python--文件流读写
在讲述fileinput模块之前,首先说一下python内置的文件API—open()函数以及与其相关的函数。
我这里主要讲讲其中四个比较重要和常用的方法,更多的方法,可以参考:菜鸟教程http://www.runoob.com/python/file-methods.html
(1)file = open(file_name [, access_mode][, buffering])
参数解析:
1. file_name:
file_name变量是一个需要访问的文件名称的字符串值,在应用中需要用单引号或者双引号将文件名包裹起来。
2. access_mode:
access_mode决定了打开文件的模式:只读,写入,追加等。这个参数是非强制的,默认文件访问模式为只读(r)
详细模式可以参考:菜鸟教程http://www.runoob.com/python/python-files-io.html
3. buffering:
这个参数用于设置缓存区的大小。如果buffering的值被设为0,就不会有缓存。如果buffering的值取1,访问文件时会寄存行。如果将buffering的值设为大于1的整数,这个整数就为缓存区的缓存大小。如果取负值,寄存区的缓冲大小则为系统默认。
(2)file.flush()方法
用于刷新缓冲区,,即将缓冲区中的数据立刻写入文件,同时清空缓冲区
flush()方法在爬虫中也用得挺多,在爬虫过程由于种种原因,程序中断,写入缓存的数据没有写入磁盘很可惜,所以可以手动添加flush()方法
(3)file.close()方法
关闭文件,并将缓冲区的数据写入文件中。
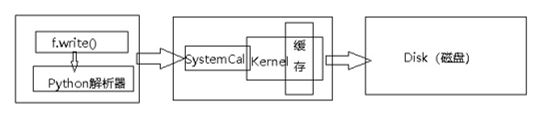
文件的缓存机制
在写入文件内容的时候,在我们调用python的write()函数对文件进行写入的时候,python解析器会调用操作系统的write方法,但值得注意的是,不是马上保存到磁盘中的,是先写到内核的缓冲区里面,只有当我们主动调用flush()函数或者close()函数的时候,才会将缓冲区的内容写入磁盘中。另外当写入的数据量大于或者等于缓冲区的大小的时候,写缓冲会自动同步到磁盘。
例如:
写20万行数据结果
file = open('file1.txt','a+')
for i in range(200000):
file.write('this line is line%s'%i)
file.write('\r\n')
pycharm报出如下的提示


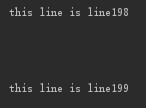
因为我设置的buffering是默认的系统的缓存大小,所以当写到1999856行时,就刚好到系统的缓存区大小,因为所需要写的数据大于缓存区的大小,所以这些内容直接就写入了磁盘,而1998856后面的数据在写入的时候还是先写到了缓存区中,而这些数据的大小显然是小于缓存区大小的,所以被保存在缓存区中,并没有写到磁盘。
使用flush()方法后,所有在缓存区的数据都会写入到磁盘中

如果我直接在调用open()方法的时候像下面这样设置buffering为1,就无需担心缓存的问题了
(4)file.seek(offset [,whence]) 文件指针
当文件进行写入或者读取的时候,文件指针会根据具体的内容进行移动。灵活地运用seek()方法,可以在一次I/O操作中对文件同时进行写和读操作,避免多次的I/O。
参数解析:
offset:偏移量,代表需要移动偏移的字节数
whence:可选参数,默认值为 0。作用是给offset参数设定起始值,表示要从哪个位置开始偏移。0代表从文件开头开始算起,1代表从当前位置开始算起,2代表从文件末尾算起。
例如以下案例:
file = open('file.txt','a+',1)
for i in range(200):
file.write('this line is line%s'%i)
file.write('\r\n')
for line in file:
print(line)
file.close()
终端没有打印任何数据
如果将代码顺序修改一下
file = open('file.txt','a+',1)
for i in range(200):
file.write('this line is line%s'%i)
file.write('\r\n')
file.close()
f = open('file.txt','r+')
for line in f:
print(line)
f.close()
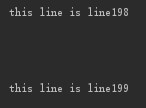
终端打印出数据
那么怎么用seek()方法呢?
import os
file = open('file.txt','a+',1)
for i in range(200):
file.write('this line is line%s'%i)
file.write('\r\n')
file.seek(0,os.SEEK_SET)
for line in file:
print(line)
file.close()
同样也能打印出数据
上面,我用了os模块的SEEK_SET
os模块有这些内容:
os.SEEK_SET:表示文件的相对起始位置
os.SEEK_CUR:表示文件的相对当前位置
os.SEEK_END:表示文件的相对结束位置
关于fileinput模块
fileinput可以对文件进行细致化的处理,比直接的open方法有更多文件操扩展。可以一次性迭代一个或者多个文件,并对文件进行修改。
主要的函数有:
1. input([files[,inplace[,backup]]]) 帮助迭代多个输入流中的行
2. filename() 返回当前文件的名称
3.nestfile() 关闭当前文件并移动到下一个文件
4. close() 关闭序列(多个文件
5. lineno() 返回(多个文件累计的)当前行号
6. filelineno() 返回在当前文件的行好
7. isfirstline() 检查当前是否是当前文件中的第一行
8. isstdin() 检查最后一行是否来自sys.stdin
可以理解,fileinput模块重点是对多文件的读取和适当时候的修改。而没有直接的写操作
1. input()方法
这个函数是fileinput模块中最重要的一个函数,参数相对复杂一点。
官方的定义:
fileinput.input([files[, inplace[, backup[, bufsize[, mode[, openhook]]]]]])

input(files=None, inplace=False, backup='', bufsize=0, mode='r', openhook=None)
1)files列表,可以是一个文件,也可以是多个文件的列表形式
2)inplace 是否对文件进行就地修改。默认为False,设置为False跟文件的open区别不大
3)mode 读取的格式
官方:FileInput opening mode must be one of 'r', 'rU', 'U' and 'rb' (b:二进制字节模式和U:unicode模式)
4)backup 文件备份,为原本的文件做一份备份,不作任何修改,其实就是复制。备份的文件名是原本的文件名+备份文件名。注意备份文件需要把文件的格式也写进去。一般backup需要与参数inplace一起使用才有意义。而在设置了inplace=True,一般同时会设置backup参数来备份原本的文件内容。
例子:在每一行文本的前面添加 ‘#行号’字样
单个文件案例:
for line in fileinput.input('file.txt',inplace=True,mode='r',backup='file_back.txt'):
num = fileinput.filelineno()
print('#%s'%num+' '+line)
如果inplace设置为True,即就地修改,必须要有print函数将读取的数据重新写回当前的文件中,否则文件的数据最后会变成空。所以使用inplace时候必须很小心。
备份后的文件目录
多个文件案例
for line in fileinput.input(files=['file.txt','file1.txt'],inplace=True,mode='r',backup='file_back.txt'):
num = fileinput.filelineno()
print('#%s'%num+' '+line
通常fileinput模块会结合re模块一起使用,例如在对日志的分析中会很有用
例如,这里有一个monoodb的log文件内容

希望获取日期为11-13的日志
import fileinput
import re
for line in fileinput.input('mongolog.txt',mode='r',inplace=True,backup='log_backup.txt'):
pattern = '2018-11-13'
if re.search(pattern,line):
print(line)
获取结果在原log.txt文件中,备份文件中的内容与原文件相同

python--文件流读写的更多相关文章
- 【基础巩固】文件流读写、大文件移动 FileStream StreamWriter File Path Directory/ ,m资料管理器(递归)
C#获取文件名 扩展名 string fullPath = @"d:\test\default.avi"; string filename = Path.GetFileName(f ...
- python文件的读写总结
读写文件是最常见的IO操作.Python内置了读写文件的函数,用法和C是兼容的. 读写文件前,我们先必须了解一下,在磁盘上读写文件的功能都是由操作系统提供的,现代操作系统不允许普通的程序直接操作磁盘, ...
- 关于 Delphi 中流的使用(2) 用 TFileStream(文件流) 读写
TStream 是一个抽象的基类, 不能直接生成对象. 在具体的应用中, 主要使用它的子孙类:TFileStream: 文件流TStringStream: 字符串流TMemoryStream: 内存流 ...
- python文件的读写的模式
<1>打开文件 在python,使用open函数,可以打开一个已经存在的文件,或者创建一个新文件 open(文件名,访问模式) 示例如下: f = open('test.txt', 'w' ...
- Python文件的读写操作
Python文件的使用 要点:Python能够以文本和二进制两种形式处理文件. 1.文件的打开模式,如表1: 注意:使用open()函数打开文件,文件使用结束后耀使用close()方法关闭,释放文件 ...
- python文件的读写权限以及相关应用read、write和文件指针
f=open('ceshi.txt','a',encoding='utf-8')r=open('ceshi.txt','r',encoding='utf-8')上面的2种写法可以用with来写:wit ...
- Python文件的读写
一.写数据 f = open("hello.txt", "w") f.write("hello world python!") f.clos ...
- 【8】python文件的读写方法
(1).读文件的步骤: (1)打开文件 open(path,flag,encoding,[errors]) path:打开路径 flag:打开方式 r(只读) rb(二进制格式) r+(可以读写) w ...
- [ Python ] 文件的读写操作
1. 文件读写操作 读写文件是最常见的 IO 操作, Python 内置了读写文件的函数.在磁盘上读写文件的功能是由操作系统提供的,所以读写文件是请求操作系统打开一个文件对象(通常称为文件描述符),然 ...
- python文件流
打开文件 文件的基本方法 迭代文件内容 打开文件 打开文件,可以使用自动导入的模块io中的函数open.函数open将文件名作为唯一必不可少的参数,并返回一个文件对象.如果只指定一个文件名,则获得一个 ...
随机推荐
- (转)Apache从2.2换至2.4httpd.conf的调整笔记(windows环境)
原文:https://www.cnblogs.com/tjws/articles/3469075.html#top 整理一下Windows环境Apache 2.2 改成 Apache 2.4.1后 h ...
- CAS单点登陆/oAuth2授权登陆
单点登陆 CAS是一个单点登录框架,即Central Authentication Service(中心认证服务) ,开始是由耶鲁大学的一个组织开发,后来归到apereo去管,github地址:htt ...
- Python Selenium 常用方法总结(不断补充)
还有此篇内容也丰富Selenium常见元素定位方法和操作的学习介绍 selenium Python 总结一些工作中可能会经常使用到的API. 1.获取当前页面的Url 方法:current_url 实 ...
- github代码clone加速
这阵子想看看开源项目 MyBatis 的源码,结果使用 git 的 clone 命令怎么也 clone 不下来,我以为是网速慢,上 Google 一搜,原来 Github 的域名被 DNS 污染了,我 ...
- dubbo自定义异常传递信息丢失问题解决
访问我的博客 目前计划对已有的单体项目进行组织架构拆分,调研了分布式系统中常用中间件 Dubbo 和 Spring Cloud,选择了 Dubbo,可以对当前现有项目进行平滑升级改造.但是一开始就遇到 ...
- linux 命令 — sed
sed stream editor,流编辑器 查找替换 sed 's/pattern/replace_string/' file 替换每一行第一次出现的pattern,将替换后的文本输出到stdout ...
- Linux常用命令之网络和关机重启命令
目录 1.网络命令 一.给指定用户发送信息:write 二.给所有用户发送广播信息:wall 三.测试网络连通性:ping 四.查看和设置网卡信息:ifconfig 五.查看发送电子邮件:mail 六 ...
- webmagic 的 helloworld
<dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-core</a ...
- [转]使用Git Submodule管理子模块
本文转自:https://blog.csdn.net/qq_37788558/article/details/78668345 实例代码: 父项目:https://github.com/jjz/pod ...
- mysql外键使用
一.外键 .外键:链接两张表的字段,通过主表的主键和从表的外键来描述主外键关系,呈现的是一对多的关系.例如:商品类别(一)对商品(多),主表:商品类别表,从表:商品表. .外键的特点:从表外键的值是对 ...