Hadoop| MapperReduce02 框架原理
MapReduce框架原理
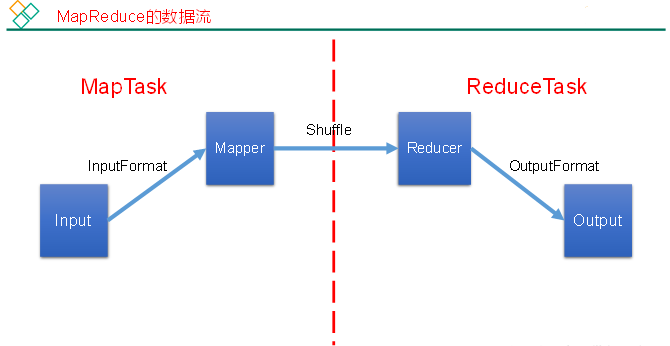
MapReduce核心思想
1)分布式的运算程序往往需要分成至少2个阶段。
2)第一个阶段的MapTask并发实例,完全并行运行,互不相干。
3)第二个阶段的ReduceTask并发实例互不相干,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出。
4)MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行运行。
1、InputFormat(切片| 把切片变成k,v值)数据输入
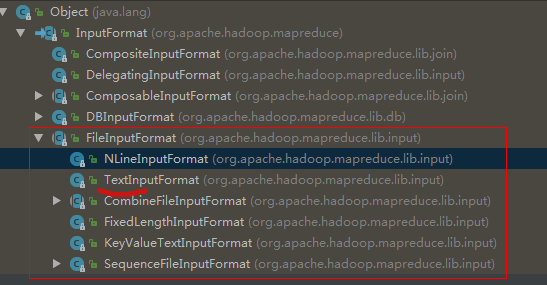
一. 默认的FileInputFormat--TextInputFormat
public abstract class FileInputFormat<K, V> extends InputFormat<K, V>
public class TextInputFormat extends FileInputFormat<LongWritable, Text> Rich leaning form --每条记录对应的键值对---> (0,Rich leaning form )
@Override
public RecordReader<LongWritable, Text> createRecordReader(InputSplit split,TaskAttemptContext context) {
String delimiter = context.getConfiguration().get("textinputformat.record.delimiter");
byte[] recordDelimiterBytes = null;
if (null != delimiter)
recordDelimiterBytes = delimiter.getBytes(Charsets.UTF_8);
return new LineRecordReader(recordDelimiterBytes);
}
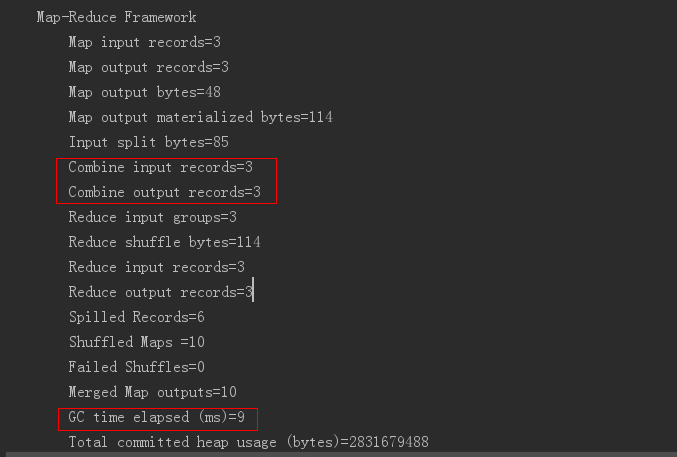
默认切片规则的实现类FileInputFormat;默认把切片变成key,value值的实现类为TextInputFormat(按行读取每条记录,键是存储该行在整个文件中的起始偏移量,LongWritable类型;值是这行内容 Text类型),它返回的RecordReader类型为LineRecordReader。
MapTask的数量是由InputFormat来指定的,InputFormat生成多少个InputSpilt切片数就会有多少个task。
切片与MapTask并行度决定机制
MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个Job的处理速度。
MapTask并行度决定机制
数据块:Block是HDFS物理上把数据分成一块一块。
数据切片:数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。

yarn优化策略,本地启动任务启动MapTask,尽量不产生网络IO;按照一个个文件来切,判断是否大于128M;切片数量默认>=文件数量。
切片的原理
FileInputFormat切片源码解析


FileInputFormat切片大小参数设置

Job提交流程
源码
waitForCompletion() submit(); // 1建立连接
connect();
// 1)创建提交Job的代理
new Cluster(getConfiguration());
// (1)判断是本地yarn还是远程
initialize(jobTrackAddr, conf); // 2 提交job
submitter.submitJobInternal(Job.this, cluster)
// 1)创建给集群提交数据的Stag路径
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf); // 2)获取jobid ,并创建Job路径
JobID jobId = submitClient.getNewJobID(); // 3)拷贝jar包到集群
copyAndConfigureFiles(job, submitJobDir);
rUploader.uploadFiles(job, jobSubmitDir); // 4)计算切片,生成切片规划文件
writeSplits(job, submitJobDir);
maps = writeNewSplits(job, jobSubmitDir);
input.getSplits(job); // 5)向Stag路径写XML配置文件
writeConf(conf, submitJobFile);
conf.writeXml(out); // 6)提交Job,返回提交状态
status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());
确认文件夹是否存在; 获取jobId;要往jobId中提交一些文件:
copyAndConfigureFiles(Job,submitJobDir)即 xml文件 | 切片文件信息 writeConf(conf,SubmitJobFile)
切片的方法:
①遍历所有文件 |
②判断是否可切 |
③计算块大小,切片大小 | minsize blocksize maxsize -->取中间值;splitSize要比blockSize大,则minsize设置 > blocksize;splitsize< blicksize,则maxsize < blocksize
return Math.max(minSize, Math.min(maxSize, blockSize));
本地模式没有块,默认32M;
④ Long bytesRemaining / splitsize > 1.1(本地剩余/切片数量)
但切时按1倍切,保证切片体积不至于太小;bytesRemaining -=splitSize
默认切片规则的实现类FileInputFormat;默认把切片变成key,value值的实现类为TextInputFormat(按行读取每条记录,键是存储该行在整个文件中的起始偏移量,LongWritable类型;值是这行内容 Text类型),它返回的RecordReader类型为LineRecordReader。
CombineTextInputFormat 改变了切片规则;虽重写了从切片到k,v但返回的还是<LongWritable, Text>;适用于小文件过多的场景;
CombineTextInputFormat用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个MapTask处理。 public abstract class CombineFileInputFormat<K, V> extends FileInputFormat<K, V>
public class CombineTextInputFormat extends CombineFileInputFormat<LongWritable, Text> CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m
注意:虚拟存储切片最大值设置最好根据实际的小文件大小情况来设置具体的值。
生成切片过程包括:虚拟存储过程和切片过程二部分。
(1)虚拟存储过程:
将输入目录下所有文件大小,依次和设置的setMaxInputSplitSize值比较,如果不大于设置的最大值,逻辑上划分一个块。如果输入文件大于设置的最大值且大于两倍,那么以最大值切割一块;当剩余数据大小超过设置的最大值且不大于最大值2倍,此时将文件均分成2个虚拟存储块(防止出现太小切片)。
例如setMaxInputSplitSize值为4M,输入文件大小为8.02M,则先逻辑上分成一个4M。剩余的大小为4.02M,如果按照4M逻辑划分,就会出现0.02M的小的虚拟存储文件,所以将剩余的4.02M文件切分成(2.01M和2.01M)两个文件。
(2)切片过程:
(a)判断虚拟存储的文件大小是否大于setMaxInputSplitSize值,大于等于则单独形成一个切片。
(b)如果不大于则跟下一个虚拟存储文件进行合并,共同形成一个切片。
(c)测试举例:有4个小文件大小分别为1.7M、5.1M、3.4M以及6.8M这四个小文件,则虚拟存储之后形成6个文件块,大小分别为:
1.7M,(2.55M、2.55M),3.4M以及(3.4M、3.4M)
最终会形成3个切片,大小分别为:
(1.7+2.55)M,(2.55+3.4)M,(3.4+3.4)M
以后都是FileInputFormat的子类:
KeyValueTextInputFormat 改变了切片到k,v值;每一行均为一条记录,被分隔符分割为key,value;
NLineInputFormat 按行切片;切片-->k,v用默认方式;(不再按块去划分,而是按NLineInputFormat指定的行数N来划分即:输入文件的总行数 / N = 切片数)
一个文件一个切片,RecordReader把切片变成k,v值;
默认输入输出类型:InputFormat从数据源头的类型就改变了;
二. 自定义InputFormat

//自定义InputFormat,继承FileInputFormat
public class WholeInputFormat extends FileInputFormat<Text, BytesWritable> { /**
* 1.设置为不切分,一次读取一个完整文件封装为k,v
* @param context
* @param filename
* @return
*/
@Override
protected boolean isSplitable(JobContext context, Path filename) {
return false;
} /**
*2. 重写RecordReader --> return new WholeRecordReader()
* @param split
* @param context
* @return
* @throws IOException
* @throws InterruptedException
*/
@Override
public RecordReader<Text, BytesWritable> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException { return new WholeRecordReader();
}
} public class WholeRecordReader extends RecordReader<Text, BytesWritable> {
private Text key = new Text();
private BytesWritable value = new BytesWritable();
private boolean isRead = false;
private FileSystem fileSystem;
private FileSplit fs;
private Path path;
private FSDataInputStream fis; /**
* 1.
* @param split
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
fileSystem = FileSystem.get(context.getConfiguration());//new Configuration(),这里已经开了,只需调用
fs = (FileSplit) split; //从输入InputSplit中解析出一个个key/value
path = fs.getPath();
fis = fileSystem.open(path); } /**
* 2.true读取key, value
* @return
* @throws IOException
* @throws InterruptedException
*/
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
if (!isRead){
//ture, 读取key
String path = fs.getPath().toString();
key.set(path); //读取value
long length = fs.getLength();
byte[] bytes = new byte[(int) length];
fis.read(bytes);
value.set(bytes, 0, bytes.length); //设为true
isRead = true;
return true;
}else {
return false;
}
} /**
* 3. 获取key
* @return
* @throws IOException
* @throws InterruptedException
*/
@Override
public Text getCurrentKey() throws IOException, InterruptedException {
return key;
} /**
* 4.获取value
* @return
* @throws IOException
* @throws InterruptedException
*/
@Override
public BytesWritable getCurrentValue() throws IOException, InterruptedException {
return value;
} /**
* 5. 获取读取进度;
* @return
* @throws IOException
* @throws InterruptedException
*/
@Override
public float getProgress() throws IOException, InterruptedException {
return isRead ? 1 : 0;
} /**
* 6. 关流
* @throws IOException
*/
@Override
public void close() throws IOException {
fileSystem.close();
IOUtils.closeStream(fis);
}
} public class WholeDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1.实例化
Job job = Job.getInstance(new Configuration());
//2.设置jar类路径
job.setJarByClass(WholeDriver.class);
//3.设置自定义的InputFormat
job.setInputFormatClass(WholeInputFormat.class);
//输出文件类型;输出时用SequenceFileOutputFormat输出合并文件
job.setOutputFormatClass(SequenceFileOutputFormat.class);
//4.设置Map输出端的k v类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(BytesWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(BytesWritable.class);
//5.设置输入输出路径
FileInputFormat.setInputPaths(job, new Path("F://input"));
FileOutputFormat.setOutputPath(job, new Path("F://output"));
//6.提交任务
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
} }
2、 MapReduce工作流程


在有限的内存实现全排序;
Job.split、wc.jar、Job.xml等文件通过客户端提交给yarn,yarn根据切片信息启动相应数量的MapTask;
MapTask1处理切片128M的数据块,它调用默认的TextInputFormat的RecoderReader类型的方法读取数据,它一行行读到的 k,v值(行号,行内容)给Mapper();
Mapper()调用map(k,v)方法 通过context.write(k, v)写出去(给框架) ----通过outputCollector收集(MapTask的处理结果)<K,V,P>到环形缓冲区中;
排序的时候要先完成分区(就是把分区号一样的在一块);再在分区内部排序-->分区排序--局部的快排序(内存保证输出的每个文件内部是有序的,按照文件key做全排序,相同的key挨一起),
缓冲区满就溢出到文件磁盘(文件特点:①一个文件;②分区且区内有序;溢写完之后文件分两个部分spill.index索引(文件有多少个分区,分区从哪结束)和spill.out输出文件)
---->>多次溢出(取决于map方法)形成的多个文件,不同文件之间是无序的--->多个溢写的文件合并成一个文件,按照分区归并排序(A、B文件之间做比较,若A第一个值 < B第一个值,就写到C中;接着再比较下面的依次...)
首先分区1进行归并写到文件的前半部分,分区2再进行归并写到文件的后半部分...(归并是数据流)
到此为止,Map阶段结束(生成一个分区且区内有序的完整的输出文件,shuffle的前半部分);
MapTask输出文件分区且区内有序,多个MapTask形成多个分区且区内有序的文件;多个map输出文件交给Reduce来处理,全都下载到本地;
--->>根据分区数启动相应数量的ReduceTask,ReduceTask1下载所有分区patition0即分区1的数据拷贝到内存缓冲区buffer,内存不够溢出到磁盘;ReduceTask2下载所有分区2的数据;
---->>各自合并文件,归并排序(多个文件归并得到一个文件,文件特点是:按照key有序);
至此完成了从map输出到reduce输入的3次排序--全排序;有了这个全排序文件才能进行分组-->输出到reduce()方法里边;这就是shuffle的全过程(Map方法之后,Reduce方法之后;3次全排序+分组);
--->>一次读取一组,按照相同key分组 --> GroupingComparator(k, knext) 分组 --->>Reduce(k,v)方法 context.write(k,v)-->>
经过outputformat(默认TextOutputFormat)RecordWriter--- write(k, v) --->>Part-r-00000文件; 如果启动了combiner:(前提是求和操作而不是求平均值)
第一次排序结束后在落盘(溢出写入磁盘)之前会经过combiner的合并(没有重复的单词,但两个ReduceTask之间有重复的单词);
第二次排序即归并排序完之后还没落盘之前(没有重复的的单词)数据流会流入combiner(之后可进行压缩),写到磁盘上;
第三次排序,两个相同分区的数据下载(有可能有重复单词)合并---> 启动Reduce,没有combine
3、shuffle机制
目的:分组 --->方法是全排序;
Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。
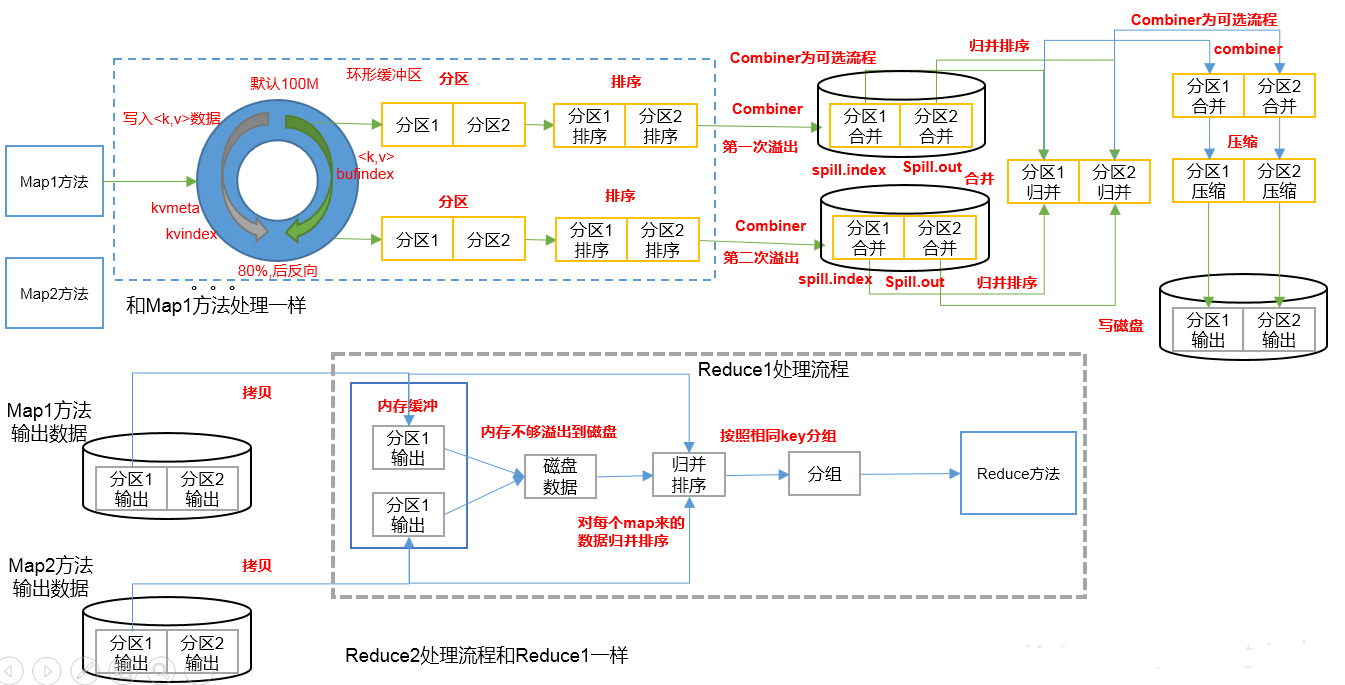
环形缓冲区:在逻辑上就是环形的,特点没头没尾;<k,v,p>进入环形缓冲区,传递过来的是序列化的数据,右环是数据,左环是索引;
写之前要排序,数据要反序列化成对象才能比较,看1、2数据是否需要交换顺序,如果需要交换交换的是索引;按照索引一组一组把数组写到磁盘上;
分区也是在排序;首先按P排序,再按k排序--->写到磁盘上; 分区和排序全都发生在缓冲区当中,且分区和排序是同时完成的;在数据没填满(达到80%)时就会溢写(溢出之前就已经排好序了)到磁盘;
shuffle是一部分MapTask,一部分ReduceTask;MapTask会有一个单独的输出文件;ReduceTask要从MapTask中下载数据到本地,要等到所有的MapTask运行完之后才能运行;
按key分组,全排序---->按key排好,两个数据就可以决定分组,(默认调用compareTo进行分组,否则就用自定义的,自定义是继承类WritableComparator;)这个数据跟下个数据比较,一样就分同一组,不一样就新启动一组;
内存里边只有两个数据,这一个和下一个;
从map到reduce进行的全排序;快排,单轴排序,java用的双轴排序;
分区只是决定这条数据去哪个reduceTask,不能决定reduceTask的数量;
怎么比较key是否相等;
① 分区
public class HashPartitioner<K, V> extends Partitioner<K, V> {
public int getPartition(K key, V value, int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
默认分区是根据 Key的hashCode对ReduceTask个数取模得到,没法控制哪个key存储到哪个分区;
}
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
numReduceTasks是设置的ReduceTask的数量;取余
Integer.MAX_VALUE换算成位是一串011111...;假设key.hashCode是
0100100,它们做位运算,没变化,但如果是以1开头的,就是负数,取余还是负数; --->目的就是防止出现负数;
把不同的数据分到不同的ReduceTask分别处理叫分区;
public class MyPartitioner extends Partitioner<Text, FlowBean> {
//自定义分区
public int getPartition(Text text, FlowBean flowBean, int i) {
String substring = text.toString().substring(0, 3);
switch (substring){
case "136":
return 0;
case "137":
return 1;
case "138":
return 2;
case "139":
return 3;
default:
return 4;
}
}
}
public class PatitionDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1.实例化
Job job = Job.getInstance(new Configuration());
//2.设置类jar路径
job.setJarByClass(PatitionDriver.class);
//3.设置Mapper和Reduce路径
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReduce.class);
job.setPartitionerClass(MyPartitioner.class);
//job.setNumReduceTasks(5);
//job.setNumReduceTasks(6); //ReduceTask数量6 > 分区数量5; 产生空的输出文件part-r-00005
//job.setNumReduceTasks(4); //ReduceTask数量4 < 分区数量5; 有部分数据无处放Illegal partition for 18271575951 (4)
//如果分区数量跳过3,不按顺序;Illegal partition for 13956435636 (4);分区号不能跳,会浪费;分区号必须从0开始,逐一累加;
job.setNumReduceTasks(1); //ReduceTask数量1,不管MapTask输出多少个分区文件,最终结果都交给这一个ReduceTask,最终也只会产生一个part-r-0000文件
//4.输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
//5.路径
FileInputFormat.setInputPaths(job, new Path("F://input"));
FileOutputFormat.setOutputPath(job, new Path("F://output"));
//6.提交
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
② WritableComparable排序
MapTask和ReduceTask均会对数据按照key进行排序,属Hadoop默认行为,任何应用程序中的数据均会被排序,不管逻辑上是否需要;
默认排序是按字典顺序排序,且实现该排序方法的是快速排序;

分类:
部分排序(MapReduce根据输入记录的键对数据集排序,保证输出的每个文件内部有序);
全排序(最终输出结果只有一个文件,且文件内部有序;实现方法是只设置一个ReduceTask,在处理大型文件时效率极低,一台机器处理所有文件,丧失了MapReduce所提供的行为架构);辅助排序(GroupingComparator分组,在Reduce端对key分组,应用于:在接受的key为bean对象时,想让一个或几个字段相同(全部字段比较不相同)的key进入到同一个reduce方法时可采用分组排序);
二次排序(自定义排序中,如果comparaTo中的判断条件为两个即二次排序;)
排序接口 WritableComparable,利用了Shuffle强制排序的过程
分区-->排序;把需要排序的放到key的位置就会自动排序(强制性)
自定义排序
自定义排序WritableComparable
原理分析
bean对象做为key传输,需要实现WritableComparable接口重写compareTo方法,就可以实现排序。
/OrderBeam是WritableComparable的实现类
//bean对象做为key传输,需要实现WritableComparable接口重写compareTo方法,就可以实现排序。
public class OrderBean implements WritableComparable<OrderBean> { } @Override
public int compareTo(OrderBean o) {
//先按orderById分; 如果相同则按price
int compare = this.getOrderById().compareTo(o.getOrderById());
if (compare == 0){
return -Double.compare(this.price, o.price); //默认是升序; 降序需加-
}else {
return compare;
}
}
@Override //序列化把它写进去
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(orderById);
dataOutput.writeUTF(productId);
dataOutput.writeDouble(price); }
@Override //反序列化要再把它读出来
public void readFields(DataInput dataInput) throws IOException {
orderById = dataInput.readUTF();
productId = dataInput.readUTF();
price = dataInput.readDouble();
}
排序的同时可自定义分区
public class SortPatitioner extends Partitioner<FlowBean, Text>{
@Override
public int getPartition(FlowBean flowBean, Text text, int i) {
String start = text.toString().substring(0, 3);
switch (start) {
case "136":
return 0;
case "137":
return 1;
case "138":
return 2;
case "139":
return 3;
default:
return 4;
}
}
}
③ Combiner合并
combiner应用的前提是求和操作,求平均值不行

Reduce(K, V)它在ReduceTask中; Combine在MapTask节点中运行;
Combine是对Mapper的局部汇总,不能改变Mapper的输出类型,Combine输入输出泛型应该是一样的;
如:
aaa aaa aaa bbb bbb bbb ccc ccc ccc
在map阶段是(aaa,1)3;(bbb, 1)3;(ccc, 1)3
用了combine在map阶段(aaa, 3),(bbb, 3),(ccc, 3)
reduce可以对所有的mapper进行全局汇总;combine是局部合并;
reduce(分组输入,combine肯定也是分组输入,)输出文件至少是有序的;整个shuffle阶段就是给reduce准备输入文件,排好序;
job.setCombinerClass(WcReduce.class); //不设置CombinerClass
④分组(辅助排序)
对Reduce阶段的数据根据某一个或几个字段进行分组。
分组排序步骤:
(1)自定义类继承WritableComparator
(2)重写compare()方法
@Override
public int compare(WritableComparable a, WritableComparable b) {
// 比较的业务逻辑
return result;
}
(3)创建一个构造将比较对象的类传给父类
protected OrderGroupingComparator() {
super(OrderBean.class, true);
}
自定义分组
分组规则和排序规则一致就不需要自定义分组;排序规则和分组规则不一样,就用到自定义分组;
分组粒度 > 排序的粒度;分组的粒度更粗一点,排序的粒度更细点;
public class MyComparator extends WritableComparator{
public MyComparator(){
super(OrderBean.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
OrderBean oa = (OrderBean) a;
OrderBean ob = (OrderBean) b; //构造两个空对象拿到序列化的数据,把具有相同id的key放一个组;需要反序列化去比较
return oa.getOrderById().compareTo(ob.getOrderById()); //分组,相同的key即id就分一个组 } }
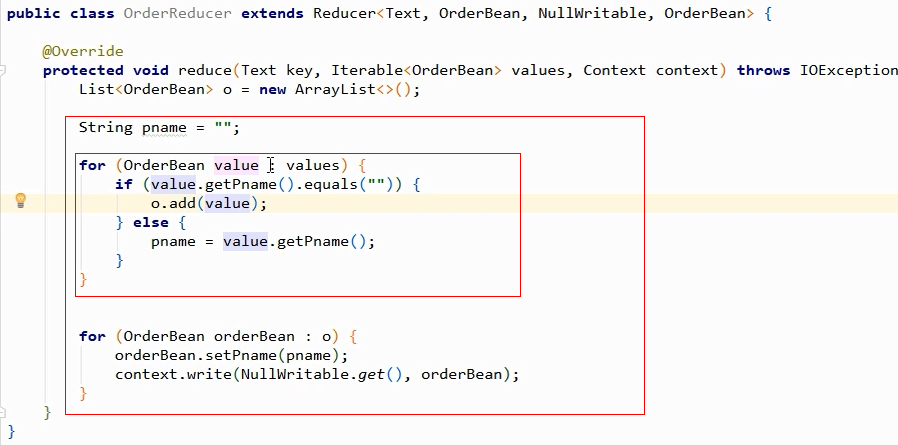
public class OrderReducer extends Reducer<OrderBean, NullWritable, OrderBean, NullWritable>{
@Override
protected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
// context.write(key, NullWritable.get()); //key之前是相同的,不相同的key进入同一个组;它取出来的是每个组第一个值;
for (NullWritable value : values) { //遍历所有的
context.write(key, value);
}
对于reduce,key, value都只有一个对象;
它拿到的数据是已经排好序的k,v对象;往下遍历一个,就反序列化一个,
再遍历一个,继续往下移动(只能往下移动,不能返回),反序列化; 对象始终只有两个,对象的值却是在不断变化(通过反序列化的方法);
执行hasNaxt,调用WritableComparable跟下面比较下:若相等返回true就继续往下迭代;把当前的迭代值与下一个比较,0返回true继续迭代,非0返回false迭代结束;
结束后第二个reduceTask接着迭代的数据往下...分组和读数据是同时进行的;
Iterator<NullWritable> iterator = values.iterator(); //单例模式,来回遍历还是他自己
for (int i = 0; i < 2; i++){
if (!iterator.hasNext())
break;
iterator.next();
context.write(key, NullWritable.get()); //查看组内前两个值
//取前两个值;
}
NullWritalbe单例模式;私有化构造器,公有化一个get方法;饿汉式模式;
public class NullWritable implements WritableComparable<NullWritable> {
private static final NullWritable THIS = new NullWritable();
private NullWritable() {
}
public static NullWritable get() {
return THIS;
}
在大数据背景下,不允许有大量对象存在内存,在整个MapReduce框架运行过程中,所有的数据都是用序列化来传递的。需要用到对象时,现场序列化现场反序列化;
对于自定义的comparator比较的时候并没有现成的对象用,需要先构造两个空对象,拿到序列化的数据,反序列化进行比较;核心:减小IO;
分区发生在mapTask,分组发生在ReduceTask中;
combine输入的数据肯定是要分组,默认用bean的排序规则,combine的分组规则不会用到GroupingComparator;
GroupingComparator 起效只在reduce之前分组起效;
4、OutputFormat数据输出

SequenceFileOutputFormat它是处在两个MapReduce之间的临时文件; SequenceFileOutputFormat SequenceFileInputFormat发,接;什么类型出来,什么类型接,中间用它连接;
自定义OutputFormat
public class MyOutputFormat extends FileOutputFormat<LongWritable, Text> {
@Override
public RecordWriter<LongWritable, Text> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException {
MyRecordWriter recordWriter = new MyRecordWriter();
recordWriter.initialize(job);
return recordWriter;
}
}
public class MyRecordWriter extends RecordWriter<LongWritable, Text> {
private FSDataOutputStream atguigu;
private FSDataOutputStream others;
public void initialize(TaskAttemptContext job) throws IOException { //job来获取configuration
//获取文件系统
Configuration configuration = job.getConfiguration();
FileSystem fileSystem = FileSystem.get(configuration);
//获取文件目录
String path = configuration.get(FileOutputFormat.OUTDIR);
atguigu = fileSystem.create(new Path(path + "/atguigu.log"));
others = fileSystem.create(new Path(path + "/others.log"));
}
@Override
public void write(LongWritable key, Text value) throws IOException, InterruptedException {
String line = value.toString() + "\n";
if (line.contains("atguigu")){
//包含就写出去; FSDataOutputStream要以bytes的格式写出去; 把k, v键值对变成text;
atguigu.write(line.getBytes());
}else {
others.write(line.getBytes());
}
}
@Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
IOUtils.closeStream(atguigu);
IOUtils.closeStream(others);
}
}
public class OutDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance(new Configuration());
job.setJarByClass(OutDriver.class);
job.setOutputFormatClass(MyOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path("F://input"));
FileOutputFormat.setOutputPath(job, new Path("F://output"));
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 :1);
}
}
5、Join的多种应用
① Reduce Join
原理:
Map端:为来自不同表或文件的key/value对,打标签以区别不同来源的记录。然后用连接字段作为key,其余部分和新加的标志作为value,最后输出;
Reduce端:在Reduce端以连接字段作为key的分组已完成,只需在每一个分组中将来源不同文件的记录(在map阶段已打标志)分开,最后合并就ok
缺点:
这种方式合并的操作在Reduce阶段完成,Reduce端的处理压力太大,Map节点的运算负载则很低,资源利用率不高,且在Reduce阶段极易产生数据倾斜;
解决方案:Map端实现数据合并。
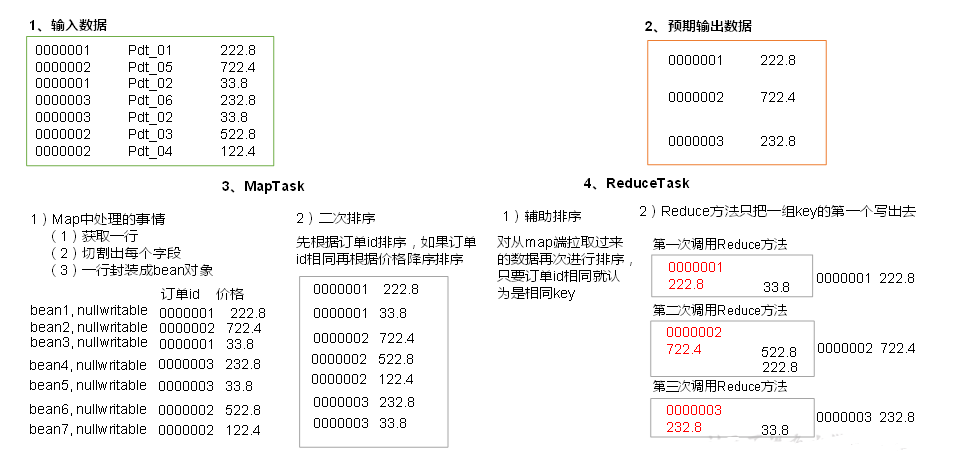
ArrayList数组的底层是,数组中每个值指向内存地址,每个数组对象bean对象;o.add添加对象,这个对象不会改变;
首先要获得pname,要找到它,排序把它放到第一个,进来的时候就直接获取到了;第二个就直接往外写就可以了; 分组排序
①
pid 订单id amount
01 1001 1
02 1002 2
03 1003 3
01 1004 4
02 1005 5
03 1006 6
01 小米 0
02 华为
03 格力
②先按pid排,再按pname排,二次排序
01 小米 0
01 x 1 1001
01 x 4 1004
02 华为 0
02 x 2 1002
02 x 5 1005
03 格力 0
03 x 3 1003
03 x 6 1006
③把pid一样的分到一个组;
return ta.getPid().compareTo(tb.getPid());
再经过Reduce方法处理:
01 小米 0
01 小米 1 1001
01 小米 4 1004
02 华为 0
02 华为 2 1002
02 华为 5 1005
03 格力 0
03 格力 3 1003
03 格力 6 1006
最后结果④
订单id pname amount
1004 小米 4
1001 小米 1
1005 华为 5
1002 华为 2
1006 格力 6
1003 格力 3
通过将关联条件作为Map输出的key,将两表满足Join条件的数据并携带数据所来源的文件信息,发往同一个ReduceTask,在Reduce中进行数据的串联,如图

@Override
public int compareTo(TableBean o) {
//先按pid排序,再按名字排
int compare = this.pid.compareTo(o.pid);
if (compare == 0){
return -this.pname.compareTo(o.pname); //默认是升序,没名字的在前;降序加- ;把有pname的靠前;;
}else {
return compare;
}
} 在map阶段完成封装,首先按pid排序,然后再按pname排;
01 小米 排完序之后(排序和分组)应该这样子; 把排好序的一块输到reduce里;
1001 01 1
1004 02 4 public class TableReducer extends Reducer<TableBean, NullWritable, TableBean, NullWritable> {
@Override
protected void reduce(TableBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
Iterator<NullWritable> iterator = values.iterator();
iterator.next(); //先遍历第一个,指针首先是指向0的,next完之后它就指向了1,
String pname = key.getPname(); //取出pname;把剩下的数据写出去,因为它们都要进行替换
System.out.println(pname);
while (iterator.hasNext()){
iterator.next(); //先执行下;
key.setPname(pname); 执行到这一步时key已经到第二行了即 1001 01 1
context.write(key, NullWritable.get()); setpanme,再写出去
} }
}
遍历value时,key会变; key像一个杯子,先取出水pname放一个string里,再next下,里边就是装的其他内容;再把pname装进去;最后把这个杯子整体倒出来到一个框架。
② Map Join
使用场景
Map Join适用于一张表十分小(大约25M,最好不超过10M)、另一张表大小无所谓。
优点
思考:在Reduce端处理过多的表,非常容易产生数据倾斜。怎么办?
在Map端缓存多张表,提前处理业务逻辑,这样增加Map端业务,减少Reduce端数据的压力,尽可能的减少数据倾斜。
不需要Reduce,Map出的key就不需专门排序了,也不需分组了;从Map---->outputFormat结束;
没有shuffle,不会产生数据倾斜;
并行数由切片数决定的;一个reduce处理多少数据看分区的均匀度;默认按hashcode值分区,hashcode要尽量平均,这是其一;key的重复过多(如全校前10排序,因为有尖子班,它们班占据前八) --->>数据倾斜(由分区引起);
如25M小文件,join 10G文件(分80份,80个MapTask),每个MapTask都需要拉来25M数据; 25*80=2000MB
具体办法:采用DistributedCache
(1)在Mapper的setup阶段,将文件读取到缓存集合中。
(2)在驱动函数中加载缓存。
// 缓存普通文件到Task运行节点。
job.addCacheFile(new URI("file://e:/cache/pd.txt"));
public class DistributedMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
//存放缓存数据的map
private Map<String, String> pMap = new HashMap<>();
private Text text = new Text();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
//①利用context获取缓存文件,把pd.txt文件放到缓存文件中;用java的IO流读取
URI[] cacheFiles = context.getCacheFiles(); //可以添加多个
String path = cacheFiles[0].getPath(); //获取字符串路径,/F:/input/pd.txt
System.out.println("文件路径为:" + path);
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(path), "UTF-8"));
//②一行行的读取,放到缓存文件map集合中
String line;
while (StringUtils.isNotEmpty(line = reader.readLine())){ //循环读取缓存文件
String[] split = line.split("\t"); //切割
pMap.put(split[0], split[1]); //把pid和pname存放集合中
//System.out.println(split[0] + "\t" + split[1]);
}
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split("\t");
String pname = pMap.get(split[1]);
String out = split[0] + "\t" + pname + "\t" + split[2]; //拼接写出去;订单id pname amount
text.set(out);
context.write(text, NullWritable.get()); //强制按照id进行排序
}
}
public class DistributedCacheDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance(new Configuration());
job.setJarByClass(DistributedCacheDriver.class);
job.setMapperClass(DistributedMapper.class);
job.setNumReduceTasks(0); //不需要Reduce阶段
job.addCacheFile(URI.create("file:///F:/input/pd.txt")); //file://协议,表本地文件; 加载缓存文件
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path("F://input/order.txt"));
FileOutputFormat.setOutputPath(job, new Path("F://output"));
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
Hadoop| MapperReduce02 框架原理的更多相关文章
- Hadoop Yarn框架原理解析
在说Hadoop Yarn的原理之前,我们先来看看Yarn是怎样出现的.在古老的Hadoop1.0中,MapReduce的JobTracker负责了太多的工作,包括资源调度,管理众多的TaskTrac ...
- Hadoop Yarn 框架原理及运作机制及与MapReduce比较
Hadoop 和 MRv1 简单介绍 Hadoop 集群可从单一节点(其中所有 Hadoop 实体都在同一个节点上运行)扩展到数千个节点(其中的功能分散在各个节点之间,以增加并行处理活动).图 1 演 ...
- hadoop MapReduce Yarn运行机制
原 Hadoop MapReduce 框架的问题 原hadoop的MapReduce框架图 从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路: 首先用户程序 (JobClient) ...
- Hadoop MapReduceV2(Yarn) 框架简介[转]
对于业界的大数据存储及分布式处理系统来说,Hadoop 是耳熟能详的卓越开源分布式文件存储及处理框架,对于 Hadoop 框架的介绍在此不再累述,读者可参考 Hadoop 官方简介.使用和学习过老 H ...
- Hadoop学习之YARN框架
转自:http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/,非常感谢分享! 对于业界的大数据存储及分布式处理系统来说,H ...
- hadoop yarn
简介: 本文介绍了 Hadoop 自 0.23.0 版本后新的 map-reduce 框架(Yarn) 原理,优势,运作机制和配置方法等:着重介绍新的 yarn 框架相对于原框架的差异及改进:并通过 ...
- 【大数据技术】Hadoop三大组件架构原理(HDFS-YARN-MapReduce)
目前,Hadoop还只是数据仓库产品的一个补充,和数据仓库一起构建混搭架构为上层应用联合提供服务. Hadoop集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起. ...
- hadoop备战:yarn框架的简单介绍(mapreduce2)
新 Hadoop Yarn 框架原理及运作机制 重构根本的思想是将 JobTracker 两个基本的功能分离成单独的组件,这两个功能是资源管理和任务调度 / 监控.新的资源管理器全局管理全部应用程序计 ...
- Hadoop 新 MapReduce 框架 Yarn 详解【转】
[转自:http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/] 简介: 本文介绍了 Hadoop 自 0.23.0 版本 ...
随机推荐
- AES加解密程序的实现
AES加解密程序的实现正常情况,用户不能访问sys.dbms_crypto,需要DBA授权:grant execute on dbms_crypto to crm;建立加解密的PKG_AES包:CRE ...
- MongoDB、Hbase、Redis等NoSQL优劣势、应用场景
NoSQL的四大种类 NoSQL数据库在整个数据库领域的江湖地位已经不言而喻.在大数据时代,虽然RDBMS很优秀,但是面对快速增长的数据规模和日渐复杂的数据模型,RDBMS渐渐力不从心,无法应对很多数 ...
- iOS -- Effective Objective-C 阅读笔记 (2)
1: 多用类型常量, 少用 #define 预处理指令 #define 预处理指令会把碰到的所有 指定名称 一律换位 定义的内容, 这样的话, 假设此指令在某个头文件中, 那么所有引入这个头文件的代码 ...
- django之数据库表的单表查询
一.添加表记录 对于单表有两种方式 # 添加数据的两种方式 # 方式一:实例化对象就是一条表记录 Frank_obj = models.Student(name ="海东",cou ...
- django----利用Form 实现两次密码输入是否一样 ( 局部钩子和全局钩子 )
from django import forms # 导入表单模块 from django.core.exceptions import ValidationError class RegisterF ...
- 基于Manhattan最小生成树的莫队算法
点u,v的Manhattan距离:distance(u,v)= |x2-x1|+|y2-y1| Manhattan最小生成树:边权值为两个点Manhattan距离的最小生成树. 普通算法:prim复杂 ...
- node.js 框架express有关于router的运用
1.express 路由入门 const express = require('express'); let server = express(); server.listen(8087); //用户 ...
- 第七周学习总结-C#
2018年8月26日 这个周二突然得知另一位老师留的暑假作业,群文件里早就上传了,我居然一直没翻到那里,要不是同学问作业做完没,我可能开学就要“真●裸考”了
- vue中Axios的封装和API接口的管理
前端小白的声明: 这篇文章为转载:主要是为了方便自己查阅学习.如果对原博主造成侵犯,我会立即删除. 转载地址:点击查看 如图,面对一团糟代码的你~~~真的想说,What F~U~C~K!!! 回归正题 ...
- OpenCV-Python入门教程7-PyQt编写GUI界面
前面一直都是使用命令行运行代码,不够人性化.这篇用Python编写一个GUI界面,使用PyQt5编写图像处理程序.包括:打开.关闭摄像头,捕获图片,读取本地图片,灰度化和Otsu自动阈值分割的功能. ...