python 爬虫得到网页的图片
import urllib.request,os
import re # 获取html 中的内容
def getHtml(url):
page=urllib.request.urlopen(url)
html=page.read()
return html path='本地存储位置' # 保存路径
def saveFile(x):
if not os.path.isdir(path):
os.makedirs(path)
t = os.path.join(path,'%s.jpg'%x)
return t html=getHtml('https://。。。') # 获取网页的图片
def getImg(html):
# 正则表达式
reg=r'src="(https://imgsa[^>]+\.(?:jpeg|jpg))"'
# 编译正则表达式
imgre=re.compile(reg)
imglist=re.findall(imgre,html.decode('utf-8'))
x=0
for imgurl in imglist:
# 下载图片
urllib.request.urlretrieve(imgurl,saveFile(x))
print(imgurl)
x+=1
if x==23:
break
print(x)
return imglist getImg(html)
print('end')
正则表达式:
^ : 字符串的开始,
$: 字符串的末尾
. : 匹配任意字符,除换行符
* : 任意多的字符
+: 任意大于1 的字符
?: 匹配0或1个, home-?brew : homebrew, 或home-brew
[]: 指定一个字符类别,可以单独列出,也可以使用- 表示一个区间。[abc]匹配a,b,c 中的任意一个字符,也可以表示[a-c]的字符集
[^]: ^ 作为类别的首个字符,[^5]将匹配除5之外的任意字符
\ : 转义字符
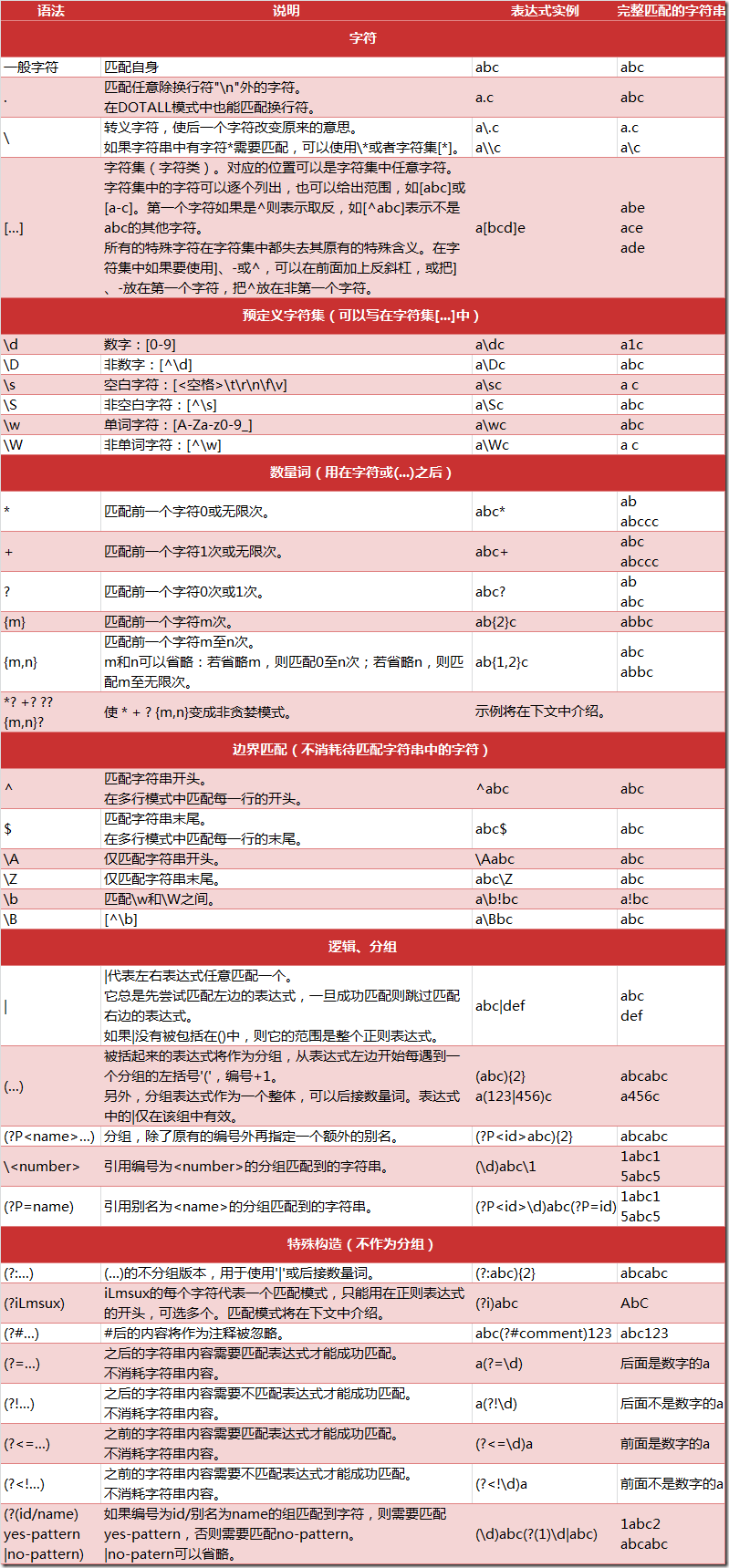
加反斜杠取消特殊性。\ section, 为了匹配反斜杠,就得写为\\, 但是\\ 又有别的意思。。大量反斜杠。。。 使用raw字符串表示,在字符串前加r,反斜杠就不会当做特殊处理,\n 表示两个字符\ 和n,而不是换行。
如: https://imgsa[^>]+\.(?:jpeg|jpg) 表示 https://imgsa(不匹配>的多余1个的字符串).
| 方法/属性 | 作用 |
| match() | 决定 RE 是否在字符串刚开始的位置匹配 |
| search() | 扫描字符串,找到这个 RE 匹配的位置 |
| findall() | 找到 RE 匹配的所有子串,并把它们作为一个列表返回 |
| finditer() | 找到 RE 匹配的所有子串,并把它们作为一个迭代器返回 |
| 方法/属性 | 作用 |
| group() | 返回被 RE 匹配的字符串 |
| start() | 返回匹配开始的位置 |
| end() | 返回匹配结束的位置 |
| span() | 返回一个元组包含匹配 (开始,结束) 的位置 |
实现: 在一个文档中找到system('***'); 并且在后面加上print('***')
文档为:
aba
cdc
system('a');
cde;
system('d');
写入 system\([\s\S]*\) 查找(\s \t\n..空白字符,\S 非空白字符,[]表示选择匹配一个,* 表示0个或多个), 找到的为:
system('a');
cde;
system('d');
因为会匹配最长的一个,要匹配第一个匹配的字符串:system\([\s\S]*?\)。
要替换为:
aba
cdc
system('a');
'a'
cde;
system('d');
'd'
python 爬虫得到网页的图片的更多相关文章
- python爬虫抓网页的总结
python爬虫抓网页的总结 更多 python 爬虫 学用python也有3个多月了,用得最多的还是各类爬虫脚本:写过抓代理本机验证的脚本,写过在discuz论坛中自动登录自动发贴的脚本,写过自 ...
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
- Python爬虫之网页图片抓取
一.引入 这段时间一直在学习Python的东西,以前就听说Python爬虫多厉害,正好现在学到这里,跟着小甲鱼的Python视频写了一个爬虫程序,能实现简单的网页图片下载. 二.代码 __author ...
- Python爬虫解析网页的4种方式 值得收藏
用Python写爬虫工具在现在是一种司空见惯的事情,每个人都希望能够写一段程序去互联网上扒一点资料下来,用于数据分析或者干点别的事情. 我们知道,爬虫的原理无非是把目标网址的内容下载下来存储到内存 ...
- python爬虫 前程无忧网页抓取
Python爬虫视频教程零基础小白到scrapy爬虫高手-轻松入门 https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.482434a6E ...
- Python爬虫之简单的图片获取
简单的静态网页的图片获取: import urllib import re import os url = 'http://www.toutiao.com/a6467889113046450702/' ...
- Python 爬虫学习 网页图片下载
使用正则表达式匹配 # coding:utf-8 import re import urllib def get_content(url): """ Evilxr, &q ...
- [记录][python]python爬虫,下载某图片网站的所有图集
随笔仅用于学习交流,转载时请注明出处,http://www.cnblogs.com/CaDevil/p/5958770.html 该随笔是记录我的第一个python程序,一个爬去指定图片站点的所有图集 ...
- python爬虫中文网页cmd打印出错问题解决
问题描述 用python写爬虫,很多时候我们会先在cmd下先进行尝试. 运行爬虫之后,肯定的,我们想看看爬取的结果. 于是,我们print... 运气好的话,一切顺利.但这样的次数不多,更多地,我们会 ...
随机推荐
- CF1106E Lunar New Year and Red Envelopes
比赛时看到这题懵逼了,比完赛仔细一想是个很简单的dp = = 由于题目限制,可以发现\(B\)取红包的策略是唯一的,可以用优先队列预处理出\(B\)在第\(i\)秒可以拿到的红包的收益\(w_i\)和 ...
- 单片机pwm控制基本原理详解
前言 PWM是Pulse Width Modulation的缩写,它的中文名字是脉冲宽度调制,一种说法是它利用微处理器的数字输出来对模拟电路进行控制的一种有效的技术,其实就是使用数字信号达到一个模拟信 ...
- ElasticSearch 2 (9) - 在ElasticSearch之下(图解搜索的故事)
ElasticSearch 2 (9) - 在ElasticSearch之下(图解搜索的故事) 摘要 先自上而下,后自底向上的介绍ElasticSearch的底层工作原理,试图回答以下问题: 为什么我 ...
- jenkins自动打包部署项目
首先去jenkins的官网下载安装包 https://jenkins.io/ 个人下载是长期稳定的那个版本,下载后,得到一个.msi的安装包: 点击进行安装,然后一直点击下一步. jenkins会 ...
- Day4--Python--列表增删改查,元组,range
# 一.列表# 能装东西的东西 列表中装的数据是没有限制的,大小基本上够用# 列表用[]表示# 有索引和切片 [start,end,step] ###增删改查 (重点) # 1.新增 # appent ...
- Luogu P3355 骑士共存问题
题目链接 \(Click\) \(Here\) 二分图最大独立集.对任意两个可以相互攻击的点,我们可以选其中一个.对于不会互相攻击的,可以全部选中.所以我们只需要求出最大匹配,根据定理,二分图最大独立 ...
- u-boot(五)内核启动
目录 u-boot(五)内核启动 概述 分区空间 内核文件格式 内核复制跳转 内核启动 机器ID 启动参数 (起始tag)setup_start_tag 内存设置 根文件系统,启动程序,串口设备 (结 ...
- docker 基础之操作容器
Docker子命令分类 Docker 环境信息 info .version 容器生命周期管理 Create.exec.kill.pause.restart.rm.run.start.stop.unpa ...
- centos的用户、组权限、添加删除用户等操作的详细操作命令
1.Linux操作系统是多用户多任务操作系统,包括用户账户和组账户两种 细分用户账户(普通用户账户,超级用户账户)除了用户账户以为还 有组账户所谓组账户就是用户账户的集合,centos组中有两种类型, ...
- java io系列10之 FilterInputStream
FilterInputStream 介绍 FilterInputStream 的作用是用来“封装其它的输入流,并为它们提供额外的功能”.它的常用的子类有BufferedInputStream和Data ...