我们想要的根据关键词来分词,我是中国人 不能简单的分成一个个字,我们更希望 “中国人”,“中国”,“我”这样的分词,这样我们就需要 ...
- Elasticsearch入门之从零开始安装ik分词器
起因 需要在ES中使用聚合进行统计分析,但是聚合字段值为中文,ES的默认分词器对于中文支持非常不友好:会把完整的中文词语拆分为一系列独立的汉字进行聚合,显然这并不是我的初衷.我们来看个实例: POST ...
- Elasticsearch下安装ik分词器
安装ik分词器(必须安装maven) 上传相应jar包 解压到相应目录 unzip elasticsearch-analysis-ik-master.zip(zip包) cp -r elasticse ...
- 【ELK】【docker】【elasticsearch】1. 使用Docker和Elasticsearch+ kibana 5.6.9 搭建全文本搜索引擎应用 集群,安装ik分词器
系列文章:[建议从第二章开始] [ELK][docker][elasticsearch]1. 使用Docker和Elasticsearch+ kibana 5.6.9 搭建全文本搜索引擎应用 集群,安 ...
- Elastic Stack 笔记(二)Elasticsearch5.6 安装 IK 分词器和 Head 插件
博客地址:http://www.moonxy.com 一.前言 Elasticsearch 作为开源搜索引擎服务器,其核心功能在于索引和搜索数据.索引是把文档写入 Elasticsearch 的过程, ...
- ElasticSearch5.3安装IK分词器并验证
ElasticSearch5.3安装IK分词器 之前使用Elasticsearch安装head插件成功了,但是安装IK分词器却失败了.貌似是ElasticSearch5.0以后就不支持直接在elast ...
- windows下elasticsearch安装ik分词器后无法启动
windows下elasticsearch安装ik分词器后启动报如下图错误: 然后百度说是elasticsearch路径有空格,一看果然我的路径有空格,然后重新换个路径就好了.
随机推荐
- shiro框架的UsernamePasswordToken与对应Realm中的AuthenticationToken的一点比较
这里以简单的登陆为例子 控制器对应的登陆方法: @RequestMapping(value = "/login", method = RequestMethod.GET) publ ...
- Operation not allowed on a unidirectional dataset错误?
关于网友提出的“ Operation not allowed on a unidirectional dataset错误?”问题疑问,本网通过在网上对“ Operation not allowed o ...
- delphi中如何实现DBGrid中的两列数据想减并存入另一列
可参考下面的例子: 数据自动计算的实现:“金额”是由“单价”和“工程量”相乘直接得来的,勿需人工输入. 这可在“数据源构件”的onupdatedata例程添加如下代码实现: procedure T ...
- npm安裝、卸載、刪除、撤銷發佈包、更新版本信息
利用npm安裝包: 全局安裝:npm install -g 模塊安裝 局部安裝(可以使用repuire(‘模塊名’)引用):npm install 模塊名稱 如果權限不夠,就是用管理員方式安裝. 本地 ...
- chrome中 GET /undefined 404
Chrome中调试网站,会出现 这是由 crxMouse Chrome™ 手势 引起的,关闭即可
- org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'org.mybatis.spring.mapper.MapperScannerConfigurer#0'
七月 05, 2018 10:26:54 上午 org.apache.tomcat.util.digester.SetPropertiesRule begin警告: [SetPropertiesRul ...
- Codeforces Round #441 Div. 1
A:显然答案与原数的差不会很大. #include<iostream> #include<cstdio> #include<cmath> #include<c ...
- 第三十八天 GIL 进程池与线程池
今日内容: 1.GIL 全局解释器锁 2.Cpython解释器并发效率验证 3.线程互斥锁和GIL对比 4.进程池与线程池 一.全局解释器锁 1.GIL:全局解释器锁 GIL本质就是一把互斥锁,是夹在 ...
- CSS初步学习
1.选择器: 如果你要在HTML元素中设置CSS样式,你需要在元素中设置"id" 和 "class"选择器. id 选择器 id 选择器可以为标有特定 id 的 ...
- 洛谷P1414又是毕业季二题解
题目 思想: 首先这个题必定是一个数学题,肯定不是一个一个枚举得到解,这样肯定会T,所以我们就应该想一些别的方法,. 分析: 比如,答案,一定是递减的,因为该答案所满足的条件肯定是越来越苛刻的,所以我 ...