python爬虫之天气预报网站--查看最近(15天)的天气信息(正则表达式)
python爬虫之天气预报网站--查看最近(15天)的天气信息(正则表达式)
思路:
1.首先找到一个自己想要查看天气预报的网站,选择自己想查看的地方,查看天气(例:http://www.tianqi.com/xixian1/15/)
2.打开"网页源代码",分析自己想要获取数据的特点
3.运用正则表达式来对数据进行处理,获得自己想要的数据 #网站可能反爬虫,需要绕过,这里用浏览器的代理(python默认的用户代理是自己,需要改成浏览器的用户代理,这样就能绕过一些网站简单的反爬虫)
4.获得数据后,对数据进行简单的美化
5.把数据写入文件(用pickle模块)
2.打开"网页源代码",分析自己想要获取数据的特点(不同网站的数据不同,需要具体问题具体分析)

3.1被网站禁止爬虫效果图如下:

3.2运用正则表达式来对数据进行处理,获得自己想要的数据
代码如下:
查看天气预报
import re
import requests
from prettytable import PrettyTable
url="http://www.tianqi.com/xixian1/15/"
#绕过网站反爬虫
txt=requests.get(url,headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36","Host":"www.tianqi.com"}).text
#print(txt)
s1=re.compile(r'<b>(\d\d月\d\d日)</b>') #日期
print(s1.findall(txt))
s2=re.compile(r'<li class="temp">(.+) (-?\d+)(\W+)<b>(-?\d+)</b>℃</li>')
print(s2.findall(txt))
s3=re.compile('>(.{1,4})</b></li>')
print(s3.findall(txt))
s4=re.compile(r'<li>([\u4e00-\u9fa5].+)</li>')
print(s4.findall(txt))
tianqi=[]
for i in range(len(s1.findall(txt))):
tianqi.append([s1.findall(txt)[i],s2.findall(txt)[i][0],s2.findall(txt)[i][1]+s2.findall(txt)[i][2]+s2.findall(txt)[i][3],s3.findall(txt)[i],s4.findall(txt)[i]]) print(tianqi)
ptable=PrettyTable('日期 天气 气温(℃) 空气质量 风级'.split())
for i in tianqi:
ptable.add_row(i)
print(ptable)
运行效果如下:
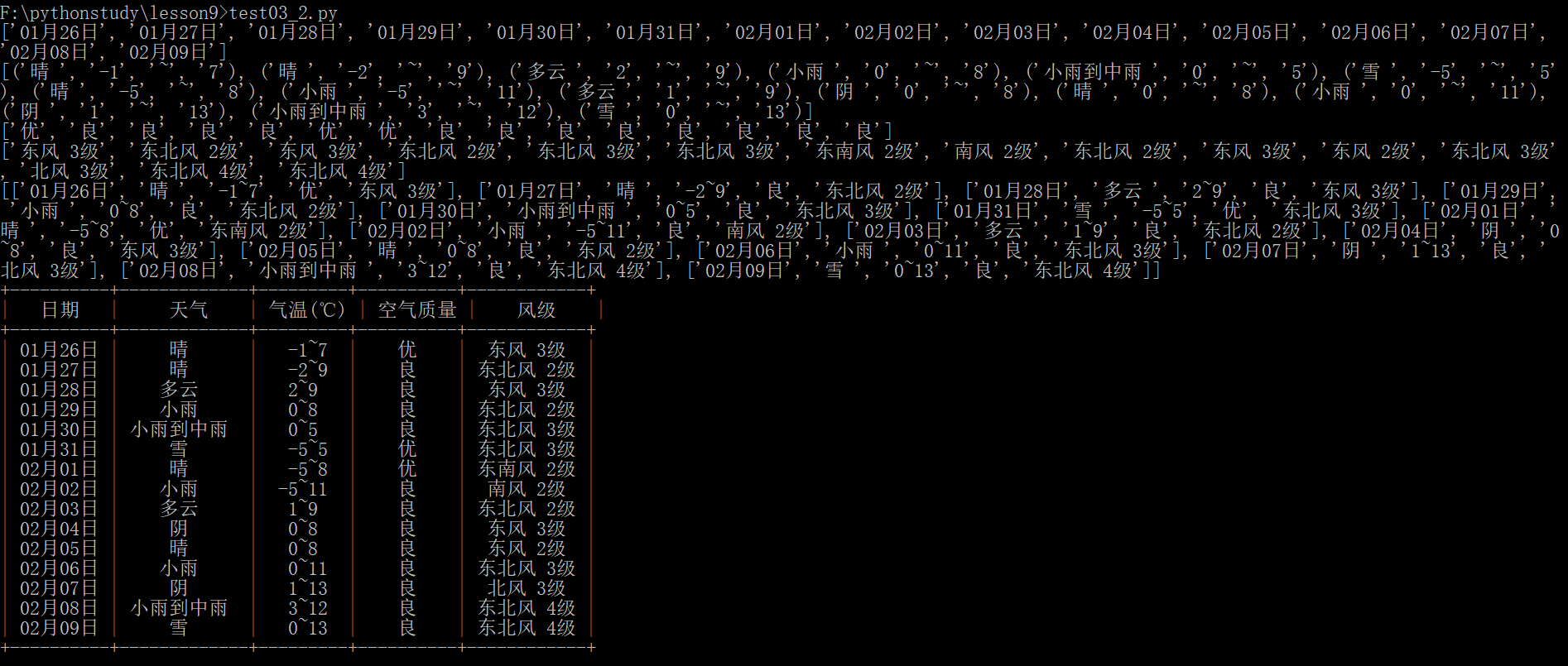
5.把数据写入文件(pickle)
代码如下:
import re
import requests
import pickle
from prettytable import PrettyTable
url="http://www.tianqi.com/xixian1/15/"
#绕过网站反爬虫
#把内容写入到文件中(序列化)
try:
with open("tianqi.txt","rb") as f:
txt=pickle.load(f)
print("结果已加载")
except:
txt=requests.get(url,headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36","Host":"www.tianqi.com"}).text
with open("tianqi.txt","wb") as f:
pickle.dump(txt,f)
print("文件已写入!")
#print(txt)
s1=re.compile(r'<b>(\d\d月\d\d日)</b>') #日期
print(s1.findall(txt))
s2=re.compile(r'<li class="temp">(.+) (-?\d+)(\W+)<b>(-?\d+)</b>℃</li>')
print(s2.findall(txt))
s3=re.compile('>(.{1,4})</b></li>')
print(s3.findall(txt))
s4=re.compile(r'<li>([\u4e00-\u9fa5].+)</li>')
print(s4.findall(txt))
tianqi=[]
for i in range(len(s1.findall(txt))):
tianqi.append([s1.findall(txt)[i],s2.findall(txt)[i][0],s2.findall(txt)[i][1]+s2.findall(txt)[i][2]+s2.findall(txt)[i][3],s3.findall(txt)[i],s4.findall(txt)[i]]) print(tianqi)
ptable=PrettyTable('日期 天气 气温(℃) 空气质量 风级'.split())
for i in tianqi:
ptable.add_row(i)
print(ptable)
python爬虫之天气预报网站--查看最近(15天)的天气信息(正则表达式)的更多相关文章
- python爬虫之12306网站--火车票信息查询
python爬虫之12306网站--火车票信息查询 思路: 1.火车票信息查询是基于车站信息查询,先完成车站信息查询,然后根据车站信息查询生成的url地址去查询当前已知出发站和目的站的所有车次车票信息 ...
- python爬虫之小说网站--下载小说(正则表达式)
python爬虫之小说网站--下载小说(正则表达式) 思路: 1.找到要下载的小说首页,打开网页源代码进行分析(例:https://www.kanunu8.com/files/old/2011/244 ...
- Python爬虫某招聘网站的岗位信息
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:阿尔法游戏 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- python爬虫之12306网站--车站信息查询
python爬虫查询车站信息 目录: 1.找到要查询的url 2.对信息进行分析 3.对信息进行处理 python爬虫查询全拼相同的车站 目录: 1.找到要查询的url 2.对信息进行分析 3.对信息 ...
- 利用Python爬虫刷新某网站访问量
前言:前一段时间看到有博友写了爬虫去刷新博客访问量一篇文章,当时还觉得蛮有意思的,就保存了一下,但是当我昨天准备复现的时候居然发现文章404了.所以本篇文章仅供学习交流,严禁用于商业用途 很多人学习p ...
- Python爬虫: "追新番"网站资源链接爬取
“追新番”网站 追新番网站提供最新的日剧和日影下载地址,更新比较快. 个人比较喜欢看日剧,因此想着通过爬取该网站,做一个资源地图 可以查看网站到底有哪些日剧,并且随时可以下载. 资源地图 爬取的资源地 ...
- 编写python爬虫采集彩票网站数据,将数据写入mongodb数据库
1.准备工作: 1.1安装requests: cmd >> pip install requests 1.2 安装lxml: cmd >> pip install lxml ...
- python爬虫1——获取网站源代码(豆瓣图书top250信息)
# -*- coding: utf-8 -*- import requests import re import sys reload(sys) sys.setdefaultencoding('utf ...
- python爬虫爬小说网站涉及到(js加密,CSS加密)
我是对于xxxx小说网进行爬取只讲思路不展示代码请见谅 一.涉及到的反爬 js加密 css加密 请求头中的User-Agent以及 cookie 二.思路 1.对于js加密 对于有js加密信息,我们一 ...
随机推荐
- eclipse中打断点debug无效
今天在测试的时候,发现在eclipse中打了断点,debug居然无效.结果是因为我无意开启了另一个功能,Run-->Skip All Breakpoints (忽略所有的断点) 快捷键:Ctrl ...
- npm设置和查看仓库源
转载请注明出处:https://www.cnblogs.com/wenjunwei/p/10078460.html 在使用npm命令时,如果直接从国外的仓库下载依赖,下载速度很慢,甚至会下载不下来,我 ...
- Dubbo 入门之二 ——- 项目结构解析
本文主要说明点 概述 背景 需求 架构 Dubbo源代码项目结构 概述 分享 Dubbo 的项目结构 ,通过本文可以大致了解到Dubbo整个项目的结构 背景 将一个项目进行拆分, 进行分布式架构. 需 ...
- Go基础系列:函数(1)
Go中函数特性简介 对Go中的函数特性做一个总结.懂则看,不懂则算. Go中有3种函数:普通函数.匿名函数(没有名称的函数).方法(定义在struct上的函数). Go编译时不在乎函数的定义位置,但建 ...
- Git+Gitlab+Ansible的roles实现一键部署Nginx静态网站(一)--技术流ken
前言 截止目前已经写了<Ansible基础认识及安装使用详解(一)--技术流ken>,<Ansible常用模块介绍及使用(二)--技术流ken><Ansible剧本介绍及 ...
- python的一些内置模块
整理了几种python的常用内置模块. 内置函数思维导图:https://www.processon.com/view/link/5c7902b1e4b0168e4200846a re模块 re(re ...
- 第一册:lesson forty nine。
原文: At the butcher's A:Do you want any meat today,Mrs.B? B:Yes,please. A:Do you want beef or lamb? B ...
- Postgresql ODBC驱动,用sqlserver添加dblink跨库访问postgresql数据库
在同样是SQLserver数据库跨库访问时,只需要以下方法 declare @rowcount int set @rowcount =(select COUNT(*) from sys.servers ...
- PATH环境变量
PATH是环境变量,要大写 那几个目录是你放置linux命令的目录,输入命令后系统会去PATH中寻找是否存在该命令 查看当前环境变量: echo $PATH 也可以用set命令看一下 设置: expo ...
- C#反射、方法调用、自动调用方法、根据按钮名称调用方法、C#按钮权限管理
根据按钮名称,直接调用方法,适用于用户对按钮的操作权限管理. /// <summary> /// 菜单按钮点击事件 /// </summary> void usrMenu1_U ...