爬虫_拉勾网(解析ajax)
拉勾网反爬虫做的比较严,请求头多添加几个参数才能不被网站识别
找到真正的请求网址,返回的是一个json串,解析这个json串即可,而且注意是post传值
通过改变data中pn的值来控制翻页
job_name读取的结果是一个列表 ['JAVA高级工程师、爬虫工程师'] ,而我只想得到里面的字符串,在用job_name[0]的时候,爬取过程中会报下标错误,不知道怎么回事,都看了一遍没问题啊,只能不处理这个列表了
import requests
from lxml import etree
import time
import re headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36',
'Cookie': '_ga=GA1.2.438907938.1533109215; user_trace_token=20180801154015-21630e48-955e-11e8-ac93-525400f775ce; LGUID=20180801154015-216316d6-955e-11e8-ac93-525400f775ce; WEBTJ-ID=08122018%2C193417-1652dea595ec0a-0ca5deb5d1dcb9-172f1503-2073600-1652dea595f51f; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1533109214,1534073658; LGSID=20180812193418-a61634a5-9e23-11e8-bae9-525400f775ce; PRE_UTM=m_cf_cpt_baidu_pc; PRE_HOST=www.baidu.com; PRE_SITE=https%3A%2F%2Fwww.baidu.com%2Fs%3Fie%3Dutf-8%26f%3D8%26rsv_bp%3D0%26rsv_idx%3D1%26tn%3Dbaidu%26wd%3Dlagou%2520wang%2520%26rsv_pq%3D8f8c8d4500066afd%26rsv_t%3Deaa21Vp5dXD8YMkjoybb0H4UW4n0ReZfxSBiBne14tXfDsN5XKFydx2jVnA%26rqlang%3Dcn%26rsv_enter%3D1%26rsv_sug3%3D12%26rsv_sug1%3D2%26rsv_sug7%3D101%26rsv_sug2%3D0%26inputT%3D1970%26rsv_sug4%3D3064; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Flp%2Fhtml%2Fcommon.html%3Futm_source%3Dm_cf_cpt_baidu_pc; _gid=GA1.2.849726101.1534073658; X_HTTP_TOKEN=0d3a98743216c83f14e092a5154d2327; LG_LOGIN_USER_ID=5f3d6b41f24b2423bae0a956753632482a2ecabcb36ef97074ff9fdec683ae51; _putrc=3A0548631F844F3C123F89F2B170EADC; JSESSIONID=ABAAABAAAIAACBI302EB6DF4BD54C909C01751F65D4311D; login=true; unick=%E5%88%98%E4%BA%9A%E6%96%8C; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=0; gate_login_token=c6678499c0aaeb807c1e37249f90d483317ec272762e7060fa18175f49d9c806; index_location_city=%E5%85%A8%E5%9B%BD; TG-TRACK-CODE=search_code; _gat=1; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1534074635; LGRID=20180812195035-ec87e3ce-9e25-11e8-a37b-5254005c3644; SEARCH_ID=85704a0c1aaf43d4b9f07489311f0707',
'Referer': 'https://www.lagou.com/jobs/list_%E7%88%AC%E8%99%AB?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=sug&suginput=pachong',
'Origin': 'https://www.lagou.com'
} data = {
'first': 'false',
'pn': 1,
'kd': '爬虫'
} def get_list_page(page_num):
url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
data['pn'] = page_num
response = requests.post(url, headers=headers, data=data)
result = response.json()
positions = result['content']['positionResult']['result']
for position in positions:
positionId = position['positionId']
position_url = 'https://www.lagou.com/jobs/%s.html' %positionId parse_detail_page(position_url)
# break def parse_detail_page(url):
job_information = {}
response = requests.get(url, headers=headers)
# response.raise_for_status()
html = response.text
html_element = etree.HTML(html)
job_name = html_element.xpath('//div[@class="job-name"]/@title')
job_description = html_element.xpath('//dd[@class="job_bt"]//p//text()')
for index, i in enumerate(job_description):
job_description[index] = re.sub('\xa0', '', i)
job_address = html_element.xpath('//div[@class="work_addr"]/a/text()')
job_salary = html_element.xpath('//span[@class="salary"]/text()') # 字符串处理去掉不必要的信息
for index, i in enumerate(job_address):
job_address[index] = re.sub('查看地图', '', i)
while '' in job_address:
job_address.remove('') # job_address_detail = html_element.xpath('//div[@class="work_addr"]/a[-2]/text()')
# print(job_address_detail)
job_information['job_name'] = job_name
job_information['job_description'] = job_description
job_information['job_address'] = job_address
job_information['job_salary'] = job_salary
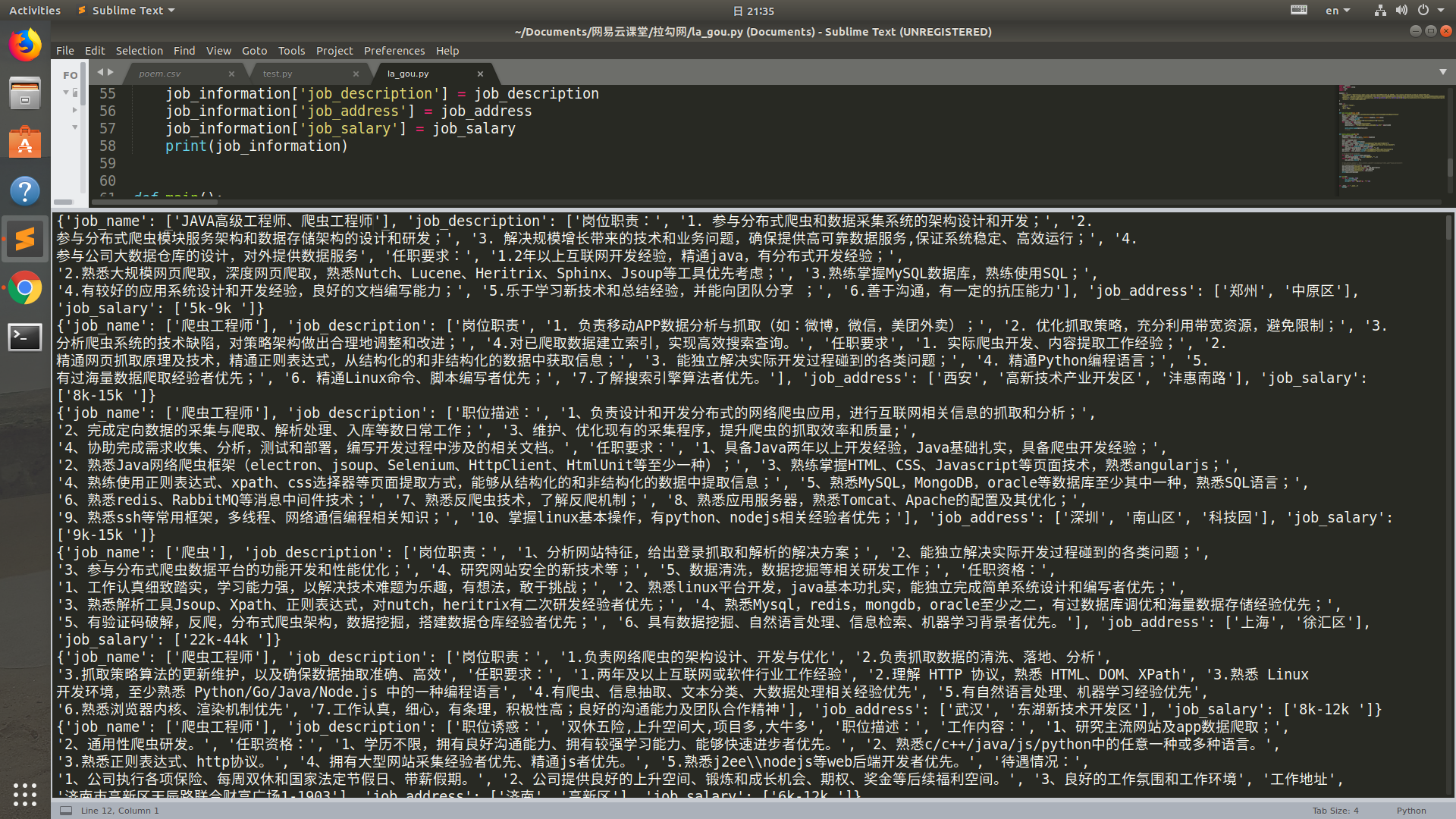
print(job_information) def main():
for i in range(1, 31):
get_list_page(i)
print('='*30 + '第%s页'%i + '='*30) if __name__ == '__main__':
main()
运行结果
爬虫_拉勾网(解析ajax)的更多相关文章
- 爬虫_拉勾网(selenium)
使用selenium进行翻页获取职位链接,再对链接进行解析 会爬取到部分空列表,感觉是网速太慢了,加了time.sleep()还是会有空列表 from selenium import webdrive ...
- Python网络爬虫_爬取Ajax动态加载和翻页时url不变的网页
1 . 什么是 AJAX ? AJAX = 异步 JavaScript 和 XML. AJAX 是一种用于创建快速动态网页的技术. 通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新 ...
- 笔记-爬虫-js代码解析
笔记-爬虫-js代码解析 1. js代码解析 1.1. 前言 在爬取网站时经常会有js生成关键信息,而且js代码是混淆过的. 以瓜子二手车为例,直接请求https://www.guaz ...
- jQuery解析AJAX返回的html数据时碰到的问题与解决
$.ajax({ type : "post", url : "<%=request.getContextPath()%>/ce/articledetail/m ...
- python爬虫---爬虫的数据解析的流程和解析数据的几种方式
python爬虫---爬虫的数据解析的流程和解析数据的几种方式 一丶爬虫数据解析 概念:将一整张页面中的局部数据进行提取/解析 作用:用来实现聚焦爬虫的吧 实现方式: 正则 (针对字符串) bs4 x ...
- 20170717_python_爬虫_网页数据解析_BeautifulSoup_数据保存_pymysql
上午废了老大劲成功登陆后,下午看了下BeautifulSoup和pymysql,晚上记录一下 自己电脑装的sublime,字体颜色竟然拷贝不下来 - - 写的过程中遇到了很多问题: 1.模拟登陆部分 ...
- python爬虫_简单使用百度OCR解析验证码
百度技术文档 首先要注册百度云账号: 在首页,找到图像识别,创建应用,选择相应的功能,创建 安装接口模块: pip install baidu-aip 简单识别一: 简单图形验证码: 图片: from ...
- 【Python3爬虫】拉勾网爬虫
一.思路分析: 在之前写拉勾网的爬虫的时候,总是得到下面这个结果(真是头疼),当你看到下面这个结果的时候,也就意味着被反爬了,因为一些网站会有相应的反爬虫措施,例如很多网站会检测某一段时间某个IP的访 ...
- PYTHON 爬虫笔记九:利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集(实战项目二)
利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集 目标站点分析 今日头条这类的网站制作,从数据形式,CSS样式都是通过数据接口的样式来决定的,所以它的抓取方法和其他网页的抓取方 ...
随机推荐
- Truncated Power Method for Sparse Eigenvalue Problems
目录 算法 k的选择 \(x\)的初始化 代码 抱歉,真的没怎么看懂,当然,估计和我现在没法静下心来好好看也有关系. 算法 想法非常非常简单吧,就是在原来幂法的基础上,每次迭代的时候再加个截断.当然, ...
- Git push提交时报错Permission denied(publickey)...Please make sure you have the correct access rights and the repository exists.
一.git push origin master 时出错 错误信息为: Permission denied(publickey). fatal: Could not read from remote ...
- Python_内置函数之map()
map 会根据提供的函数对指定序列做映射. 代码如下: def square(x): return x ** 2 ret = map(square, [1, 2, 3, 4, 5]) # 计算列表各元 ...
- Python之参数类型、变量
一.参数类型 (一)形参与实参 要使用局部变量时,只能通过return的方式返回 def my(name): #函数体 return name my('lrx') #name是形参,lrx是实参 不写 ...
- Jmeter操作之跨线程组传递参数
思路:将某一线程组内的变量通过“__setProperty”函数设置成jmeter的全局变量,在另一线程组中通过“__P”函数调用即可. 1.添加-后置处理器-BeanShell PostProces ...
- HashSet中存放不重复元素
一.自定义对象存放在hashSet中,保证元素不重复.重写hashCode()和equals()方法 public class Student{ private String name; privat ...
- MYSQL 创建数据库SQL
CREATE DATABASE crm CHARACTER SET utf8 COLLATE utf8_general_ci; MySQL :: MySQL 5.7 Reference Manual ...
- 【翻译】asp.net core中使用FluentValidation来进行模型验证
asp.net core中使用FluentValidation FluentValidation 可以集成到asp.net core中.一旦启用,MVC会在通过模型绑定将参数传入控制器的方法上时使用F ...
- 局域网 FTP建立,搭建一个简易的局域网服务器
1.创建用户名以及密码: 右键我的电脑 -> 管理->本地用户和组->右键用户->新用户----设置用户名密码: 2.安装IIS 和FTP :控制面板->程序->打 ...
- C# Note26: [MethodImpl(MethodImplOptions.Synchronized)]与lock机制
在进行.NET开发时,经常会遇见如何保持线程同步的情况.在众多的线程同步的可选方式中,加锁无疑是最为常用的.如果仅仅是基于方法级别的线程同步,使用System.Runtime.CompilerServ ...