mysql 开发进阶篇系列 48 物理备份与恢复(xtrabackup 的增量备份与恢复,以及备份总结)
一.增量备份概述
xtrabackup 和innobackupex 二个工具都支持增量备份,这意味着能复制自上次备份以来更改的数据。可以在每个完整备份之间执行许多增量备份,因此,您可以设置一个备份过程,例如每周一次完整备份和每天一次增量备份,或者每天一次完整备份和每小时一次增量备份。对于定期自动备份可以在备份目录里生成带有时间戳的目录。
增量备份之所以有效,是因为每个InnoDB页面都包含一个日志序列号(LSN)。每个页面的LSN显示了最近的变化。增量备份复制每个页面,对比增量备份或完整备份的LSN, 查找要复制的页面集。有二个算法来查找LSN。第一个算法是:直接通过读取所有数据页来检查LSN页面。Percona服务器提供的第二个算法是:在服务器上启用已更改的页面跟踪功能,当页面被更改时,该功能会注意到这些页面。
这些信息将被写入一个紧凑的单独的位图文件。xtrabackup二进制文件将仅使用该文件读取增量备份所需的数据页,从而可能节省许多读取请求。如果xtrabackup二进制文件找到位图文件,则默认启用后一种算法。即使位图数据可用,也可以使用xtrabackup --incremental-force-scan强制扫描来读取所有页面。
增量备份实际上不会将数据文件与前一个备份的数据文件进行比较。实际上,您可以使用xtrabackup--incremental-lsn来执行增量备份,甚至不需要以前的备份,如果你知道它的LSN。增量备份只需读取页面并将其LSN与上一个备份的LSN进行比较。但是,您仍然需要一个完整的备份来恢复增量更改;如果没有作为基础的完整备份,增量备份是无用的。
二. 增量备份案例
要进行增量备份,请像往常一样从完全备份开始,xtrabackup二进制文件写入一个名为xtrabackup_checkpoints 进入备份的目标目录,这个文件包含一行内容to_lsn,是备份结束时数据库的LSN。
步骤1: 创建完整数据库备份,这里不在演示(上一篇有讲到)。完全备份结束后,如果您查看xtrabackup_checkpoints文件,会看到LSN number相关的版本号。以及备份类型为full -backuped。
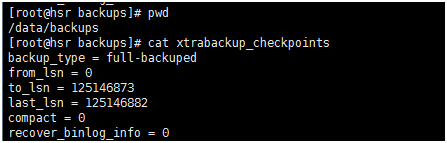
最后我把/data/backups的完整备份目录改成了/data/backups/base。
步骤2:现在已经有了完整的备份,可以基于它进行增量备份。首先创建/data/backups/inc1 目录。
[root@hsr backups]# mkdir inc1
[root@hsr backups]# chmod 777 inc1
[root@hsr backups]# ls
base inc1
-- 下面新增一条数据
INSERT INTO test.`testbackup` VALUES(11,'小王')
步骤3:增量备份
[root@hsr backups]# xtrabackup --host=127.0.0.1 --user bkpuser --password=123456 --backup --target-dir=/data/backups/inc1
--incremental-basedir=/data/backups/base
增量备份完成后,查看增量备份的xtrabackup_checkpoints文件,这里的from_lsn是备份的起始LSN,对于增量备份,它必须与完整备份或上一次增量备份的to_lsn(如果它是最后一个检查点)相同,这里的完全备份to_lsn与增量备份from_lsn 相同都是125146873序号。这里备份类型为incremental。如下图所示:
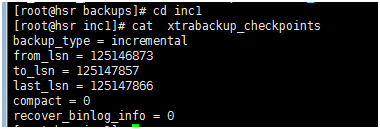
步骤4 : 增量备份(2)
现在可以使用inc1这个目录作为另一个增量备份的基础了,下面先插入一条数据,开始第二次增量备份。首先创建/data/backups/inc2目录
[root@hsr backups]# mkdir inc2
[root@hsr backups]# chmod 777 inc2
[root@hsr backups]# ls -l
总用量 0
drwxr-xr-x 6 root root 235 10月 10 12:53 base
drwxrwxrwx 6 root root 261 10月 10 13:05 inc1
drwxrwxrwx 2 root root 6 10月 10 13:15 inc2 -- 下面新增一条数据
INSERT INTO test.`testbackup` VALUES(12,'小李')
[root@hsr backups]# xtrabackup --host=127.0.0.1 --user bkpuser --password=123456 --backup --target-dir=/data/backups/inc2
--incremental-basedir=/data/backups/inc1
第二次增量备份成功后,下面是查看第二次增量备份的xtrabackup_checkpoints文件,起始的LSN 的 from_lsn序号与第一次增量备份的to_lsn 相同。
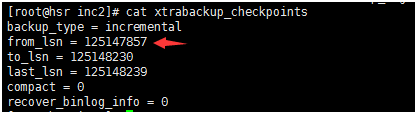
注意:to_lsn(最后一个检查点LSN)和last_lsn(最后一个复制的LSN)之间存在差异较大时,这意味着在备份过程中服务器上有一些流量。
三. prepare增量备份
prepare参数,一般情况下,在备份完成后,数据尚且不能用于恢复操作,因为备份的数据中可能会包含尚未提交的事务或已经提交但尚未同步至数据文件中的事务。因此,此时数据 文件仍处于不一致状态。-apply-log-only的作用是通过回滚未提交的事务以及同步已经提交的事务,使数据文件处于一致性状态。
警告:如果没有使用 xtrabackup --apply-log-only 选项,防止回滚阶段,那么增量备份将是无用的。
上面创建了完全备份后,可以使用prepare增量备份,然后对完全备份应用增量差异。上面的备份目录如下:
/data/backups/base
/data/backups/inc1
/data/backups/inc2
步骤1:prepare到完全备份,需要运行xtrabackup --prepare 防止回滚阶段.
[root@hsr backups]# xtrabackup --host=127.0.0.1 --user bkpuser --password= --prepare --apply-log-only --target-dir=/data/backups/base
步骤2:prepare第一个增量备份应用于完整备份
[root@hsr backups]# xtrabackup --host=127.0.0.1 --user bkpuser --password= --prepare --apply-log-only --target-dir=/data/backups/base
--incremental-dir=/data/backups/inc1
步骤3:准备第二个增量备份的过程与上面类似:将增量备份应用于(修改后的)基础备份,然后将其数据及时向前滚动到第二个增量备份点:
[root@hsr backups]# xtrabackup --host=127.0.0.1 --user bkpuser --password= --prepare --target-dir=/data/backups/base
--incremental-dir=/data/backups/inc2
注意:xtrabackup --apply-log-only合并除最后一个以外的所有增量备份,上面的prepare运用并没有使用 --apply-log-only选项。即使在最后一步中使用了--apply-log-only选项。备份仍然是一致的,但在这种情况下,服务器将执行回滚阶段。
一旦准备好的增量备份与完全备份相同,它们可以以相同的方式恢复。上面将增量备份文件都应用到了/data/backup /base文件中,如下图所示 完全备份的xtrabackup_checkpoints文件此时类型是 log-applied, 它的lsn与第二次增量备份的lsn相同了。
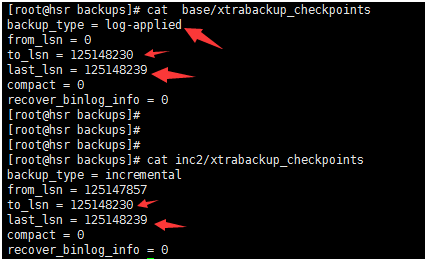
四. 恢复还原
-- 先停掉服务
[root@hsr data]# service mysql stop
-- 删除data目录下所有数据文件,安全起见可以先保存原有副本
[root@hsr data]# rm -rf /usr/local/mysql/data/*
-- 恢复
[root@hsr backups]# xtrabackup --defaults-file=/etc/my.cnf --host=127.0.0.1 --user bkpuser --password= --copy-back --target-dir=/data/backups/base
-- 恢复之后,更改data目录权限为mysql
[root@hsr data]# pwd
/usr/local/mysql/data
[root@hsr data]# chown -R mysql:mysql ../data
-- 启动服务成功
[root@hsr data]# service mysql start
Starting MySQL.. SUCCESS!
最后查看test.`testbackup`表,二次增量备份的数据出来了。
总结:学习xtrabackup差不多有5篇了,根据官网的文档来学习还有压缩备份、加密备份、部分备份等,还有一些高级功能:节流备份、无锁二进制日志信息、加密的InnoDB表空间备份。以及不完全恢复,克隆到从库slave。要完全掌握这个备份工具,还有很多知识点。这次学习算入门,以后在慢慢了解,并不断完善整合到文章中。
从42篇开始 到 48篇里,介绍了逻辑备份和物理备份, 逻辑备份保存是sql文本,可以在各种条件下恢复,但对于大数据量的系统,备份和恢复时间都会比较长。 物理备份则正好相反,由于它是基于文件的cp, 备份和恢复时间比较短,但备份的文件在不同平台上不一定兼容。
逻辑备份介绍了mysqldump工具是基于innodb引擎的,对于mysqlhotcopy工具没有介绍,该工具是基于myisam引擎的,最后介绍了物理备份的热备份工具xtrabackup。
mysql 开发进阶篇系列 48 物理备份与恢复(xtrabackup 的增量备份与恢复,以及备份总结)的更多相关文章
- mysql 开发进阶篇系列 47 物理备份与恢复(xtrabackup 的完全备份恢复,恢复后重启失败总结)
一. 完全备份恢复说明 xtrabackup二进制文件有一个xtrabackup --copy-back选项,它将备份复制到服务器的datadir目录下.下面是通过 --target-dir 指定完全 ...
- mysql 开发进阶篇系列 46 物理备份与恢复( xtrabackup的 选项说明,增加备份用户,完全备份案例)
一. xtrabackup 选项说明 在操作xtrabackup备份与恢复之前,先看下该工具的选项,下面记录了xtrabackup二进制文件的部分命令行选项,后期把常用的选项在补上.点击查看xtrab ...
- mysql 开发进阶篇系列 45 物理备份与恢复(xtrabackup 安装,用户权限,配置)
一. 安装说明 安装XtraBackup 2.4 版本有三种方式: (1) 存储库安装Percona XtraBackup(推荐) (2 )下载的rpm或apt包安装Percona XtraBacku ...
- mysql 开发进阶篇系列 44 物理备份与恢复( 热备份xtrabackup 工具介绍)
一.概述 物理备份和恢复又分为冷备份和热备份.与逻辑备份相比,它最大优点是备份和恢复的速度更快.因为物理备份的原理都是基于文件的cp. 1.1 冷备份 冷备份就是停掉数据库服务.这种物理备份一般很少使 ...
- mysql 开发进阶篇系列 42 逻辑备份与恢复(mysqldump 的完全恢复)
一.概述 在作何数据库里,备份与恢复都是非常重要的.好的备份方法和备份策略将会使得数据库中的数据更加高效和安全.对于DBA来说,进行备份或恢复操作时要考虑的因素大概有如下: (1) 确定要备份的表的存 ...
- mysql 开发进阶篇系列 55 权限与安全(安全事项 )
一. 操作系统层面安全 对于数据库来说,安全很重要,本章将从操作系统和数据库两个层面对mysql的安全问题进行了解. 1. 严格控制操作系统账号和权限 在数据库服务器上要严格控制操作系统的账号和权限, ...
- mysql 开发进阶篇系列 20 MySQL Server(innodb_lock_wait_timeout,innodb_support_xa,innodb _log_*)
1. innodb_lock_wait_timeout mysql 可以自动监测行锁导致的死锁并进行相应的处理,但是对于表锁导致的死锁不能自动监测,所以该参数主要用于,出现类似情况的时候等待指定的时间 ...
- mysql 开发进阶篇系列 10 锁问题 (相同索引键值或同一行或间隙锁的冲突)
1.使用相同索引键值的冲突 由于mysql 的行锁是针对索引加的锁,不是针对记录加的锁,所以虽然是访问不同行的记录,但如果是使用相同的索引键,是会出现锁冲突的.设计时要注意 例如:city表city_ ...
- mysql 开发进阶篇系列 2 SQL优化(explain分析)
接着上一篇sql优化来说 1. 定位执行效率较低的sql 语句 通过两种方式可以定位出效率较低的sql 语句. (1) 通过上篇讲的慢日志定位,在mysqld里写一个包含所有执行时间超过 long_q ...
随机推荐
- rn下的弹性布局
重点: 1]react native 下的弹性布局名字叫:flexDirection 2]flexDirection的默认值是column而不是row,而flex也只能指定一个数字值. 3]使用fle ...
- win10 64位 安装scrapy
在学习python时,不可避免下载了Anaconda,当我打算写爬虫时,urllib,requests,selenium,pyspider都已经安装好了,可以直接使用了,但是有一天我想要使用scrap ...
- istio实现对外暴露服务
1.确认istio-ingressgateway是否有对外的IP kubectl get service istio-ingressgateway -n istio-system 如果 EXTERNA ...
- 不支持find_element_by_name元素定位方法,抛不支持find_element_by_name元素定位方法,会抛如下错误 org.openqa.selenium.InvalidSelectorException: Locator Strategy 'name' is not supported for this session的解决
appium1.5后不支持find_element_by_name元素定位方法,会抛如下错误 org.openqa.selenium.InvalidSelectorException: Locator ...
- 20155205 郝博雅 Exp9 Web安全基础
20155205 郝博雅 Exp9 Web安全基础 一.实验内容 一共做了13个题目. 1.WebGoat 输入java -jar webgoat-container-7.1-exec.jar 在浏览 ...
- ROS学习笔记(一) : 入门之基本概念
目录 基本概念 1. Package 2. Repositories 3. Computation Graph 4. Node 5. Master 6. Message 7. Topic 8. Ser ...
- sftp修改用户home目录后登录时报connection closed by remote host
在sftp用户需要修改登录根目录的情况下,我们可以修改/etc/ssh/sshd_config文件中ChrootDirectory /home/[path]的路径. 但是,在重启sshd服务后,sft ...
- HDFS-HA高可用
HDFS-HA工作机制 通过双NameNode消除单点故障 HDFS-HA工作要点 1.元数据管理方式需要改变 内存中各自保存一份元数据: Edits日志只有Active状态的NameNode节点可以 ...
- [转] AppArmor
AppArmor https://help.ubuntu.com/14.04/serverguide/apparmor.html AppArmor 是一个实施了基于名称强制存取控制的Linux安全模组 ...
- 解决Jenkins安装的时区问题
正常情况下,jenkins是Java执行在Java容器,比如tomcat容器之下,只要改了tomcat的时区就行.我这里是为了方便后续的代码可用性测试,用的是Ubuntu中apt在线安装,也只是安装了 ...