基于python的opcode优化和模块按需加载机制研究(学习与个人思路)(原创)
基于python的opcode优化和模块按需加载机制研究(学习与思考)
姓名:XXX
学校信息:XXX
主用编程语言:python3.5
个人技术博客:http://www.cnblogs.com/Mufasa/
文档转换为PDF有些图片无法完全显示,请移步我的博客查看
完成时间:2019.03.06
本项目希望您能完成以下任务:
- 优化python字节码解析代码,从底层提升python脚本运行效率;(底层、编译器、虚拟机)
- 基本思路可以统计游戏常用opcode指令,进行类似opcode合并,opcode排序;
- 另外,可以研究下指令预测相关资料,比如indirect threading,寻找更优的机制;(自然语言处理里面的东西好像可以用,类似语言翻译)
- 为了缩短应用的启动时间,需要在应用启动时,把模块进行按需加载(或者延迟加载,lazy import);(优化启动项)
- 目前的不同实现主要是针对 Python 标准库进行处理,对第三方扩展库,尤其是游戏引擎相关的扩展支持不好,甚至无法支持;(软件适配&通用化)
- 此课题不仅有一定的学术研究意义,更在手游等App中有很好的实用价值;(意义价值)
- 希望在自适应学习的基础上,能够做到按需加载。(自适应)
一,Python 字节码
Python 源代码文件以.py结尾,字节码文件以.pyc结尾;其中字节码文件在一个叫__pycache__ 的子目录中,它可以避免每次运行 Python 时去重新解析源代码。

图1 python代码运行过程
Python执行的四步操作:
1,lexing: 词法分析,就是把一个句子分解成 token。大致来说,就是用str.split()可以实现的功能。
2,parsing:解析,就是把这些 token 组装成一个逻辑结构。
3,compiling:编译,把这个逻辑结构转化成一个或者多个code object (代码对象)
4,interpreting:解释,执行每个code object 代表的代码。
其中前三步可以归类为“代码编译”,最后一步单独成类。Python 程序的执行过程就是,它先把代码编译成 bytecode (字节码)指令,交给虚拟机,逐条执行 bytecode 指令。
分清function object、code object ,以及 bytecode
①function object:定义一个函数之后,它就成了一个function object (函数对象)。只要不使用函数调用符号——也就是小括号——这个函数就不会执行。但是它已经被编译了,可以通过这个function object 的__code__ 属性找到它的 code object
②code object:code object 的类型是‘code’
③bytecode:bytecode 是 code object 的一个属性的值。这个属性名为 co_code,它的类型是‘bytes’,长度是8。例:b'|\x00\x00d\x01\x00\x14S'
实例1:
>>> def double(a):
return a*2 # 并不知道为什么贴在这里缩进会是这样 >>> import dis
>>> dis.dis(double)
2 0 LOAD_FAST 0 (a)
2 LOAD_CONST 1 (2)
4 BINARY_MULTIPLY
6 RETURN_VALUE
第1列的2源代码中的行号;第2列的数字 0 3 6 7 是 bytecode 的偏移量;第3列很好理解,都是opcode。
因为可以节省编译时间,这里有一篇非常详细的文章,作者在遗传编程领域工作,发现他们Python 程序的总运算时间中,有50%都被编译过程吃掉。于是作者深入到 bytecode 层次进行了小小改动,大幅削减了编译时间,把总的运算时间降至不足原先的一半。(有改进的潜力)
理论上的优化方向
1,从字节码bytecode上下手

图2 python字节码优化猜想1-代码级优化
优点:有一些固定的套路可以使用并且实施起来比较简单,例子:累加可以直接将很多分步直接在同一次处理中进行,节省步数
缺点:优化后的效率,不能达到量级变化
2,从串行转并行入手(多线程、多进程、多核心)
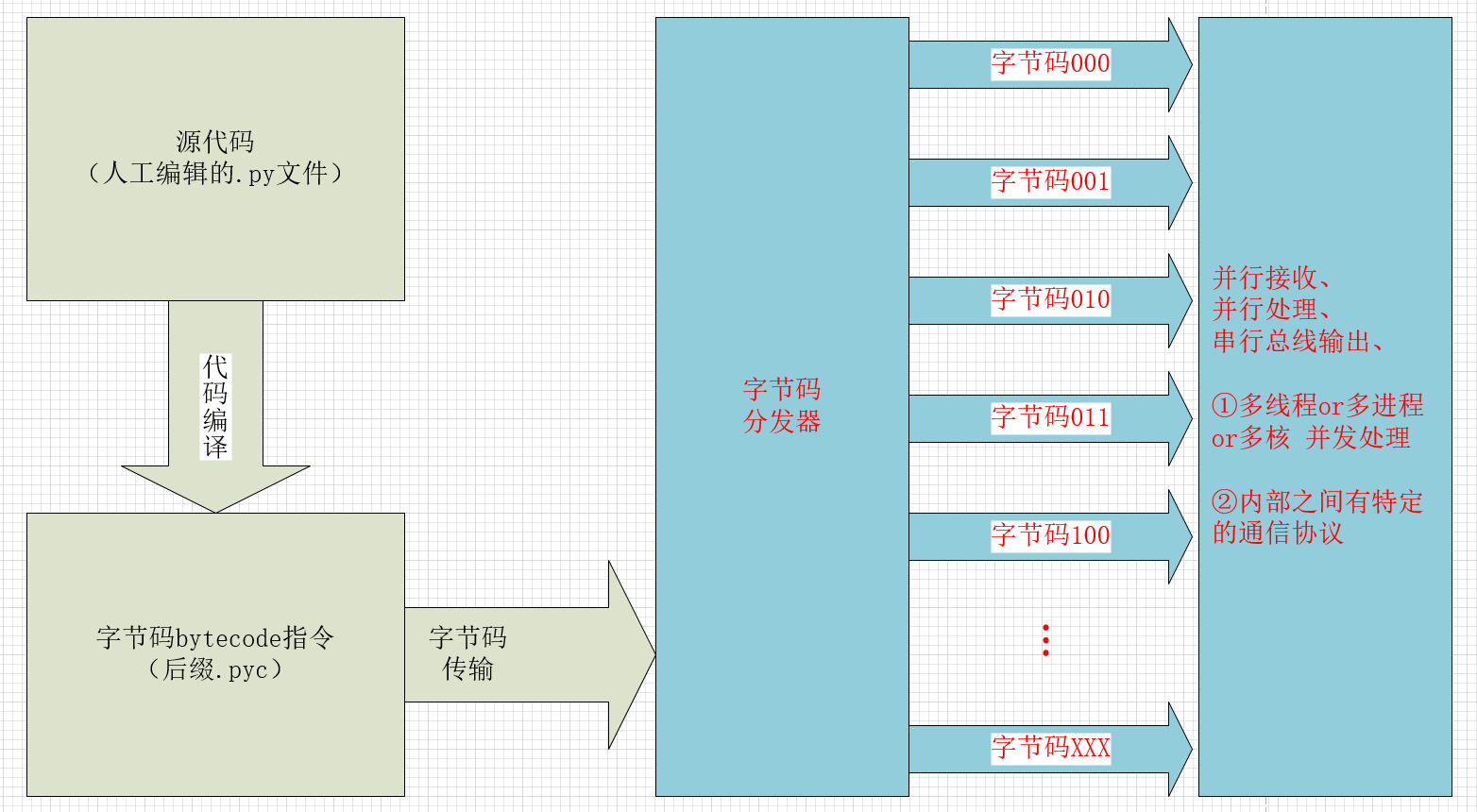
图3 python字节码优化猜想2-处理方式优化
优点:需要从python解释器底层进行重新布局
缺点:优化的效率可以成倍数提升,并且效率与相关硬件有一定关系,参考nvidia的pascal架构的并行计算卡
前景:现在的手机芯片、电脑芯片大都是多核心、多进程的,这个可以一试。
我自己之前去实习的公司中船重工709所凌久电子,设计过一台拥有256颗C66X核心的DSP处理机,这台机器这个就是实时、并发计算的,耗电快赶上空调,但是性能真的很强很强!!!(我在简历里面写过)
(注:我只是最近两天看了一下相关的文档资料,我现在不确定python解释器是否已经在内部集成并行处理的功能)
参考:
3,从python解释器层级进行优化
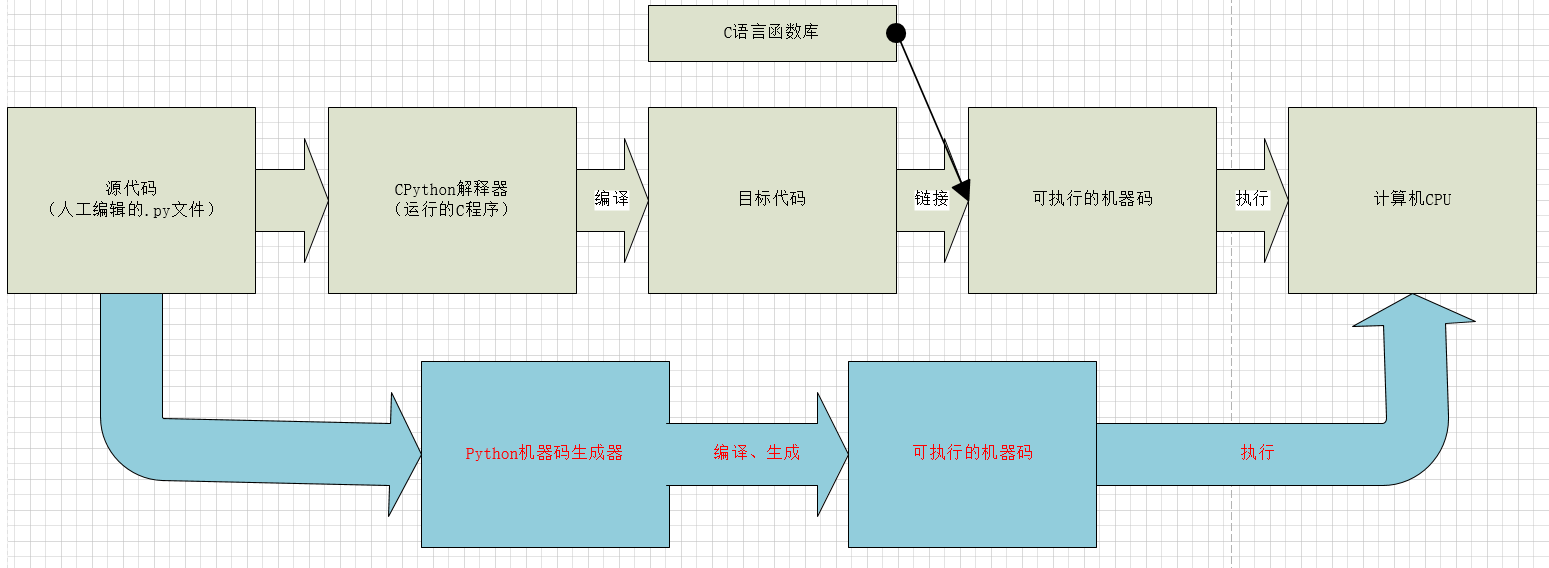
图4 python字节码优化猜想3-解释器层级
之前的两个都是不触及python最底层的东西,这里是从最底层进行优化的思考。
如上图4可知,我们现在常使用的CPython解释器是通过C语言进行二级运行的,这就和android虚拟机一样,一台机器上运行另一个环境,当我们想要改变什么的时候还需要通过中介来通知做出改变,这个就和两个人隔着墙通过手机来通话,但是这样不如我们面对面沟通的明了!!!
优点:可以省去中间的很多步骤,直接对计算机硬件进行操作,效率提升至C语言那般畅快
缺点:开发难度大,计算机越接近底层开发难度越大,这需要一个团队来进行。
参考:Python解释器
总体参考链接:
理解 Python 的执行方式,与字节码 bytecode 玩耍 (上)
理解 Python 的执行方式,与字节码 bytecode 玩耍 (下)
二,opcode指令
根据上文中的bytecode以及其附属的给人类理解查看opcode。opcode又称为操作码,是将python源代码进行编译之后的结果,python虚拟机无法直接执行human-readable的源代码,因此python编译器第一步先将源代码进行编译,以此得到opcode。例如在执行python程序时一般会先生成一个pyc文件,pyc文件就是编译后的结果,其中含有opcode序列。Opcode和bytecode是有一定相关性的两种不同表述。(这里不做累赘表述)
python的目标不是一个性能高效的语言,出于脚本动态类型的原因虚拟机做了大量计算来判断一个变量的当前类型,并且整个python虚拟机是基于栈逻辑的,频繁的压栈出栈操作也需要大量计算。
缺点即为可能的改进方向!
参考链接:
三,指令预测
这个研究比较少,但是感觉应该和NLP有一定的关系(可以进行一定的迁移应用)
参考链接:
高性能虚拟机解释器:DTC vs ITC(Indirect-Threaded Code)
Dynamically Disabling Way-prediction to Reduce Instruction Replay
The research of indirect transfer prediction technology based on information feedback
四,模块按需加载
Python import原理:

图5 import运行大致原理
使用import module_name语句就可以将这个文件作为模块导入。系统在导入模块时,要做以下三件事:
1.为源代码文件中定义的对象创建一个名字空间,通过这个名字空间可以访问到模块中定义的函数及变量。
2.在新创建的名字空间里执行源代码文件。
3.创建一个名为源代码文件的对象,该对象引用模块的名字空间,这样就可以通过这个对象访问模块中的函数及变量。
普通加载方式:
文件抬头就对所有所需的库进行加载,这样的缺点是耗时(尤其是对快应用、启动速度有要求的程序很敏感)
以前的两种惰性/延迟加载方法:
①本地子功能区加载而非程序启动时的全局加载。直到你的程序运行需要这个库的时候才进行加载;缺点:易重复载入库文件、容易遗忘库载入的范围。
②惰性加载。需要模块的时候触发 ModuleNotFoundError 提前发现这个模块,而延迟的只是后续补加载过程;缺点:显式优于隐式、如果一个模块希望立即加载,那么在延迟加载时,它可能会严重崩溃。(Mercurial实际上开发了一个模块黑名单,以避免延迟加载来解决这个问题,但是他们必须确保对其进行更新,因此这也不是一个完美的解决方案。)
最新py3.7中的方法:
在Python 3.7中,模块现在可以在其上定义__getattr__(),允许编写一个函数,在模块上的属性不可用时导入模块。这样做的缺点是使它成为一个惰性导入而不是一个加载,因此很晚才发现是否会引发ModuleNotFoundError。但是它是显式的,并且仍然是为您的模块全局定义的,因此更容易控制。
改进方向:发现导入错误被推迟,如何提前获知这个可能出现的导入错误防止程序抛出异常并终止。
缺点:当你用的时候才开始加载,这个会锁住主线程进行库加载动作,如果是带有画面的操作,那么就会有视觉延迟(假设这个加载是第一次运行,且很耗时)
改进:能不能在主线程旁边开一条线程提前进行预加载!!!虽然这个多线程还是使用的同一条时间线,但是这种方法将延迟的时间进行了平分
例如:
如果使用原始的加载需要消耗0.5s的时间,这0.5s=500ms>>16.6ms我们人眼是可以察觉的
但是,使用多线程加载,我们可以把这个延迟的时间分配在各个过程(假如这其中有20个 过程,有时人类自身的操作比较慢也可以在这个过程中见缝插针进行预加载)中,0.5/20=0.001s=1ms<<16.6ms这个时间人眼是感觉不错来的。
import importlib # 这个是实现lazy_import的功能函数
def lazy_import(importer_name, to_import):
module = importlib.import_module(importer_name) # 直接加载调用的后一级函数 import_mapping = {} # 字典 键名:有可能为缩写名 值名:为原始可查找库名,例如:import_mapping['np'] = 'numpy'
for name in to_import:
importing, _, binding = name.partition(' as ')
if not binding:
_, _, binding = importing.rpartition('.')
import_mapping[binding] = importing def __getattr__(name):
if name not in import_mapping: # 如果这个库没在import_mapping中,就抛出异常错误,并且中断
message = f'module {importer_name!r} has no attribute {name!r}'
raise AttributeError(message)
importing = import_mapping[name]
imported = importlib.import_module(importing,module.__spec__.parent)
# print('name=',name,'module=',module,'module.__spec__=',module.__spec__,'module.__spec__.parent=',module.__spec__.parent)
setattr(module, name, imported) # sub, np, numpy
return imported return module, __getattr__ #返回一个库和一个方法
详情见网址:lazy_import源码解析(原创) 我自己的博客
现在的思路:

图6 按需预加载

图7 按需预加载运行逻辑
粗糙的实现代码1:preload.py
优点:
将preload在需要的函数之前运行(这个是多线程的加载方式,不会锁定主线程的相关计算,同时在计算机IO空闲的时候加载,见缝插针进行。提高程序运行效率),在后面需要相关函数时就直接调用这个功能即可
缺点:
①预加载的代码提前多少,这个我现在还没有办法说清,要具体看机器的计算时间;②不太人性化,需要人为或者程序转换原始.py程序。
总地来说也是一种尝试!后面还可以试试其他的多种方法解决。
import threading
from importlib import import_module
# 可以返回值的功能函数
class MyThread(threading.Thread):
def __init__(self, func, args, name=''):
threading.Thread.__init__(self)
self.name = name
self.func = func
self.args = args
self.result = self.func(*self.args) # 返回一个函数
def get_result(self):
try:
return self.result
except Exception:
return None def module_before(module_name):
t = MyThread(import_module, [module_name], import_module.__name__)
t.start()
return t if __name__ == '__main__':
numpy_mid = module_before('numpy')
numpy = numpy_mid.get_result()
print(numpy.array([1, 2, 3, 4]))
代码段2:测试_preload.py
import preload as pld # 这里面的预加载是放在需要这个函数的前面的相关代码块前,
modules = ['numpy', 'sys', 'os']
module = {}
for i in modules:
module[i] = pld.module_before(i) np = module['numpy'].get_result()
print(np.array([1, 2, 3, 4]))
参考链接:
An approach to lazy importing in Python 3.7
动态导入对象,importlib.import_module()使用
备注:这个里面的思路只是现在的一些方向,欢迎大家讨论指教。
基于python的opcode优化和模块按需加载机制研究(学习与个人思路)(原创)的更多相关文章
- Vue性能优化之组件按需加载(以及一些常见的性能优化方法)
关于Vue中的按需加载我就简单介绍一下:大概就是我们所有的东西都会在app.js里面,但是我们并不需要把所有的组件都一次性加载进来,我们可以在需要它的时候再将它加载进来,话不多说,开车! 1.webp ...
- webpack4下import()模块按需加载,打包按需切割模块,减少包体积,加快首页请求速度
一:背景 因为项目功能越加越多,打包后的体积越来越大,导致首页展示的时候速度比较慢,因为要等压缩的js的包加载完毕. 首页展示的时候只需要对应的js,并不需要全部的js模块,所以这里就可以用按需加载, ...
- 大规模服务网格性能优化 | Aeraki xDS 按需加载
作者 钟华,腾讯云专家工程师,Istio project member.contributor,专注于容器和服务网格,在容器化和服务网格生产落地方面具有丰富经验,目前负责 Tencent Cloud ...
- python模块与包加载机制
模块的搜索路径: When a module named spam is imported, the interpreter searches for a file named spam.py in ...
- Python模块的动态加载机制
Python在运行环境初始化中,就将sys module加载到了内存中, 实际上,Python是将一大批的module加载到了内存中.但是为了使local名字空间能够达到最干净的效果,Python并没 ...
- pdfjs优化,实现按需加载,节省流量和内存
1 问题 当使用pdfjs来实现预览功能的时候,遇到了2个问题: 一是带宽占用过大,会下载整个pdf文件,这对部署在公网的应用来说,成本压力很大,因为云服务带宽是很贵的. 二是内存占用过大,一个80M ...
- Extjs4.1.x使用Application动态按需加载MVC各模块
我们知道Extjs4之后提出了MVC模块开发,将以前肥厚的js文件拆分成小的js模块[model\view\controller\store\form\data等],通过controller拼接黏合, ...
- 原创《分享(Angular 和 Vue)按需加载的项目实践优化方案》
针对前端优化的点有很多,例如:图片压缩,雪碧图,js/css/html 文件的压缩合并, cdn缓存, 减少重定向, 按需加载 等等 最近有心想针对 ionic项目 和 vue项目,做一个比较大的优 ...
- Webpack按需加载一切皆模块
前言 在学习 Webpack 之前,我们需要了解一个概念:模块. 何为模块? 如果你曾学过 Java , C# 之类的语言,一定会知道 Java 中的 import 或 C# 中的 using 吧? ...
随机推荐
- idea实现热部署并且开启自动编译
[注]本文转自https://blog.csdn.net/z15732621582/article/details/79439359博文,如有冒犯,请联系博主: 问题描述: 最近在调试代码并进行本地测 ...
- spring实现listener(转)
博主说未经同意,不能转载,我这种小码农,他应该不会在乎 原创地址:http://blog.csdn.net/caihaijiang/article/details/8629725 spring 允许 ...
- Programming for Everyone !
Hello Internet ! This blog is to store my algorithm practices. Since Evernote code blocks do not sho ...
- Eclipse导入的User Libarary
在使用eclipse导入外部jar包时,经常使用Add User Libarary的方式,采用这种方式,外部的jar包没有直接添加到WEB-INF/libs下,那这些jar是在哪里引入的呢? 使用外部 ...
- PCL安装
本文是在Ubuntu16.04下安装PCL. 按照官网的教程,有两种方法可以安装: 1.直接安装预先编译好的二进制库文件 sudo add-apt-repository ppa:v-launchpad ...
- SVN服务端和客户端的安装与搭建
版权声明:本文为博主原创文章,转载请注明原文出处. https://blog.csdn.net/zzfenglin/article/details/50931462 SVN简介 SVN全名Subver ...
- 20145232韩文浩《网络对抗》MSF基础应用
MS08-067漏洞攻击 攻击机:Kali:192.168.31.132 靶机:win XP SP3(English):192.168.31.180 在VMware中设置两台虚拟机网络为NAT模式,自 ...
- spark随笔
spark基于RDD成功构建起大数据处理的一体化解决方案,将MappReduce.Streaming.SQL.Machine Learning.Graph Processing等 大数据计算模型统一到 ...
- CCNA学前基础一
网络设备: 集线器:集线器就是一种采用共享式工作状态的设备.Hub将信号放大后传输给其他端口,即传输线路是共享的. 交换机:用于连接终端设备,和基本的安全功能还有广播域的隔离.优点实现多用户同时访问, ...
- PYTHON黑帽编程 4.1 SNIFFER(嗅探器)之数据捕获--补充
荒废了一个多月了,重新捡起来,手生了不少.发现在<4.1下>的文章里没有 提到pcap库,实在是不应该. 在网络数据分析的工具中,tcpdump绝对是大名鼎鼎,tcpdump底层是libp ...