Hadoop学习笔记(六):hive使用
1. 安装hive:上传apache-hive-2.1.1-bin.tar.gz文件到/usr/local目录下,解压后更名为hive。
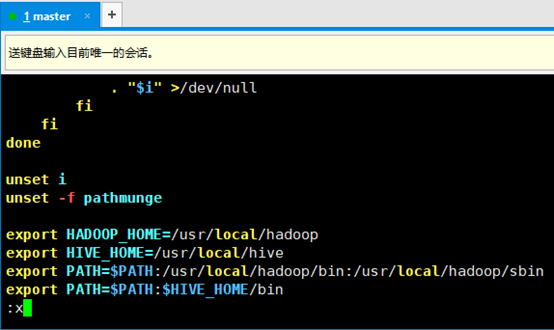
2. 配置hive环境变量,编辑/etc/profile文件(配置完后记得source /etc/profile使其生效)
3. 配置hive,进入到hive文件夹内,将hive-default.xml.template拷贝一份,命名为hive-site.xml,编辑它,将其中的hive.metastore.schema.verification属性设置为false(内容较多不方便,可是用查找命令,vim在非编辑状态下按/键,然后输入要搜索的内容,回车即可,按小写N键往后翻,按大写N键往前翻)

4. 创建/usr/local/hive/tmp目录,替换${system:java.io.tmpdir}为该目录(vim下使用替换命令,进入命令模式,输入%s#A#B#回车,即为将所有的A替换为B,按照此方式将所有的${system:java.io.tmpdir}替换为/usr/local/hive/tmp)
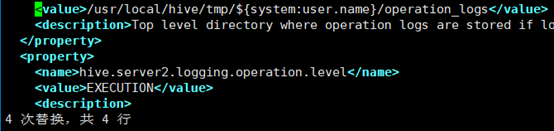
5. 同理,将所有${system:user.name}替换为登录用户,此处为root(共三处)
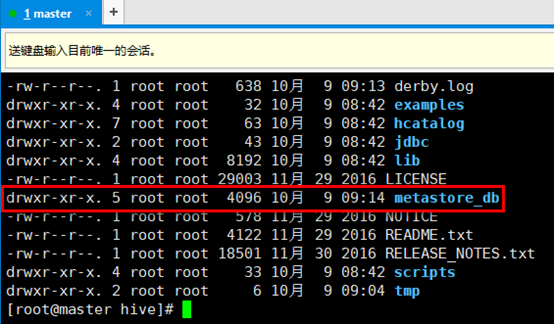
6. 进入/usr/local/hive目录下,执行schematool -initSchema -dbType derby命令。该命令会初始化derby数据库,该数据库中存放的是hive数据库的元数据,实际生产环境中可能用MySQL替换derby数据库,或者其他数据库,不过MySQL使用的较多。执行完该命令后,在hive目录下会多出一个metastore_db文件。(注意!!!下次执行hive时应该还在同一目录,derby默认会到当前目录下寻找metastore。如果遇到问题,把metastore_db删掉,重新执行命令)
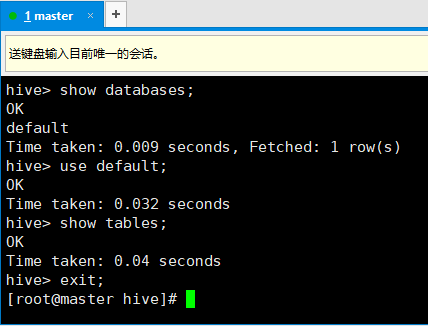
7. 启动hive(此时hadoop和yarn也要启动起来),直接输入hive回车即可。
8. 此后的操作和MySQL的命令行差不多:
9. 使用hive创建一张表:
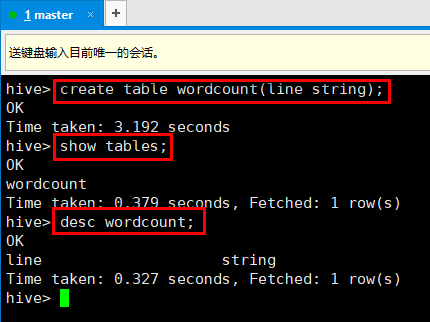
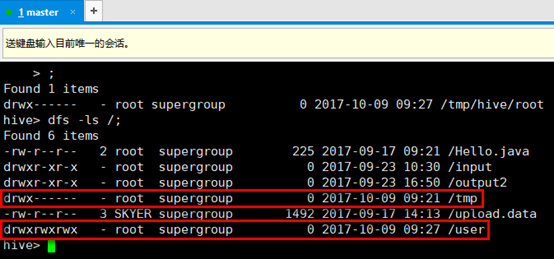
10. 可以直接在hive里执行hadoop语句,观察刚才创建的数据库,红框为刚才创建表时hive创建的目录,其中/user/hive/warehouse目录下有刚才的创建的表的信息。
11. 往表里装数据,在hive命令模式下,输入load data inpath '/input/' overwrite into table wordcount;

其中/input/目录下有一个txt文件,内容如下:
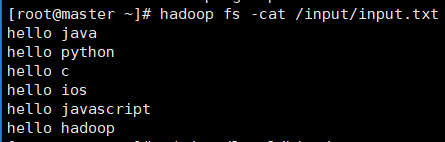
12. 上一步操作即为将/input/input.txt这个文件和wordcount这张表建立一个关联,查询这张表的时候,就会通过hdfs查询到该文件的内容。
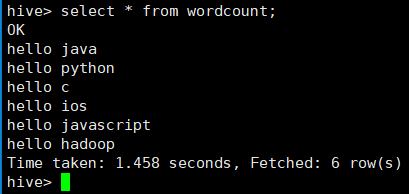
13. 下面使用hive执行上一节中wordcount程序,直接在hive命令模式写输入:select word, count(*) num from (select explode(split(line, ' ')) as word from wordcount) w group by word;其中,split为分割,即将line字段按照空格进行分割,expode函数的作用是,将数组中每一个元素作为单独的一行进行输出。该sql语句的执行结果如下图:
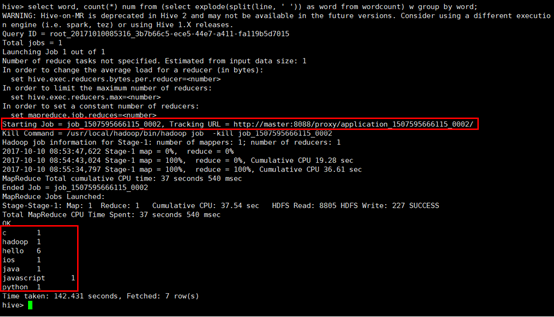
可以看出,该sql语句实际上执行MapReduce成功,开启了一个job,和上一节中编写的java代码是一个效果。
14. 下面用hive分析一个实际当中的日志文件,将该文件上传至hadoop根目录(该文件为搜狗的搜索日志文件)
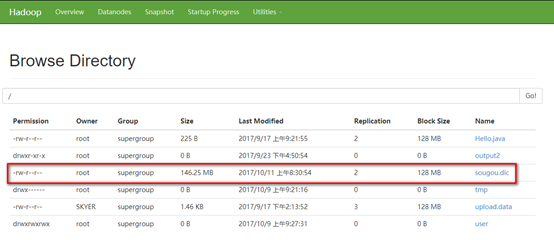
该文件的内容大致如下图,其格式为搜索时间+搜索ID+搜索内容+结果URL,期间都是用逗号隔开。
15. 创建一张表,用来装载sougou.dic的数据,然后对这张表进行操作。进入hive命令模式,输入命令:
create table sougou (qtime string, qid string, qword string, url string) row format delimited fields terminated by ',';
其中,row format delimited fields terminated by ','表示将每一行用逗号进行分割,分别作为一个字段。
16. 装载数据,将sougou.dic里的数据装载到刚才创建的表里(不是将里边的内容装载到了表里,而是在它们两者之间建立了一种联系)。输入命令:
load data inpath '/sougou.dic' into table sougou;
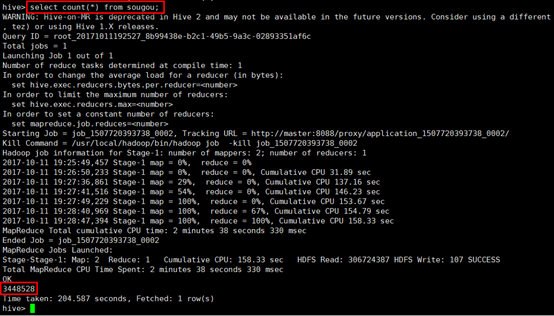
17. 下面就可以通过这个张表来操作这个日志文件了,先统计一下一共有多少条记录(由于这个日志文件有146M,而hadoop默认块大小为128M,因此操作这张表的时候一般会启动MapReduce程序),输入select count(*) from sougou;观察结果:
18. 下面来查询热搜榜,首先创建一张表,用来记录搜索的关键字和该关键字的搜索次数,按照由大到小排序,输入HQL语句:
create table sougou_results as select keyword, count(1) as count from (select qword as keyword from sougou) t group by keyword order by count desc;
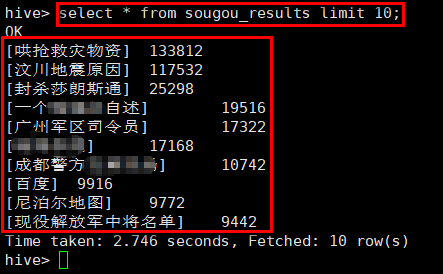
19. 接下来查询热搜榜前十名的搜索记录,输入HQL语句,并观察执行结果:
select * from sougou_results limit 10;
Hadoop学习笔记(六):hive使用的更多相关文章
- Hadoop学习笔记—17.Hive框架学习
一.Hive:一个牛逼的数据仓库 1.1 神马是Hive? Hive 是建立在 Hadoop 基础上的数据仓库基础构架.它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储. ...
- hadoop学习笔记-目录
以下是hadoop学习笔记的顺序: hadoop学习笔记(一):概念和组成 hadoop学习笔记(二):centos7三节点安装hadoop2.7.0 hadoop学习笔记(三):hdfs体系结构和读 ...
- Hadoop学习笔记系列
Hadoop学习笔记系列 一.为何要学习Hadoop? 这是一个信息爆炸的时代.经过数十年的积累,很多企业都聚集了大量的数据.这些数据也是企业的核心财富之一,怎样从累积的数据里寻找价值,变废为宝炼 ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- Hadoop学习笔记(7) ——高级编程
Hadoop学习笔记(7) ——高级编程 从前面的学习中,我们了解到了MapReduce整个过程需要经过以下几个步骤: 1.输入(input):将输入数据分成一个个split,并将split进一步拆成 ...
- Hadoop学习笔记(6) ——重新认识Hadoop
Hadoop学习笔记(6) ——重新认识Hadoop 之前,我们把hadoop从下载包部署到编写了helloworld,看到了结果.现是得开始稍微更深入地了解hadoop了. Hadoop包含了两大功 ...
- Hadoop学习笔记(2)
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(5) ——编写HelloWorld(2)
Hadoop学习笔记(5) ——编写HelloWorld(2) 前面我们写了一个Hadoop程序,并让它跑起来了.但想想不对啊,Hadoop不是有两块功能么,DFS和MapReduce.没错,上一节我 ...
- Hadoop学习笔记(3)——分布式环境搭建
Hadoop学习笔记(3) ——分布式环境搭建 前面,我们已经在单机上把Hadoop运行起来了,但我们知道Hadoop支持分布式的,而它的优点就是在分布上突出的,所以我们得搭个环境模拟一下. 在这里, ...
- Hadoop学习笔记(2) ——解读Hello World
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
随机推荐
- Python几周学习内容小结
环境配置 学习python首先是要配置环境,我们选择了Anaconda. 什么是Anaconda:专注于数据分析的python发行版本. 为什么选择Anaconda:省事省心,分析利器 至于下载和安装 ...
- P1081 开车旅行(Not Finish)
https://www.luogu.org/problemnew/show/P1081
- Spring Boot不同版本整合Redis的配置
1. Spring Boot为1.4及其他低版本 1.1 POM.XML配置 <!--引入 spring-boot-starter-redis(1.4版本前)--> <depende ...
- s6-4 TCP 数据段
传输控制协议 TCP (Transmission Control Protocol) 是专门为了在不可靠的互联网络上提供可靠的端到端字节流而设计的 TCP必须动态地适应不同的拓扑.带宽.延迟. ...
- 信号量(Semaphore)
在python的多线程体系中,一共有4种锁: 同步锁(互斥锁):Lock: 递归锁:RLock: 信号量:Semaphore: 同步条件锁:Condition. 信号量(semaphore)是一种可以 ...
- Android从入门到进阶——布局
一.组件 1.UI组件 (Android.view.View的子类或者间接子类) 2.容器组件(Android.view.ViewGroup子类或者间接子类) 二.UI组件:TextView,Spin ...
- mysql利用LAST_INSERT_ID实现id生成器
首先了解 LAST_INSERT_ID LAST_INSERT_ID 有自己的存储空间,能存一个数字 不带参数时返回最近insert的那行记录的自增字段值.带参数时会将自己存储的数字刷成参数给定的值 ...
- (转)jira7.2安装、中文及破解
转自:http://www.cnblogs.com/ilanni/p/6200875.html 本文由ilanniweb提供友情赞助,首发于烂泥行天下 想要获得更多的文章,可以关注我的微信ilanni ...
- docker install
1.安装必要工具集 sudo yum install -y yum-utils 2.安装Docker官方源 sudo yum-config-manager \ --add-repo \ https:/ ...
- 记一下vue.js事件的修饰等问题
在事件处理程序中调用 event.preventDefault() 或 event.stopPropagation() 是非常常见的需求.尽管我们可以在 methods 中轻松实现这点,但更好的方式是 ...